Try out vector search for yourself using this self-paced hands-on learning for Search AI. You can start a free cloud trial or try Elastic on your local machine now.
Elasticsearch 9.4 makes restrictive DiskBBQ filtered vector search 3–5x faster. DiskBBQ is Elasticsearch’s new partition based index. It strives to provide the best trade-off for cost and performance by making the vector index as sympathetic as possible to the underlying system. While DiskBBQ does well with broad filters, it struggled with restrictive filters. Continuing our journey for a simple, fast, and efficient vector index, we adjust how we apply filtering and significantly improve latency.
What’s hard about filtering partition indices
With partition indices, all searches are done in two phases:
- Find the nearest centroids.
- Find all the nearest vectors within the nearest centroids’ clusters.
For DiskBBQ, the centroids are quantized and possibly indexed in their own structure. The cluster contents (we’ll call them postings lists from now on) are laid out in an effort to make scoring the vectors fast. Postings are stored in blocks of 32, with each block in doc_id order. Doc IDs are delta-encoded to minimize disk usage with low decode overhead. Vector values are also block-encoded, separating dimensions from quantized corrections to maximize single instruction, multiple data (SIMD) throughput using our optimized kernels.
Once we reach a postings list, the layout is optimized for fast scoring and filtering. For example, if an index sort is provided, blocks of vectors that match a filter will be stored and scored together within a list. This unlocks scoring contiguous blocks of vectors at a time, taking full advantage of the underlying CPU throughput.
That said, we don’t know if a cluster matches a given filter until we actually check its doc_ids. Once verified, we can be sure to only score against the relevant vectors. In restrictive-filter cases, we can inspect a centroid and still find that none of its vectors match the filter. To compensate, we keep scoring and exploring centroids until we get a representative group of vectors scored.
This meant wasted work for restrictive filters. We score centroids, not knowing if they have vectors relevant to the filter or not; prepare to score the postings list, only to find that none of the blocks apply. The wasted compute adds up:
- Unnecessarily scoring the centroid.
- Loading a filtered-out postings list because it’s close to the query vector.
- Decoding and checking the document IDs in the list, only to find out none match.
- Continue the search, potentially hitting another completely filtered-out centroid, until we visit enough to get the desired recall.
Here’s an example showing the old flow. Check all the centroids, see what matches, move on to centroids that have matching vectors. Rinse and repeat.
How do we get to the right centroids quickly?
The simplest solution would be to skip centroids that contain no valid vectors. But we don’t want to index additional information for all potential filter fields and values. A user can provide many variations of complex or simple filters. This is a strength of Elasticsearch, and we don’t want to hamper that.
Instead, we simply store the mapping of doc_id -> centroid_ord. This gives us an immediate view of all docs and their centroid membership. Allowing us to iterate any provided filter in document order, quickly determining the relevant centroids. Of course, iterating every document to check if it passes a filter is not free. We only apply this eager logic if the average number of documents per cluster that match the filter is 1.25. Yes, this is a “magic number”; however, it's empirically based. Assuming the filter is random, we’re validating at least one matching vector per centroid with some overhead. We may refine this in the future, but early experimentation found this number to be a sweet spot for most users.
Here’s the new way. Detecting we have a restrictive filter, go straight to the filtered centroids.
Benchmark, benchmark, benchmark
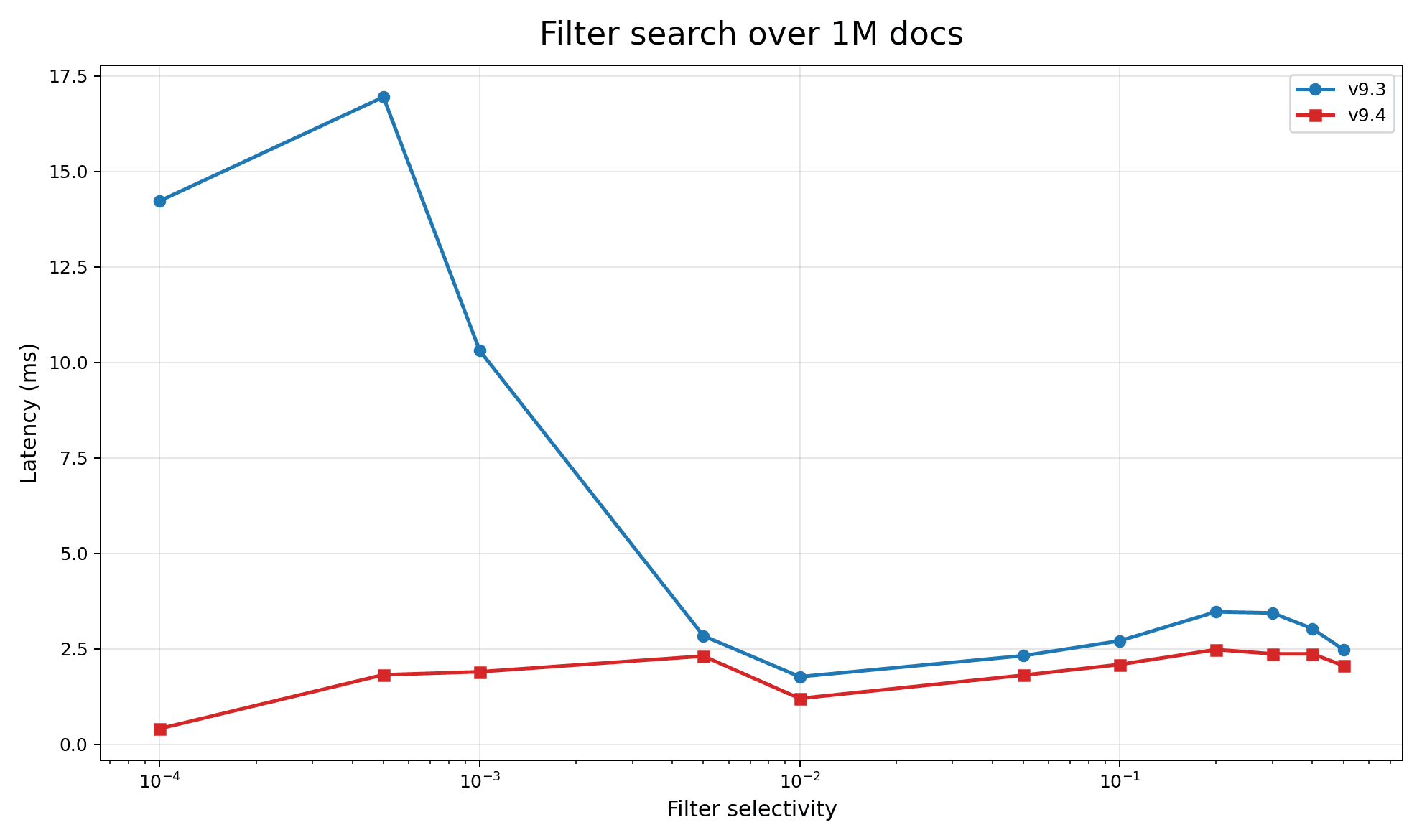
Here’s a macro-benchmark with a random filter. The filter selectivity is purposefully extreme to show the significant improvement on hyper-restrictive filters. Here we see almost an order-of-magnitude improvement. Where before, when filters got very restrictive, there would be a horrible elbow. Now latency remains consistent and will in fact improve as filters get more restrictive.
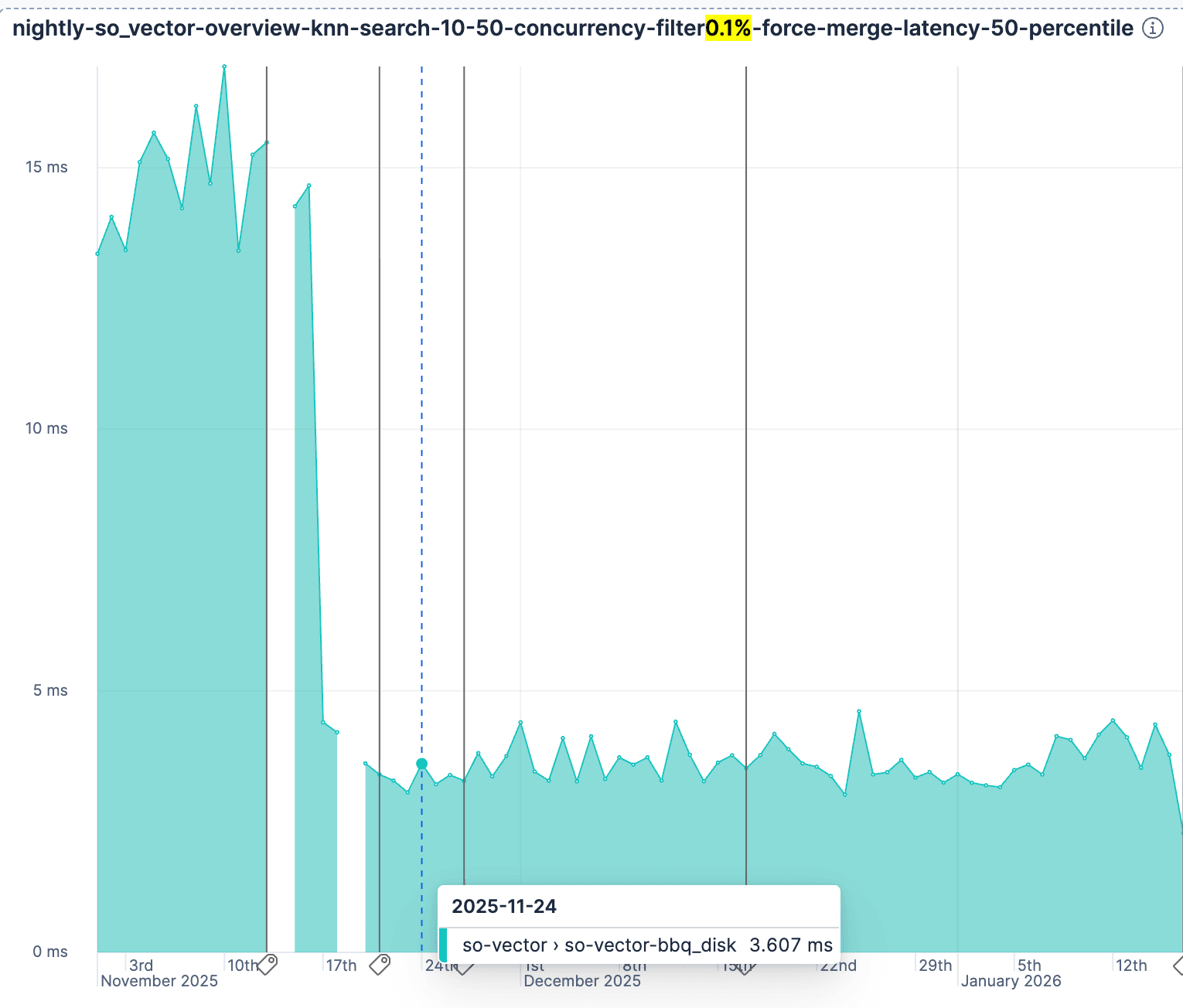
A further validation is our nightly runs of so-vector with rally showing the improvement. You can try this yourself by specifying bbq_disk in the vector_index_type in the rally configuration.
What's next?
This is in Elastic Serverless now and will be in stack release 9.4.0. We aren’t done improving vector search in Elasticsearch. This is just another step in our journey to bring you simple, efficient, practical, and fast vector search. Thank you so much for using the code that we write. We ❤️ you.
相关内容

2026年7月10日
How BBQ shrinks Jina v5 embeddings by 29x without losing recall in Elasticsearch
A hands-on test comparing BBQ and float32 vector indices in Elasticsearch, measuring memory, disk and recall@10 across five languages.

2026年7月7日
Short queries, formal documents: how HyDE improved semantic search precision by 50% in Elasticsearch
HyDE boosts semantic search precision and recall by 50% on short queries. Here's how to implement it in Elasticsearch with the Inference API and semantic_text.

2026年7月2日
A simdvec deep-dive: How Elasticsearch uses neural-net and video-codec CPU instructions for vector search
Four ways Elasticsearch's vector search engine reuses neural-network, video-codec and cryptography CPU instructions for up to 6x speedups; with the math, the failed attempts and the benchmarks.

2026年6月24日
Elasticsearch DiskBBQ delivers 7x faster vector search than Qdrant on network-attached storage
Elasticsearch DiskBBQ achieves up to 7x higher vector search throughput than Qdrant at comparable recall on network-attached storage. Explore the benchmark methodology and full results.

2026年6月18日
Jingra: A Reproducible Framework for Vector Search Benchmarking
Jingra is an open source benchmarking framework that runs the same vector search workload across Elasticsearch, OpenSearch and Qdrant so you can compare engines under identical, reproducible conditions.