在 Elasticsearch 中,连接两个索引不像在传统 SQL 关系数据库中那么简单。不过,使用 Elasticsearch 提供的某些技术和功能也可以实现类似的结果。
历史上,许多人使用nested 字段类型作为将不同索引连接在一起的机制。然而,由于 Kibana 的查询成本高昂且支持不完整,特别是镜头可视化功能,该功能受到了限制。
本文将深入探讨在 Elasticsearch 中连接两个索引的过程,重点介绍以下方法:
- 使用
terms查询 - 在摄取流水线中使用
enrich处理器 - Logstash
elasticsearch过滤器插件 - ES|QL
ENRICH - ES|QL
LOOKUP JOIN
使用术语查询
术语查询是 Elasticsearch 中连接两个索引的最有效方法之一。该查询用于检索在特定字段中包含一个或多个精确术语的文档。下面我们讨论如何使用它来连接两个索引。
首先,您需要从第一个索引中获取所需的数据。这可以通过简单的 GET 请求和从_source 属性中提取值来实现。
获得第一个索引的数据后,就可以用它来查询第二个索引。这是通过terms 查询完成的,您可以在查询中指定要匹配的字段和值。
下面就是一个例子:
在本例中,field_in_second_index 是第二个索引中要与第一个索引中的值匹配的字段。value1_from_first_index 和value2_from_first_index 是第一个索引中要在第二个索引中匹配的值。
术语查询还支持使用术语查找技术一次性完成上述两个步骤。Elasticsearch 会以透明方式从另一个索引中检索要匹配的值。例如,如果您有一个包含球员列表的球队索引:
如下图所示,可以通过人员索引查询在 team1 队中比赛的所有人员:
在上面的示例中,Elasticsearch 会以透明方式从球队索引中 id 为 team1 的文档中检索球员姓名(即"john"、"bill "和 "michael"),并查找人物索引中所有在姓名字段中包含这些值的文档。
对于那些好奇的人来说,等价的 SQL 查询应该是这样的:
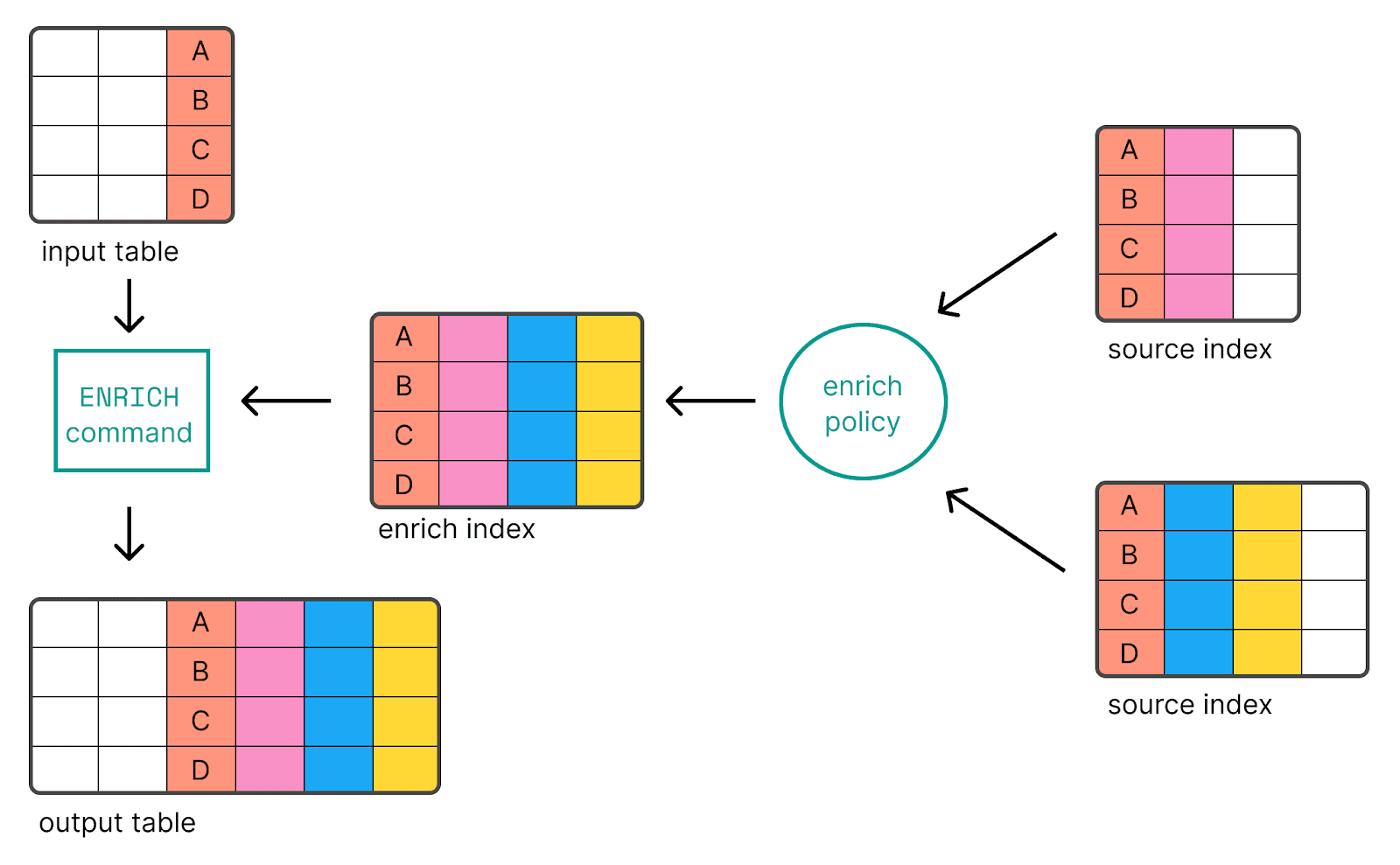
使用浓缩处理器
enrich 处理器是另一个可用于连接 Elasticsearch 中两个索引的强大工具。该处理器通过添加来自预定义丰富索引的数据来丰富输入文件的数据。
下面介绍如何使用浓缩处理器连接两个索引:
1.首先,您需要创建一个浓缩策略。该策略定义了使用哪个索引来丰富输入文档、匹配哪个字段以及使用哪个字段来丰富输入文档。
下面就是一个例子:
2.创建策略后,需要执行该策略,以便根据新创建的策略创建 enrich 索引:
这将建立一个新的隐藏浓缩索引,在浓缩过程中使用。根据源索引的大小,这一操作可能需要一些时间。在进行下一步之前,请确保充实政策已完全制定。
3.建立丰富策略后,就可以在摄取管道中使用丰富处理器来丰富传入文档的数据:
在本例中,field_in_second_index 是第二个索引中需要与第一个索引中的match_field 匹配的字段。enriched_field 是第二个索引中的新字段,将包含第一个索引enrich_fields 中的丰富数据。
这种方法的一个缺点是,如果first_index 中的数据发生变化,则需要重新执行浓缩策略。丰富索引不会自动更新或同步源索引。但是,如果first_index 相对稳定,那么这种方法就很有效。
Logstash elasticsearch 过滤器插件
如果使用 Logstash,另一个与上述enrich 处理器类似的选项是使用elasticsearch 过滤器插件,根据指定的查询将相关字段添加到事件中。Logstash 管道的配置位于.conf 文件中,如my-pipeline.conf 。
假设我们的管道使用elasticsearch 输入插件从 Elasticsearch 中提取日志,并通过查询缩小选择范围:
如果我们想用给定索引的信息来丰富这些信息,可以使用filter 部分的elasticsearch 过滤器插件来丰富我们的日志:
上述代码将从索引index_name 中查找文件,其中type 为起始值,操作字段与指定的opid 匹配,然后将@timestamp 字段的值复制到名为started 的新字段中。
然后,丰富的文档将被发送到适当的输出源,在本例中是使用elasticsearch 输出插件发送到 Elasticsearch:
如果您已经在使用 Logstash,该选项可能有助于将丰富逻辑整合到一个地方,并在新事件发生时进行处理。但是,如果您不这样做,就会增加解决方案的复杂性,而且您还需要运行和维护另一个组件。
ES|QL ENRICH
在 8.14 版本中引入的ES|QL 是 Elasticsearch 支持的管道式查询语言,可用于过滤、转换和分析数据。使用 ENRICH 处理命令,我们就可以使用丰富策略从现有索引中添加数据。
以原浓缩处理器示例中的相同策略my_enrich_policy 为例,ES|QL 示例如下:
也可以覆盖匹配字段和丰富字段,在我们的例子中分别是field_in_first_index 和field_to_enrich :
虽然 ES|QL 的明显限制是需要先指定丰富策略,但 ES|QL 确实提供了根据需要调整字段的灵活性。
es|ql 查找连接
Elasticsearch 8.18 引入了一种在 Elasticsearch 中连接索引的新方法,即LOOKUP JOIN 命令。该命令在连接的右侧使用新的查找索引模式,以 SQL 风格的 LEFT OUTER JOIN 方式运行。

再看我们之前的例子,新的查询如下,其中match_field 需要同时出现在first_index 和second_index 中:
与其他方法相比,LOOKUP JOIN 的优势在于它不需要任何enrich 策略,因此也不需要与设置策略相关的额外处理。与本文讨论的其他方法不同,它在处理经常变化的丰富数据时非常有用。
结论
总之,虽然 Elasticsearch 不支持传统的连接操作,但它提供了各种功能,可用于实现类似的结果。具体来说,我们介绍了如何使用连接操作:
terms查询enrich摄录流水线中的处理器- Logstash
elasticsearch过滤器插件 - ES|QL
ENRICH - ES|QL
LOOKUP JOIN
需要注意的是,这些方法都有其局限性,应根据具体要求和数据性质谨慎使用。
相关内容

2025年11月14日
如何在 Azure AKS 上自动部署 Elasticsearch
了解如何使用 AKS Automatic 和 ECK 在 Azure 上部署带有 Kibana 的 Elasticsearch,以实现部分托管的 Elasticsearch 设置配置。


介绍 Kibana 中的 Elasticsearch 查询规则用户界面
了解如何使用 Elasticsearch 查询规则用户界面,在 Kibana 中使用可定制的规则集从搜索查询中添加或排除文档,而不影响有机排名。

2025年10月3日
如何在 AWS Marketplace 上部署 Elasticsearch
通过这份分步指南,您将了解如何在 AWS Marketplace 上使用 Elastic Cloud Service 来设置和运行 Elasticsearch。
