在本文中,我们将展示如何将 Apache Kafka 与 Elasticsearch 集成,以实现数据摄取和索引。我们将概述 Kafka 及其生产者和消费者的概念,并创建一个日志索引,通过 Apache Kafka 接收消息并编制索引。该项目使用 Python 实现,代码可在GitHub 上获取。
准备工作
- Docker 和 Docker Compose:确保计算机上安装了 Docker 和 Docker Compose。
- Python 3.x:运行生产者和消费者脚本。
Apache Kafka 简介
Apache Kafka 是一个分布式流平台,可实现高扩展性和可用性以及容错。在 Kafka 中,数据管理通过主要组件进行:
- 经纪人:负责在生产者和消费者之间存储和分发信息。
- Zookeeper:管理和协调 Kafka 代理,控制集群状态、分区领导者和消费者信息。
- 主题:发布和存储数据以供消费的渠道。
- 消费者和生产者:生产者向主题发送数据,消费者检索数据。
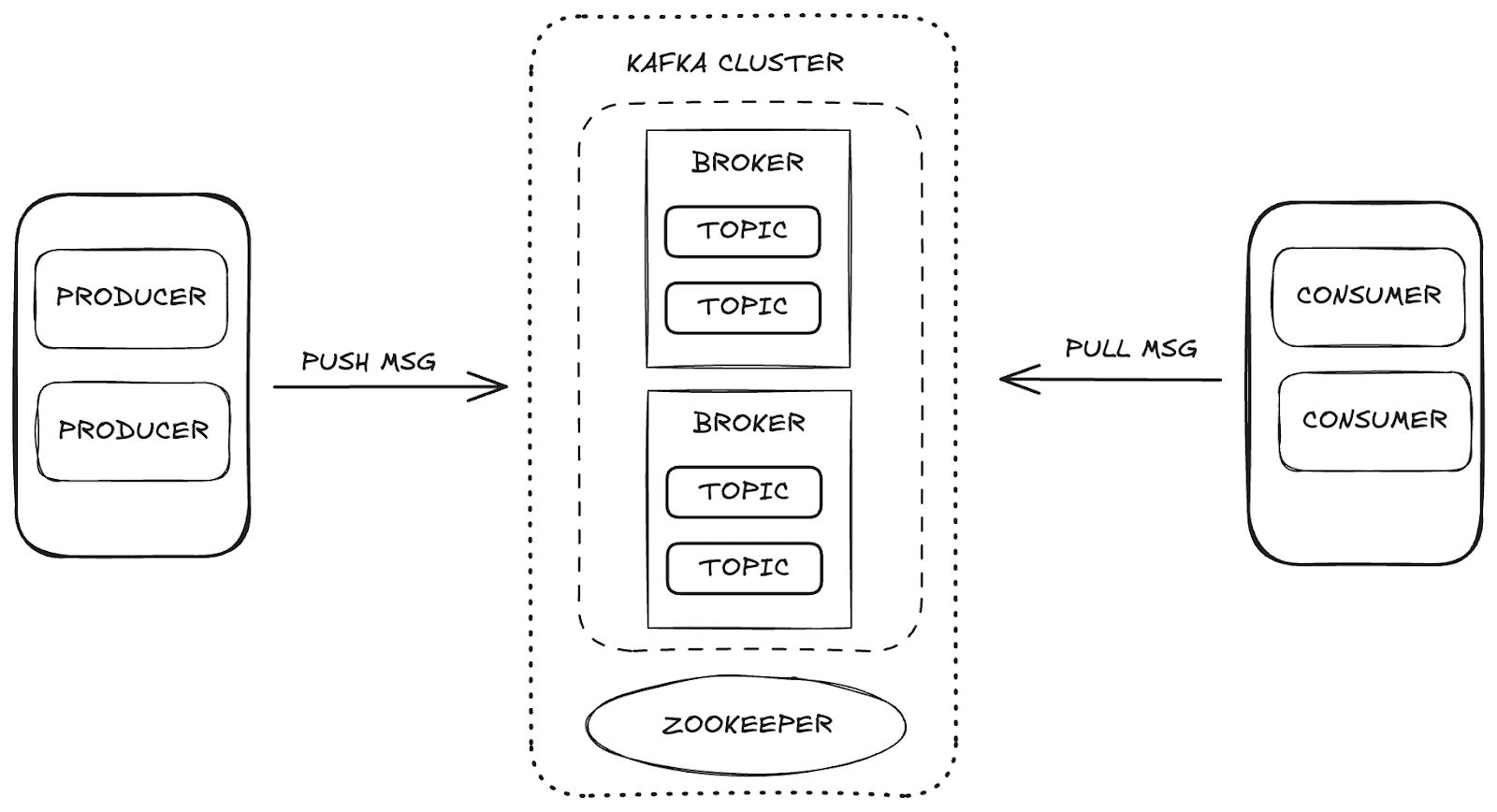
这些组件共同构成了 Kafka 生态系统,为数据流提供了一个强大的框架。
项目结构
为了解数据摄取过程,我们将其分为几个阶段:
- 基础架构调配:设置 Docker 环境以支持 Kafka、Elasticsearch 和 Kibana。
- 创建生产者:实现向日志主题发送数据的 Kafka 生产者。
- 创建消费者:开发 Kafka 消费者,以便在 Elasticsearch 中读取信息并编制索引。
- 输入验证:验证和确认发送和消耗的数据。
使用 Docker Compose 配置基础设施
我们利用 Docker Compose 配置和管理必要的服务。下面是 Docker Compose 代码,用于设置集成 Apache Kafka、Elasticsearch 和 Kibana 所需的各项服务,确保数据摄取过程。
您可以直接从 Elasticsearch LabsGitHubrepo 访问该文件。
使用 Kafka 生产者发送数据
生产者负责向日志主题发送消息。通过分批发送信息,它提高了网络使用效率,允许使用batch_size 和linger_ms 设置进行优化,这两个设置分别控制批次的数量和延迟。配置acks='all' 可确保信息的持久存储,这对重要的日志数据至关重要。
启动生产者时,消息会分批发送到主题,如下图所示:
使用 Kafka 消费者消费数据并编制索引
消费者旨在高效处理消息,从日志主题中批量消费,并将其索引到 Elasticsearch 中。通过auto_offset_reset='latest' ,它可以确保消费者开始处理最新的邮件,而忽略较早的邮件,并且max_poll_records=10 将批量限制为 10 封邮件。使用fetch_max_wait_ms=2000 时,消费者最多等待 2 秒钟,积累足够的报文后再处理批处理。
在其主循环中,消费者消耗日志信息,处理每个批次并将其索引到 Elasticsearch 中,从而确保持续的数据摄取。
在 Kibana 中可视化数据
有了 Kibana,我们就能探索和验证从 Kafka 采集并在 Elasticsearch 中编入索引的数据。通过访问 Kibana 中的 "开发工具",您可以查看已编入索引的信息,并确认数据符合预期。例如,如果我们的 Kafka 生产者发送了 5 个批次,每个批次 10 条消息,那么我们应该在索引中看到总共 50 条记录。
要验证数据,可以使用开发工具部分的以下查询:
响应:

此外,Kibana 还提供创建可视化和仪表盘的功能,有助于使分析更加直观和互动。下面,您可以看到我们创建的仪表盘和可视化的一些示例,这些仪表盘和可视化以各种格式展示了数据,增强了我们对所处理信息的理解。

使用 Kafka Connect 进行数据摄取
Kafka Connect 是一项服务,旨在促进数据源和目的地(汇)(如数据库或文件系统)之间的集成。它通过预定义的连接器自动处理数据移动。在我们的案例中,Elasticsearch 发挥着数据汇的作用。

使用 Kafka Connect,我们可以简化数据摄取流程,无需在 Elasticsearch 中手动实施数据摄取工作流。有了适当的连接器,Kafka Connect 就能将发送到 Kafka 主题的数据直接编入 Elasticsearch 索引,只需极少的设置,也无需额外编码。
使用 Kafka Connect
为了实现 Kafka Connect,我们将在 Docker Compose 设置中添加 kafka-connect 服务 。此配置的关键部分是安装 Elasticsearch 连接器,它将处理数据索引。
配置服务并创建 Kafka Connect 容器后,需要为 Elasticsearch 连接器创建配置文件。该文件定义了基本参数,如
connection.url:Elasticsearch 的连接 URL。topics:连接器将监控的 Kafka 主题(本例中为"logs" )。type.name:Elasticsearch 中的文档类型(通常为 _doc)。value.converter:将 Kafka 消息转换为 JSON 格式。value.converter.schemas.enable:指定是否包含模式。schema.ignore和key.ignore:在编制索引时忽略 Kafka 模式和键的设置。
下面是在 Kafka Connect 中创建 Elasticsearch 连接器的curl 命令:
使用此配置后,Kafka Connect 将自动开始摄取发送到"logs" 主题的数据,并在 Elasticsearch 中编制索引。这种方法可实现全自动数据摄取和索引,无需额外编码,从而简化了整个集成过程。
结论
集成 Kafka 和 Elasticsearch 可为实时数据摄取和分析创建一个强大的管道。本指南为构建强大的数据摄取架构提供了基本方法,可在 Kibana 中实现无缝可视化和分析,随时适应未来更复杂的要求。
此外,使用 Kafka Connect 使 Kafka 和 Elasticsearch 之间的集成更加简化,无需额外的代码来处理数据和编制索引。Kafka Connect 使发送到特定主题的数据只需最少的配置就能在 Elasticsearch 中自动编入索引。
相关内容


作为代码的弹性开放式网络爬虫
了解如何使用 GitHub Actions 管理 Elastic Open Crawler 配置,以便每次向版本库推送变更时,这些变更都会自动应用到已部署的爬虫实例。

如何显示 Elasticsearch 索引的字段
了解如何使用 _mapping 和 _search API、子字段、合成 _source 和运行时字段显示 Elasticsearch 索引的字段。

