Elasticsearch has native integrations with the industry-leading Gen AI tools and providers. Check out our webinars on going Beyond RAG Basics, or building prod-ready apps with the Elastic vector database.
To build the best search solutions for your use case, start a free cloud trial or try Elastic on your local machine now.
Generative AI is a type of Artificial Intelligence (AI) that can create new content and ideas, including conversations, stories, images, videos, and music. Like all AI, generative AI is powered by Machine Learning (ML) models—very large models that are pre-trained on vast corpora of data and commonly referred to as Foundation Models (FMs).
To the public, generative AI has seemingly appeared from nowhere. But if you dig deeper, you’ll note that the ideas underlying generative AI solutions trace their lineage back to inventions such as the Mark I perceptron in 1958 and neural networks in the late twentieth century.
Advancements in statistical techniques, the vast growth of publicly available data and advancements in Machine Learning (specifically the invention of the transformer-based neural network architecture) have led to the rise of models that contain billions of parameters or variables. To give a sense for the change in scale, the largest pre-trained model in 2019 was 330M parameters. Cohere's Command XL model, one of the leading models in Stanford’s Holistic Evaluation of Language Models (HELM) benchmark is trained on 52.4 billion parameters - ~1580x increase in size in just a few years.
Foundation Models (FMs) are ML models trained on massive quantities of structured and unstructured data, which can be fine-tuned or adapted for more specific tasks.
Large Language Models (LLMs) are a subset of FMs focused on understanding and generating human-like text. These models are ideal for needs such as translation, answering questions, summarizing information, and creating or identifying images.
LLMs can perform a wide range of tasks that span multiple domains, like writing blog posts, solving math problems, engaging in dialog, and answering questions based on a document. The size and general-purpose nature of FMs make them different from traditional ML models, which typically perform specific tasks, like analyzing text for sentiment, classifying images, and forecasting trends.
The primary goal of LLMs is to enable meaningful and engaging conversation between humans and machines and have become an immensely effective resource in countless industries, helping business to improve the customer experience.
Limitations of LLMs
LLMs have certain limitations. One notable constraint is that they are trained on general domain corpora, making them less effective on domain-specific tasks. There are scenarios when you want models to generate text based on specific data rather than generic data. For example, a health service provider company may want their chatbot to answer questions using the latest information stored in an enterprise document repository, so that the answers are specific to the health service provider’s business.
Also, these LLMs are trained offline until a knowledge cutoff date. It will be agnostic of any developments that have happened after the knowledge cutoff date. This may lead to inaccurate interpretations. For example, in 2021 San Francisco was the most expensive Bay Area City for renters. Today, it is Mountain view - source.
Approaches to enhance LLMs
There are two popular ways to reference contextual data in LLMs.
The first option is to fine-tune the base LLMs with contextual data. But, using this approach generating the correctly formatted information is time consuming. Also, it is costly to fine-tune a model. In addition to that, if the domain specific data is changing frequently, it would require frequent fine-tunings and retraining to provide accurate responses. This impacts time to market and also increases overall cost of the solution. In addition to that, not all LLMs provide an option to fine-tune.
To overcome these constraints, we can use a technique called Retrieval Augmented Generation (RAG). RAG is a process in which the model retrieves contextual documents from an external data source like Elasticsearch as part of its execution. These contextual documents are used in conjunction with the original input to produce an output.
Below are a few examples of how RAG can be used in various applications to improve the quality and relevance of generated content.
- Chatbot responses: In a chatbot system, RAG refers to combining a retrieval-based approach with a generative model. The retrieval component obtains relevant responses from a pre-defined database or knowledge base, while the generative model can add additional context or generate more fluent and diverse responses. This combination helps the chatbot provide more accurate and contextually appropriate answers to user queries.
- Content generation: RAG can be used in content generation tasks such as summarization or paraphrasing. The retrieval component can retrieve relevant sentences or paragraphs from existing documents or articles, and the generative model can then augment or rephrase the retrieved content to create new and original summaries or paraphrases.
- Recommendation systems: RAG can also be applied in recommendation systems. The retrieval component can retrieve a set of candidate items or products based on user preferences or history, and the generative model can then generate personalized recommendations or provide additional information about the recommended items to enhance the user’s decision-making process.
RAG using Elasticsearch and Cohere Command model through Amazon Bedrock
Why Cohere?
Cohere is the leading AI platform for enterprise. The company builds world-class LLMs that allow computers to search, understand meaning, and converse in text. Cohere's models are uniquely suited to the needs of business, providing ease of use and strong security and privacy controls across multiple deployment options. Companies can use the models out-of-the-box or tailor them to their particular needs using their own custom data.
Command is Cohere’s flagship text generation model. It is trained to follow user commands and to be instantly useful in practical business applications, such as text generation, summarization, RAG, and chat. Command ranks as one of the leading language models according to the Stanford’s HELM website an evaluation leaderboard comparing large language models on a wide number of tasks from Stanford University (March 2023 results). Customers can use Cohere's Command LLM through Amazon SageMaker Jumpstart and Amazon Bedrock.
Embed is Cohere’s representative model which translates text into numerical vectors that models can understand. Cohere provides industry-leading English and multilingual models (100+ languages) for a range of use cases, including semantic search, text classification, and semantic engine for RAG.
Why Elasticsearch?
To make the most of generative AI, it is essential to have a unified data platform where the organization's data is stored, making it easily (and safely) accessible and searchable in one centralized location.
Elasticsearch is a distributed, open source search and analytics engine for all types of data, including textual, numerical, geospatial, structured, and unstructured. Raw data from Enterprises flows into Elasticsearch from a variety of sources, including logs, system metrics, and web applications. Elasticsearch is built on top of Lucene and it excels at full-text search. Elasticsearch is fast and excels at delivering the most relevant responses to users.
In addition to full-text search, Elasticsearch also supports vector-search.
Vector search leverages ML to capture the meaning and context of unstructured data, including text and images, transforming it into a numeric representation. Frequently used for semantic search, vector search finds similar data using approximate nearest neighbor (ANN) algorithms. Compared to traditional keyword search, vector search yields more relevant results and executes faster. Users can enhance the search experience by combining vector search with filtering and aggregations to optimize relevance by implementing a hybrid search and combining it with traditional scoring.
Elasticsearch provides an easy-to-use and performant API to enable integration with other services. These features make Elasticsearch a preferred choice for enterprises to store business data and improve search experience.
Elasticsearch allows for the seamless integration of domain-specific context from the organization's data, thereby enhancing the performance and value of generative AI for achieving desired business objectives.
Why Amazon Bedrock?
Amazon Bedrock is a fully managed service that offers a choice of high-performing FMs from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Stability AI, and Amazon with a single API, along with a broad set of capabilities you need to build generative AI applications, simplifying development while maintaining privacy and security. With the comprehensive capabilities of Amazon Bedrock, you can easily experiment with a variety of top FMs, privately customize them with your data using techniques such as fine-tuning and RAG, and create managed agents that execute complex business tasks—from booking travel and processing insurance claims to creating ad campaigns and managing inventory—all without writing any code. Since Amazon Bedrock is serverless, you don't have to manage any infrastructure, and you can securely integrate and deploy generative AI capabilities into your applications using the AWS services you are already familiar with.
Amazon Bedrock offers several capabilities to support security and privacy requirements and has achieved HIPAA eligibility and GDPR compliance. With Amazon Bedrock, content is not used to improve the base models and is not shared with third-party model providers. Data in Amazon Bedrock is always encrypted in transit and at rest, and can encrypt the data using your own keys. AWS PrivateLink can be used with Amazon Bedrock to establish private connectivity between FMs and your Amazon Virtual Private Cloud (Amazon VPC) without exposing your traffic to the Internet.
Solution overview
Here's how to use RAG to enable Generative AI capabilities on domain-specific business data using Elasticsearch and Cohere Generate Model -Command through Amazon Bedrock.
The below architecture diagram explains how to get domain-specific responses from Cohere Command Model through Amazon Bedrock using enterprise data hosted in Elastic Enterprise Search using a technique called RAG.
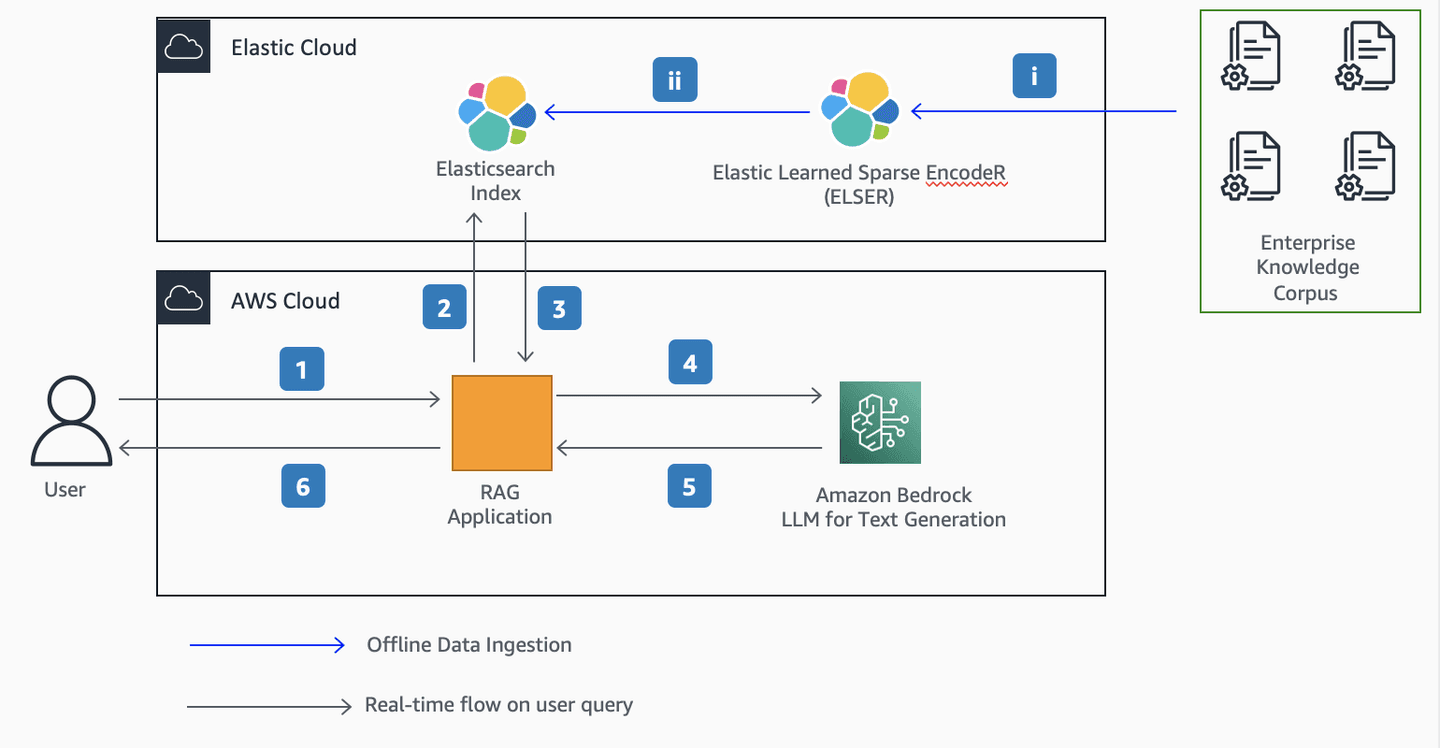
Figure 1. RAG Architecture using Elasticsearch and Amazon Bedrock
Step by step explanation
Offline Data Ingestion:
i. The documents are ingested using web crawler or any other ingestion mechanism.
ii. The Elastic Learned Sparse EncodeR (ELSER) model will embed the text and store the resulting tokens in the Elasticsearch Index
Real-time flow on user query:
- The User provides a question via the RAG web application
- The RAG application generates a retrieval request initialized from the vector store (Elasticsearch index). At query time, the text will be embedded using the ELSER model and the resulting tokens will be used to perform a text expansion query.
- The Retriever component of RAG application fetches the relevant documents from Elasticsearch vector store.
- The RAG application passes the retrieved documents (context) along with user question (prompt) to the Cohere Command Model through Amazon Bedrock
- The Cohere Command Model through Amazon Bedrock generates a textual response and sends it back to RAG application
- The RAG application performs any required post processing tasks. For example, it adds source to the response generated from Cohere Command Model. The User views the response in the web application.
We used the following AWS and third-party services:
- Amazon Bedrock for interacting with LLMs from Cohere.
- Cohere Command Model for Text Generation.
- Elasticsearch for storing embeddings of the enterprise knowledge corpus and doing similarity search with user questions.
- Python, LangChain and Streamlit for building the RAG application
- Amazon EC2 for hosting the Streamlit application
- AWS Identity and Access Management roles and policies for access management.
Prerequisites:
- Sign up for a free trial of Elasticsearch cluster with Elastic Cloud
- Create a new deployment on AWS following the steps
- Reset and download the elastic user password following these steps
- Copy the Cloud ID from the My Deployment page listed under Deployments
- Deploy ELSER Model: In Kibana, navigate to Machine Learning> Trained models. ELSER can be found in the list of trained models. Click the Download model button under Actions. After the download is finished, start the deployment by clicking the Start deployment button. Go to the Elastic ELSER page to find more details.

- Install packages and import modules: Firstly, we need to install modules. Make sure python is installed with min version 3.8.1. Then we need to import modules.
- Initialize Amazon Bedrock client using the following code
- Connect to Elasticsearch using Elastic Cloud Id, Elastic username and Elastic password. Use ElasticsearchStore to connect to our elastic cloud deployment. As we’re using ELSER we use “SparseVectorRetrievalStrategy”. This strategy uses Elasticsearch’s sparse vector retrieval to retrieve the top-k results.
- Download the dataset, deserialize the document and split the document into passages. We’ll chunk the documents into passages in order to improve the retrieval specificity and to ensure that we can provide multiple passages within the context window of the final question answering prompt. Here we are chunking into 800 tokens with an overlap of 400 tokens. Here, we are using a simple splitter but LangChain offers more advanced splitters to reduce the chance of context being lost.
- Index data to Elasticsearch using ElasticsearchStore.from_documents.
- Initialize the Amazon Bedrock LLM. In the Amazon Bedrock instance, will pass bedrock_client and specific model_id. In this case model_id =
cohere.command-text-v14.
- Asking a question: Now that we have the passages stored in Elasticsearch and LLM is initialized, we can now ask a question to get the relevant passages.
- (Optional) You can also add a reranking step to the search pipeline which can further improve the ranking of the results returned in the search step. See the Deploying with Amazon SageMaker guide on using Rerank.
Conclusion
In this post, we showed how to create a RAG web application using a combination of Elasticsearch, Amazon Bedrock, Cohere Command Model and open source python packages like LangChain and Streamlit.
We encourage you to learn more by exploring Amazon SageMaker Jumpstart, Amazon Bedrock, Cohere, and Elasticsearch and building a solution using the sample implementation provided in this post and a dataset relevant to your business. If you have questions or suggestions, leave a comment.
Frequently Asked Questions
What is generative AI?
Generative AI is a type of Artificial Intelligence (AI) that can create new content and ideas, including conversations, stories, images, videos, and music. Like all AI, generative AI is powered by Machine Learning (ML) models—very large models that are pre-trained on vast corpora of data and commonly referred to as Foundation Models (FMs).
What are the limitations of Large Language Models (LLMs)?
LLMs have certain limitations. One notable constraint is that they are trained on general domain corpora, making them less effective on domain-specific tasks. Also, LLMs are trained offline until a knowledge cutoff date. It will be agnostic of any developments that have happened after the knowledge cutoff date. This may lead to inaccurate interpretations.
Related Content

July 7, 2026
Short queries, formal documents: how HyDE improved semantic search precision by 50% in Elasticsearch
HyDE boosts semantic search precision and recall by 50% on short queries. Here's how to implement it in Elasticsearch with the Inference API and semantic_text.

June 24, 2026
Elasticsearch DiskBBQ delivers 7x faster vector search than Qdrant on network-attached storage
Elasticsearch DiskBBQ achieves up to 7x higher vector search throughput than Qdrant at comparable recall on network-attached storage. Explore the benchmark methodology and full results.

July 6, 2026
Who grades the grader? LLM-as-a-Judge inside Elasticsearch Workflows
Find out if your RAG agent is ready to ship. Score it on correctness, faithfulness and retrieval quality using only Elasticsearch Workflows and two Claude models.

June 15, 2026
Your search index is already an agent memory system: Persistent agent memory for Claude Code with Elasticsearch
Give your AI agent persistent cross-session memory using Elasticsearch: Hybrid recall, a knowledge graph, and cross-device handoffs. Three commands to install.

June 15, 2026
Your FAQ bot doesn't need a PhD: LLM query routing with Elastic Workflows
Route LLM queries by complexity using Elasticsearch search metadata: Mistral Small for FAQ questions, Claude Sonnet for multi-source synthesis.