하이브리드 검색이란 무엇인가요?
두 개 이상의 검색 방법을 하나의 순위 목록으로.
하이브리드 검색은 두 개 이상의 검색 방법(예: 어휘 검색 및 시맨틱 검색)을 단일 순위 목록으로 결합하여 관련성과 재현율을 개선하는 정보 검색 기술입니다. 가장 일반적인 조합은 정확한 단어와 구문을 일치시키는 데 탁월한 풀텍스트 어휘 검색과 쿼리의 의미를 해석하는 시맨틱 벡터 검색입니다. 어휘 측면은 정밀도를 제공하고, 시맨틱 측면은 사용자의 기본 의도에 대한 깊은 이해를 제공합니다.
이러한 방법은 단일 쿼리에서 함께 실행되며, 그 결과는 전문 융합 전략을 사용하여 하나의 일관된 순위로 병합됩니다. 어휘 + 시맨틱 조합이 가장 흔하지만, 하이브리드 검색은 지리공간 + 시맨틱 검색 또는 텍스트 + 이미지 검색과 같은 다른 접근 방식과도 조합하여 다양한 요구 사항에 맞출 수 있습니다.
하이브리드 검색이 중요한 이유
하이브리드 검색은 개별 검색 방법의 약점을 완화하는 동시에 단일 파이프라인에서 각 방법의 강점을 활용합니다. 최신 AI는 다양한 모달리티, 텍스트, 이미지, 오디오, 로그 등을 처리하고 의도를 데이터로 연결해야 합니다. 관련성은 그 어느 때보다 중요해지고 있습니다. 예를 들어 이커머스에서 검색 환경은 사용자가 빠르게 결과를 필터링하고 구체화할 수 있도록 지원해야 성공할 수 있지만, AI 에이전트는 질문에 응답하거나 조치를 취하기 위해 관련성이 높은 하나의 답변이 필요한 경우가 많습니다. 이것이 바로 검색 기술을 혼합하고 최적화하는 역량이 오늘날 중요한 이유입니다. 이는 전통적인 검색 결과뿐만 아니라, 정확하면서도 데이터에 기반한 응답을 제공하는 대화형 에이전트를 지원합니다.
하이브리드 검색에 대해 더 자세히 알아보기 전에, 어휘(lexical) 검색과 시맨틱(semantic) 검색이 어떻게 다르고 왜 서로를 보완하는지 간단히 살펴보겠습니다.
어휘 검색이란
어휘 검색은 잘 구조화된 데이터가 있고 사용자가 찾고자 하는 내용을 알고 있을 때 이상적입니다. 정확한 용어를 일치시켜 매우 정확하고 설명하기 쉬우며, 정확도 점수 알고리즘(예: BM25F)을 사용해 쿼리 용어의 빈도 및 희귀도에 따라 문서 순위를 매깁니다. 이 방식은 투명한 점수 산정을 제공하며, 필드 부스트, 동의어, 분석기를 통해 세밀하게 조정된 관련성을 지원합니다. 모델 오버헤드가 없기 때문에 어휘 검색은 빠르고 효율적이며, 필터와 패싯은 속도 저하나 전체 인덱스 스캔 없이 대규모 환경에서도 안정적으로 작동합니다. 특히 구조화된 쿼리, 희귀 용어, 도메인 특화 언어에 효과적입니다.
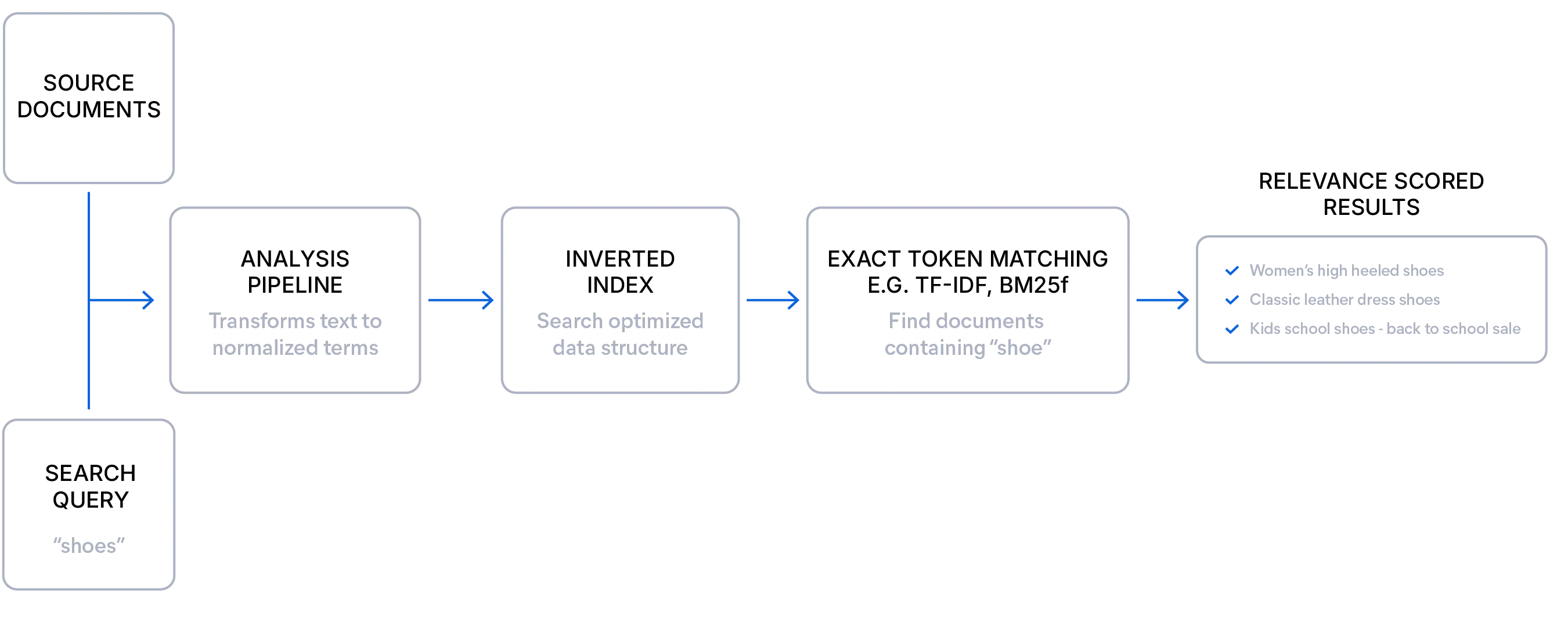
다음은 어휘 검색 쿼리의 간단한 예입니다.
GET example-index/_search
{
"query": {
"term": {
"text": "blue shoes"
}
}
}
Elasticsearch 쿼리 언어(ES|QL)를 사용한 어휘 검색의 유사한 예로 요리 블로그를 살펴보겠습니다. 이 블로그에는 텍스트 콘텐츠, 범주형 데이터, 숫자 등급 등 다양한 속성을 가진 레시피가 포함되어 있습니다.
FROM cooking_blog METADATA _score | WHERE description:"fluffy pancakes" | KEEP title, description, _score | SORT _score DESC | LIMIT 1000
이 쿼리는 description 필드에서 "fluffy" 또는 "pancakes"(또는 둘 다)가 포함된 문서를 검색합니다. 기본적으로 ES|QL은 검색어 간에 OR 논리를 사용하므로 지정된 단어가 포함된 문서와 일치합니다. KEEP 명령을 사용하여 결과에 포함할 필드를 정확히 지정하고 _score 메타데이터를 요청하여 검색 결과가 쿼리와 얼마나 잘 일치하는지에 따라 검색 결과의 순위를 매길 수 있습니다.
이 실습 튜토리얼을 통해 어휘 검색에 대해 자세히 알아보세요.
시맨틱 검색이란
시맨틱 검색은 어휘 검색처럼 정확한 단어만 일치시키는 것이 아니라 쿼리와 문서 간의 의미 유사성을 기반으로 결과를 검색합니다.
임베딩 모델은 텍스트나 기타 미디어의 의미를 벡터라는 수치적 표현으로 변환합니다. 이러한 벡터(숫자 목록)는 텍스트의 근본적인 맥락과 주제를 담아, Elasticsearch와 같은 벡터 데이터베이스에 저장됩니다.
이를 통해 검색 엔진은 쿼리와 정확히 일치하는 단어가 없는 경우에도 개념적으로 유사한 결과를 찾을 수 있습니다.
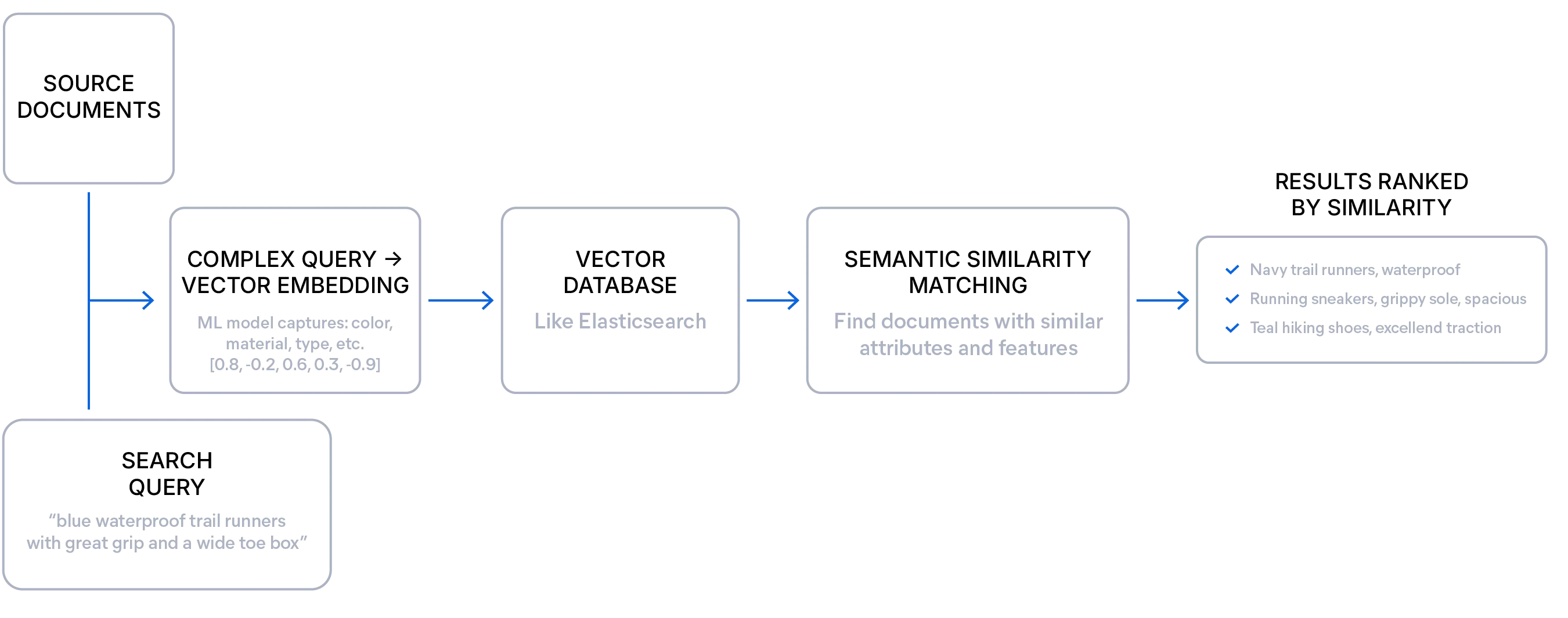
이 접근 방식은 비정형 데이터, 탐색적 쿼리, 그리고 사용자가 정확한 용어를 모르는 경우에 특히 유용합니다. 개발자는 시맨틱 검색을 활용하여 더 관련성 높은 결과를 제공하고, 모호하거나 장황하거나 애매한 표현을 처리하면서도 정확한 답변을 보여줄 수 있습니다.
다음은 시맨틱 검색 쿼리의 예입니다.
GET example-index/_search
{
"query": {
"semantic": {
"field": "inference_field",
"query": "blue waterproof trail runners with great grip and a wide toe box"
}
}
}
ES|QL은 매핑에 semantic_text 유형의 필드가 포함된 경우 시맨틱 검색을 지원합니다. 추론 엔드포인트에서 실행 중인 기본 모델에 의해 문서가 처리되면 시맨틱 검색을 수행할 수 있습니다. 다음은 semantic_description 필드에 대한 자연어 쿼리 예시입니다.
FROM cooking_blog METADATA _score | WHERE semantic_description:"What are some easy to prepare but nutritious plant-based meals?" | SORT _score DESC | LIMIT 5
시맨틱 검색에 대해 자세히 알아보거나 이 실습 튜토리얼을 통해 더 깊이 알아보세요.
어휘 알고리즘(예: BM25F)은 쿼리 용어가 문서 용어와 일치할 때 정밀도가 뛰어나지만 관련 콘텐츠가 다르게 표현되면 실패합니다. (예를 들어, "athletic footwear(운동화)"에 대한 쿼리는 "shoes(신발)"나 "trail runner(트레일화)"만 언급된 문서를 놓칠 수 있습니다.) 시맨틱 벡터 검색은 고차원 임베딩과 근사 최인접 이웃(ANN) 알고리즘(예: HNSW)을 사용하여 정확한 용어 중복 여부와 관계없이 개념적으로 유사한 문서를 검색합니다. 그러나 문맥이 모호한 경우 노이즈가 발생할 수 있습니다.
하이브리드 검색이 작동하는 방식
두 가지 장점을 모두 활용할 수 있다면 어떨까요? 이제 하이브리드 검색을 살펴보겠습니다. 제대로 활용하면 하이브리드 검색은 각 검색 방식의 단순 합을 뛰어넘어, 어휘 검색이나 시맨틱 검색만 사용하는 것보다 훨씬 우수한 결과를 제공합니다. 하이브리드 방식은 균형 잡힌 관련성, 향상된 정규화 할인 누적 이득(NDCG), 그리고 추가 검색 시스템 없이도 더 높은 재현율을 제공합니다.
다음은 하이브리드 검색 쿼리의 예입니다.
GET example-index/_search
{
"retriever": {
"rrf": {
"retrievers": [
{
"standard": {
"query": {
"term": {
"description": "shoes"
}
}
}
},
{
"knn": {
"field": "vector",
"query_vector": [1.25, 2, 3.5],
"k": 50,
"num_candidates": 100
}
}
],
"rank_constant": 20,
"rank_window_size": 50
}
}
}
ES|QL에서는 풀텍스트와 시맨틱 쿼리를 결합할 수도 있습니다. 이 예시에서는 풀텍스트 검색과 시맨틱 검색을 커스텀 가중치와 함께 결합합니다.
FROM my-index METADATA _score
| FORK ( WHERE match(text_field:"shoes") | SORT _score DESC | LIMIT 50)
( WHERE knn(vector, [1.25, 2, 3.5], { "min_candidates" : 100 }) | SORT _score DESC | LIMIT 50 ) // k for knn is derived from LIMIT
| FUSE RRF WITH { "rank_constant": 20 }
| SORT _score DESC
| LIMIT 50
하이브리드 검색 쿼리를 실행하려면 일반적으로 적어도 하나의 어휘 검색과 하나의 시맨틱 검색을 실행한 다음 그 결과를 결합해야 합니다. 주요 과제는 여러 개의 순위 목록을 하나의 일관된 순위로 병합하는 것입니다.
BM25F 또는 TF-IDF와 같은 알고리즘으로 생성되는 어휘 검색 점수는 제한이 없을 수 있으며, 최대값은 용어 빈도와 문서 분포에 따라 달라질 수 있습니다. 대조적으로, 시맨틱 점수는 일반적으로 유사성 함수에 의해 결정되는 고정된 범위 내에 있습니다(예: 코사인 유사성의 경우 [0, 2]).
이들을 병합하려면 검색된 문서의 상대적 관련성을 유지하는 융합 방법이 필요합니다.
Elasticsearch를 사용한 하이브리드 검색
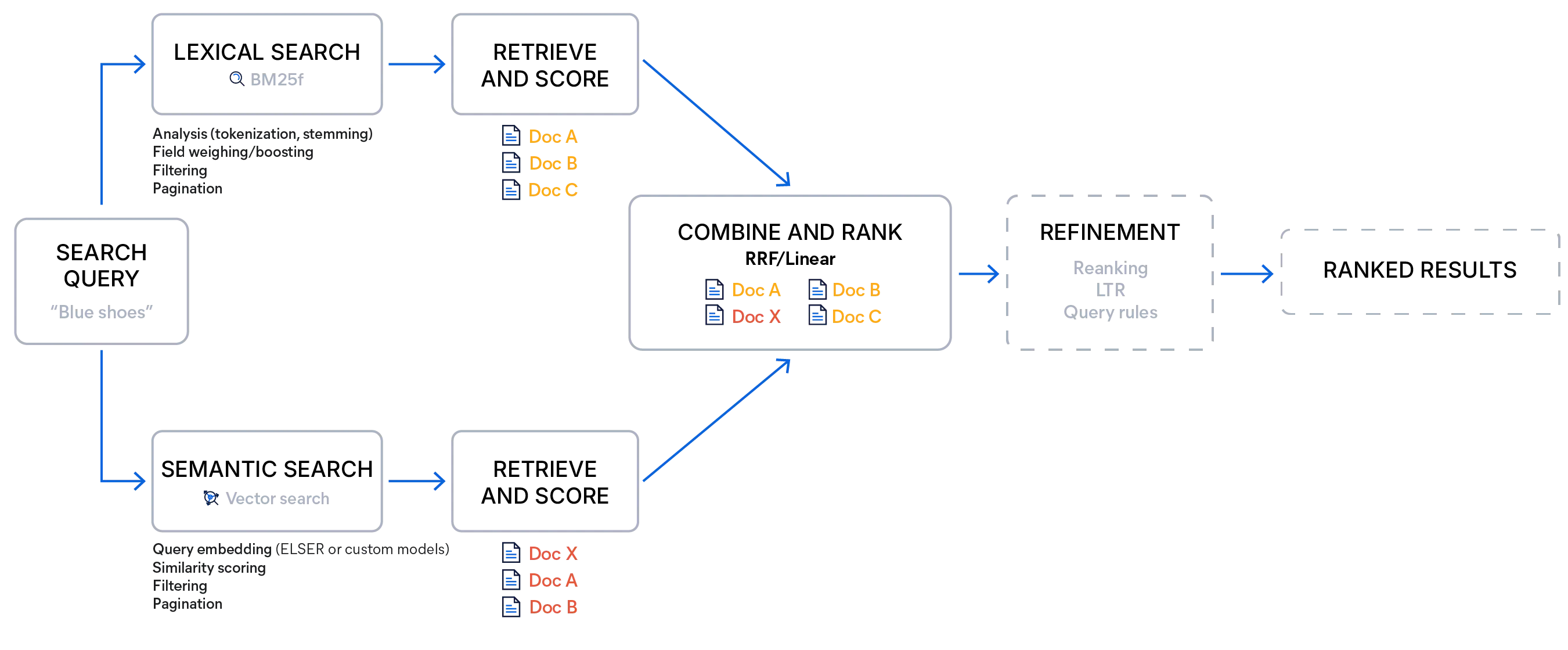
Elasticsearch를 이용한 하이브리드 검색은 표준 키워드 쿼리와 벡터 쿼리를 결합하거나, 검색기를 사용하여 구현할 수 있습니다. 검색기는 여러 종류의 쿼리를 실행하고, 선택한 점수화 방법을 사용해 결과를 하나의 순위 목록으로 통합하는 검색 옵션입니다. 이를 통해 결과를 결합하기 위한 여러 요청이나 추가 클라이언트 측 로직 없이도, 단일 검색 호출로 다단계 검색 파이프라인을 실행할 수 있습니다.
Elasticsearch는 상호 순위 결합(RRF)과 선형 결합(종종 API에서 선형 검색기로 불림)이라는 두 가지 내장 융합 방법을 제공합니다. 두 방법 모두 각 검색기의 강점을 보존하는 통합 순위를 만드는 것을 목표로 하지만, 점수를 처리하는 방식과 효과적으로 작동하는 상황에서는 차이가 있습니다.
상호 순위 결합은 원시 점수를 완전히 무시하고 각 목록에서 문서가 얼마나 높은 순위에 나타나는지에 초점을 맞춥니다. 목록 상위에 위치한 문서는 강력한 보상을 받으며, 여러 목록에 나타나는 문서는 추가 부스트를 받습니다. 이 방법이 강력한 이유는 호환되지 않는 점수 범위의 문제를 회피하고, 순위 상수 이외에는 거의 조정이 필요하지 않으며, 자연스럽게 상위 결과의 다양성을 촉진하기 때문입니다.
RRF는 다음 공식을 사용하여 결과 집합의 순위에 따라 문서에 점수를 매기며, 여기서 k 는 낮은 순위의 문서의 중요성을 조정하기 위한 임의의 상수입니다.
![]()
RRF는 검색기가 상위 결과에서 일부 중복을 보일 때, 그리고 개발자가 레이블이 지정된 학습 데이터나 복잡한 보정 없이 바로 사용할 수 있는 솔루션을 필요로 할 때 특히 유용합니다.
반면, 선형 결합은 각 검색기의 실제 점수를 직접 병합합니다. 어휘 및 시맨틱 점수는 매우 다른 범위에서 작동하기 때문에, 선형은 점수를 비교 가능한 범위로 가져오기 위해 최소-최대 스케일링과 같은 정규화가 필요합니다.
정규화되면 각 검색기의 상대적 중요성을 나타내는 가중치를 사용하여 점수가 혼합됩니다. 가중치가 1보다 크면 검색기의 영향력이 증가하고, 1보다 작으면 감소합니다.
이러한 접근 방식을 통해 세밀한 제어가 가능합니다. 개발자는 키워드 정밀도가 중요할 때 BM25F를 강조하고, 의도와 컨텍스트가 중요할 때 시맨틱 유사성을 중심으로 기울이거나, 검색 점수와 함께 추가적인 비즈니스 또는 개인화 신호를 통합할 수 있습니다. 가중치가 신중하게 보정되면 선형 결합은 더 정확하고 예측 가능한 순위를 생성함으로써 RRF를 능가할 수 있지만, 실험이 필요하고 데이터 세트별 튜닝에 민감합니다.
선형 결합은 각 가중치와 β(이 경우, 0 ≤α, β)를 사용해, 어휘 검색 결과와 시맨틱 검색 결과를 다음과 같이 결합합니다.
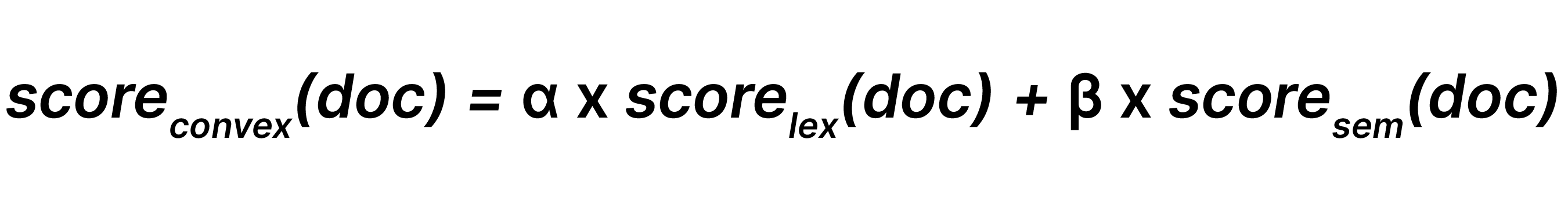
실제로, RRF는 단순성과 점수 척도 불일치에 대한 복원력 덕분에 하이브리드 검색을 위한 최적의 출발점입니다. 많은 튜닝 없이도 강력한 결과를 얻을 수 있어 프로토타입 제작이나 검색기가 겹치는 경우에 이상적입니다. 선형 결합은 서로 다른 검색 방법이 배타적인 결과를 반환할 때나 어휘·시맨틱·외부 신호를 신중하게 균형 있게 조정할 필요가 있을 때 더 적합합니다. 간단히 말해, RRF는 즉시 사용 가능한 빠르고 신뢰할 수 있는 하이브리드화를 제공하는 반면, 선형 결합은 애플리케이션과 데이터에 맞게 가중치와 정규화 매개변수가 조정되면 더 높은 정확도를 달성할 수 있습니다.
요약하면 다음과 같습니다.
| 상호 순위 결합 | 선형 결합 |
|---|---|
강력한 하이브리드 결과를 빠르게 얻으려면 RRF로 시작하세요. |
관련성을 미세 조정할 준비가 되면 선형으로 전환하세요. |
요약하자면, 선형 결합은 조정 시 더 높은 잠재적 정확도를 제공하며, RRF는 구현이 더 쉽고 레이블이 지정된 학습 데이터 없이도 잘 작동합니다.
하이브리드 검색에 대해 자세히 알아보려면 이 튜토리얼을 참조하세요.
하이브리드 검색의 작동 방식
- 어휘 검색: BM25F는 쿼리 용어를 인덱싱된 토큰과 대조하여 일치시킵니다. 이는 정밀도, 구조화된 필터, 설명 가능한 점수 매기기에 적합합니다.
- 시맨틱 검색: 벡터(밀집형 또는 희소형)는 텍스트의 의미를 나타내며, 유사도 검색은 공유된 단어가 없어도 관련 콘텐츠를 찾아줍니다.
- 융합: 점수를 RRF, 가중치 혼합 또는 선형 검색기와 결합합니다. 필터와 부스트는 두 검색 모두에 일관되게 적용됩니다.
| 검색 유형 | 작동 방식 | 처리 결과 | 적합한 경우 |
|---|---|---|---|
| 어휘 검색 쿼리: "red running shoes size 10" | 쿼리의 정확한 단어를 문서 내 단어(BM25F, TF-IDF, 분석기, 동의어)와 일치시킵니다. | 제목/설명에서 해당 토큰이 포함된 제품을 찾습니다(예: "Nike Men's Red Running Shoes, Size 10"). | 쇼핑객은 자신이 원하는 것을 정확히 알고 있습니다. 정확하고, 설명 가능하며, 효율적입니다. |
| 시맨틱 검색 쿼리: "lightweight shoes for jogging" | 키워드뿐 아니라 의미와 문맥을 포착하기 위해 임베딩을 사용합니다. 용어가 일치하지 않더라도 개념적으로 관련된 결과를 찾습니다. | "lightweight"와 "jogging"이라는 단어가 정확히 포함되지 않았더라도 "Adidas Cloudfoam Running Sneakers, Size 10"을 반환합니다. | 쇼핑객은 의도를 설명하거나 자연어를 사용합니다. 모호하거나 서술적인 쿼리도 처리할 수 있습니다. |
| 하이브리드 검색 쿼리: "comfortable dress shoes for office" | 어휘 검색과 시맨틱 결과를 결합한 후, 순위를 융합합니다(예: RRF를 사용). | 정확히 일치하는 항목(예: "Black Leather Dress Shoes, Comfort Fit")과 의미적으로 관련된 항목(예: "Loafers with cushioned insoles")을 검색합니다. 두 항목 모두 관련성에 따라 순위를 매겨 함께 표시합니다. | 쿼리에는 정확한 단어와 의도가 혼합되어 있습니다. 정확성과 탐색 모두를 균형 있게 제공합니다. |
하이브리드 검색 속 밀집 벡터와 희소 벡터 이해하기
Elasticsearch의 시맨틱 검색은 쿼리와 문서를 의미를 포착하는 벡터 표현으로 변환하는 방식으로 작동합니다. 하이브리드 검색은 밀집 모델이든 희소 모델이든 상관없이, 어휘 검색과 시맨틱 검색을 결합합니다.
밀집 벡터
밀집 벡터는 BERT와 같은 모델에서 생성되는 고정 길이의 숫자 배열로, 유사한 입력(예: 고양이와 새끼 고양이)이 벡터 공간에서 서로 가까이 나타나며 의미 매칭, 추천, 유사성 검색에 강력하게 활용됩니다.
텍스트가 밀집 벡터로 임베딩되면 다음과 같이 나타납니다.
[ 0.13586345314979553, -0.6291824579238892, 0.32779985666275024, 0.36690405011177063, ... ]
각 차원에는 의미 있는 정보가 포함되어 있어, 벡터가 데이터로 가득 차 있습니다. 유사한 콘텐츠는 벡터 공간에서 서로 가까운 임베딩을 생성합니다.
Elasticsearch에서 밀집 벡터는 dense_vector 필드에 저장되고 HNSW와 같은 근사 최인접 이웃(ANN) 알고리즘으로 쿼리됩니다. 이는 텍스트, 이미지 등 콘텐츠의 전반적인 시맨틱 의미를 포착하는 데 이상적입니다.
POST my-index/_search
{
"retriever": {
"rrf": {
"retrievers": [
{
"standard": {
"query": {
"match": {
"text_field": "fox"
}
}
}
},
{
"knn": {
"field": "title_vector",
"query_vector": [0.1, 3.2, 2.1],
"k": 5,
"num_candidates": 100
}
}
]
}
}
}
다음은 ES|QL 예시입니다.
FROM my-index METADATA _score
| FORK ( WHERE match(text_field:"fox") | SORT _score DESC | LIMIT 5)
( WHERE knn(image_vector, [0.1, 3.2, 2.1], { "min_candidates" : 100 }) | SORT _score DESC | LIMIT 5 )
| FUSE
| SORT _score DESC위에서 볼 수 있듯이, 하이브리드 검색 쿼리는 rrf 검색기를 활용하여 표준 검색기로 만든 어휘 검색 쿼리(예: 매치 쿼리)와 knn 검색기에서 지정된 벡터 검색 쿼리를 결합합니다. 이 쿼리는 먼저 글로벌 레벨에서 상위 5개의 벡터 매치를 검색한 다음, 이를 어휘 매치와 결합한 뒤, 마지막으로 가장 잘 일치하는 10개의 결과를 반환합니다. rrf 검색기는 벡터 매치와 어휘 매치를 결합하기 위해 RRF 순위 방식을 사용합니다.
희소 벡터와 ELSER 이해하기
밀집 임베딩은 시맨틱 검색을 수행하는 유일한 방법이 아닙니다.
희소 벡터는 대부분 0으로 이루어져 있고 해석 가능한 용어와 연결된 몇 개의 가중치 값을 포함하므로, 자원 효율적이고 설명 가능하며 제로샷 시나리오에서 효과적입니다.
희소 벡터 표현은 다음과 같습니다:
{"f1":1.2,"f2":0.3,… }
Elasticsearch에서, Elastic Learned Sparse EncodeR(ELSER)는 도메인 외 희소 자연어 처리(NLP) 모델로, 텍스트를 의미론적으로 관련 용어로 확장하고 가중치를 할당하여 정확한 키워드를 넘어서는 매칭을 가능하게 하면서 해석 가능성을 유지합니다.
또한 semantic_text 필드는 인제스트 시 임베딩 생성 및 추론을 자동으로 처리하여 기존 텍스트 검색처럼 시맨틱 검색을 손쉽게 만들어 줍니다. 문서를 텍스트 필드처럼 인덱싱하고 간단한 매치 쿼리를 실행하면, 필드 유형이 다른 인덱스 간에서도 추가 쿼리 로직 없이 어휘 일치와 시맨틱 일치를 모두 얻을 수 있습니다. 고급 제어가 필요할 경우, 동일한 필드에서 knn 또는 sparse_vector 쿼리를 사용하세요.
ELSER 예시
- 약 30,000개 용어 어휘에 대해 사전 학습
- sparse_vector로 저장(용어/가중치 쌍)
- semantic_text를 사용한 인제스트 시 또는 추론 인제스트 프로세서를 사용한 인덱스 시 자동 생성
- 역방향 인덱스(어휘 검색과 유사)를 통해 쿼리되며, 효율적이고 필터 친화적이며 설명 가능함
POST my-index/_search
{
"retriever": {
"rrf": {
"retrievers": [
{
"standard": {
"query": {
"match": {
"text_field": "fox"
}
}
}
},
{
"standard": {
"query": {
"sparse_vector": {
"field": "ml.tokens",
"inference_id": ".elser_model_1",
"query": "a quick brown fox jumps over a lazy dog"
}
}
}
}
]
}
}
}
밀집 벡터와 희소 벡터는 함께 유연성을 제공합니다. 밀집 벡터는 미묘한 의미를 포착하는 데 우수하며, 희소 벡터는 실제 검색에 필요한 투명성과 확장성을 제공합니다.
ELSER를 사용한 텍스트 확장이 어떻게 향상된 결과를 얻는 데 도움이 되는지 확인해 보세요.
희소 vs. 밀집 벡터 실무 비교
| 희소 벡터(ELSER) | 밀집 벡터 | |
|---|---|---|
| 작동 방식 | 텍스트를 의미론적으로 관련된 가중치가 있는 용어로 확장합니다. 각 차원은 가중치가 부여된 토큰에 해당합니다. | 콘텐츠(텍스트, 이미지 등)를 고정 길이 부동 소수점 벡터로 인코딩합니다. 유사한 의미는 벡터 공간 내 근접한 위치를 의미합니다. |
| 강점 |
|
|
| 예시 사용 사례 |
|
|
| 적합한 경우 | 시맨틱 개선과 투명성이 필요하거나, 도메인 특정 용어가 가장 중요할 때 | 다양한 데이터 유형에서 정확한 단어가 아닌 의미를 기반으로 탐색과 유사성을 원할 때 |
밀집 모델과 희소 모델을 사용한 하이브리드 검색
지금까지 밀집 벡터 공간과 희소 벡터 공간에 따라 수행되는 하이브리드 검색의 두 가지 방법을 살펴보았습니다. 동일한 인덱스 내에서 밀집 데이터와 희소 데이터를 모두 혼합하여 사용할 수도 있습니다.
POST my-index/_search
{
"_source": false,
"fields": [ "text_field" ],
"retriever": {
"rrf": {
"retrievers": [
{
"knn": {
"field": "image_vector",
"query_vector": [0.1, 3.2, ..., 2.1],
"k": 5,
"num_candidates": 100
}
},
{
"standard": {
"query": {
"sparse_vector": {
"field": "ml.tokens",
"inference_id": ".elser_model_1",
"query": "a quick brown fox jumps over a lazy dog"
}
}
}
}
]
}
}
}
심화 탐구: 밀집, 희소, BM25F를 활용한 하이브리드 검색
다음 예시는 세 개의 검색기를 결합하고, RRF를 통해 각각의 순위 목록을 융합합니다.
- BM25F (match on text): 정확한 키워드/구문 일치("snowy mountain")
- kNN (image_vector): 제공된 이미지 임베딩을 사용한 시각적 유사성(num_candidates 중 k 결과 반환)
- 시맨틱 (semantic_text): 쿼리의 시맨틱 확장을 통한 개념적 일치
rank_window_size는 융합되는 결과의 수를 제어하고, rank_constant는 각 목록의 기여도를 균형 있게 조정합니다.
GET my-index/_search
{
"retriever": {
"rrf": {
"retrievers": [
{
"standard": {
"query": {
"match": {
"text": {
"query": "snowy mountain"
}
}
}
}
},
{
"knn": {
"field": "image_vector",
"query_vector": [
0.01,
0.3,
-0.4
],
"k": 10,
"num_candidates": 100
}
},
{
"standard": {
"query": {
"semantic": {
"field": "semantic_text",
"query": "snowy mountain"
}
}
}
}
],
"rank_window_size": 50,
"rank_constant": 60
}
}
}
ES|QL에서의 비슷한 사례도 확인해 보겠습니다.
FROM my-index METADATA _score
| FORK (WHERE match(text, "snowy mountain") | SORT _score DESC | LIMIT 50)
(WHERE knn(image_vector, [0.01, 0.3, -0.4], {"min_candidates": 100 }) | SORT _score DESC | LIMIT 50)
(WHERE match(semantic_text, "snowy mountain") | SORT _score DESC | LIMIT 50)
| FUSE RRF WITH {"rank_constant": 60 } // 60 is the default anyway?
| SORT _score DESC
| LIMIT 50결론
하이브리드 검색은 풀텍스트 검색의 정밀도와 시맨틱 검색의 문맥적 범위를 결합하여, 다양한 콘텐츠에서 보다 정확하고 관련성 높은 결과를 제공합니다. 밀집 모델과 희소 모델을 모두 지원하고 선형 결합 및 상호 순위 결합과 같은 유연한 융합 방법을 제공함으로써, 쿼리와 벡터를 직접 페어링하거나 검색기로 다단계 검색을 간소화하는 등 사용 사례에 맞게 검색을 맞춤화할 수 있습니다. 이러한 유연성 덕분에 하이브리드 검색은 복잡한 쿼리, 다양한 데이터 유형, 높은 관련성 요구 사항을 다루는 강력한 접근 방식이 됩니다.
하이브리드 검색 자세히 알아보기:
- 이 블로그에서 하이브리드 검색이 무엇인지와 Elasticsearch가 지원하는 쿼리 유형 및 이를 구축하는 방법을 알아보세요.
- 컨텍스트 — 하이브리드 검색과 컨텍스트 엔지니어링의 진화
- ES|QL에서의 하이브리드 검색 및 다단계 검색
- 두통 없는 하이브리드 검색: 검색기를 이용한 하이브리드 검색 간소화
벡터 이상의 기능을 원하신다면, Elasticsearch의 LLM 에이전트를 활용한 지능형 하이브리드 검색을 확인해 보세요.
실습을 해보고 싶다면, 하이브리드 검색 튜토리얼을 따라 풀텍스트와 kNN 결과를 결합하거나, ES|QL 튜토리얼을 통해 ES|QL로 검색하고 필터링해 보세요.