NLPをデプロイする方法:センチメント分析の例


 Share on Twitter
Share on TwitterTwitter

 Share on LinkedIn
Share on LinkedInリンクトイン

 Share on Facebook
Share on FacebookFacebook

 Share by Email
Share by Emailメール

 Print this page
Print this page印刷
自然言語処理(NLP)のブログシリーズの一部として、センチメント分析NLPモデルを使用して、コメント(テキスト)フィールドに肯定的な感情または否定的な感情が含まれているかどうかを評価する例を紹介します。公開モデルを使用して、そのモデルをElasticsearchにデプロイし、インジェストパイプラインでそのモデルを使用して、顧客のレビューを肯定的または否定的に分類する方法を説明します。
センチメント分析は一種のバイナリ分類であり、フィールドにある値または別の値があることが予測されます。一般的に、0~1の範囲の予測の確率スコアがあり、スコアが1に近いほど、予測の信頼度が高いことを示します。このタイプのNLP分析は、製品レビューや顧客フィードバックなどのさまざまなデータセットに有効に適用できます。
分類する顧客レビューは、2015 Yelp Dataset Challengeの公開データセットにあります。Yelp Reviewサイトから照合されたデータセットは、センチメント分析に最適なリソースです。この例では、共通センチメント分析NLPモデルを使用してYelpレビューデータセットのサンプルを評価し、モデルを使用してコメントに肯定的または否定的のラベルを設定します。そして、肯定的なレビューと否定的なレビューの割合を見つけたいと思います。
センチメント分析モデルをElasticsearchにデプロイする
docker run -it --rm elastic/eland \
eland_import_hub_model \
--url $ELASTICSEARCH_URL \
--hub-model-id distilbert-base-uncased-finetuned-sst-2-english \
--task-type text_classification \
--start
今回は--task-typeをtext_classificationに設定し、--startオプションをElandスクリプトに渡します。これにより、Model Management UIを起動せずに自動でモデルをデプロイすることが可能になります。
デプロイが完了したら、Kibanaコンソールでこれらの例を試します。
POST _ml/trained_models/distilbert-base-uncased-finetuned-sst-2-english/deployment/_infer
{
"docs": [
{
"text_field": "The movie was awesome!"
}
]
}
次のような結果が表示されます。
{
"predicted_value" : "POSITIVE",
"prediction_probability" : 0.9998643924765398
}
次の例も試すことができます。
POST _ml/trained_models/distilbert-base-uncased-finetuned-sst-2-english/deployment/_infer
{
"docs": [
{
"text_field": "The cat was sick on the bed"
}
]
}
猫とシートを清掃する人の両方に強く否定的な反応が生成されます。
{
"predicted_value" : "NEGATIVE",
"prediction_probability" : 0.9992468477843378
}
Yelpレビューを分析する
導入部で説明したように、Hugging Faceで提供されているYelpレビューのサブセットを使用します。これには手動でセンチメントがマークアップされています。これにより、結果をマークアップされたインデックスと比較できます。Kibanaのファイルアップロード機能を使用して、推論プロセッサーで処理するためのこのデータセットのサンプルをアップロードします。
前回のブログ記事でも紹介したように、インジェストパイプラインの作成はKibanaのコンソールで行うことができます。今回はセンチメント分析用なので、sentimentという名前にしました。レビューはreviewという名前のフィールドにあります。前回の記事同様に、field_mapを定義することにより、モデルが期待するフィールドにreviewをマッピングします。NERパイプラインからの同じon_failureハンドラーが設定されます。
PUT _ingest/pipeline/sentiment
{
"processors": [
{
"inference": {
"model_id": "distilbert-base-uncased-finetuned-sst-2-english",
"field_map": {
"review": "text_field"
}
}
}
],
"on_failure": [
{
"set": {
"description": "Index document to 'failed-<index>'",
"field": "_index",
"value": "failed-{{{_index}}}"
}
},
{
"set": {
"description": "Set error message",
"field": "ingest.failure",
"value": "{{_ingest.on_failure_message}}"
}
}
]
}
レビュードキュメントはElasticsearchインデックスyelp-reviewsに格納されます。再インデックスAPIを使用して、センチメント分析パイプライン経由でレビューデータをプッシュします。再インデックスではすべてのドキュメントを処理、および推論するため、ある程度時間がかかります。この点を考慮し、APIでwait_for_completion=falseフラグを呼び出すことにより、再インデックスをバックグラウンドで実行します。タスク管理APIで進行状況を確認します。
POST _reindex?wait_for_completion=false
{
"source": {
"index": "yelp-reviews"
},
"dest": {
"index": "yelp-reviews-with-sentiment",
"pipeline": "sentiment"
}
}
上記のスクリプトを実行すると、1つのタスクIDが返されます。次のスクリプトを使うと、そのタスクの進捗を監視できます。
The above returns a task id. We can monitor progress of the task with:
別の方法として、model stats UIでInference countの増加を確認して進捗を追跡することも可能です。

この時点で、再インデックスされたドキュメントに推論の結果が含まれています。サンプルとして1つ分析されたドキュメントを開くと、次のようになります。
{
"review": "The food is good. Unfortunately the service is very hit or miss. The main issue seems to be with the kitchen, the waiters and waitresses are often very apologetic for the long waits and it's pretty obvious that some of them avoid the tables after taking the initial order to avoid hearing complaints.",
"ml": {
"inference": {
"predicted_value": "NEGATIVE",
"prediction_probability": 0.9985209630712552,
"model_id": "distilbert-base-uncased-finetuned-sst-2-english"
}
},
"timestamp": "2022-02-02T15:10:38.195345345Z"
}
予測された値はNEGATIVEで、低品質のサービスには合理的な値です。
否定的なレビュー数を視覚化する
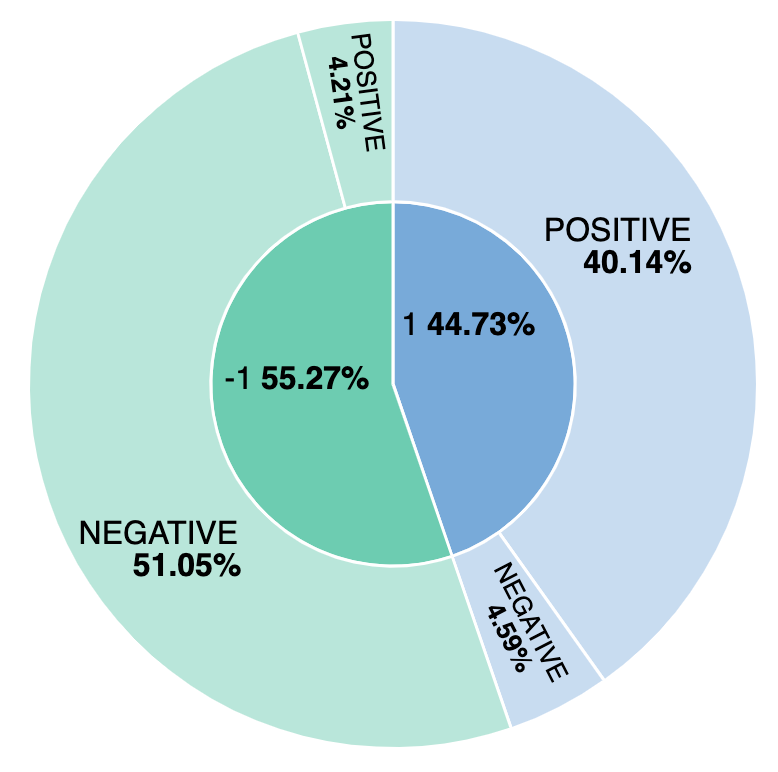
否定的なレビューの割合はどのくらいか。モデルはどのように手動でラベルが付けられた感情と比較したのか。それでは、シンプルなビジュアライゼーションを作成し、モデルと手動の肯定的なレビューと否定的なレビューを追跡してみましょう。ml.inference.predicted_value fieldに基づいてビジュアライゼーションを作成すると、比較を報告し、約44%のレビューが肯定的であると見なされ、そのうちの4.59%がセンチメント分析モデルから誤ったラベルが付けられていることがわかります。
試してみよう
NLPに関するその他の記事はこちらをご覧ください。
- NLPのテキスト埋め込みとベクトル検索をデプロイする方法
- 固有表現抽出(NER)をデプロイする方法の例
- 自然言語処理(NLP)をデプロイする方法:Getting started(自然言語処理をデプロイする ― はじめに)
シェアする
- Share on Twitter
Twitter
- Share on LinkedIn
リンクトイン
- Share on Facebook
Facebook
- Share by Email
メール
- Print this page
印刷