Elasticでコレクター銀行のイノベーションを推進
Splunkの代替となるソリューションをお探しですか?SplunkからElasticのソリューションに移行するメリットをご確認ください。オブザーバビリティとセキュリティデータを単一のプラットフォームに統合し、総合的なコストと管理者の手間を削減できます。
コレクター銀行は北欧でデジタルバンキングサービスの牽引役となっています。そして直近3年間、この銀行の高いサービス品質に最も貢献してきた技術がElasticsearchです。このブログ記事では、私たちがElastic Stackを取り入れた経緯と、Microsoft Azure Cloudのアーキテクチャーに関するインサイト、そしてElastic Cloud Enterprise(ECE)へ移行した理由をご紹介したいと思います。
背景
コレクター銀行は設立から18年を迎え、現在5か国、400万人の利用者と多数の法人顧客に送金ソリューションを提供しています。個人の利用者に低金利の貸し出し、高金利の預金サービスを行うほか、ファクタリング(売掛債権買取)などのBtoBサービスも手掛けます。今年秋には多数のサードパーティーソリューションを統合した革新的な銀行アプリもリリースする予定です。
テクノロジーという観点で、コレクター銀行はフィンテック企業がパブリッククラウドを使用する試みの最前線にいます。この3年、私たちはあらゆるタイプの新製品とサービスをMicrosoft Azure Cloudに構築してきました。たとえば、ローンや貯蓄口座向けの新たなバンキングシステムや、提携パートナー向けの決済ソリューションの構築などです。したがって、Elasticsearchを活用するインフラもすべてAzure仕様になっています。
導入への道のり
3年前、コレクター銀行のシステムは決済ソリューション、ファクタリング、個人ローンを網羅する巨大なものになっていました。自社構築部分はオンライン決済システムだけで、他のシステムはすべて購入したものです。当時、システムの大部分でアプリケーションログはファイルに書き出されており、そこにアクセスして検索できるエンジニアの数はごくわずかでした。結果として、非常に効率の悪い開発プロセスとなっていたのです。
Splunkもインストールしましたが、1つのシステムでしか使用されませんでした。私とチームは他のソリューションを検討し、Elasticsearchならあらゆるファイルとリレーショナルデータベースのログソリューションとして使用でき、大きなメリットを得られると判断しました。そして実際に、Elasticsearchの導入に踏み切りました。まず多数のマイクロサービスを構築し、システム間でログを検索、関連付けできるようにしました。コレクター銀行のアーキテクチャーとワークフローにおいて、これが大きな転換点となりました。その後社内のチームが次々にElastic Stackを使ったロギングや、Kibanaによる可視化を行うようになり、短期間に高水準のサービス提供を実現したのです。
ソリューション導入後
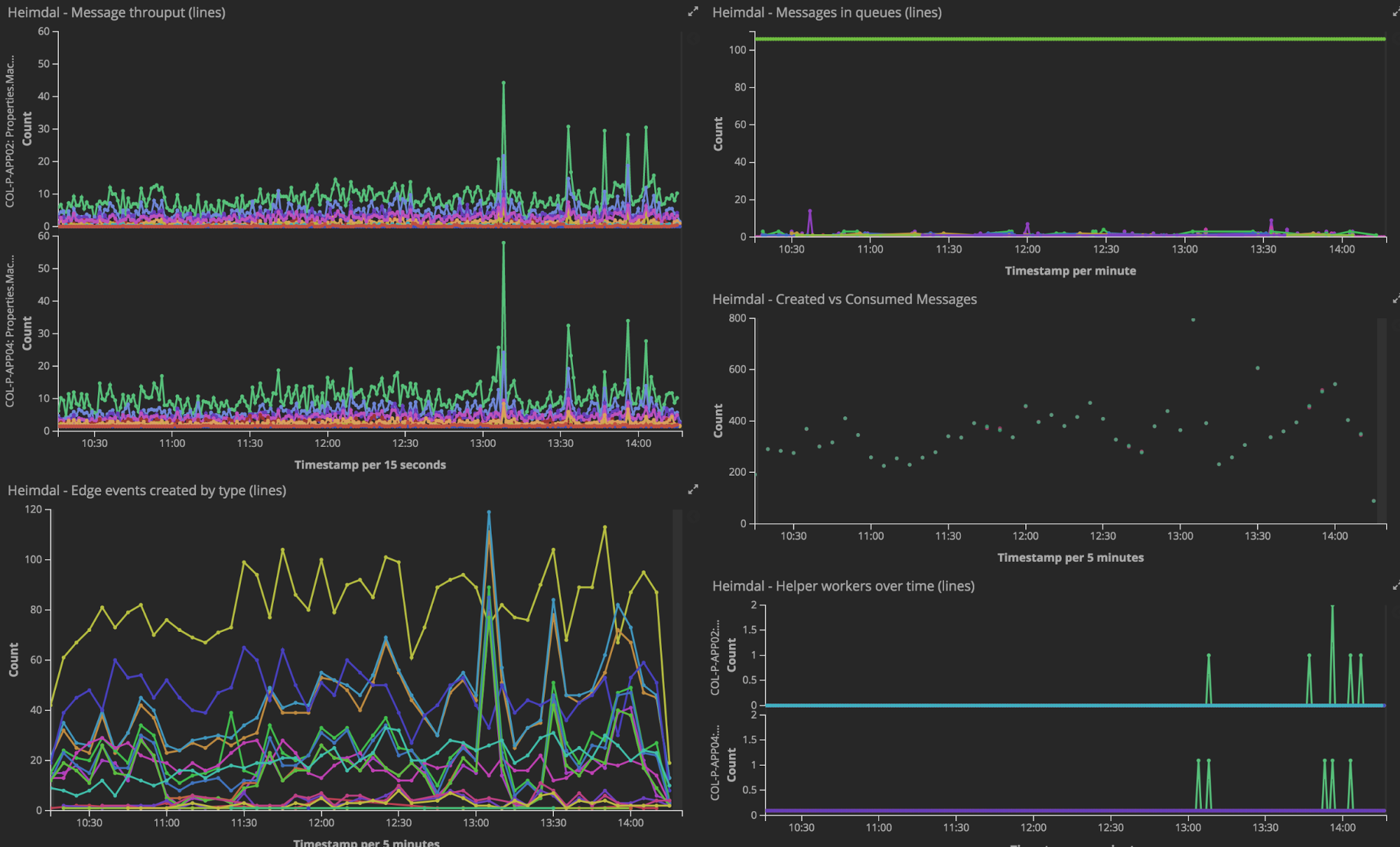
現在コレクター銀行にはソフトウェア開発を手掛けるチームが18あります。オフィスを見渡すと、各チームに1つ以上の大型ディスプレイがあり、Kibanaのダッシュボードがシステムの稼働状況を表示しています。アラートと監視も導入していますが、リアルタイムの状況が見えるとモチベーションが高まります。たとえば決済やシステムに問題が生じれば、監視や通知で即座に問題を把握できます。社内ではPagerDutyやSlackのようなDevOpsツールがよく使われており、何か問題がある時やパートナーとの統合作業を行う時も、連絡はまずSlackです。それでも、ディスプレイで状況を可視化しておくことでチームの士気が上がり、完了した作業のバリューを実感することができます。先週は、これまでにサービスを使用した顧客の数を表示してみました。
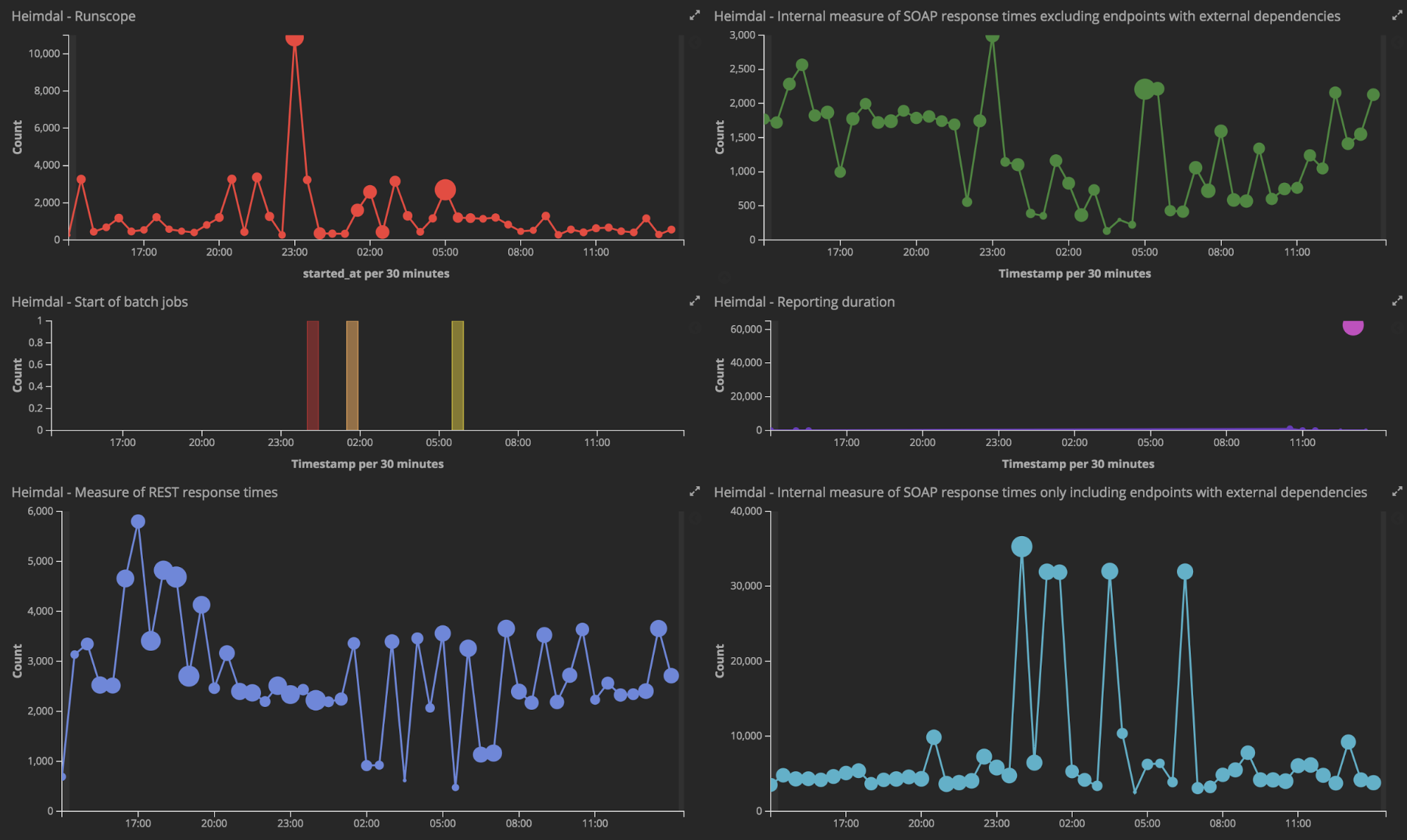
Azureアーキテクチャー
コレクター銀行では大部分のサービスをC#で構築し、Azure Web Appsにデプロイしています。メインのログフレームワークにはSerilogを使用しています(Githubで一部を公開中)。
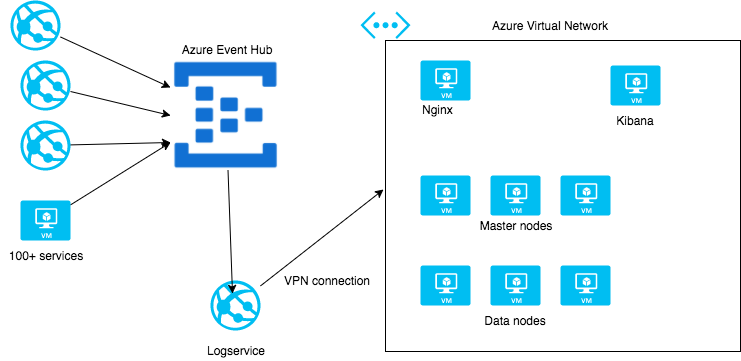
すべてのサービスログはAzure Event Hubに出力されますが、これは、Azure Event Hubが何百万ものイベント処理に耐えられる設計だからです。多くの企業ではRedisやKafkaを使っています。これらの3つのサービスはすべてキャッシュとして振る舞いますが、Azure Event HubはIaaSであることがメリットです。ホスティングの心配が要りません。イベントハブから読み込むというのは、VPNで接続されたAzureの仮想ネットワークのAzure Webジョブとしてはやや難しいのですが、私たちはそこにElasticsearchクラスターを稼働させています。
導入時の課題
多数のチームが膨大な量のログを出力する一方、ロギングに定まったフォーマットはありませんでした。そして発覚したのは、一部のログがインデックスされていないという問題です。原因は、1つのフィールドを異なる種類のデータで使用していたことでした。Aというチームがjson { \"field\" : 1 }をインデックスしようとしても、Bというチームが{\"field\" : \"one\" }と送信した場合、ドキュメントはインデックスされません。しかも、どちらのチームも変更する気はありません。双方のチームの中ではその形式で扱うことが最も適切だからです。さらにもう1つ、私たちは、他のチームに対して「Elasticsearchでスキーマを減らせる」という売り文句は使えないという事実にも直面しました。そう単純ではなかったのです。
ソリューション
そこで私たちはデータパイプライン(この場合はserilog sink)で、すべてのフィールドにサフィックスを加えることにしました。先ほどの例で説明すると、Aチームは以前と同じようにログを取得していますが、Elasticsearchには{\"field_i\" : 1}として届き、Bチームからは{\"field_s\" : \"one\"}が届けられます。詳しい方法はGitHubのrepoに掲載しています。
Elastic Stackのメリットと今後
現在、私たちはElastic Cloud Enterprise(ECE)GAのインストールを微調整しています。これはベータ1となり、並列で実行する設定です。ECEの良い点は、ホスティングの状況をあまり心配する必要がなく、ひたすらElasticsearchをいじって楽しめることです。また、各チームがテストや開発用にクラスターを持つこともできます。プラチナレベルのサブスクリプション機能がすべて含まれることも大きなポイントです。RESTでの暗号化、フィールドとドキュメントレベルのセキュリティ、カスタムrealm、監査ログなどもサポートされます。2018年から施行されるGDPRのセキュリティ要件への対応では、これらの機能が重要になります。将来的には、不正検知のためのElasticsearch 機械学習も導入予定です。オンライン購入の膨大なログがあり、機械学習が異常の特定に役立つはずです。
先日、紙の書式を使用しているすべての書類のデジタルアーカイブを実装しました。数百万枚の書類を夏中かけてスキャンし、今はElasticsearchで簡単に検索、アクセスできるようになりました。

2年半前にコレクター銀行に入社。新しいテクノロジーをこよなく愛し、Elastic Stack使用歴は5年。開発者、アーキテクトとしてキャリアを積む以前に基礎工学修士を取得しているほか、プロのポーカープレイヤーとして6年活動していた。