Customize indexing for a content source
editCustomize indexing for a content source
editEach content source has indexing rules that determine what data is synchronized to Workplace Search. Each content source also has an indexing schedule that determines when data is synchronized to Workplace Search. Both the indexing rules and synchronization schedule can be configured individually for any standard source. This customization does not apply to custom content sources.
Customizing indexing relies on the Workplace Search API. The steps in these guides assume that you are familiar with authenticating to the API. The examples on this page use bearer tokens.
If you create or update indexing rules for an existing content source, the new rules may exclude documents that have already been indexed. This occurs when full or incremental syncs encounter the document again on a subsequent run, triggering a deletion of that document.
Indexing rules
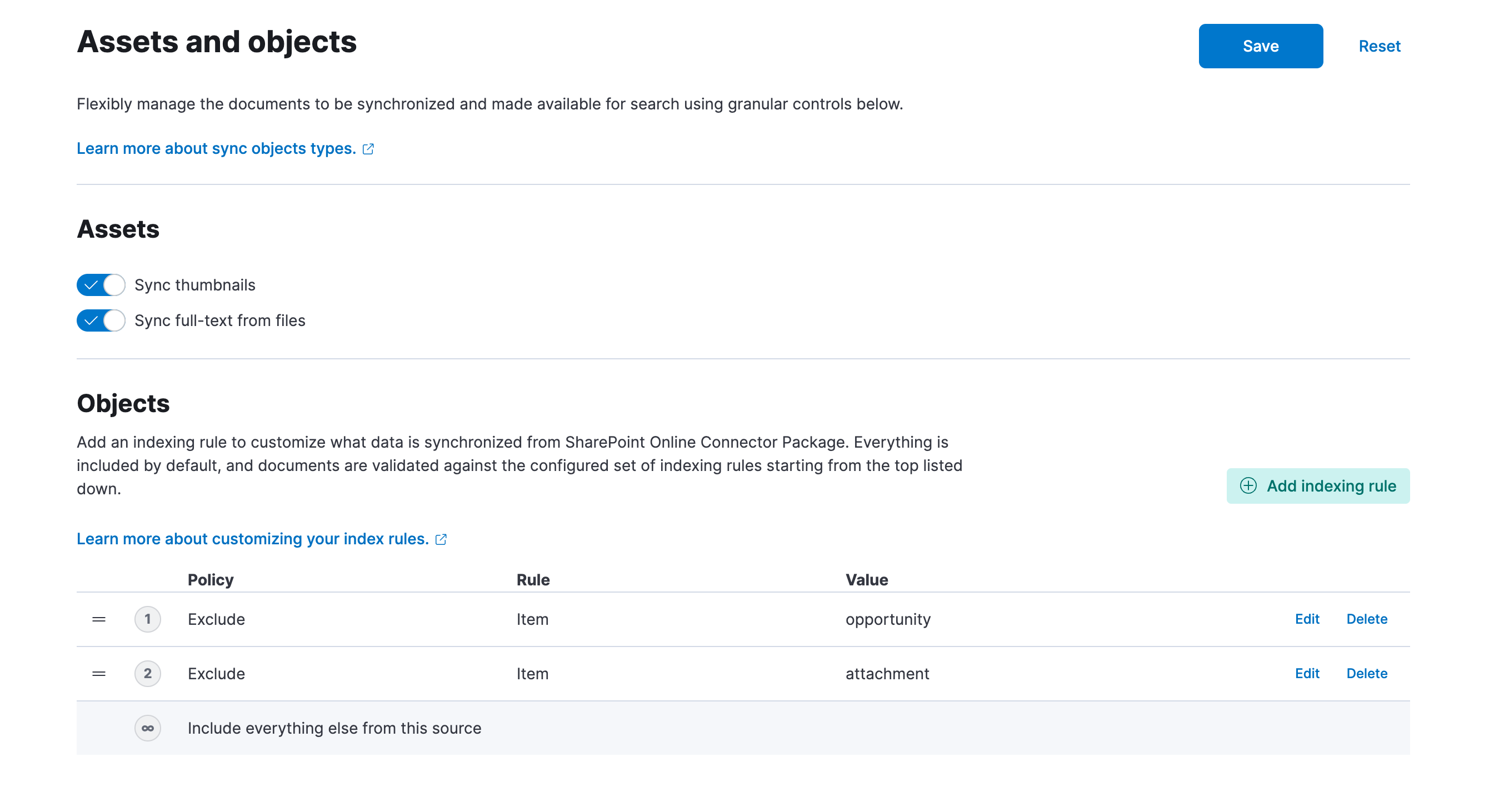
editIndexing rules can be configured for each content source. You may be able to use custom indexing rules to speed up content source synchronization and decrease storage costs. You can also exclude content that shouldn’t be processed, such as binary files.
Indexing rules apply at the time of full source synchronization. This means that they will only take effect when the content from a source is re-synchronized. Changing indexing rules automatically triggers a synchronization process, but this process might take some time, especially when dealing with content sources that have large sets of documents.
Indexing rules are evaluated in order. Any object is evaluated against each rule in order, and the first rule it matches will be applied to it. This means that if the first rule excludes a file, that file will be excluded from indexing even if later rules include it. Similarly, if the first rule includes a file that file will be included even if later rules exclude it.
In this guide, you will see how to change the indexing rules on a content source. Here are some examples of sources that support custom indexing rules:
The examples in this guide use a Dropbox content source.
A more concise and technical API reference can be found at Content sources API reference.
Modify the indexing rules on a content source
editThese steps assume you have already connected a source. Here we will modify the indexing rules on a Dropbox source to exclude content from a top-level folder named Legal.
Step 1. First, we need to locate the content source in Kibana, and open the Assets and objects page. From the administrative dashboard, navigate to Sources:
From here, open the Dropbox content source by clicking on Details, then click on Synchronization in the sidebar and open the Assets and objects page.
Step 2. Next, we need to identify the filter rule we wish to use when indexing documents. If we assume our Dropbox documents exist at the following paths:
/employee-directory.pdf /Documentation/enabling-saml-auth.pdf /Documentation/customizing-content-sources.pdf /Legal/clients-list.xls /Legal/Contracts/business.docx
If we want to exclude every document contained in the top-level Legal folder, we can use a pattern like:
/Legal/**/*
This pattern is created using glob patterns.
Step 3. We can then use the table at the bottom of the page to build an indexing configuration to filter out our Legal documents. Click Add indexing rule, set the Policy to Exclude, the Rule to Path and the Value to /Legal/**/*. Click Save in the table to add the rule to the indexing configuration.
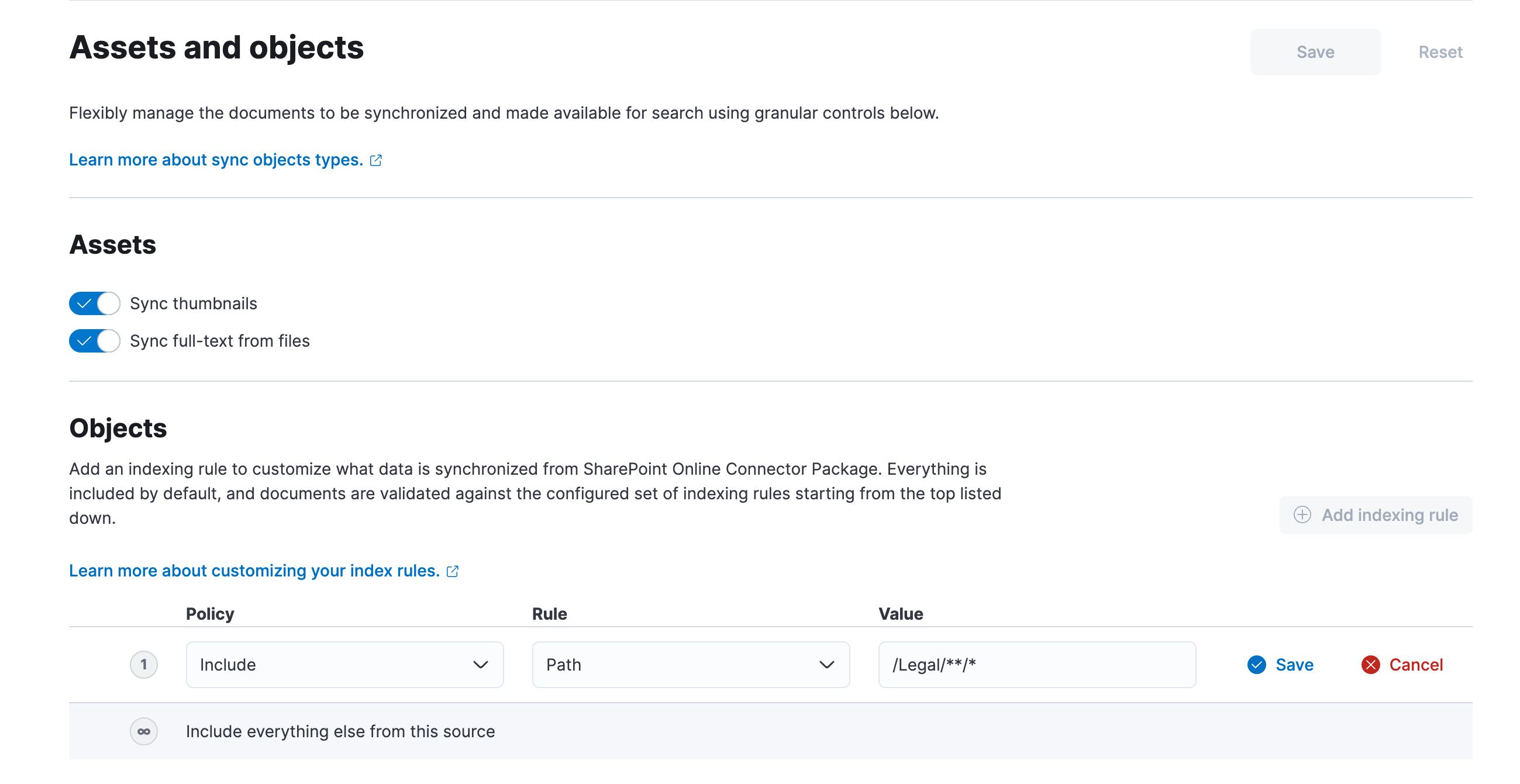
Note that the new indexing rule configuration won’t be saved until you click the Save button at the top of the page. You can do so now.
Disabling Sync thumbnails and Sync full-text from files prevents future syncing of these assets, but it does not remove previously synced assets.
Step 4. Modifying a content source’s indexing configuration will trigger a full synchronization of the source’s data. When complete, we should see that no documents from the top-level Legal folder were indexed into Workplace Search.
Additional examples
editUsing the above steps, here are some additional examples of indexing configurations for other use cases.
Revert indexing configuration to default
To revert a source’s indexing configuration back to the default state, you can remove all rules. The default rule will always stay in place, as all files that don’t fit a rule are automatically included in indexing.
Include only specific sub-directories
For file system based sources, rather than excluding content, perhaps you only want to index content within a specific set of directories. Note that rules are evaluated in order, which allows a complex mixture of include and exclude rules. This example will index all content in the Engineering and Design top-level folders, however the Templates folder within Design will also be excluded:
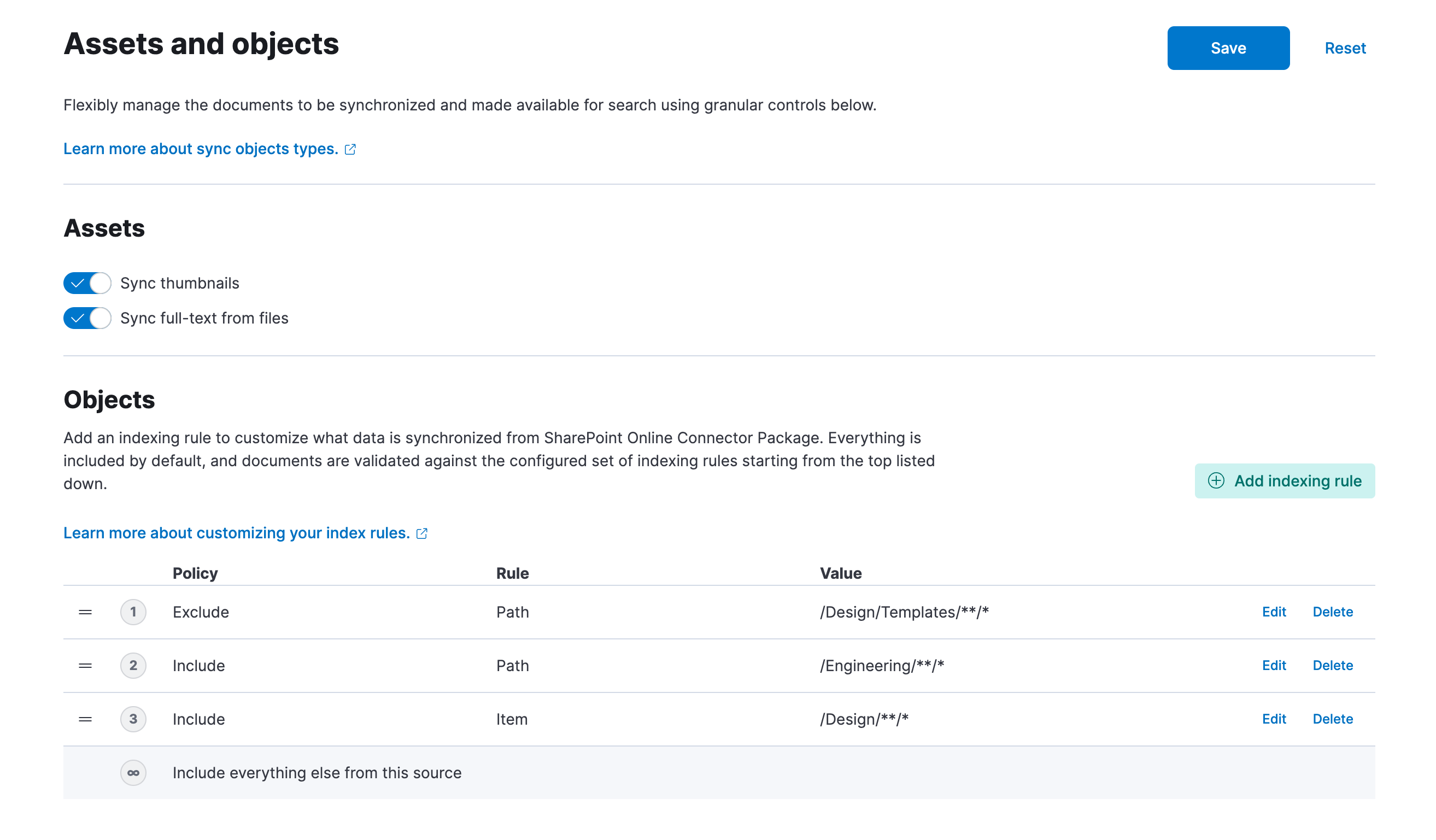
Rules can easily be reordered by dragging them within the table. You will need to click Save at the top of the page to store your changes and trigger a full synchronization.
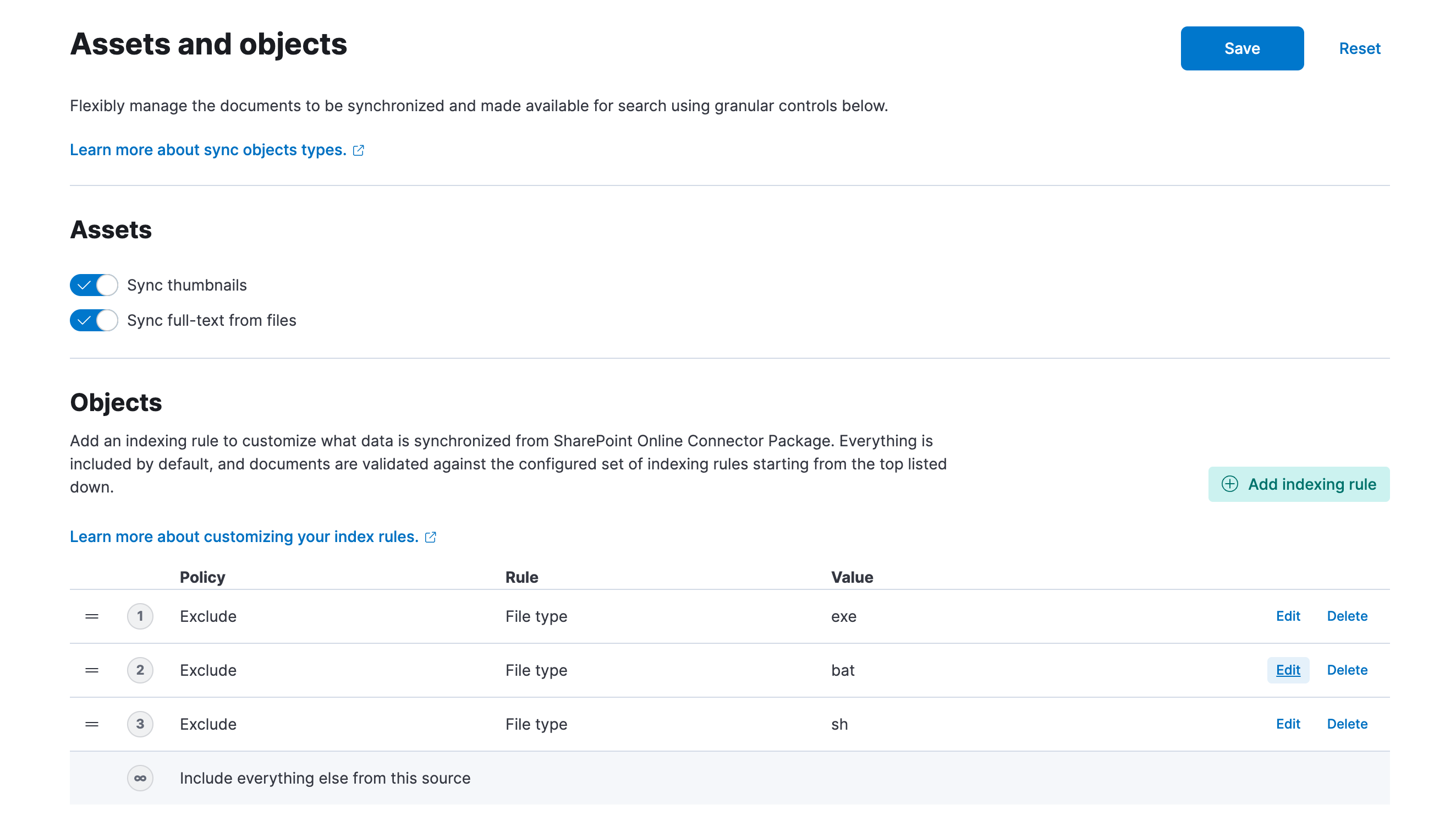
Exclude specific file extensions
This configuration will exclude some common executable file types:
Exclude specific object types
This configuration will exclude some specific object types. Which object types you can exclude or include will depend on your content source. This is particularly useful for content sources that sync in a variety of document types, like Salesforce:
Indexing schedule
editThis feature is not available for all Elastic subscription levels. Refer to the subscriptions pages for Elastic Cloud and Elastic Stack. To change your subscription level or start a trial, see Subscriptions and features.
The schedule that determines when data is synchronized to Workplace Search can be configured for each content source. You can configure a schedule that synchronizes less frequently, to lower the burden on a third-party server, or you can synchronize more frequently to ensure your data is up-to-date. You can also configure windows of time when synchronization should not be performed. This can allow you to perform operations such as scheduled maintenance in a third-party system that Workplace Search connects to.
Synchronization jobs
editFull sync (runs every 72 hours by default): This synchronization job synchronizes all of the data from the content source ensuring full data parity.
Incremental sync (runs every 2 hours by default): This synchronization job synchronizes updates to the data at the content source ensuring high data freshness.
Deletion sync (runs every 6 hours by default): This synchronization job synchronizes document deletions from the content source ensuring regular removal of stale data.
Permissions sync (runs every 5 minutes by default, when Document Level Permissions are enabled): This synchronization job synchronizes document permissions from the content sources ensuring secure access to documents on Workplace Search.
Only one sync job of a given type for a given content source can run at a time. For example, if a Salesforce content source takes longer than the default of 3 days to run, Workplace Search will not spawn another full sync job for Salesforce until the existing full sync has completed.
Each sync job type for a given content source can run independently. For example, if a full sync job is in progress for Salesforce, an incremental sync can run at the same time as the full sync. This allows us to prioritize recently updated data while still allowing older data to be synced.
A more concise and technical API reference can be found at Content sources API reference.
Modify the indexing schedule on a content source
editThese steps assume you have already connected a source. Here we will modify the schedule of a Dropbox content source to run incremental indexing every one hour, instead of the default two hours.
Step 1. First, we need to retrieve the source’s ID and definition. We’ll retrieve it from the API with the following curl command:
curl \ --request "GET" \ --url "<ENTERPRISE_SEARCH_BASE_URL>/api/ws/v1/sources" \ --header "Authorization: Bearer ${TOKEN}"
Which gives us a response of:
{
"meta": { ... },
"results":
[
{
"id": "60de02d9a1c4934b6efe24dc",
"service_type": "dropbox",
"name": "Dropbox",
...
}
]
}
In the above response data, the source we’re looking for has an ID of 60de02d9a1c4934b6efe24dc. You can find name values in the source definitions to help identify which source you’re looking for.
Step 2. Next, we need to fetch the current configuration for the content source.
curl \ --request "GET" \ --url "<ENTERPRISE_SEARCH_BASE_URL>/api/ws/v1/sources/60de02d9a1c4934b6efe24dc" \ --header "Authorization: Bearer ${TOKEN}"
Which gives us a response of:
{
"id": "60de02d9a1c4934b6efe24dc",
"service_type": "dropbox",
"name": "Dropbox",
...
"indexing": {
...
"schedule": {
"full": "P3D",
"incremental": "PT2H",
"delete": "PT6H",
"estimates": {
"full": {
"next_start": "2021-08-09T04:45:48Z",
"duration": "PT20S"
},
"incremental": {
"next_start": "2021-08-06T06:45:48Z",
"duration": "PT3S"
},
"delete": {
"next_start": "2021-08-06T10:45:48Z",
"duration": "PT11S"
}
}
}
},
...
}
Step 3. We can then use the source definition from the previous step to modify the indexing schedule.
We will modify the incremental duration specified in the indexing schedule to be PT1H.
This is an ISO 8601 Duration that indicates "every one hour".
We will pass our new configuration as our --data content:
curl \ --request "PUT" \ --url "<ENTERPRISE_SEARCH_BASE_URL>/api/ws/v1/sources/60de02d9a1c4934b6efe24dc" \ --header "Authorization: Bearer ${TOKEN}" \ --header "Content-Type: application/json" \ --data ' { "id": "60de02d9a1c4934b6efe24dc", "service_type": "dropbox", "name": "Dropbox", "is_searchable": true, ... "indexing": { ... "schedule": { "full": "P3D", "incremental": "PT1H", "delete": "PT6H" } }, ... } '
After this request returns, the new schedule will be active.
Configuring global indexing schedule
editYou can also configure the global defaults for scheduling that apply to all content sources. Note that any overrides configured for a content source, using the method above, will take precedence.
To modify the schedule for incremental jobs to be one hour by default, update your Enterprise Search configuration file to contain:
workplace_search.content_source.sync.refresh_interval: full: PT72H incremental: PT1H delete: PT6H permissions: PT6M