Qu'est-ce que le Model Context Protocol (MCP) ?
Pourquoi le MCP a-t-il été créé ? La nécessité d'une couche d'intégration standard
Le Model Context Protocol (MCP) a été développé pour relever un défi essentiel dans la conception d'applications d'IA agentiques : permettre aux grands modèles de langage (LLM) isolés d'interagir avec le monde extérieur. Si les grands modèles de langage (LLM) sont par nature de puissants moteurs de raisonnement, leurs connaissances sont statiques en raison de la date limite de leur entraînement. Ils ne peuvent donc pas nativement accéder à des données en temps réel ni exécuter des actions dans des systèmes externes.
La connexion des grands modèles de langage (LLM) à des systèmes externes s'effectuait jusqu'à présent au moyen d'intégrations API directes et personnalisées. Bien qu'efficace, cette approche exigeait de chaque développeur qu'il apprenne l'API spécifique de chaque outil, qu'il écrive le code nécessaire pour traiter les requêtes et analyser les résultats, et qu'il assure la maintenance de cette connexion. Face à la multiplication des applications d'IA et des outils disponibles, une méthode plus standardisée et efficace s'imposait.
Le MCP fournit ce protocole standardisé, s'inspirant de normes éprouvées telles que REST pour les services Web et le Language Server Protocol (LSP) pour les outils de développement. Au lieu d'obliger chaque développeur d'applications à maîtriser l'API de chaque outil, le MCP établit un langage commun pour cette couche de connectivité.
Cette approche crée une séparation claire des responsabilités. Les fournisseurs de plateformes et d'outils peuvent ainsi exposer leurs services via un serveur MCP unique et réutilisable, intrinsèquement compatible avec le LLM. La responsabilité de la maintenance de l'intégration peut alors être transférée du développeur d'applications d'IA au propriétaire du système externe. Résultat : un écosystème robuste et interopérable où toute application compatible peut se connecter à n'importe quel outil compatible, simplifiant considérablement le développement et la maintenance.

Comment fonctionne le MCP : l'architecture de base
Architecture MCP
Le MCP fonctionne selon un modèle client-serveur conçu pour connecter un moteur de raisonnement (le LLM) à un ensemble de capacités externes. L'architecture part du LLM et dévoile progressivement les composants qui lui permettent d'interagir avec le monde extérieur.
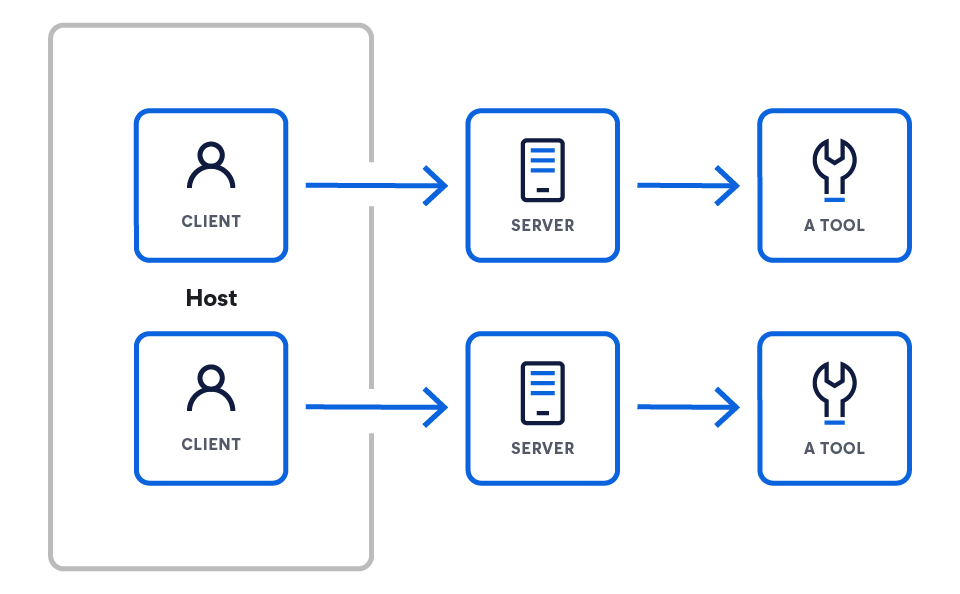
Cette architecture comprend trois composants principaux :
- Les hôtes sont des applications LLM qui souhaitent accéder aux données via MCP (par exemple, Claude Desktop, IDE, agents IA).
- Les serveurs sont des programmes légers qui exposent chacun des fonctionnalités spécifiques via le MCP.
- Les clients assurent la maintenance de connexions 1:1 avec les serveurs, au sein de l'application hôte.
Clients ou hôtes MCP

Les clients ou hôtes MCP sont des applications qui orchestrent l'interaction entre les LLM et un ou plusieurs serveurs MCP. Le client est essentiel ; il contient la logique spécifique à l'application. Si les serveurs fournissent les capacités brutes, c'est au client qu'il incombe de les utiliser. Pour ce faire, il recourt aux fonctionnalités suivantes :
- Assemblage du prompt : collecter du contexte à partir de divers serveurs pour construire le prompt final et efficace pour le LLM
- Gestion de l'état : conserver l'historique des conversations et le contexte utilisateur à travers plusieurs interactions
- Orchestration : déterminer quels serveurs interroger pour obtenir quelles informations et exécuter la logique lorsqu'un LLM décide d'utiliser un outil
Les clients MCP se connectent aux serveurs via des requêtes réseau standard (généralement HTTPS) vers un point de terminaison serveur connu. La force du protocole est de standardiser le contrat de communication entre eux. Le protocole lui-même est indépendant du langage de programmation et utilise un format basé sur JSON. Ainsi, tout client, quel que soit le langage dans lequel il est développé, peut communiquer correctement avec n'importe quel serveur.
Exemples de clients tirés de la spécification MCP
Serveurs MCP
Un serveur MCP est un programme backend qui sert d'interface standardisée pour une source de données ou un outil spécifique. Il implémente la spécification MCP afin d'exposer des fonctionnalités sur le réseau, telles que des outils exécutables ou des ressources de données. Concrètement, il traduit le protocole unique d'un service donné (comme une requête de base de données ou une API REST tierce) dans le langage commun du MCP, le rendant ainsi compréhensible par n'importe client MCP.
Exemples de serveurs tirés de la spécification MCP
Exercice pratique : Comment créer votre premier serveur MCP ?
Prenons l'exemple d'un serveur exposant des outils (nous examinerons ces outils plus loin). Ce serveur doit traiter deux requêtes principales du client :
- Installez le SDK.
# Python pip install mcp # Node.js npm install @modelcontextprotocol/sdk # Or explore the specification git clone https://github.com/modelcontextprotocol/specification
- Créez votre premier serveur.
from mcp.server.fastmcp import FastMCP import asyncio mcp = FastMCP("weather-server") @mcp.tool() async def get_weather(city: str) -> str: """Get weather for a city.""" return f"Weather in {city}: Sunny, 72°F" if __name__ == "__main__": mcp.run() - Connectez-vous à Claude Desktop.
{ "mcpServers": { "weather": { "command": "python", "args": ["/full/path/to/weather_server.py"], "env": {} } } }
SDK et ressources officiels
Vous pouvez commencer à créer vos propres clients et serveurs MCP à l'aide des SDK officiels et open source :
Outils MCP
Un outil est une fonctionnalité exécutable spécifique qu'un serveur MCP expose à un client. Contrairement aux ressources de données passives (comme un fichier ou un document), les outils représentent des actions que le LLM peut décider d'effectuer, telles que l'envoi d'un e-mail, la création d'un ticket de projet ou l'interrogation d'une base de données en temps réel.
Les outils interagissent avec les serveurs de la manière suivante : un serveur MCP déclare les outils qu'il propose. Par exemple, un serveur Elastic peut exposer un outil "list_indices", en définissant son nom, son objectif et les paramètres requis (par ex. "list_indices", "get_mappings", "get_shards" et "search").
Le client se connecte au serveur et découvre ces outils disponibles. Le client présente les outils disponibles au LLM dans le cadre du prompt ou du contexte système. Lorsque la sortie du LLM indique une intention d'utiliser un outil, le client l'analyse et envoie une requête formelle au serveur approprié pour exécuter cet outil avec les paramètres spécifiés.
Exemple de schémas d'outils tiré de la spécification MCP
Exercice pratique : Implémentation d'un serveur MCP de bas niveau
Si cet exemple de bas niveau est utile pour comprendre les mécanismes du protocole, la plupart des développeurs utilisent un SDK officiel pour créer des serveurs. Les SDK gèrent les éléments standard du protocole (comme l'analyse des messages et le routage des requêtes), ce qui vous permet de vous concentrer sur la logique principale de vos outils.
L'exemple suivant utilise le SDK Python MCP officiel pour créer un serveur simple qui expose un outil get_current_time. Cette approche est nettement plus concise et explicite que l'implémentation de bas niveau.
import asyncio
import datetime
from typing import AsyncIterator
from mcp.server import (
MCPServer,
Tool,
tool,
)
# --- Implémentation de l'outil ---
# Le décorateur @tool du SDK gère l'enregistrement et la génération de schéma.
# Nous définissons une fonction asynchrone simple qui sera exposée en tant qu'outil MCP.
@tool
async def get_current_time() -> AsyncIterator[str]:
"""
Renvoie l'heure et la date UTC actuelles sous forme de chaîne ISO 8601.
Ce docstring est automatiquement utilisé comme description de l'outil pour le LLM.
"""
# Le SDK attend un itérateur asynchrone, nous générons donc le résultat.
yield datetime.datetime.now(datetime.timezone.utc).isoformat()
# --- Définition du serveur ---
# Nous créons une instance du serveur MCP en lui transmettant les outils que nous voulons exposer.
# Le SDK découvre automatiquement toutes les fonctions décorées avec @tool.
SERVER = MCPServer(
tools=[
# Le SDK détecte automatiquement notre fonction décorée.
Tool.from_callable(get_current_time),
],
)
# --- Bloc d'exécution principal ---
# Le SDK fournit un point d'entrée principal pour exécuter le serveur.
# Ceci gère toute la logique de communication sous-jacente (stdio, HTTP, etc.).
async def main() -> None:
"""Exécute le serveur d'outils simple."""
await SERVER.run()
if __name__ == "__main__":
asyncio.run(main())
Cet exemple pratique démontre la puissance de l'utilisation d'un SDK pour créer des serveurs MCP :
- @tool decorator : ce décorateur enregistre automatiquement la fonction get_current_time en tant qu'outil MCP. Il inspecte la signature et le docstring de la fonction pour générer le schéma et la description nécessaires pour le protocole, ce qui vous évite de les écrire manuellement.
- MCPServer instance : la classe MCPServer est au cœur du SDK. Il vous suffit de lui fournir une liste des outils que vous souhaitez exposer, et il s'occupe du reste.
- SERVER.exécution() : cette commande unique démarre le serveur et gère toutes les communications de bas niveau, y compris la gestion des différents modes de transport comme stdio ou HTTP.
Comme vous pouvez le voir, le SDK fait abstraction de presque toute la complexité du protocole, vous permettant de définir des outils puissants avec seulement quelques lignes de code Python.
Les 3 primitives de base
Le MCP standardise la façon dont un LLM interagit avec le monde extérieur en définissant trois primitives de base qu'un serveur peut exposer. Ces primitives fournissent un système complet qui permet de connecter les LLM à des fonctionnalités externes.
- Ressources : fournir un contexte
- Fonction : accès aux données
- Analogie : points de terminaison GET
- Les ressources sont le principal mécanisme permettant de fournir du contexte à un LLM. Elles représentent des sources de données que le modèle peut récupérer et utiliser pour éclairer ses réponses, comme des documents, des enregistrements de base de données ou les résultats d'une requête de recherche. Il s'agit généralement d'opérations en lecture seule.
- Outils : effectuer des actions
- Fonction : actions et calcul
- Analogie : points de terminaison POST ou PUT
- Les outils sont des fonctions exécutables qui permettent à un LLM d'effectuer des actions et d'avoir un impact direct sur les systèmes externes. C'est ce qui permet à un agent d'aller au-delà de la simple récupération de données et d'effectuer des tâches telles que l'envoi d'un e-mail, la création d'un ticket de projet ou l'appel d'une API tierce.
- Instructions : guider l'interaction
- Fonction : modèles d'interaction
- Analogie : recettes de workflow
- Les prompts sont des modèles réutilisables qui guident l'interaction du LLM avec un utilisateur ou un système. Ils permettent aux développeurs de standardiser les flux conversationnels courants ou complexes, afin de garantir un comportement plus cohérent et plus fiable à partir du modèle.
Le Model Context Protocol lui-même
Concepts de base
Le MCP fournit une méthode standardisée permettant aux applications LLM (hôtes) de s'intégrer à des données et des fonctionnalités externes (serveurs). La spécification repose sur le format de message JSON-RPC 2.0 et définit un ensemble de composants obligatoires et optionnels pour permettre des interactions riches avec état.
Protocole et fonctionnalités de base
Le principe essentiel du MCP est de standardiser la couche de communication. Toutes les implémentations doivent prendre en charge le protocole de base et la gestion du cycle de vie.
- Protocole de base : toutes les communications utilisent des messages JSON-RPC standard (requêtes, réponses et notifications).
- Fonctionnalités serveur : les serveurs peuvent offrir aux clients n'importe quelle combinaison des capacités suivantes :
- Ressources : données contextuelles que l'utilisateur ou le modèle peut consommer
- Prompts : modèles de messages et de workflows
- Outils : fonctions exécutables que le LLM peut invoquer
- Fonctionnalités client : les clients peuvent proposer ces fonctionnalités aux serveurs pour des workflows bidirectionnels plus avancés :
- Échantillonnage : permet à un serveur d'initier des comportements agentiques ou des interactions LLM récursives
- Élicitation : permet à un serveur de demander des informations supplémentaires auprès de l'utilisateur
Protocole MCP de base
Le MCP repose sur un protocole de base et une gestion du cycle de vie obligatoires. Toutes les communications entre clients et serveurs doivent respecter la spécification JSON-RPC 2.0, qui définit trois types de messages :
- Requêtes : envoyées pour lancer une opération. Elles nécessitent un identifiant unique (chaîne ou entier) pour le suivi et ne doivent pas réutiliser un même identifiant au cours de la même session.
- Réponses : envoyées en réponse à une requête. Elles doivent contenir l'identifiant de la requête d'origine et un objet result pour les opérations réussies ou un objet error pour les échecs.
- Notifications : messages unidirectionnels envoyés sans identifiant et ne nécessitant pas de réponse de la part du destinataire.
Fonctionnalités client : permettre des workflows avancés
Pour une communication bidirectionnelle plus complexe, les clients peuvent également proposer des fonctionnalités aux serveurs :
- Échantillonnage : l'échantillonnage permet à un serveur de demander une inférence au LLM via le client. Cette fonctionnalité est un atout puissant pour les workflows d'agents à plusieurs étapes. Un outil peut alors "renvoyer une question" au grand modèle de langage afin d'obtenir plus d'informations avant d'effectuer sa tâche.
- Élicitation : l'élicitation fournit un mécanisme formel permettant à un serveur de demander plus d'informations à l'utilisateur final. C'est un atout essentiel pour les outils interactifs susceptibles de demander une clarification ou une confirmation avant de lancer une action.
Fonctionnalités serveur : exposer des fonctionnalités
Les serveurs exposent leurs fonctionnalités aux clients via un ensemble de caractéristiques standardisées. Un serveur peut implémenter n'importe quelle combinaison des éléments suivants :
- Outils : les outils sont le principal mécanisme qui permet à un LLM d'effectuer des actions. Ce sont des fonctions exécutables qu'un serveur expose, qui permettent au LLM d'interagir avec des systèmes externes, par exemple appeler une API tierce, interroger une base de données ou modifier un fichier.
- Ressources : les ressources représentent les sources de données contextuelles qu'un LLM peut récupérer. Contrairement aux outils qui exécutent des actions, les ressources servent principalement à récupérer des données en lecture seule. Ce mécanisme sert à ancrer un grand modèle de langage dans des informations externes en temps réel, et constitue un élément clé des pipelines RAG avancés.
- Prompts : les serveurs peuvent exposer des modèles de prompt prédéfinis que le client peut utiliser. Cette approche permet de standardiser et de partager des prompts courants, complexes ou fortement optimisés, ce qui assure la cohérence des interactions.
Sécurité et fiabilité
La spécification met particulièrement en avant la sécurité, en énonçant les principes clés que les développeurs doivent respecter. Le protocole lui-même ne peut pas imposer ces règles ; cette responsabilité incombe au développeur de l'application.
- Consentement et contrôle de l'utilisateur : les utilisateurs doivent consentir explicitement à tous les accès aux données et aux appels d'outils et en conserver le contrôle. Des interfaces utilisateur claires pour l'autorisation sont essentielles.
- Confidentialité des données : les hébergeurs ne doivent pas transmettre de données utilisateur à un serveur sans consentement explicite et doivent mettre en œuvre des contrôles d'accès appropriés.
- Sécurité des outils : l'appel d'un outil implique l'exécution de code arbitraire et doit être abordée avec prudence. Les hôtes doivent obtenir le consentement explicite de l'utilisateur avant d'utiliser un outil.
Pourquoi le MCP est-il si important ?
Le principal atout du MCP est de standardiser la couche de communication et d'interaction entre les modèles et les outils. Cela crée un écosystème prévisible et fiable pour les développeurs. Les principaux domaines de standardisation sont les suivants :
- API de connecteur uniforme : une interface unique et cohérente pour connecter n'importe quel service externe
- Contexte standardisé : format de message universel pour transmettre des informations critiques telles que l'historique des sessions, les embeddings, les sorties d'outils et la mémoire à long terme
- Protocole d'appel d'outil : modèles de requêtes et de réponses convenus pour l'appel d'outils externes, garantissant la prévisibilité
- Contrôle du flux de données : règles intégrées de filtrage, de priorisation, de diffusion et de traitement par lots du contexte pour optimiser la construction des prompts
- Modèles de sécurité et d'authentification : hooks courants pour l'authentification par clé API ou OAuth, la limitation du débit et le chiffrement afin de sécuriser l'échange de données
- Règles de cycle de vie et de routage : conventions qui définissent quand récupérer le contexte, combien de temps le mettre en cache et comment acheminer les données entre les systèmes
- Métadonnées et observabilité : champs de métadonnées unifiés qui permettent une journalisation, des mesures et un traçage distribué cohérents sur tous les modèles et outils connectés
- Points d'extension : hooks définis pour ajouter une logique personnalisée, telle que des étapes de pré- et post-traitement, des règles de validation personnalisées et l'enregistrement de plug-ins
À grande échelle : résoudre le cauchemar de l'intégration "M×N" ou de la montée en charge multiplicative
Dans le contexte de l'IA en pleine expansion, les développeurs sont confrontés à un défi d'intégration majeur. Les applications d'IA (M) doivent accéder à de nombreuses sources de données et outils externes (N), allant des bases de données et moteurs de recherche aux API et aux référentiels de code. En l'absence de protocole standardisé, ils sont contraints de résoudre le "problème M×N" en concevant et en gérant une intégration unique et personnalisée pour chaque paire application-source.
Cette approche entraîne plusieurs problèmes critiques :
- Efforts redondants des développeurs : les équipes résolvent à plusieurs reprises les mêmes problèmes d'intégration pour chaque nouvelle application d'IA, ce qui fait perdre un temps et des ressources précieux.
- Complexité écrasante : différentes sources de données gèrent des fonctions similaires de manière unique, créant ainsi une couche d'intégration complexe et incohérente.
- Maintenance excessive : l'absence de standardisation engendre un écosystème fragile d'intégrations personnalisées. Une simple mise à jour ou modification de l'API d'un outil peut rompre les connexions, nécessitant une maintenance réactive et constante.
Le MCP transforme ce problème M×N en une équation M+N beaucoup plus simple. En créant une norme universelle, les développeurs n'ont besoin de créer que M clients (pour leurs applications) et N serveurs (pour leurs outils), ce qui réduit considérablement la complexité et les coûts de maintenance.
Comparaison des approches agentiques
Le MCP ne remplace pas les techniques largement utilisées comme la génération augmentée par récupération (RAG) ou les frameworks tels que LangChain. Il s'agit d'un protocole de connectivité fondamental qui les rend plus performants, modulaires et plus faciles à gérer. Il résout le problème universel de la connexion d'une application à un outil externe en standardisant la dernière étape de l'intégration.
Voici comment MCP s'intègre dans la pile IA moderne :
Une RAG avancée et performante
La RAG standard est puissante, mais elle se connecte souvent à une base de données vectorielle statique. Pour les cas d'utilisation plus avancés, vous devez récupérer des informations dynamiques à partir de systèmes complexes en direct.
- Sans MCP : un développeur doit écrire du code personnalisé pour connecter son application RAG directement au langage de requête spécifique d'une API de recherche comme Elasticsearch.
- Avec MCP : le système de recherche expose ses fonctionnalités via un serveur MCP standard. L'application RAG peut alors interroger cette source de données en direct à l'aide d'un client MCP simple et réutilisable, sans avoir besoin de connaître l'API spécifique du système sous-jacent. L'implémentation RAG est ainsi plus claire et plus facile à remplacer par d'autres sources de données ultérieurement.
Intégration à des frameworks agentiques (p. ex., LangChain, LangGraph)
Les frameworks agentiques constituent d'excellents outils pour créer une logique d'application, mais ils nécessitent quand même un moyen de se connecter à des outils externes.
- Les alternatives :
- Code personnalisé : écrire une intégration directe en partant de zéro, ce qui nécessite des efforts d'ingénierie importants et une maintenance continue
- Outils spécifiques au framework : utiliser un connecteur préconstruit ou écrire un wrapper personnalisé pour un framework spécifique. (Cela crée une dépendance à l'architecture de ce framework et vous enferme dans son écosystème.)
- L'avantage du MCP : le MCP fournit un standard ouvert et universel. Un fournisseur d'outils peut créer un serveur MCP unique pour son produit. Dès lors, n'importe quel framework – LangChain, LangGraph ou une solution personnalisée – peut interagir avec ce serveur à l'aide d'un client MCP générique. Cette approche est plus efficace et évite la dépendance vis-à-vis d'un seul fournisseur.
Pourquoi un protocole simplifie tout
En définitive, la valeur du MCP est de proposer une alternative ouverte et standardisée aux deux extrêmes de l'intégration :
- L'écriture de code personnalisé est fragile et entraîne des coûts de maintenance élevés.
- L'utilisation de wrappers spécifiques à un framework crée un écosystème semi-fermé et une dépendance vis-à-vis du fournisseur.
Le MCP transfère la responsabilité de l'intégration au propriétaire du système externe, lui permettant de fournir un point de terminaison MCP unique et stable. Les développeurs d'applications peuvent ensuite simplement utiliser ces points de terminaison, ce qui simplifie considérablement le travail nécessaire pour créer, scaler et gérer des applications d'IA contextuelles puissantes.
Prise en main du serveur MCP pour Elasticsearch
Elasticsearch propose désormais un serveur MCP entièrement géré et hébergé. Cela élimine le besoin de conteneurs Docker autonomes ou d'environnements Node.js locaux, et offre une passerelle persistante et sécurisée pour tout hôte compatible MCP.
Accédez au point de terminaison hébergé
À partir de la version 9.3 et de l'architecture sans serveur, le serveur MCP est activé par défaut pour les projets de recherche. Pour les utilisateurs des fonctions d'observabilité et de sécurité, le serveur MCP peut être exposé en activant Agent Builder via la configuration d'AI Assistant.
Pour tous les détails de mise en œuvre et les instructions spécifiques à la plateforme, consultez la documentation officielle d'Agent Builder.
Configurez votre client MCP
Une fois activé, il vous suffit de diriger votre hôte MCP (comme Claude Desktop, VS Code ou Cursor) vers votre point de terminaison unique Elastic.
Exemple de configuration pour Claude Desktop :
JSON
{
"mcpServers": {
"elastic": {
"command": "npx",
"args": [
"-y",
"@elastic/mcp-server-elasticsearch",
"--hosted-url",
"https://YOUR_KIBANA_URL/api/agent_builder/mcp"
],
"env": {
"ES_API_KEY": "YOUR_ELASTIC_API_KEY"
}
}
}
}
En utilisant la version hébergée, vous exploitez les couches de sécurité natives d'Elastic et vous garantissez à vos agents contextuels un accès 24/7 à vos données sans aucune gestion locale des processus.
Échangez avec nous à propos du MCP et de l'IA
Apprenez-en davantage sur le développement avec Elastic
Suivez l'actualité de l'IA et des applications de recherche intelligente. Consultez nos ressources pour découvrir en détail comment développer avec Elastic.
- Les fonctions LLM avec Elasticsearch pour une transformation intelligente des requêtes
- Les agents IA et le SDK Elastic AI pour Python
- Model Context Protocol pour Elasticsearch
Commencez à développer dès maintenant avec l'atelier pratique gratuit : Introduction au MCP avec le serveur MCP Elasticsearch.