Le parcours d'Elastic pour construire Elastic Cloud Serverless
Architecture sans état qui scale automatiquement en fonction de vos besoins en matière de données, d'utilisation et de performances


 Share on Twitter
Share on TwitterPartager sur Twitter

 Share on LinkedIn
Share on LinkedInPartager sur LinkedIn

 Share on Facebook
Share on FacebookPartager sur Facebook

 Share by Email
Share by EmailPartage par e-mail

 Print this page
Print this pageImprimer
Comment transformer un système avec état comme Elasticsearch dont les performances sont essentielles, en un système sans serveur ?
Chez Elastic, nous avons tout repensé, du stockage à l'orchestration, pour créer une véritable plateforme sans serveur dans laquelle les clients peuvent avoir confiance.
Elastic Cloud Serverless est une plateforme cloud entièrement gérée, conçue pour apporter la puissance de la Suite Elastic aux développeurs sans le fardeau opérationnel. Dans cet article de blog, nous vous expliquerons pourquoi nous l'avons créé, comment nous avons abordé l'architecture et ce que nous avons appris en cours de route.
Pourquoi le mode sans serveur ?
Au fil des années, les attentes des clients ont considérablement évolué. Les utilisateurs ne souhaitent plus s'occuper des complexités de la gestion de l'infrastructure, telles que le dimensionnement, le suivi et le scaling. Ils recherchent plutôt une expérience fluide leur permettant de se concentrer uniquement sur leurs charges de travail. Cette demande en constante évolution nous a incités à développer une solution qui réduit les frais opérationnels, offre une expérience SaaS sans friction et introduit un modèle de tarification à l'utilisation. En éliminant la nécessité pour les clients de provisionner et de gérer manuellement les ressources, nous avons créé une plateforme qui s'adapte dynamiquement à la demande tout en optimisant l'efficacité.
Jalons
Elastic Cloud Serverless se développe rapidement pour répondre à la demande des clients, ayant atteint la disponibilité générale (DG) sur AWS en décembre 2024, sur GCP en avril 2025 et sur Azure en juin 2025. Depuis, nous nous sommes étendus à quatre régions sur AWS, trois régions sur GCP et une région sur Azure ; des régions supplémentaires sont prévues chez les trois fournisseurs de services cloud (CSP).
Repenser l'architecture : de l'état à l'absence d'état
Elastic Cloud Hosted (ECH) a été initialement conçu comme un système avec état, s'appuyant sur un stockage local basé sur NVMe ou sur des disques gérés pour assurer la durabilité des données. À mesure qu'Elastic Cloud se développait à l'échelle mondiale, nous avons identifié une opportunité d'évolution de notre architecture pour mieux soutenir l'efficacité opérationnelle et la croissance à long terme. Notre approche hébergée pour gérer l'état persistant dans des environnements distribués s'est avérée efficace, mais elle a introduit une complexité opérationnelle supplémentaire : remplacement des nœuds, maintenance, assurer la redondance dans les zones de disponibilité et scaling des charges de travail intensives en calcul telles que l'indexation et la recherche.
Nous avons décidé de faire évoluer l'architecture de notre système en adoptant une approche sans état. Le changement majeur a consisté à décharger le stockage persistant des nœuds de calcul vers des stockages d'objets cloud natifs. Nous en avons tiré de nombreux avantages : réduction de la surcharge d'infrastructure requise pour l'indexation, possibilité de séparer la recherche et l'indexation, suppression du besoin de réplication et amélioration de la durabilité des données en exploitant les mécanismes de redondance intégrés des CSP.
La transition vers le stockage d'objets
L'un des changements majeurs dans notre architecture a été l'utilisation du stockage d'objets cloud natif comme magasin de données principal. ECH a été conçu pour stocker des données sur des SSD NVMe locaux ou des disques SSD gérés. Cependant, à mesure que les volumes de données augmentaient, les difficultés liées au scaling des capacités de stockage se sont accrues. Nous avons ensuite introduit des instantanés interrogeables dans ECH, ce qui nous a permis de rechercher des données directement à partir des magasins d'objets, réduisant ainsi considérablement les coûts de stockage ; mais il nous fallait aller plus loin.
Un défi majeur consistait à déterminer si les magasins d'objets pouvaient gérer des charges de travail à forte ingestion tout en maintenant le niveau de performance attendu par les utilisateurs d'Elasticsearch. Grâce à une implémentation et des tests rigoureux, nous avons validé la capacité du stockage d'objets à répondre aux exigences de l'indexation à grande échelle. Le passage au stockage d'objets a éliminé le besoin de répliquer l'indexation, a réduit les exigences d'infrastructure et a amélioré la durabilité en répliquant les données dans les zones de disponibilité, garantissant ainsi une haute disponibilité et une résilience renforcée.
Le schéma ci-dessous illustre la nouvelle architecture « stateless » par rapport à l'architecture « ECH » existante :

Optimiser l'efficacité du stockage d'objets
Si le passage au stockage d'objets a apporté des avantages en termes d'exploitation et de durabilité, il a introduit un nouveau défi : les coûts de l'API du magasin d'objets. Les écritures dans Elasticsearch, en particulier les mises à jour et les actualisations des translogs, se traduisent directement par des appels à l'API du magasin d'objets, qui peuvent scaler à la hausse rapidement et de manière imprévisible, surtout sous des charges de travail à forte ingestion ou à fort taux d'actualisation.
Pour résoudre ce problème, nous avons implémenté un mécanisme de mise en mémoire tampon des translogs par nœud qui fusionne les écritures avant leur vidage vers le magasin d'objets, réduisant ainsi considérablement l'amplification des écritures. Nous avons également dissocié les actualisations des écritures dans le magasin d'objets, envoyant les segments actualisés directement aux nœuds de recherche tout en différant la persistance du magasin d'objets. Cet affinement architectural a permis de réduire de deux ordres de grandeur les appels d'API du magasin d'objets liés aux actualisations, sans compromettre la durabilité des données. Pour plus de détails, consultez cet article de blog.
Choisir Kubernetes pour l'orchestration
ECH utilise un orchestrateur de conteneurs développé en interne qui soutient également Elastic Cloud Enterprise (ECE). Comme le développement d'ECE a commencé avant l'existence de Kubernetes (K8s), nous avions le choix entre étendre ECE pour prendre en charge le serverless ou utiliser K8s pour le serverless. Avec l'adoption rapide de K8s par l'ensemble du secteur et l'écosystème croissant qui l'entoure, nous avons décidé d'adopter des services Kubernetes gérés pour les CSP dans Elastic Cloud Serverless, là où cela correspond à nos objectifs opérationnels et de scaling.
En adoptant Kubernetes, nous avons réduit la complexité opérationnelle, standardisé les API pour améliorer la scalabilité et positionné Elastic Cloud pour l'innovation à long terme. Kubernetes nous a permis de nous concentrer sur des fonctionnalités à plus forte valeur au lieu de réinventer l'orchestration des conteneurs.
Kubernetes géré par CSP vs autogéré
Lors de la transition vers Kubernetes, nous avons dû décider si nous devions gérer nous-mêmes les clusters Kubernetes ou utiliser les services Kubernetes gérés fournis par les CSP. Les implémentations de Kubernetes varient considérablement d'un CSP à l'autre, mais pour accélérer nos délais de déploiement et réduire les frais opérationnels, nous avons opté pour des services Kubernetes gérés par les CSP sur AWS, GCP et Azure. Cette approche nous a permis de nous concentrer sur la création d'applications et l'adoption des bonnes pratiques du secteur plutôt que de nous occuper des subtilités de la gestion des clusters Kubernetes.
Nos principales exigences comprenaient la capacité de provisionner et de gérer des clusters Kubernetes de manière cohérente sur plusieurs CSP, une API indépendante du cloud pour la gestion du calcul, du stockage et des bases de données, et des opérations simplifiées et rentables. De plus, en choisissant Kubernetes géré par les CSP, nous avons pu contribuer en amont à des projets open source comme Crossplane, améliorant ainsi l'écosystème Kubernetes global tout en bénéficiant de ses capacités évolutives.
Les défis de la mise en réseau et le choix de Cilium
L'exploitation de Kubernetes à grande échelle avec des dizaines de milliers de pods par cluster Kubernetes nécessite une solution de mise en réseau qui soit indépendante du cloud, offre des performances élevées avec une latence minimale, et prenne en charge des politiques de sécurité avancées. Pour répondre à ces exigences, nous avons choisi Cilium, une solution moderne basée sur eBPF. Nous envisagions au départ de mettre en œuvre une solution Cilium uniforme et autogérée sur tous les CSP. Cependant, les différences dans les implémentations cloud nous ont conduits à adopter une approche hybride, en utilisant les solutions Cilium natives des CSP lorsqu'elles étaient disponibles, tout en maintenant un déploiement autogéré sur AWS. Cette flexibilité nous a permis de répondre à nos besoins en matière de performance et de sécurité sans complexité inutile.
Trafic entrant
Pour le trafic entrant, nous avons choisi de nous adapter et de continuer à utiliser notre proxy ECH existant, testé et validé. L'évaluation ne portait pas simplement sur la possibilité de remplacer le proxy par une solution standard, mais sur l'intérêt de le faire.
Si un proxy inverse standard fournit des fonctionnalités de base, il manque de caractéristiques distinctives que le proxy ECH gère déjà. Dans ces conditions, il nous aurait fallu créer des extensions pour les filtres de trafic d'entrée, assurer la prise en charge d'AWS PrivateLink et de Google Cloud Private Service Connect, ainsi que de la terminaison TLS conforme à la norme FIPS. Le proxy existant a également déjà passé tous les audits de conformité pertinents et les tests de pénétration.
Commencer avec une nouvelle solution aurait nécessité des efforts considérables sans apporter de valeur supplémentaire au client. L'adaptation de notre proxy pour Kubernetes a principalement consisté à mettre à jour la manière dont nous distribuons la découverte des points de terminaison des services, tout en préservant les fonctionnalités principales testées et validées. Cette approche offre plusieurs avantages :
Elle garantit que le comportement visible par le client reste cohérent entre ECH et Kubernetes.
Les équipes peuvent travailler plus efficacement avec une base de code familière et bien comprise, surtout lors de l'implémentation de nouvelles fonctionnalités nécessitant des scripts ou des extensions dans une solution prête à l'emploi.
Nous pouvons faire progresser nos plateformes ECH et Kubernetes avec une seule base de code ; ainsi, les améliorations dans un environnement se traduisent par des améliorations dans l'autre.
Les équipes de support technique peuvent tirer parti de leurs connaissances existantes, réduisant la courbe d'apprentissage de la nouvelle plateforme.
Couche de provisionnement Kubernetes
Après avoir choisi Kubernetes pour Elastic Cloud Serverless, nous avons sélectionné Crossplane comme outil de gestion de l'infrastructure. Crossplane est un projet open source qui étend l'API Kubernetes pour permettre le provisionnement et la gestion de l'infrastructure et des services cloud à l'aide d'outils et de pratiques Kubernetes natifs. Il permet aux utilisateurs de provisionner, de gérer et d'orchestrer des ressources cloud dans plusieurs CSP à partir d'un cluster Kubernetes. Pour ce faire, les définitions de ressources personnalisées (CRD) sont utilisées pour définir les ressources et les contrôleurs cloud afin de concilier l'état souhaité spécifié dans les manifestes Kubernetes avec l'état réel des ressources cloud de plusieurs CSP. L'utilisation des mécanismes de configuration et de contrôle déclaratifs de Kubernetes offre une solution cohérente et évolutive pour gérer l'infrastructure en tant que code.
Crossplane permet la gestion et le provisionnement de l'infrastructure en utilisant les mêmes outils et méthodes que ceux employés pour le déploiement des services. Cela implique de tirer parti des ressources Kubernetes, d'une architecture GitOps cohérente et d'outils d'observabilité unifiés. En outre, les développeurs peuvent établir un environnement de développement complet basé sur Kubernetes, y compris son infrastructure périphérique, qui reflète les environnements de production. Pour ce faire, il suffit de créer une ressource Kubernetes, car les deux environnements sont générés à partir du même code sous-jacent.
Gérer l'infrastructure
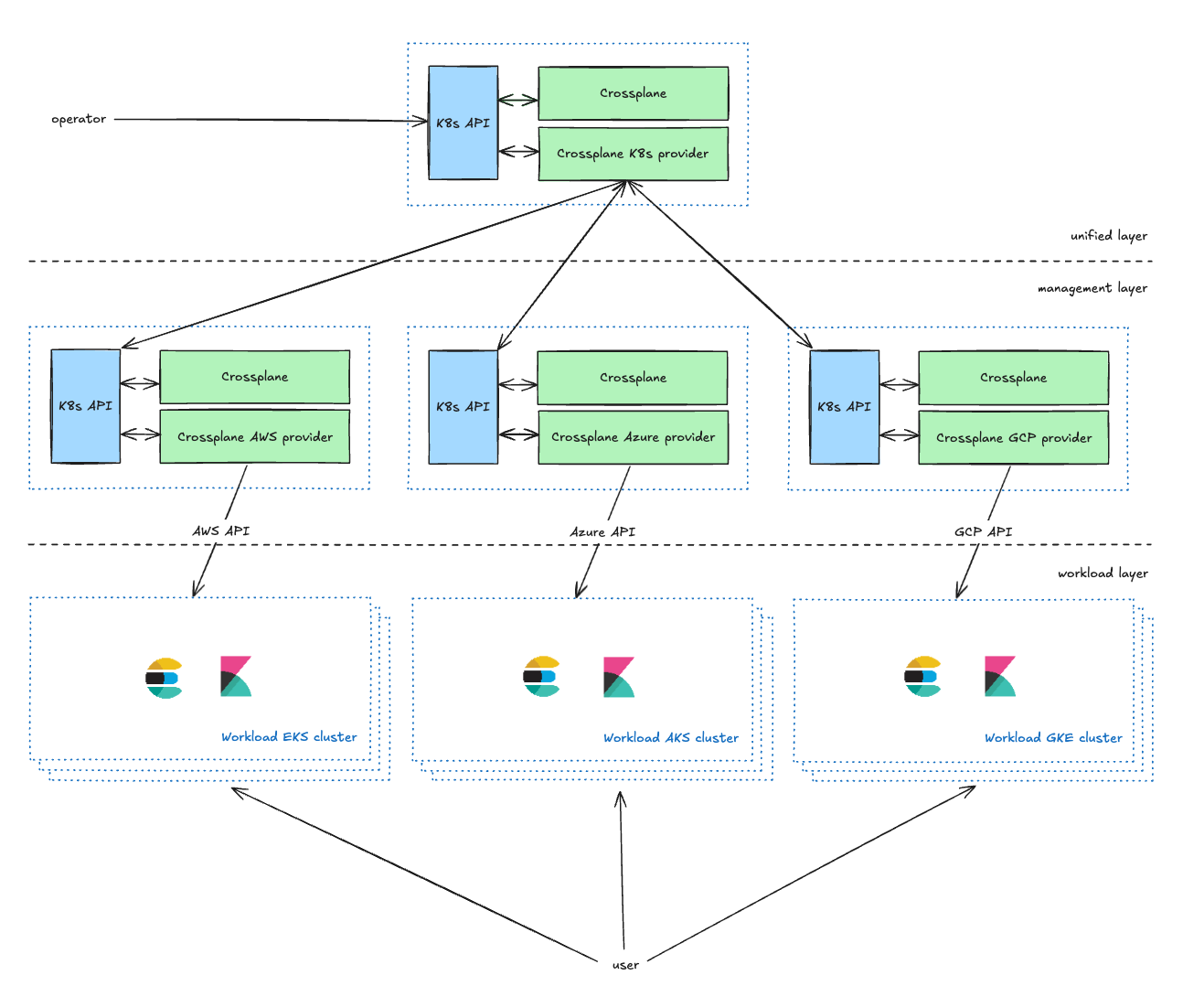
La couche unifiée est la couche de gestion orientée opérateur. Elle fournit des CRD Kubernetes qui permettent aux propriétaires de services de gérer leurs clusters Kubernetes. Ils peuvent ainsi définir des paramètres, notamment le CSP, la région et le type (comme décrit dans la section suivante). Ce mécanisme enrichit les requêtes des opérateurs et les transmet à la couche de gestion.
La couche de gestion sert de proxy entre la couche unifiée et les API du CSP. Elle transforme les requêtes de la couche unifiée en requêtes de ressources du CSP et transmet le rapport d'état à la couche unifiée.
Dans notre configuration actuelle, nous administrons deux clusters de gestion Kubernetes pour chaque CSP dans chaque environnement. Cette approche à double cluster sert principalement deux objectifs clés. Premièrement, elle nous permet de traiter efficacement les problèmes de scalabilité potentiels qui peuvent survenir avec Crossplane. Deuxièmement, et plus important, elle nous permet d'utiliser l'un des clusters comme environnement Canari. Cette stratégie de déploiement Canari facilite un déploiement progressif de nos modifications, en commençant par un sous-ensemble plus petit et contrôlé de chaque environnement, minimisant ainsi les risques.
La couche Charge de travail contient tous les clusters Kubernetes de charge de travail exécutant les applications avec lesquelles les utilisateurs interagissent (Elasticsearch, Kibana, MIS, etc.).
Gérer la capacité du cloud : éviter les erreurs « hors capacité »
Selon une hypothèse courante, la capacité du cloud serait infinie, mais en réalité, les CSP imposent des contraintes qui peuvent entraîner des erreurs « hors capacité ». Si un type d'instance n'est pas disponible, nous devons continuellement réessayer ou passer à un autre type d'instance.
Pour atténuer ce problème dans Elastic Cloud Serverless, nous avons mis en place des pools de capacité basés sur des priorités, permettant aux charges de travail de migrer vers de nouveaux ou d'autres pools de capacité si nécessaire. De plus, nous avons investi dans une planification proactive de la capacité, en réservant des ressources informatiques avant les pics de demande. Ces mécanismes garantissent une haute disponibilité tout en optimisant l'utilisation des ressources.
Rester informé
Les mises à niveau des clusters Kubernetes sont chronophages. Pour rationaliser ces opérations, nous utilisons un processus automatisé de bout en bout qui ne nécessite une intervention manuelle qu'en cas de problèmes impossibles à résoudre automatiquement. Une fois les tests internes effectués et une nouvelle version de Kubernetes approuvée, nous la configurons de manière centralisée. Un système automatisé initie ensuite la mise à niveau du plan de contrôle pour chaque cluster, selon une simultanéité contrôlée et un ordre spécifique. Par la suite, des contrôleurs Kubernetes personnalisés effectuent des déploiements blue-green pour mettre à niveau les pools de nœuds. Bien que les pods des clients migrent vers différents nœuds K8s au cours de ce processus, la disponibilité et la performance du projet restent inchangées.
Résilience de l'architecture
Nous utilisons une architecture cellulaire, ce qui nous permet de fournir des services à la fois évolutifs et résilients. Chaque cluster Kubernetes, ainsi que son infrastructure périphérique, est déployé dans un compte CSP distinct afin de permettre un scaling adapté sans être affecté par les limites du CSP et assurer des conditions de sécurité et d’isolement optimales. Les charges de travail individuelles, chacune constituant une cellule distincte, gèrent les aspects spécifiques du système. Ces cellules fonctionnent indépendamment, ce qui permet un scaling et une gestion isolés. Cette conception modulaire minimise la portée des défaillances et facilite un scaling ciblé, évitant ainsi les impacts à l'échelle du système. Pour minimiser davantage l'impact potentiel des incidents, nous utilisons des déploiements Canary à la fois pour nos applications et l'infrastructure sous-jacente.
Plan de contrôle vs plan de données : le modèle Push
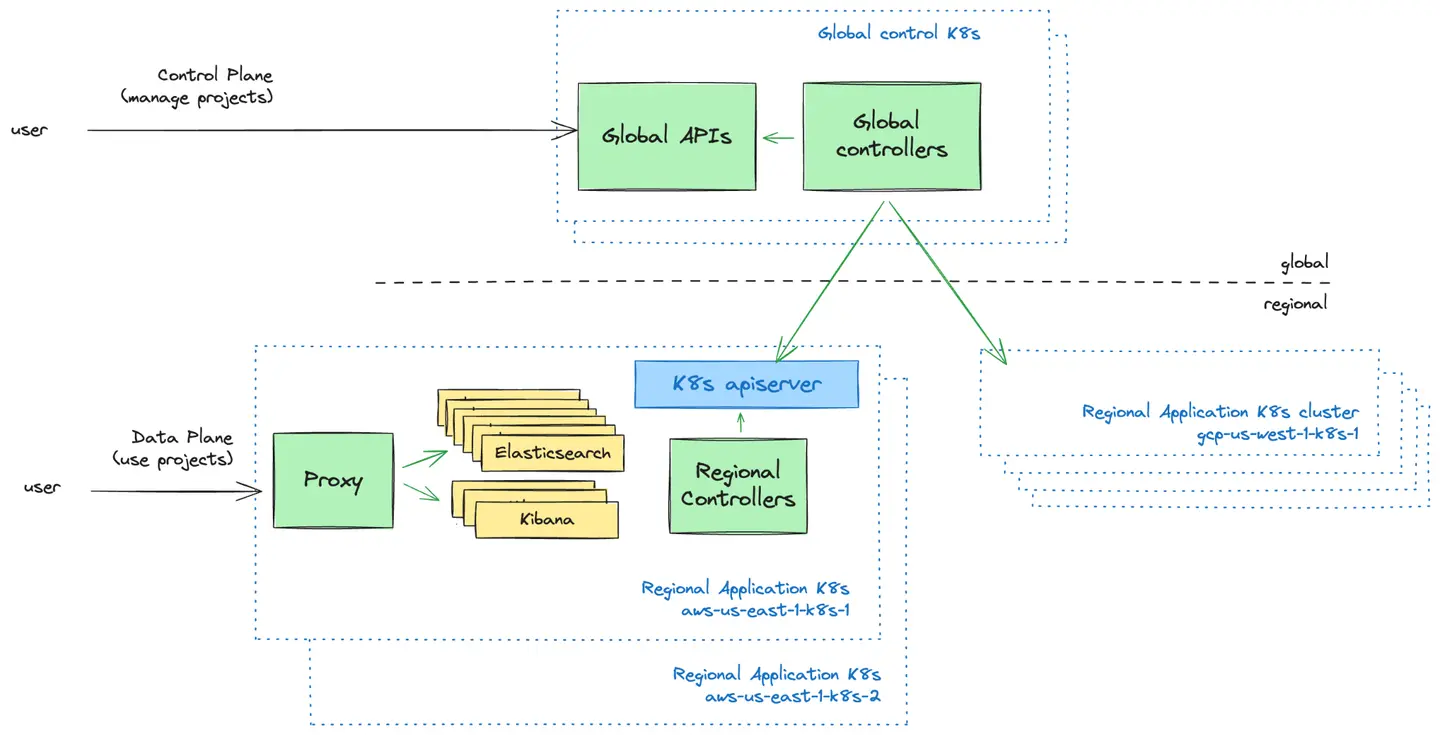
Le plan de contrôle est la couche de gestion orientée utilisateur. Nous fournissons des interfaces utilisateur et des API pour que les utilisateurs puissent gérer leurs projets Elastic Cloud Serverless. C'est ici qu'ils peuvent créer de nouveaux projets, contrôler qui y a accès et en obtenir un aperçu.
Le plan de données est la couche d'infrastructure qui soutient les projets Elastic Cloud Serverless et avec laquelle les utilisateurs interagissent lorsqu'ils souhaitent utiliser leurs projets.
Une décision de conception fondamentale à laquelle nous avons été confrontés consistait à déterminer comment le plan de contrôle global devait communiquer avec les clusters Kubernetes dans le plan de données. Nous avons exploré deux modèles :
Modèle Push : le plan de contrôle envoie de manière proactive les configurations vers les clusters Kubernetes régionaux.
Modèle Pull : les clusters Kubernetes régionaux récupèrent périodiquement les configurations depuis le plan de contrôle.
Après avoir évalué les deux approches, nous avons adopté le modèle Push en raison de sa simplicité, de son flux de données unidirectionnel et de sa capacité à faire fonctionner les clusters Kubernetes indépendamment du plan de contrôle lors des défaillances. Ce modèle nous a permis d'assurer la maintenance d'une logique de planification simple tout en réduisant les frais opérationnels et les complexités de récupération après des pannes.
Autoscaling : au-delà du scaling horizontal et vertical
Pour offrir une véritable expérience sans serveur, nous avions besoin d'un mécanisme d'autoscaling intelligent capable d'ajuster les ressources de manière dynamique en fonction des exigences de la charge de travail. Nous avons commencé par un scaling horizontal de base, mais nous nous sommes rapidement rendu compte que les différents services avaient des besoins de redimensionnement spécifiques. Certains nécessitaient des ressources de calcul supplémentaires, tandis que d'autres exigeaient une allocation de mémoire plus élevée.
Nous avons fait évoluer notre approche en développant des contrôleurs d'autoscaling personnalisés qui analysent en temps réel les métriques spécifiques à la charge de travail, permettant un scaling dynamique à la fois réactif et efficace en termes de ressources. Nous sommes ainsi en mesure de scaler de manière transparente les opérations d'indexation et de recherche pour Elasticsearch sans surprovisionnement. Cette stratégie permet d'utiliser l'autoscaling multidimensionnel des pods afin de scaler les charges de travail horizontalement et verticalement en fonction du processeur, de la mémoire et des métriques personnalisées générées par la charge de travail.
Pour nos charges de travail Elasticsearch, nous utilisons une API Elasticsearch spécifique à l'environnement sans serveur qui renvoie certaines métriques clés concernant le cluster. Voici comment cela fonctionne : le système de recommandation suggère les ressources de calcul nécessaires (replicas, mémoire et processeur) ainsi que le stockage pour un niveau donné. Ces recommandations sont ensuite converties par les mappeurs en configurations concrètes de calcul et de stockage applicables aux conteneurs. Pour éviter les fluctuations de scaling rapides, ces recommandations sont filtrées par des stabilisateurs. Les limiteurs entrent alors en jeu, imposant à la fois des contraintes de ressources minimales et maximales. La sortie du limiteur est utilisée pour mettre à jour le déploiement Kubernetes après avoir pris en compte certaines règles de restriction optionnelles.
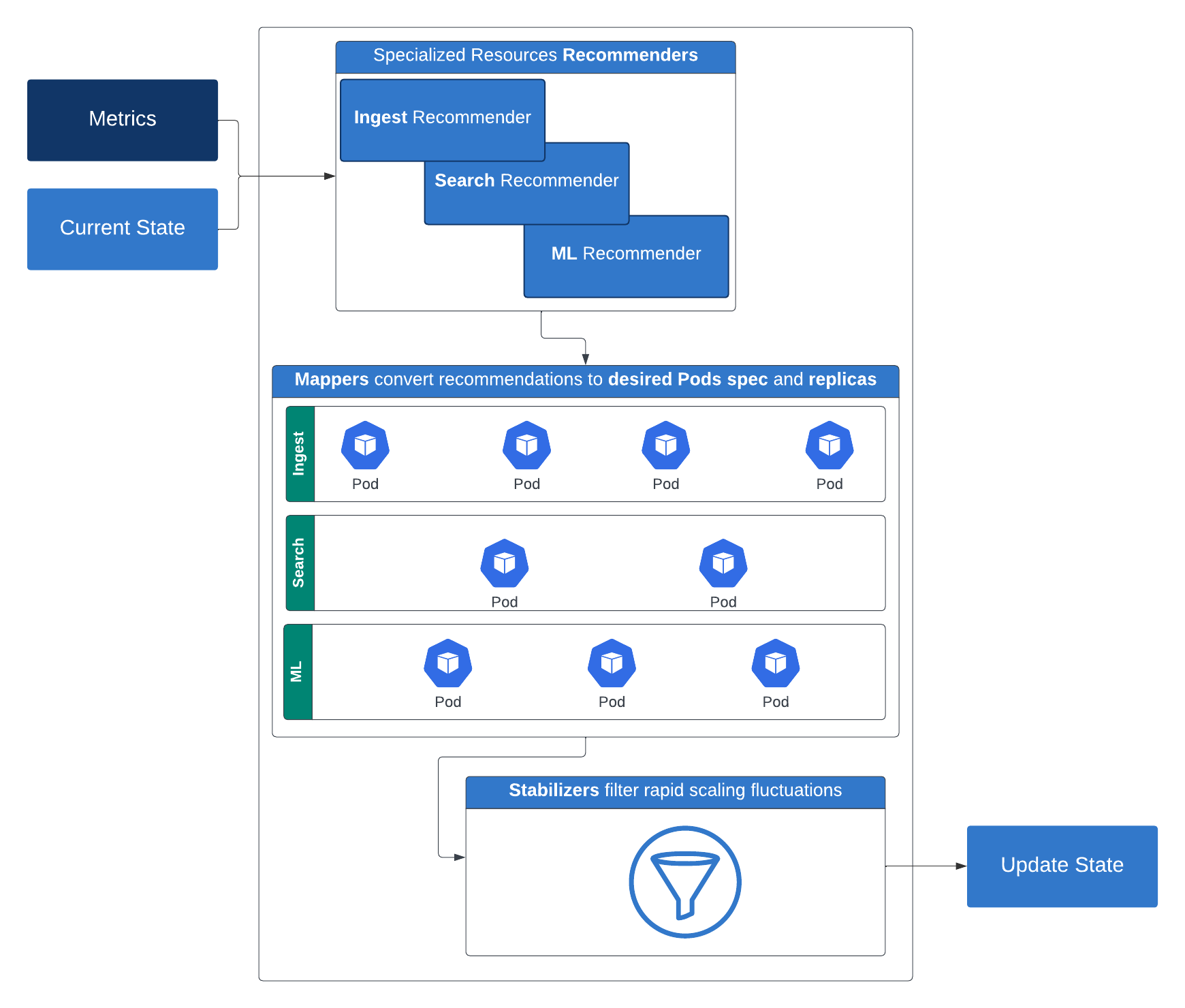
Cette stratégie de scaling intelligente et stratifiée garantit les performances et l'efficacité de diverses charges de travail, et représente un grand pas vers une véritable plateforme sans serveur.
Elastic Cloud Serverless introduit des capacités d'autoscaling nuancées adaptées au niveau de recherche, en exploitant des entrées telles que les fenêtres de données boostées, les paramètres de puissance de recherche et les métriques de charge de recherche (y compris la charge du pool de threads et la charge de la file d'attente). Ces signaux fonctionnent ensemble pour définir les configurations de base et déclencher des décisions d'autoscaling dynamique basées sur les modèles d'utilisation de la recherche du client. Pour en savoir plus sur l'autoscaling par niveau de recherche, consultez cet article de blog.Pour en savoir plus sur le fonctionnement de l'autoscaling par niveau d'indexation, consultez cet article de blog.
Élaborer un modèle de tarification flexible
Un principe fondamental de l'informatique sans serveur est d'aligner les coûts sur l'utilisation effective. Nous souhaitions proposer un modèle de tarification simple, flexible et transparent. Après avoir évalué diverses approches, nous avons conçu un modèle qui équilibre les charges de travail entre nos principales solutions :
Observability and Security : facturation basée sur les données ingérées et conservées, avec une tarification par niveaux
Elasticsearch (Search) : tarification basée sur des unités de calcul virtuelles, y compris l'ingestion, la recherche, le machine learning et la conservation des données
Cette approche propose aux clients une tarification à l'utilisation, offrant une plus grande flexibilité et une meilleure prévisibilité des coûts.
Pour mettre en œuvre ce modèle de tarification (qui a subi de nombreuses itérations au cours de la phase de développement), nous savions qu'il nous fallait une architecture évolutive et flexible. Finalement, nous avons construit un pipeline qui prend en charge un modèle de propriété distribuée, avec différentes équipes responsables des divers composants du processus de bout en bout. Nous décrivons ci-dessous les deux principaux segments de ce pipeline : la collecte de l'utilisation mesurée via le pipeline d'utilisation, et les calculs de facturation via le pipeline de facturation.
Pipeline d'utilisation
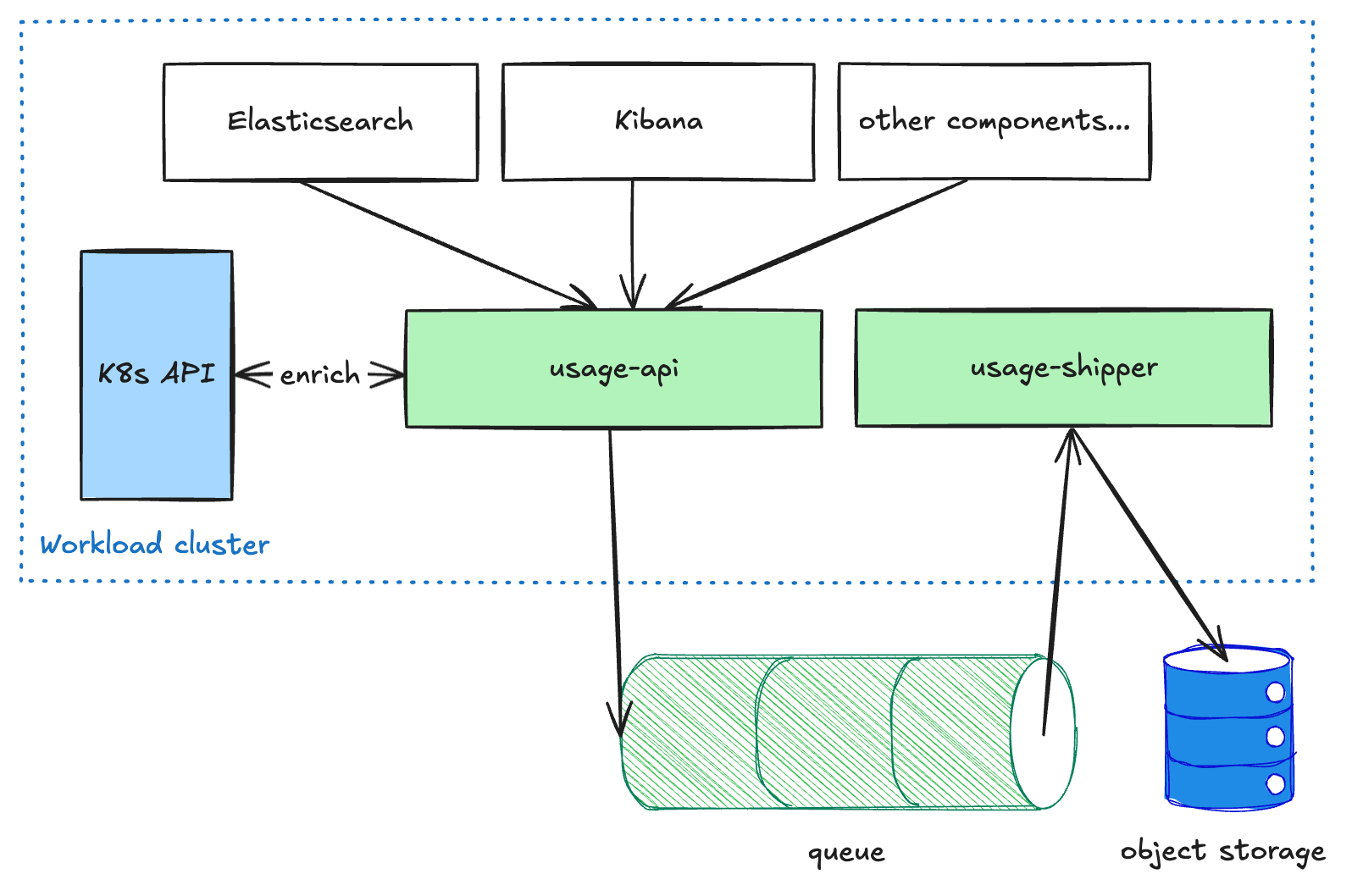
Les composants orientés utilisateur comme Elasticsearch et Kibana envoient des données d'utilisation mesurées au service usage-api, qui s'exécute dans chaque cluster de charge de travail. Ce service enrichit les données, puis les place dans une file d'attente. Le service usage-shipper extrait ensuite ces données de la file d'attente et les transmet au stockage d'objets. Cette architecture découplée est nécessaire pour garantir la résilience du pipeline lors du transfert de données entre régions et CSP, car nous privilégions la livraison plutôt que la latence. Une fois les données stockées dans le stockage d'objets, elles sont accessibles en lecture seule aux autres processus pour des transformations ou des agrégations ultérieures (par exemple, pour la facturation ou l'analyse).
Pipeline de facturation
Une fois que les enregistrements d'utilisation sont déposés dans le stockage d'objets, le pipeline de facturation récupère les données et les transforme en quantités d'ECU (Elastic Consumption Units, notre unité de facturation indépendante de la devise) que nous facturons. Le processus de base est le suivant :
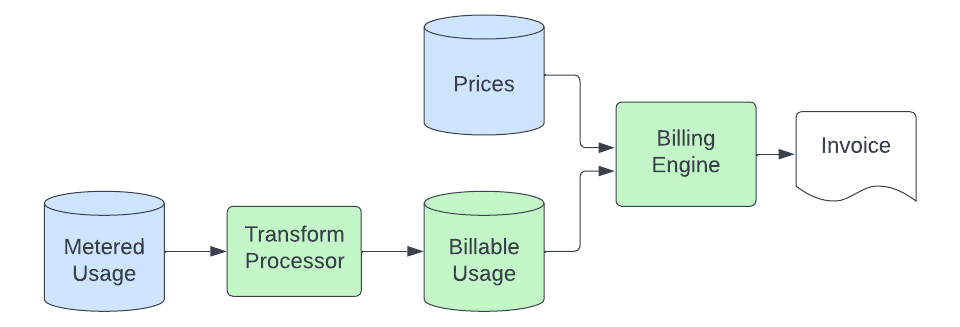
Un processus de transformation consomme les enregistrements d'utilisation mesurés à partir du stockage d'objets et les convertit en enregistrements pouvant être réellement facturés. Ce processus implique la conversion d'unités (l'application mesurée peut mesurer le stockage en octets, mais nous pouvons facturer en Go), le filtrage des sources d'utilisation que nous ne facturons pas, le mapping de l'enregistrement à un produit spécifique (ce qui implique l'analyse des métadonnées dans les enregistrements d'utilisation pour lier l'utilisation à un produit spécifique à une solution qui a un prix unique), et l'envoi de ces données à un cluster Elasticsearch qui est interrogé par notre moteur de facturation. L'objectif de cette étape de transformation est de fournir un emplacement centralisé où la logique permet de convertir les enregistrements d'utilisation génériques mesurés en quantités spécifiques au produit prêtes à être tarifées. Cela nous permet de conserver cette logique spécialisée en dehors des applications mesurées et du moteur de facturation, que nous souhaitons garder simples et indépendants des produits.
Le moteur de facturation évalue ensuite ces enregistrements d'utilisation facturable, qui contiennent désormais un identifiant associé à un produit dans notre base de données de prix. Au minimum, ce processus consiste à additionner l'utilisation sur une période donnée et à multiplier la quantité par le prix du produit pour calculer les ECU. Dans certains cas, il doit également segmenter l'utilisation en niveaux en fonction de l'utilisation cumulée tout au long du mois et les mapper à des niveaux de produits dont le prix est fixé individuellement. Afin de tolérer les retards dans le processus en amont sans manquer d'enregistrements, l'utilisation est facturée au moment où elle arrive dans le datastore de l'utilisation facturable, mais le prix est calculé en fonction de la date à laquelle elle s'est produite (pour s'assurer que nous n'appliquons pas le mauvais prix pour une utilisation arrivée « en retard »). Notre processus de facturation dispose ainsi d'une capacité d'autorégulation.
Enfin, une fois les ECU calculées, nous évaluons tous les coûts supplémentaires (comme pour le support) et les intégrons dans les calculs de facturation, qui aboutissent finalement à une facture (envoyée par nous ou par l'un de nos partenaires de marketplace cloud). Cette dernière partie du processus n'est pas nouvelle ni unique à Serverless et est gérée par les mêmes systèmes qui facturent notre produit hébergé.
Points à retenir
La construction d'une plateforme d'infrastructure qui offre des fonctionnalités similaires sur plusieurs CSP est un défi complexe. L'équilibre entre fiabilité, scalabilité et rentabilité nécessite des itérations continues et des compromis. Les implémentations de Kubernetes varient considérablement selon les fournisseurs de services cloud, et garantir une expérience cohérente entre eux nécessite des tests approfondis et une personnalisation poussée.
En outre, l'adoption d'une architecture sans serveur n'est pas seulement une transformation technique, mais aussi un changement culturel. Il est nécessaire de passer du dépannage réactif à une optimisation proactive du système et de donner la priorité à l'automatisation pour réduire la charge opérationnelle. Au cours de notre parcours, nous avons appris que la création d'une plateforme sans serveur réussie repose autant sur des décisions architecturales que sur la promotion d'un état d'esprit ouvert à l'innovation et à l'amélioration continues.
Prochaines étapes
Pour réussir dans le monde sans serveur, il est essentiel de fournir une expérience client exceptionnelle, d'optimiser les opérations de manière proactive et de maintenir en permanence un équilibre entre fiabilité, scalabilité et rentabilité. À l'avenir, nous continuerons de nous concentrer sur la création de nouvelles fonctionnalités pour nos clients sur Elastic Cloud Serverless, faisant du serverless le meilleur endroit pour exécuter Elasticsearch pour tous les utilisateurs.
L'avenir de la recherche, de la sécurité et de l'observabilité est là, sans compromis sur la vitesse, l'échelle ou le coût. Découvrez Elastic Cloud Serverless et Search AI Lake pour débloquer de nouvelles opportunités avec vos données. Apprenez-en davantage sur les possibilités du serverless ou commencez votre essai gratuit dès maintenant.
La publication et la date de publication de toute fonctionnalité ou fonction décrite dans le présent article restent à la seule discrétion d'Elastic. Toute fonctionnalité ou fonction qui n'est actuellement pas disponible peut ne pas être livrée à temps ou ne pas être livrée du tout.
Dans cet article, nous sommes susceptibles d'avoir utilisé ou mentionné des outils d'IA générative tiers appartenant à leurs propriétaires respectifs qui en assurent aussi le fonctionnement. Elastic n'a aucun contrôle sur les outils tiers et n'est en aucun cas responsable de leur contenu, de leur fonctionnement, de leur utilisation, ni de toute perte ou de tout dommage susceptible de survenir à cause de l'utilisation de tels outils. Lorsque vous utilisez des outils d'IA avec des informations personnelles, sensibles ou confidentielles, veuillez faire preuve de prudence. Toute donnée que vous saisissez dans ces solutions peut être utilisée pour l'entraînement de l'IA ou à d'autres fins. Vous n'avez aucune garantie que la sécurisation ou la confidentialité des informations renseignées sera assurée. Vous devriez vous familiariser avec les pratiques en matière de protection des données personnelles et les conditions d'utilisation de tout outil d'intelligence artificielle générative avant de l'utiliser.
Elastic, Elasticsearch et les marques associées sont des marques commerciales, des logos ou des marques déposées d'Elasticsearch N.V. aux États-Unis et dans d'autres pays. Tous les autres noms de produits et d'entreprises sont des marques commerciales, des logos ou des marques déposées appartenant à leurs propriétaires respectifs.
Partager
- Share on Twitter
Partager sur Twitter
- Share on LinkedIn
Partager sur LinkedIn
- Share on Facebook
Partager sur Facebook
- Share by Email
Partage par e-mail
- Print this page
Imprimer