The journey to support nanosecond timestamps in Elasticsearch
The ability to store dates in nanosecond resolution required a significant refactoring within the Elasticsearch code base. Read this blog post for the why and how on our journey to be able to store dates in nanosecond resolution from Elasticsearch 7.0 onwards.
Sometimes millisecond resolution isn't enough
Elasticsearch supports a date mapping type that parses the string representation of a date in a variety of configurable formats, converts this date into milliseconds since the epoch and then stores it as a long value in Lucene. This simple yet powerful approach has brought us a long way.
However, there are many use cases which require dates to be stored at a higher resolution than just milliseconds. It's not only the common log file case, which most of the time is fine with milliseconds, but think of the manufacturing industry, where many sensors trigger or actions can take place within a single millisecond. This is where you need to be able to store these kind of events at a higher resolution.
There was a problem with this though. The existing way of parsing and storing dates simply did not support storing with any resolution higher than milliseconds. The library Elasticsearch uses is called Joda-Time, and it used to be the de-facto standard for handling time in Java. However, this library is in maintenance mode and will not be extended further, even though it still receives bug fixes and especially time zone database updates. The reason for this is simple: with the release of Java SE 8 onwards, the Date and Time API (JSR 310) is part of JDK.
The good news of this change is that the java.time package has support for dates in nanosecond resolution. So, all we have to do is to convert our code to just Java Time instead and we are good? Well, not so fast...
Storing dates in nanosecond resolution
As already mentioned in the beginning of the post, currently dates are stored in Lucene as a long representing the number of milliseconds since the epoch. What are the possibilities to store a nanosecond-based date in Elasticsearch? There are a couple of options to solve this. One could split the date in several parts and store it in different fields. One could also store the date in a floating point value to encode the days since the epoch and the current nanos of the day. This, however, would have meant that dates would be stored in a different manner compared to a millisecond-based date, and the idea of keeping things simple by storing it as a long as well was most appealing.
We finally decided that the best solution was to store the date as a long value in nanoseconds. This, however, comes with a drawback. The range of potential dates is reduced. So if you store nanoseconds in a long, the range is reduced to dates up to roughly the year 2262.
However, you do not need to store the birthdays of your Wikipedia data set with such a high resolution. The scenario in which you need nanosecond resolution is usually when you process log files or events, which tend to fall into the range of 1970 to 2262.
The result of this is a new field mapper called date_nanos which is very similar to the date mapper except that it represents dates as the number of nanoseconds since the epoch instead of the number of milliseconds. Both mappers take the same configuration parameters, accept the same collection of input formats, and work similarly in searches and aggregations. See the date_nanos datatype documentation for more details. This also enables us to reuse the existing date field mapper code by replacing the methods which convert a date to a long and vice versa with their respective implementations.
Migrating code to Java Time
In order for the above new field mapper to exist, the first step was to remove the Joda-Time code and replace it with Java Time equivalents. If you have worked with Joda-Time, many concepts look remarkably similar, but some concepts have changed. There is also a blog post outlining some changes, but it is pretty high level.
First, the Java Time API is encapsulated very well, making it hard to change or extend anything — which also is not needed most of the time. However, if you find the right place to extend, then everything works as expected. For example we needed a custom epoch_millis date parser in order to parse an existing format, where the date consisted of milliseconds since the epoch, and Java Time does not ship with anything like that. Second, the API uses immutable data structures, which may create more objects than Joda-Time.
How did we approach the migration? We created a new feature branch, which was also properly added to our CI infrastructure, and this branch contained all the changes regarding the conversion for now and the master branch was merged into it every day.
The next step was basically a hard cut, where we removed most Joda-Time uses from the server/ directory, which is the very core of Elasticsearch, as it includes all the mapping, search, and aggregation logic. This led to a fair share of tests failing and required us to tackle them one by one.
Our main goal was to keep moving while not stopping or breaking anything in the main development branch. Also, this way the porting of other modules or plugins like ingest, alerting, or monitoring from Joda-Time to Java Time could be done in parallel once the initial change had been done.
However, even though Joda-Time and Java Time were written by the same person, this does not mean that they are fully compatible, as years of experience have led to different decisions. Just replacing the code was not an option, as we have to be backwards compatible with the existing codebase.
The backwards compatibility elephant in the room
Before even thinking of merging the Java Time feature branch into master, we had to come up with a solution to ensure that users are able to configure everything before upgrading, so that upgrades work as expected. This means that even the most recent Elasticsearch 6 release has support for parsing Java Time-based dates in order to provide a migration path so that users will be able to use Elasticsearch 7, which will not have support for Joda-Time-based dates.
First, we had to make sure the name-based formatters work in the same way in both variants. In order to do this, a DateFormatter interface was created that featured Java and Joda-Time implementations. Also a test that compares the output between formatters had been added, named JavaJodaTimeDuellingTests.
However, there are subtle differences between the Java and Joda-Time-based formats — for example, the YYYY format string under Joda-Time represents the usual date-based year, whereas this formatter under Java Time resembles the week-based year and thus could change at different times at the end of a year. This means a Joda-Time format string like YYYY.MM.dd would need to be converted to yyyy.MM.dd in Java Time.
Our solution to address this problem was to introduce an 8 prefix for Java-based dates and to emit proper warnings if you are using a Joda-Time formatter that may be different under Java. This way you can switch from YYYY.MM.dd to 8yyyy.MM.dd in Elasticsearch 6, then upgrade to Elasticsearch 7, where this notation is supported as well, and after the upgrade you can use yyyy.MM.dd in Elasticsearch 7.
The next hurdle we met was backwards compatibility in scripting. If you are accessing a date field in a script, you can directly access Joda-specific methods which do not exist in Java Time. The solution to this is to expose an object that still features the Joda-Time-based methods as well as exposing all the Java Time-based methods. This solution requires we mark the Joda-Time-based ones as deprecated and log a deprecation message that contains the new method call to use. For more information you can check out the JodaCompatibleZonedDateTime.
Another part of the code that heavily used Joda-Time was our rounding mechanism, which can round based on date-time units or intervals; see the Java Time rounding class. Again, creating a duelling test ensures that the same randomized input yields the same output for either implementation.
Benchmarks to the rescue!
All right, so everything has been ported in a backwards compatible manner and we have our fancy dueling implementations to ensure the same results, so now it's ready, right? Well ... turns out that writing code does not imply it is performant.
After merging the branch our nightly benchmarks exposed two issues: lower indexing throughput as well as lower aggregation performance for date histograms — very unlikely that this could have been introduced by something other than our switch to Java Time.
Exhibit A: Decrease of indexing throughput
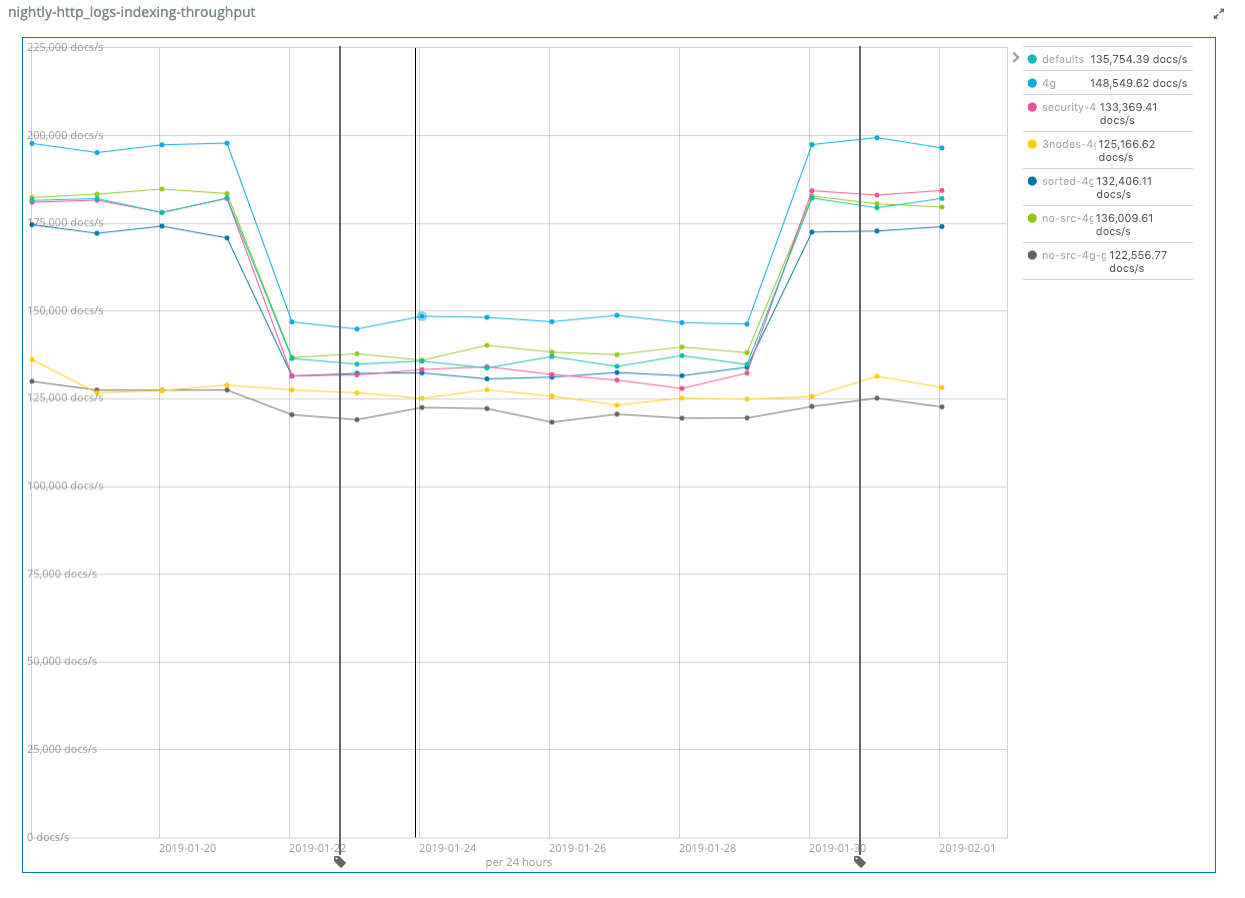
As you can see on the left side of the graph, there was a 20% indexing throughput reduction after the merge. Checking the logs from the benchmark we could see an exorbitant amount of exceptions being thrown by Java Time.
We found a similar issue very early before merging with the initial implementation of date parsing. If we specified more than one date using ||, for example strict_date_optional_time||epoch_millis, and the first date format did not match the input, an exception was thrown. This led to a severe performance degradation, as throwing exceptions and creating the corresponding stack traces is extremely expensive. We refactored the code to append the Java date formatters into one big Java date formatter, so that the parsing code keeps going if a certain format cannot be parsed instead of catching exceptions and trying the next format.
In the above case, however, we found a similar issue when converting from a TemporalAccessor to a ZonedDateTime in our own code, where an exception was thrown due to using ZonedDateTime.from. Instead of throwing exceptions we queried for the supported fields of the TemporalAccessor (which, for example, is different if you parse a date without a timezone or just the epoch millis) and thus created the proper ZonedDateTime object manually. After applying those fixes and ensuring no exceptions were thrown, the performance was restored, as you can see on the right side of the graph.
Exhibit B: Aggregation latency spike
The next major degradation was a very high latency when a date histogram was used, which would skyrocket compared to the Joda-Time implementation. We had created a few JMH microbenchmarks to check performance between Joda-Time and Java Time, and in every scenario Java Time was much faster, so what was going on here?
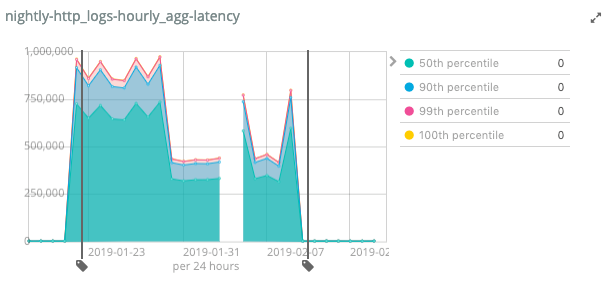
As you can see on the left side of the graph, the total aggs latency rose sharply after merging the Java-Time branch — the y-axis shows the latency in milliseconds. Fixing this took two iterations of improvements. Even though the first fix, added a few days after the initial commit, reduced the latency by more than fifty percent, we were nowhere near the figures we had before. The latency was still much higher judging from the graph.
Turns out we forgot a specific test case in our microbenchmarks: the case of a UTC-based aggregation. Why is this special? Dates that are already represented as UTC do not require any timezone calculations. There is an optimization in the Joda-Time-based code which shortcuts this case. We tried representing this special case with Java Time objects, but it turned out that the Joda code was so fast because it could easily operate on the long value representing milliseconds since the epoch, so that all the rounding in the UTC case was based on simple arithmetic operations.
In order to restore to the original performance we made sure that in this very common case we also execute all the calculations based on the milliseconds since the epoch without using Java objects. This change finally got us back to the previous execution times for the default aggs case; see the RoundingBenchmark.
Exhibit C: increased GC run times
Last but not least: not everything is about application performance metrics. It’s also about making sure that you do not put additional pressure on the garbage collector.
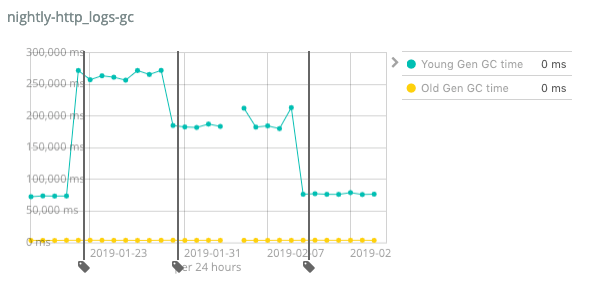
As you can see in the graph, there was also a huge spike of GC collection time after the initial merge. Also the first fix, which reduced the latency by 50%, also reduced the total GC time significantly. The main reason for this was a fix not to use the fluent API in Java Time (which creates new immutable objects while doing rounding to create aggregation buckets), but to ensure to create a single object per bucket, no matter its granularity. Even though the final fix to use the milliseconds since the epoch did not even touch this code path, all date histogram aggregations using a non-UTC timezone will benefit from this optimization.
Finally, the GC runtimes dropped to roughly the same level after the same fix as aggregation latency was applied. Lessons learned: Use microbenchmarks as early as you can, and also run benchmarks before merging your code into the main line.
Limitations
Apart from the already mentioned limitation of the nanosecond-based field mapper, which is only able to store dates between 1970 and 2262, there are some other limitations.
Aggregation buckets will be in millisecond resolution, even if you query a field of type date_nanos. The main reason for this is to prevent bucket explosions.
Also, you should have the ability to update your JDK to later versions, in case of bugs in Java Time, if you are using the Elasticsearch distribution without the included JDK. For example, the Java Time implementation in JDK 8 is not able to parse the timezone GMT0, and this has only been fixed from JDK 9 onwards.
Use the upgrade assistant
First, you should always be on the latest 6.x release before doing upgrades. In the case of this migration, you will see more deprecation warnings in latest releases, as we found a few more formats that require to be dealt with.
Second, also make sure you are upgrading to the latest 7.x version as possible. The upgrade assistant got some new functionality over time to check for indices that have been created under Elasticsearch 6.x that might contain deprecated date formats.
Soon: searching indices with different resolutions
In one of the next releases after 7.0, we want to add a mechanism allowing you to search and sort across indices with date and date_nanos fields. This requires us to do some conversion internally to ensure that we keep precision and that scroll searching and search_after keep working, but we think this is worth a bit of work, as it would let you easily update your index templates for your logging-based data and instantly benefit from the higher resolution of timestamps.
Going through the Elastic Stack
Adding this functionality to Elasticsearch is only the beginning. As soon as several indices with different resolutions can be searched properly, we will properly support this in Kibana and Beats, so that you can store dates in nanosecond resolution and query them. Stay tuned for more updates about this in the future, and reach out on Discuss if you have any questions.