Introduction de machine learning pour la Suite Elastic
Aujourd'hui, nous sommes fiers d'annoncer la sortie des premières fonctionnalités de machine learning pour la Suite Elastic. Rejoindre Elastic nous a donné un véritable coup d'accélérateur ! Après 7 mois intenses, la technologie machine learning de Prelert est entièrement intégrée à la Suite Elastic via X-Pack. Nous sommes très enthousiastes à l'idée d'avoir des retours des utilisateurs.
Remarque : avant de vous laisser gagner par l'excitation, gardez à l'esprit que cette fonctionnalité ne sera disponible qu'en version bêta dans la version 5.4.0.
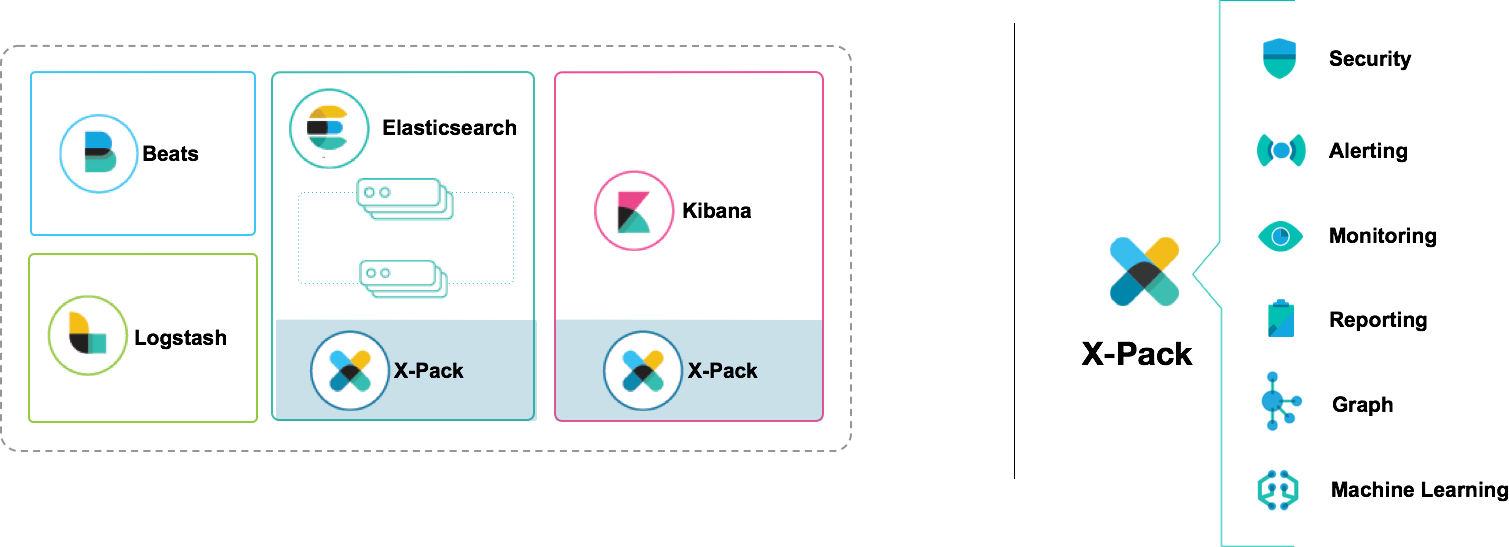
Machine Learning
Notre objectif est de fournir aux utilisateurs des outils qui leur permettent d'exploiter les indicateurs relatifs à leurs données Elasticsearch. À nos yeux, machine learning est une extension naturelle des fonctionnalités de recherche et d'analyse dans Elasticsearch. Par exemple, Elasticsearch permet de rechercher tous les transactions associées à l'utilisateur « Steve » dans un volume de données considérable, en temps réel. En outre, vous pouvez également utiliser des agrégations et des visualisations pour afficher les dix produits qui se vendent le mieux ou les évolutions des tendances de transactions. Avec machine learning, vous pouvez désormais aller plus loin et poser des questions telles que : « Certains de mes services ont-ils changé de comportement ? » ou encore « Y a-t-il des processus inhabituels qui s'exécutent sur mes machines ? » Pour répondre à ces questions, il faut faire appel à des modèles comportementaux, qui peuvent être calculés automatiquement à partir de données, grâce à des techniques de machine learning.
Néanmoins, dans le secteur du logiciel, le terme machine learning recouvre actuellement un vaste champ d'applications. Il est utilisé pour décrire un large panel d'algorithmes et de méthodes dévolues à la prévision basée sur les données, à la prise de décision et à la modélisation. C'est pourquoi il est important de décrire précisément ce que nous faisons.
Détection d'anomalies dans les données temporelles
Actuellement, les fonctionnalités de machine learning de X-Pack fournissent des capacités de « détection d'anomalies dans les données temporelles » faisant appel à du machine learning non supervisé.
Au fil du temps, nous avons l'intention d'ajouter de nouvelles fonctionnalités de machine learning. Cependant, nous souhaitons pour l'instant fournir de la valeur ajoutée aux utilisateurs qui stockent dans Elasticsearch des données temporelles telles que les fichiers logs, les métriques applicatifs et de performance, les flux de réseau ou des données financières et des données de transactions.
Exemple 1 : recevez une alerte automatique pour toute évolution inhabituelle de la valeur d'un indicateur de performance clé
Le cas d'utilisation le plus évident de cette technologie est l'identification de la déviation d'un indicateur ou d'un taux d'événement par rapport à son comportement habituel. Il est notamment possible de répondre aux questions suivantes : le délai de réponse de mon service s'est-il considérablement accru ? Le nombre de visiteurs du site Web diffère-t-il considérablement de la normale à cette heure donnée ? Habituellement, on utilise des règles, des seuils et des statistiques simples pour ce type d'analyse. Malheureusement, ces méthodes simples sont rarement efficaces pour traiter des données du monde réel, car elles se basent souvent sur des hypothèses statistiques erronées (ex. : la loi de Gauss), qui ne permettent pas d'établir des tendances (à long terme ou périodiques) ou sont sensibles aux variations.
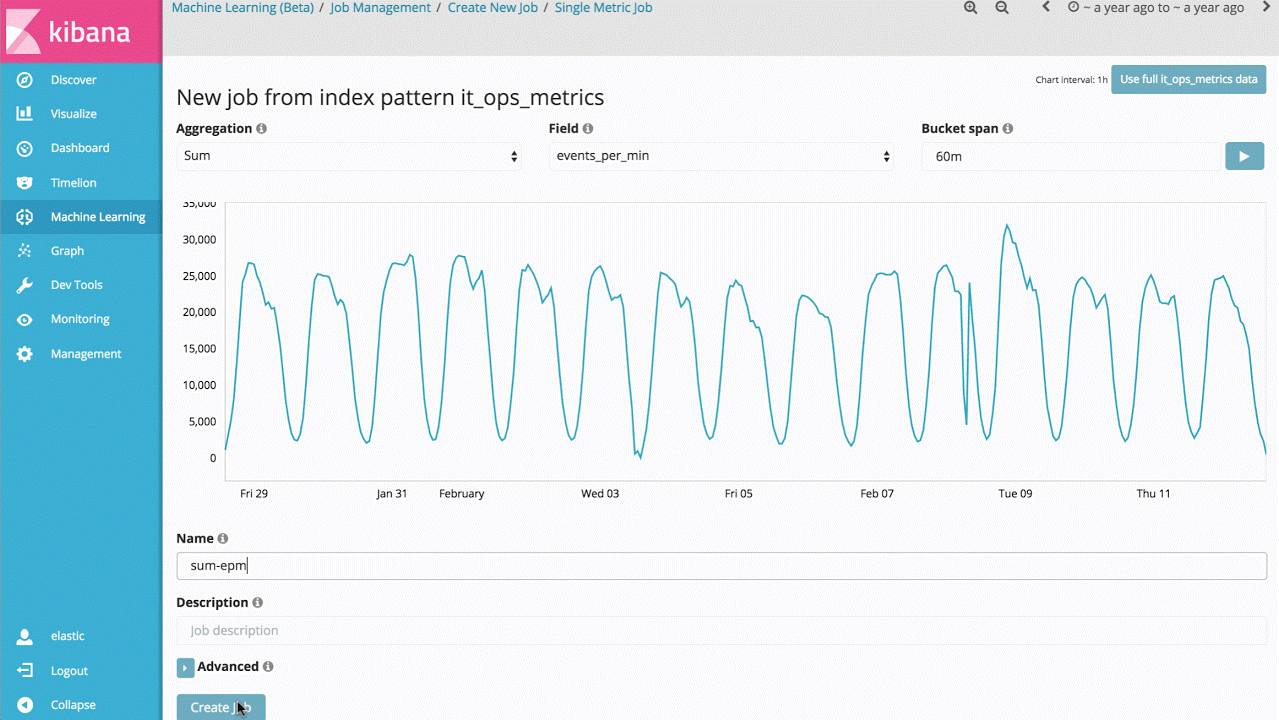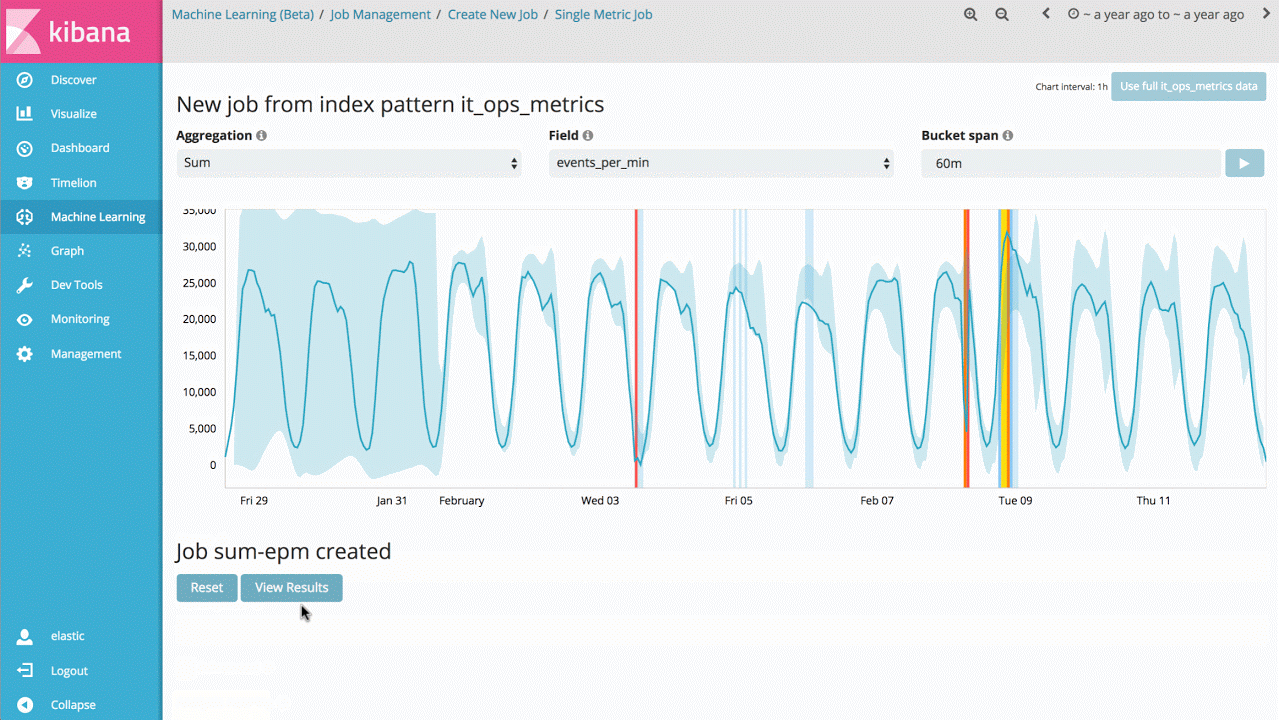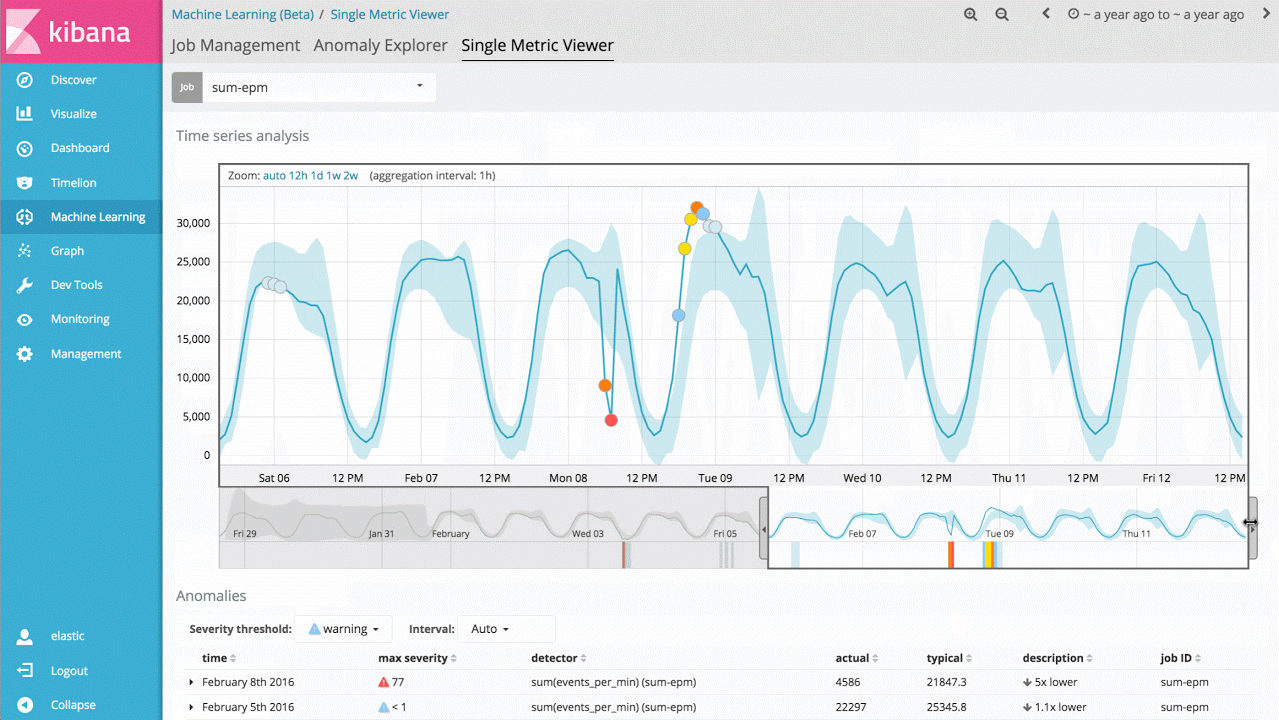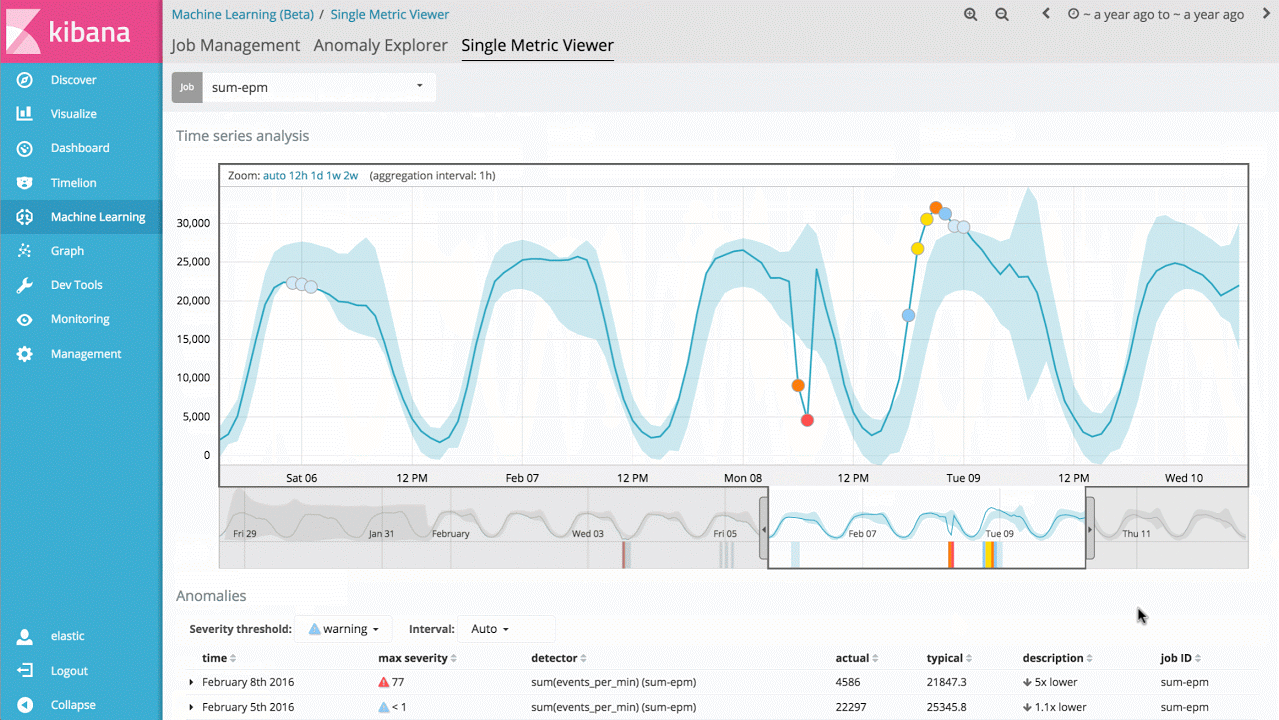
Ainsi, l'une des premières fonctionnalités de machine learning que vous pourrez mettre en œuvre est une tâche prenant la forme d'un indicateur simple (single metric job). Celle-ci vous permettra de découvrir comment machine learning apprend à identifier les situations normales ainsi que les anomalies relatives à des données temporelles unidimensionnelles. Si les anomalies découvertes sont utiles, vous pourrez exécuter cette analyse en temps réel en permanence pour recevoir une alerte lorsque l'une d'entre elles survient.
Ce cas d'utilisation peut sembler relativement simple, toutefois, le back-end du produit comporte un grand nombre d'algorithmes complexes de machine learning non supervisé ainsi que des modèles statistiques qui garantissent une réaction robuste et précise face aux signaux arbitraires.
L'implémentation est optimisée pour être exécutée de façon native dans un cluster Elasticsearch afin que des millions d'événements puissent être analysés en l'espace de quelques secondes.
Exemple 2 : suivez automatiquement l'évolution de milliers d'indicateurs
Machine learning prend en charge des centaines de milliers d'indicateurs et de fichiers log : il ne vous reste plus qu'à analyser conjointement plusieurs indicateurs ! L'analyse peut être menée sur plusieurs indicateurs connexes présents sur une même machine, sur des indicateurs de performance d'une base de données ou d'une application, ou sur de multiples fichiers logs issus de plusieurs machines. Dans ce cas de figure, il est possible de partitionner l'analyse et d'agréger les résultats en un seul tableau montrant les irrégularités du système.
Par exemple, si je dispose du délai de réponse pour un grand nombre de services d'application, je peux tout simplement analyser dans la durée celui de chaque service. Ainsi, je peux identifier les services dont le comportement est anormal et bénéficier d'un aperçu des irrégularités du système.
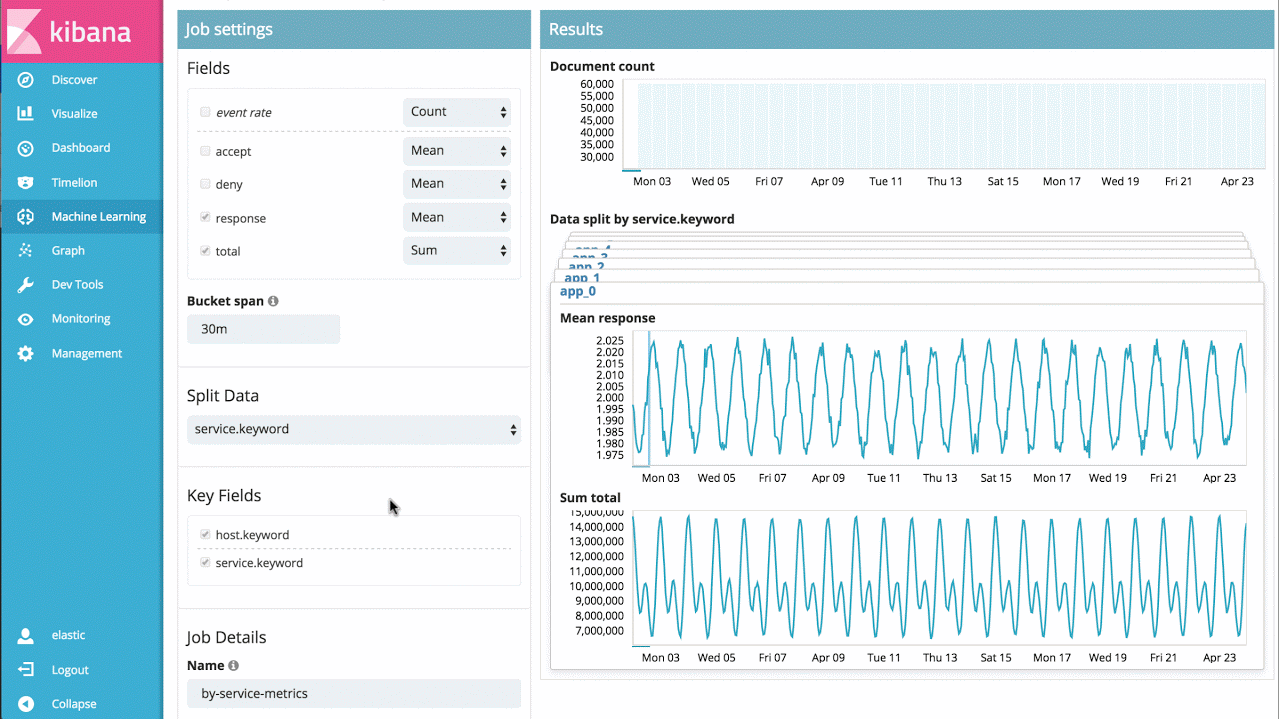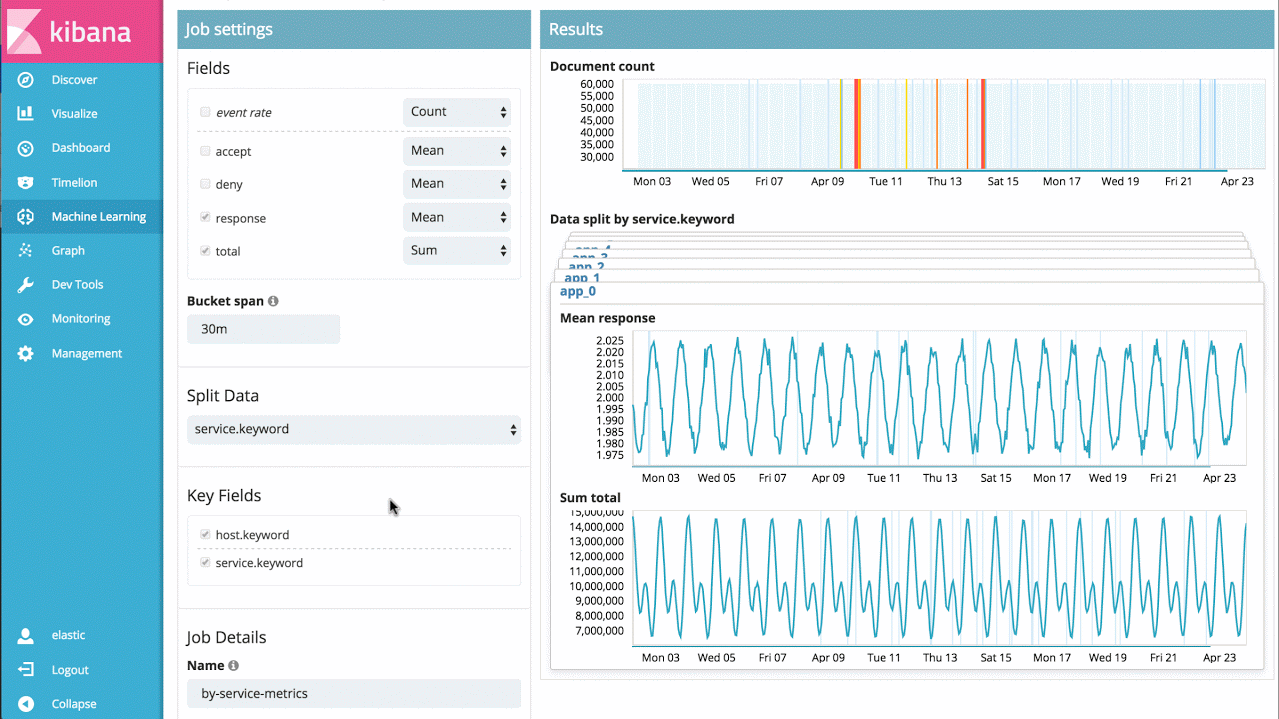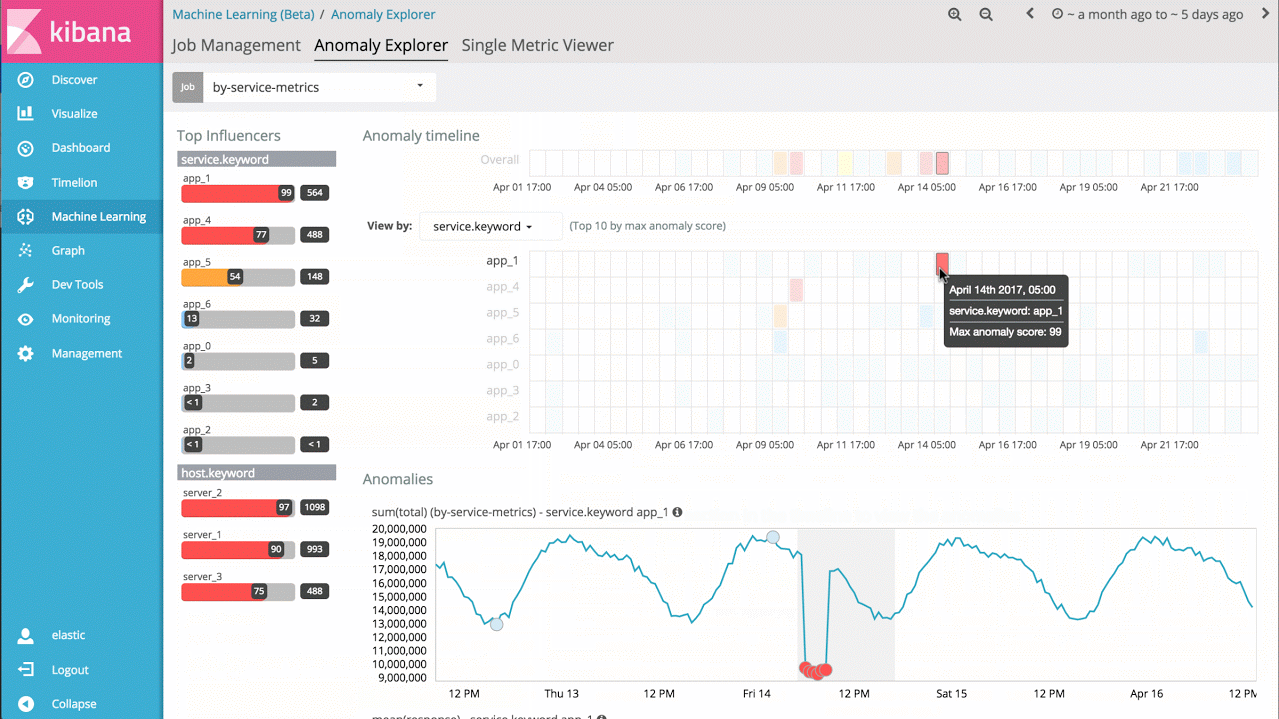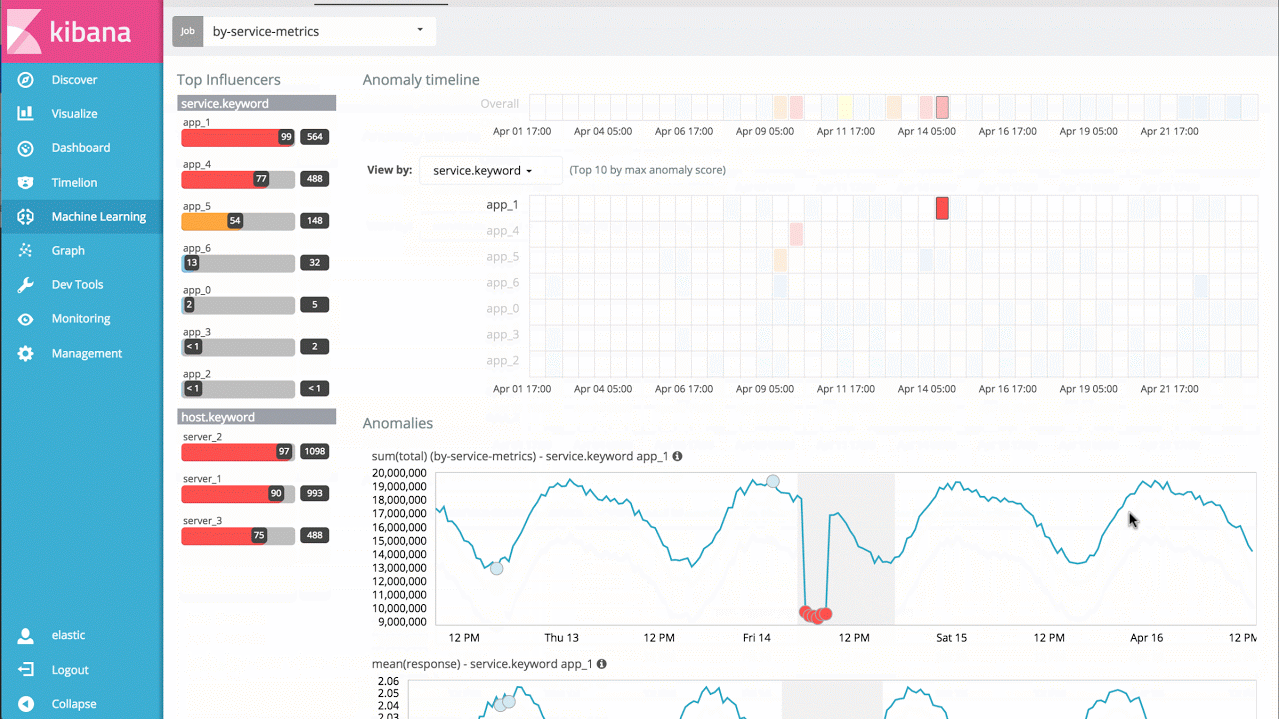
Exemple 3 : tâches avancées
Enfin, nous offrons toute une série d'autres fonctionnalités de machine learning plus avancées. Par exemple, vous pouvez rechercher des utilisateurs dont le comportement diverge par rapport à un groupe donné, identifier du trafic DNS inhabituel ou des embouteillages dans les rues londoniennes. Ces tâches avancées mettent à votre disposition un outil flexible pour analyser les données temporelles stockées dans Elasticsearch.
Intégration à la Suite Elastic
Machine learning est une fonctionnalité de X-Pack. Une fois l'installation de X-Pack finalisée, les fonctionnalités de machine learning pourront être utilisées pour analyser en temps réel des données temporelles dans Elasticsearch. Les tâches seront automatiquement distribuées et gérées sur tout le cluster Elasticsearch, à l'instar des index et des shards. Ceci signifie également que les tâches de machine learning sont résistantes à la défaillance d'un noeud du cluster. Du point de de vue de la performance, l'intégration étroite permet aux données de ne jamais quitter le cluster. En outre, les agrégations Elasticsearch permettent d'améliorer considérablement la performance de certaines tâches. L'intégration étroite octroie également un autre avantage: elle permet de créer des tâches de détection des anomalies et de visualiser les résultats directement dans Kibana.
Les données sont analysées in situ et ne quittent jamais le cluster. Cette approche permet de bénéficier d'une performance accrue et d'un avantage opérationnel par rapport à l'intégration de données Elasticsearch dans des outils d'analyse de données externes. À mesure que nous développerons de nouvelles technologiques dans ce secteur, les avantages liés à cette architecture seront de plus en plus marqués.
Essayez-le aujourd'hui et faites-nous part de votre avis
Les fonctionnalités de machine learning sont disponibles en version bêta dans X-Pack 5.4, qui est téléchargeable dès maintenant. Nous avons hâte que vous nous fassiez part de votre feedback. N'hésitez pas à télécharger la version 5.4, à installer X-Pack et à nous contacter directement, ou via notre forum de discussion.