Comment passer d’une solution Elasticsearch autogérée à Elastic Cloud sur AWS
Nous assistons à une migration de plus en plus fréquente de charges de travail sur site vers le cloud. Elasticsearch est une solution présente depuis de nombreuses années déjà et nos utilisateurs et clients la gèrent en général eux-mêmes sur site. Elasticsearch Service sur Elastic Cloud, notre service Elasticsearch géré qui s’exécute sur Amazon Web Services (AWS), Google Cloud et Microsoft Azure dans de nombreuses régions, est la meilleure façon d’utiliser la Suite Elastic et nos solutions pour la recherche d’entreprise, l’observabilité et la sécurité.
Si vous souhaitez migrer depuis une solution Elasticsearch autogérée, Elasticsearch Service s’occupe :
- du provisionnement et de la gestion de l'infrastructure sous-jacente ;
- de la création et de la gestion de clusters Elasticsearch ;
- de l'augmentation ou de la réduction des clusters ;
- des mises à niveau, de l’application des correctifs et de la création de snapshots.
Ainsi, vous aurez plus de temps pour concentrer vos efforts sur la résolution d’autres problématiques.
Ce blog explique comment migrer vers Elasticsearch Service en créant un snapshot de votre cluster Elasticsearch, puis en le restaurant sur Elasticsearch Service.
Créez un snapshot du cluster
Les premières choses à considérer lorsqu’on migre d’une solution Elasticsearch autogérée à Elasticsearch Service sont le fournisseur cloud et la région à utiliser. Ces paramètres dépendent des charges de travail existantes déployées, de votre stratégie cloud et de divers autres facteurs.
Nous allons passer en revue ce processus pour Elasticsearch Service sur AWS. Nous verrons comment faire de même pour Google Cloud et Azure très bientôt.
Le moyen le plus simple de migrer les données d’un cluster Elasticsearch vers un autre cluster est de créer un snapshot du cluster, puis de le restaurer dans le nouveau cluster Elasticsearch Service.
Il existe plusieurs façons de créer un snapshot de cluster. La plus simple consiste à effectuer une opération de snapshot unique.
Si l’on part du principe que votre Elasticsearch ingère constamment des données, l’opération de snapshot unique a pour inconvénient d’engendrer un décalage et une perte de données entre le moment de la création du snapshot et sa restauration dans le nouveau cluster. Afin de minimiser ce décalage, il est conseillé de créer une politique de cycle de vie des snapshots. Si votre cluster Elasticsearch n’ingère pas de données constamment, comme dans le cas d’une recherche, un snapshot unique ne pose aucun problème.
Avant de créer un snapshot de cluster local, vous devez configurer le compartiment AWS S3 à l’endroit où sera stocké le snapshot du cluster local. Il s’agit de l’emplacement à partir duquel le nouveau cluster Elasticsearch Service exécuté sur AWS restaurera l’état du cluster.
Pour ce faire, les étapes incluent en gros :
- la configuration du stockage dans le cloud (dans ce cas, le compartiment AWS S3) ;
- la configuration du référentiel de snapshots local ;
- la configuration de votre politique de snapshots ;
- le provisionnement du nouveau cluster sur Elasticsearch Service ;
- la configuration du référentiel de snapshots personnalisé pour le cluster Elasticsearch Service ;
- la restauration du cluster Elasticsearch Service à partir d’un snapshot local.
Configurez le stockage dans le cloud
- Créez un compartiment S3. Le compartiment S3 doit être dans la même région que celle sélectionnée pour votre cluster Elasticsearch Service :
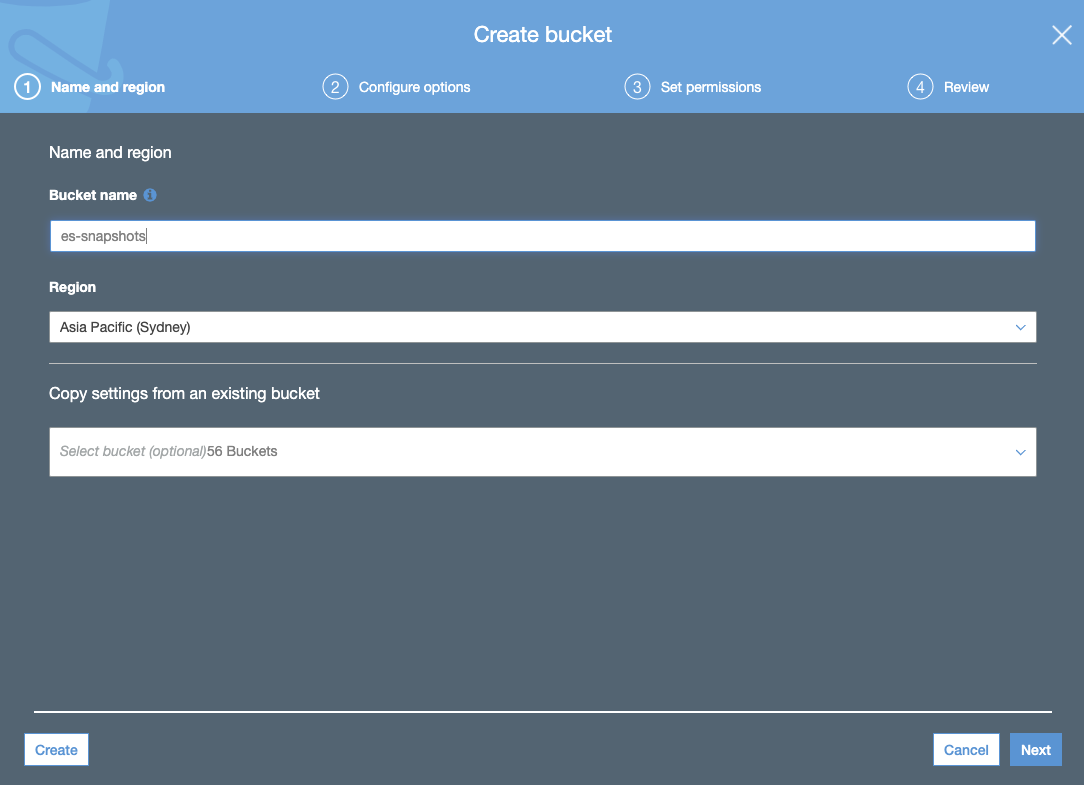
- Créez la politique de compartiment S3 via l’onglet JSON et ajoutez le JSON de la politique de compartiment S3 (en utilisant le nom du compartiment) :
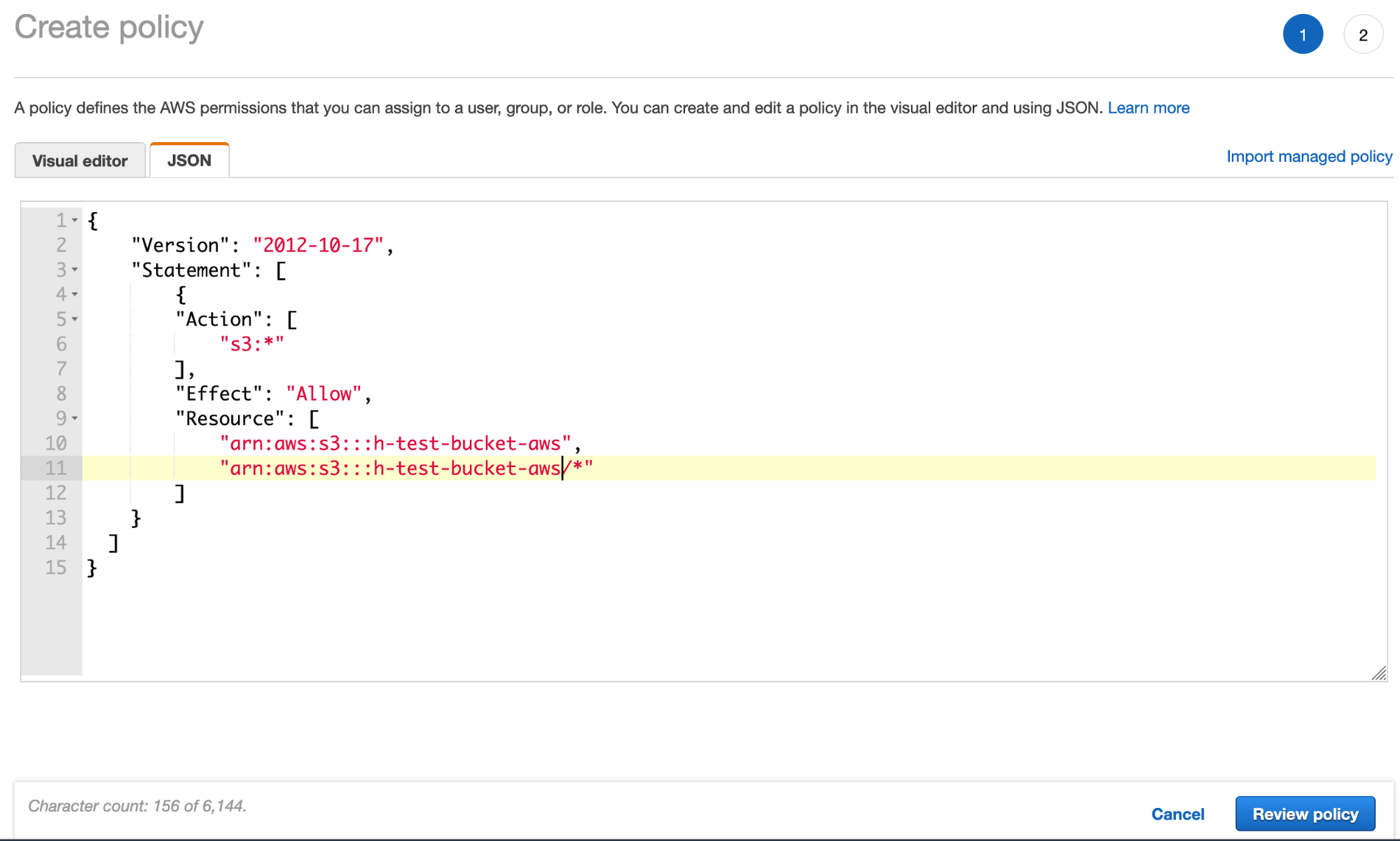
- Cliquez sur Review policy (Consulter la politique) et donnez un nom à votre politique :
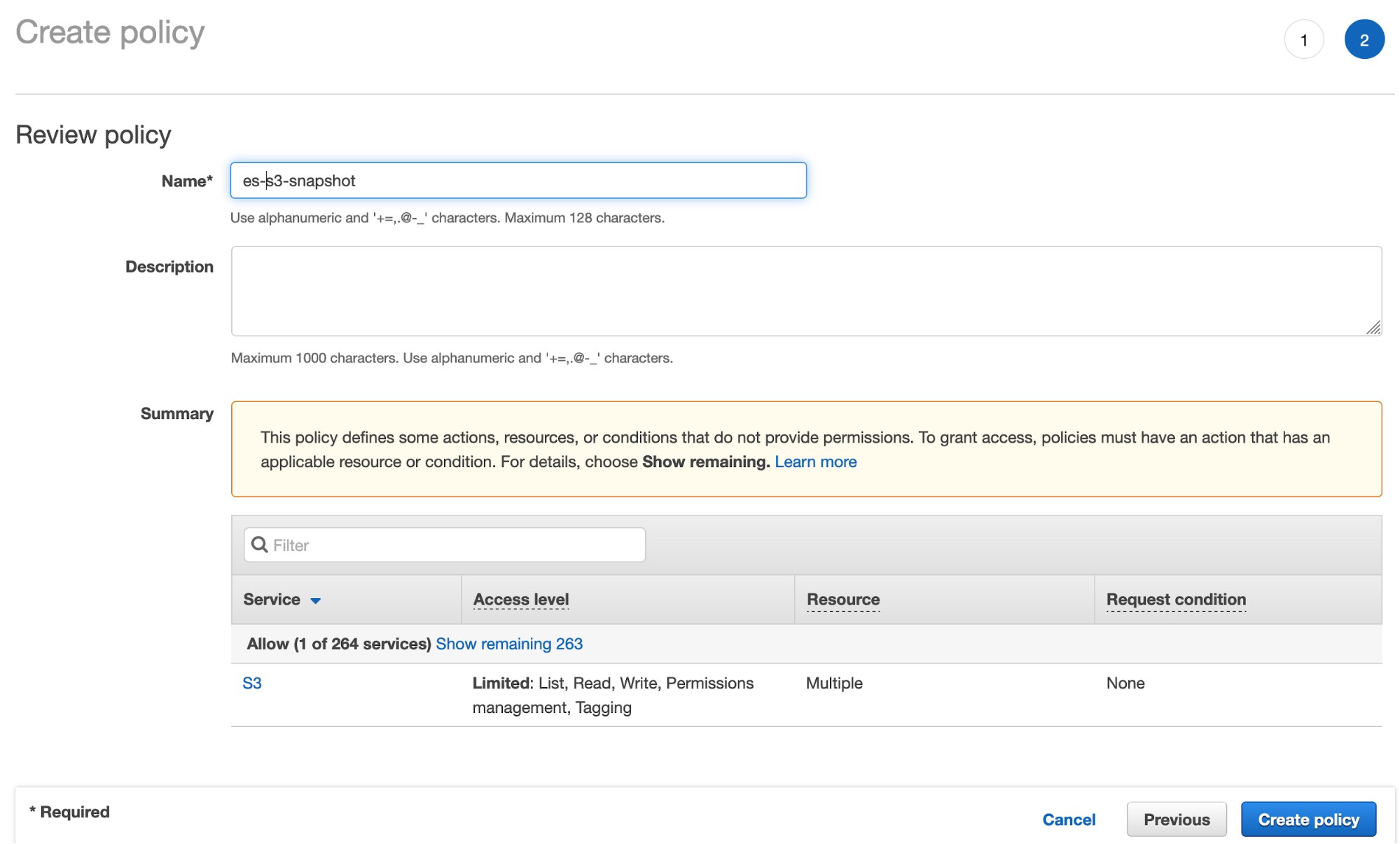
- Créez l’utilisateur IAM et affectez la politique de compartiment S3 créée ci-dessus :
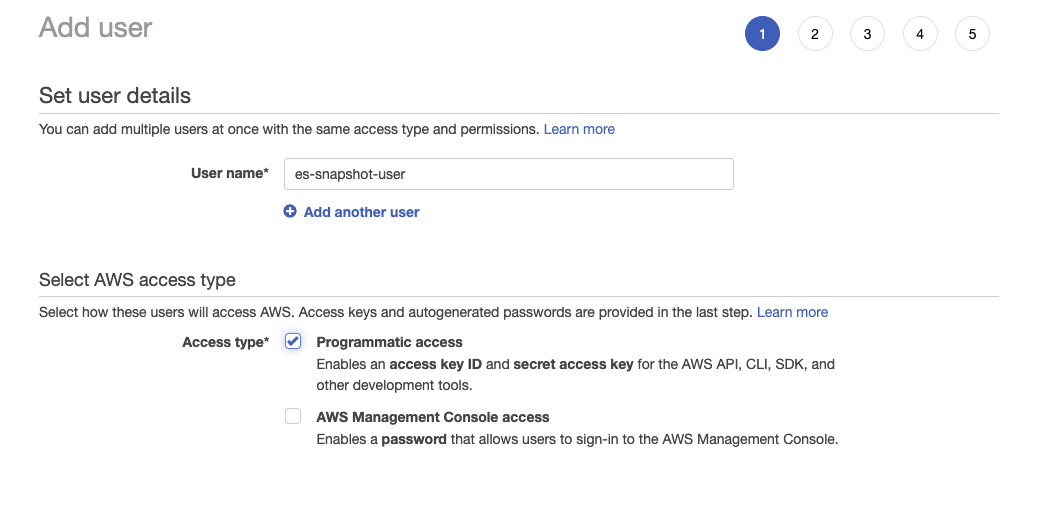
- Cliquez sur Next: Permissions (Suivant : Autorisations), sélectionnez Attach existing policies directly (Joindre directement les politiques existantes) et cherchez la politique que vous avez créée à l’étape précédente :
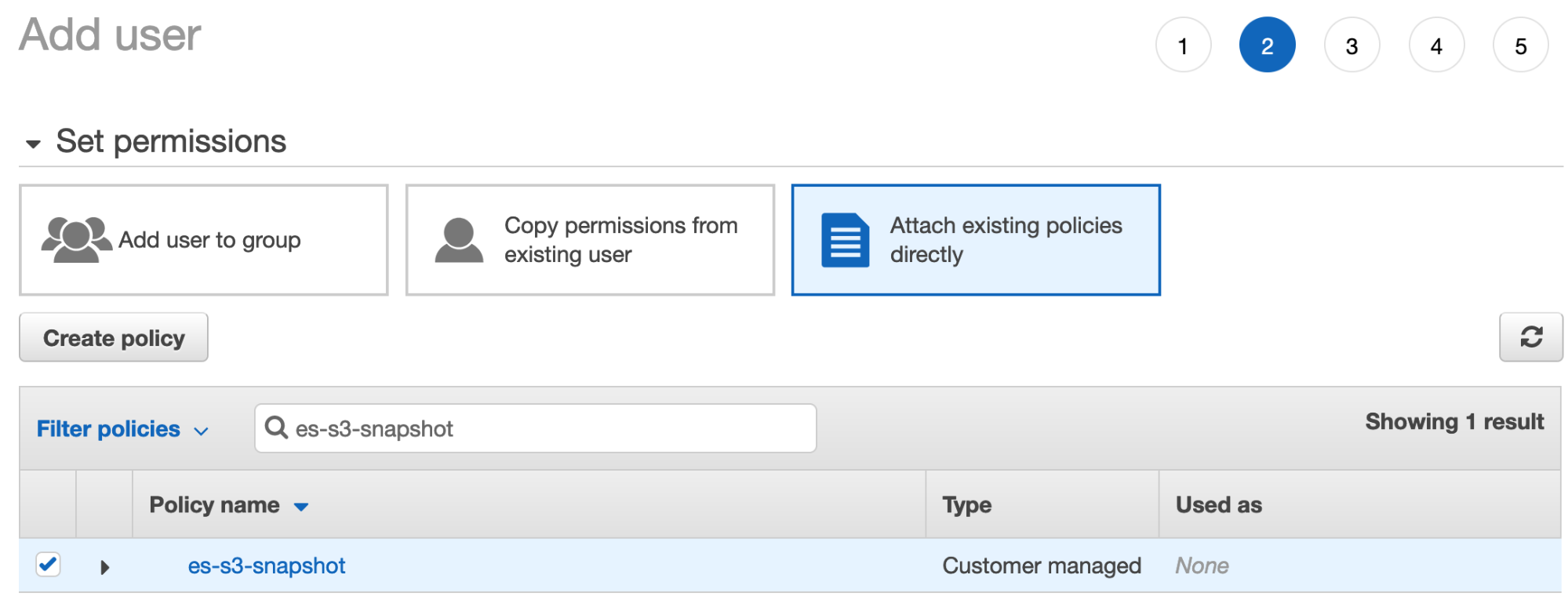
- Vérifiez que la politique est bien cochée, puis cliquez sur Next:tags (Suivant : balises). Vous pouvez ignorer l’étape d’ajout des balises et cliquer sur Create User (Créer un utilisateur).
- Téléchargez les identifiants de sécurité de l’utilisateur.
Configurez le référentiel de snapshots local
1. Installez le plug-in S3
Installez le plug-in Elasticsearch S3 sur votre déploiement sur site en exécutant la commande ci-après sur chaque nœud Elasticsearch local depuis votre répertoire d’accueil Elasticsearch :
sudo bin/elasticsearch-plugin install repository-s3
Vous devrez redémarrer le nœud après avoir exécuté cette commande.
2. Configurez les autorisations client S3
Configurez les autorisations client S3 du cluster sur site en exécutant les commandes suivantes :
bin/elasticsearch-keystore add s3.client.default.access_key
bin/elasticsearch-keystore add s3.client.default.secret_key
Cette opération est obligatoire pour que le cluster local bénéficie des informations d’identification requises pour l’écriture des snapshots vers le S3. Access_key et secret_key sont disponibles depuis l’utilisateur IAM créé à l’étape précédente.
Configurez votre politique de snapshots
1. Configurez le référentiel de snapshots
Configurez le référentiel de snapshots S3 dans votre cluster local en exécutant les commandes ci-après dans les outils de développement Kibana Dev Tools. Ici, nous indiquons au cluster local dans quel compartiment S3 écrire le snapshot. L’utilisateur IAM que vous venez de créer devrait bénéficier des autorisations d’écriture et de lecture dans ce compartiment S3.
PUT _snapshot/{ "type": "s3", "settings": { "bucket": " " } }
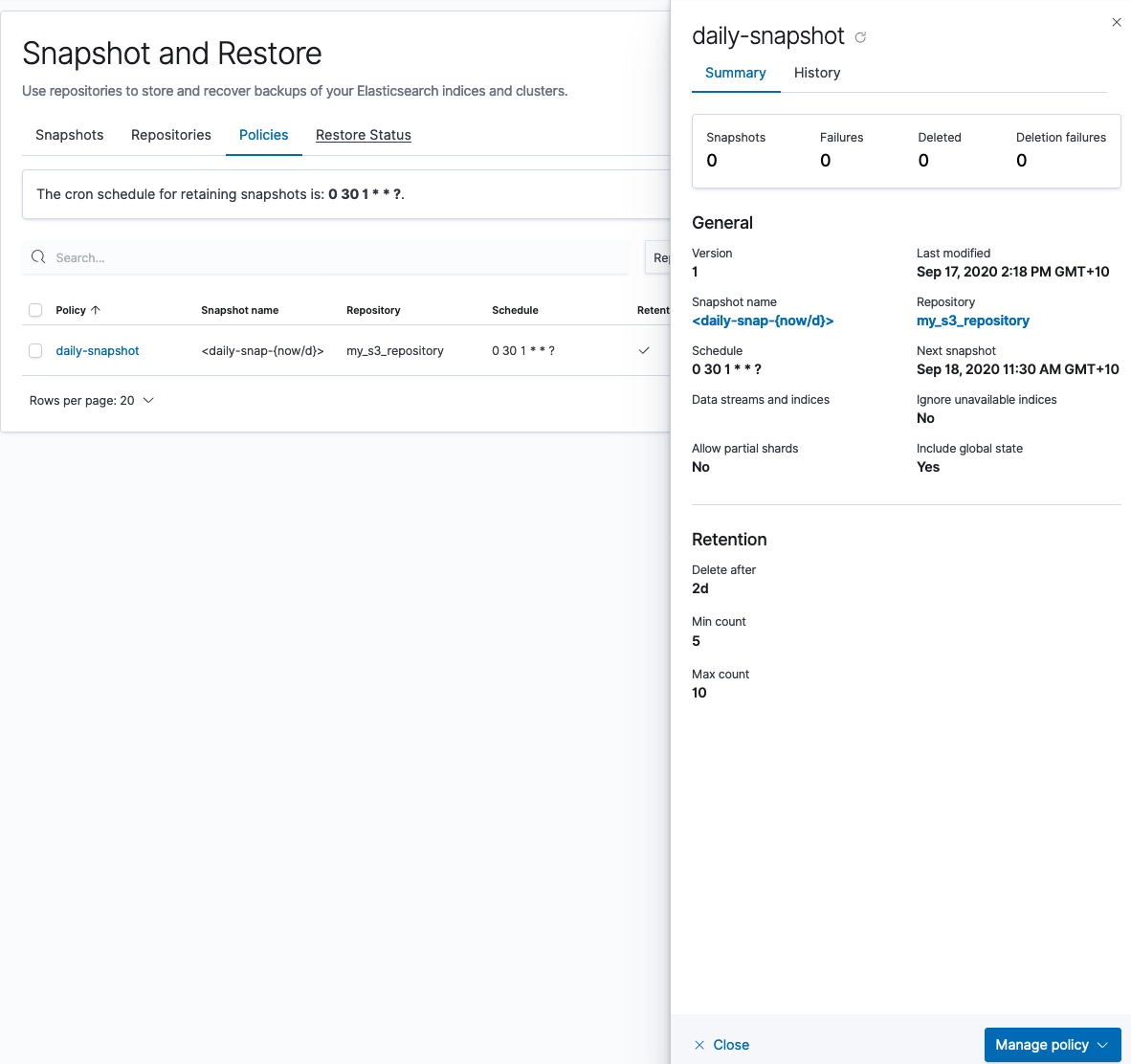
2. Créez une politique de snapshots
Maintenant, vous allez créer une politique de snapshots dans votre cluster local qui stockera le snapshot dans le compartiment S3 qui vient d’être créé :
Vous pouvez également créer un snapshot unique dans Kibana Dev Tools :
PUT /_snapshot// ?wait_for_completion=true { "indices": "*", "ignore_unavailable": true, "include_global_state": false }
Vérifiez que les snapshots fonctionnent en exécutant la commande ci-après dans Dev Tools :
GET _snapshot//_all
Provisionnez le nouveau cluster sur Elasticsearch Service
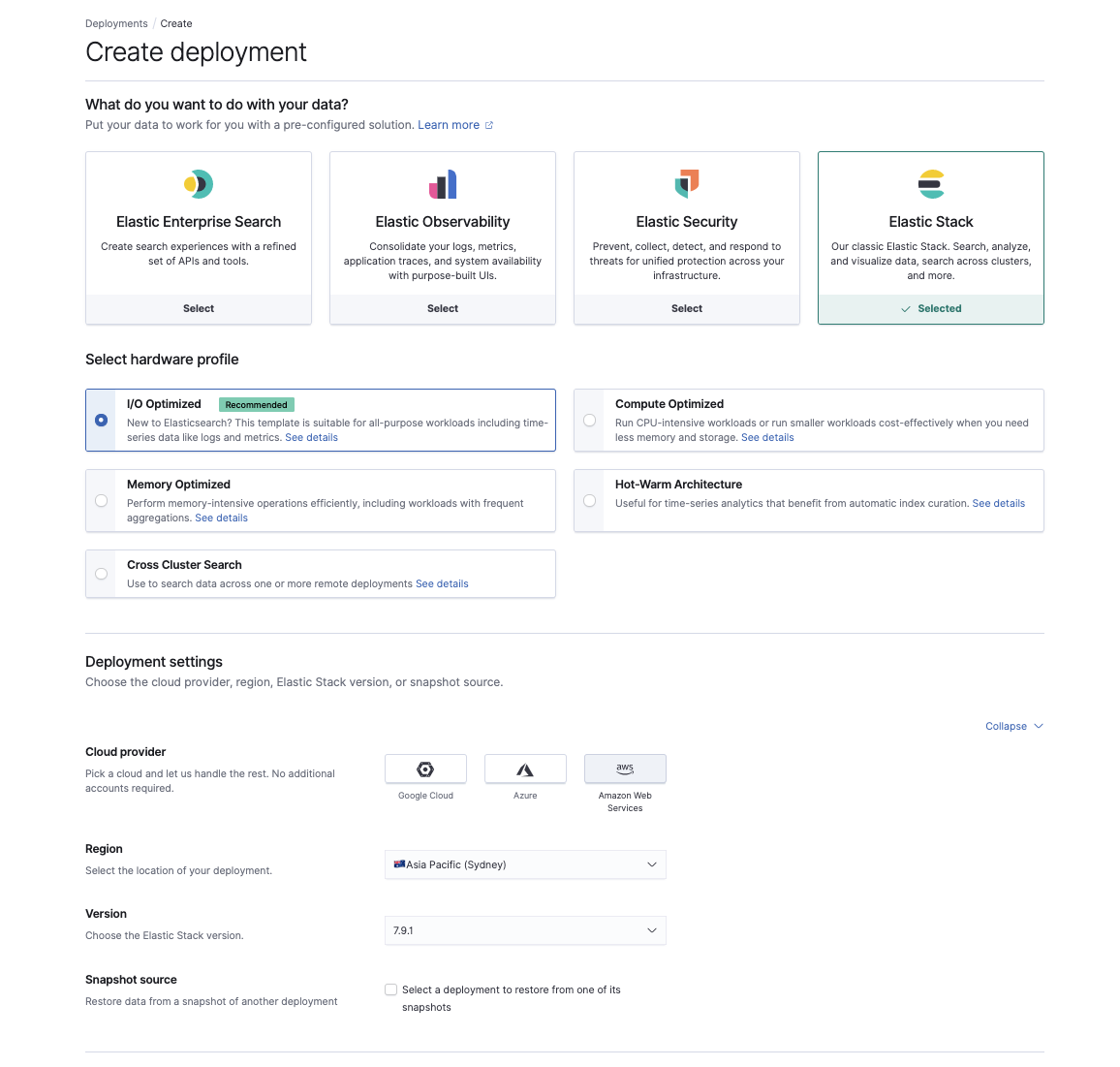
Une fois que vous avez des snapshots fonctionnels sur le S3, il est temps de provisionner un nouveau cluster sur Elasticsearch Service à l’adresse cloud.elastic.co. Ici, vous pouvez choisir le cas d'utilisation qui reflète au mieux votre charge de travail actuelle, la région AWS et votre version d’Elasticsearch.
Dans la console Elasticsearch Service, configurez les paramètres de magasin de clés du cluster :
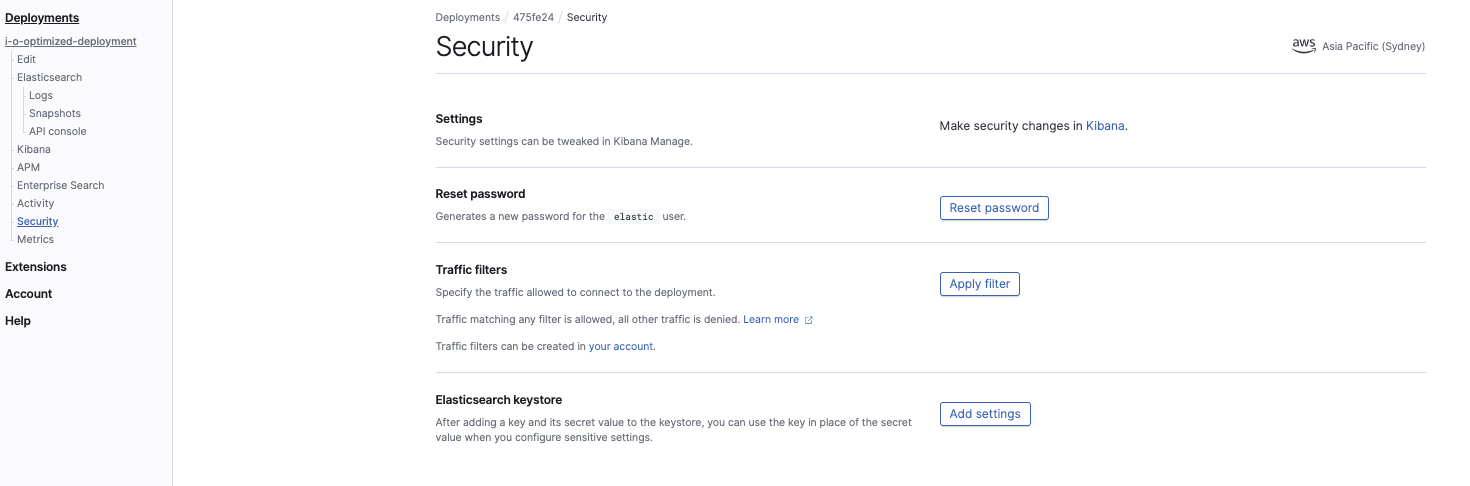
Les deux paramètres à configurer sont les suivants :
s3.client.default.access_key s3.client.default.secret_key
Cette opération est obligatoire pour que le cluster Elasticsearch Service ait l’autorisation de lire le snapshot dans le compartiment S3. Ces paramètres sont les mêmes que ceux des identifiants de sécurité de l’utilisateur IAM.
Configurez le référentiel de snapshots personnalisé pour le cluster Elasticsearch Service
Maintenant, nous devons créer un nouveau référentiel de snapshots sur le cluster Elasticsearch Service. Cela permet d’indiquer à Elasticsearch Service l’emplacement dans le compartiment S3 du snapshot que nous voulons restaurer. Pour ce faire, connectez-vous à Kibana, sélectionnez Stack Management (Gestion de la Suite) et accédez aux paramètres de snapshot et de restauration. Sélectionnez Register a repository (Enregistrer un référentiel) :
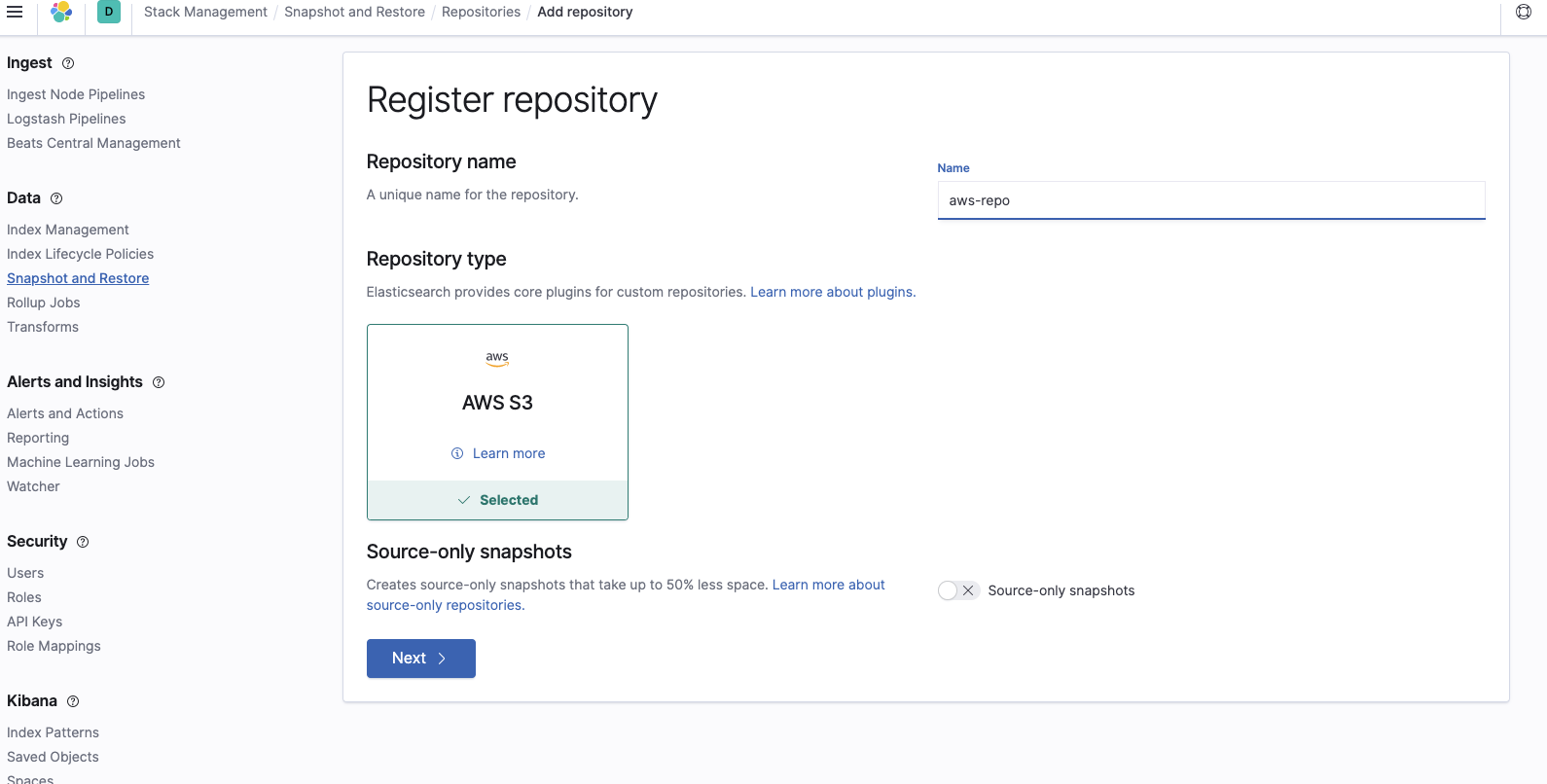
Ajoutez le nom du compartiment dans lequel se trouvent les snapshots :
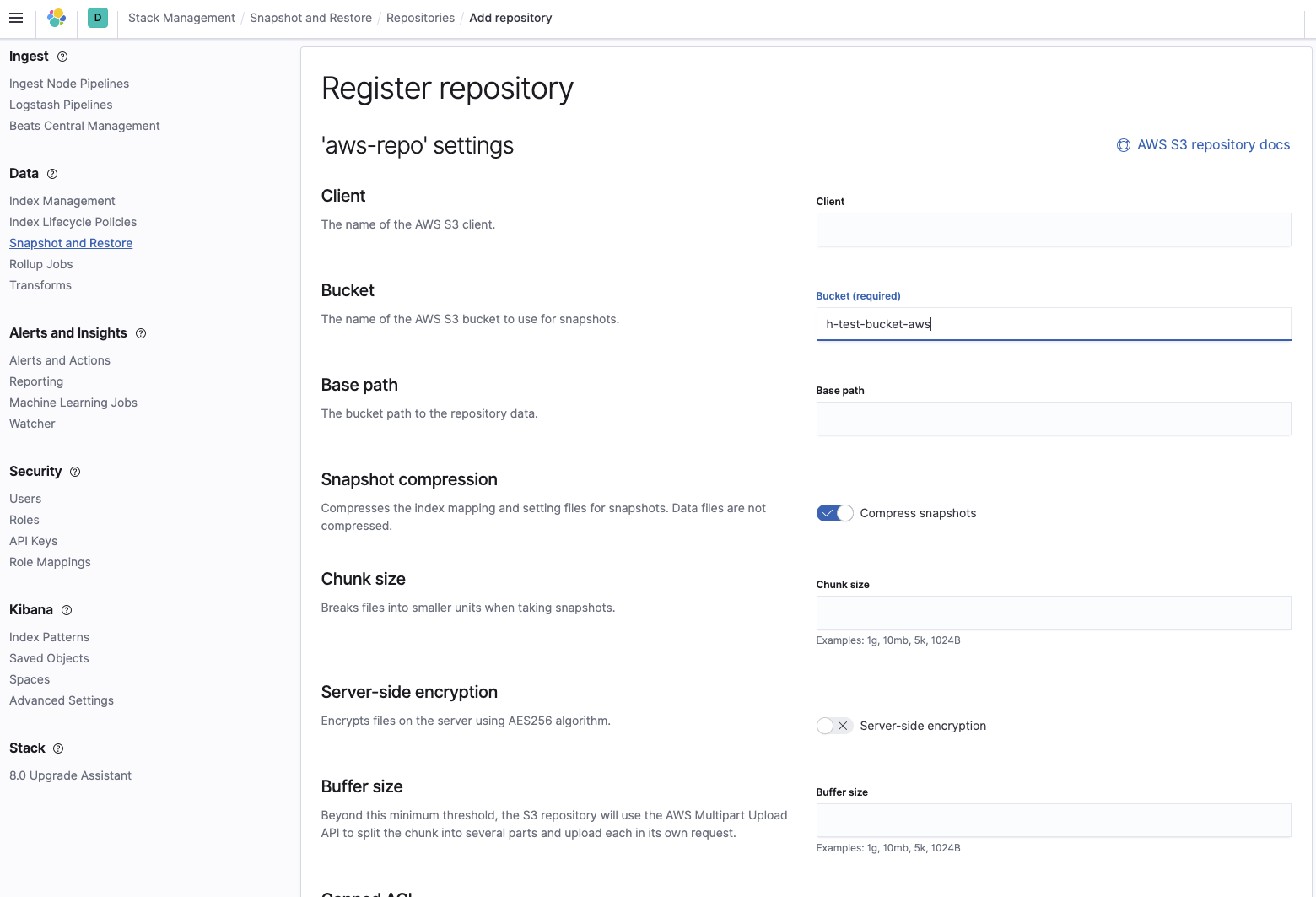
Vérifiez ensuite que le référentiel a été correctement configuré :
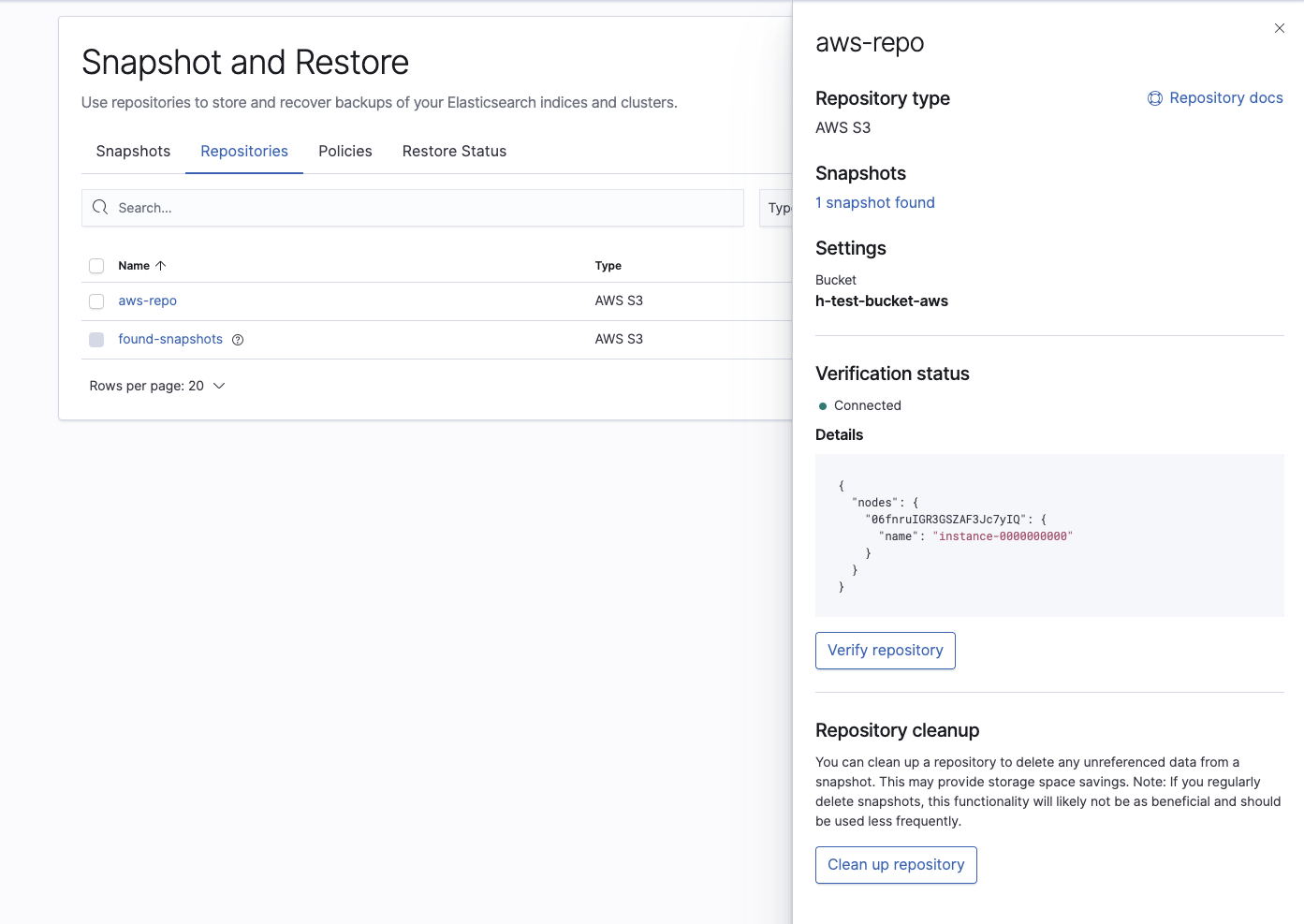
Enfin, confirmez que le cluster Elasticsearch Service peut voir le snapshot que nous voulons restaurer :
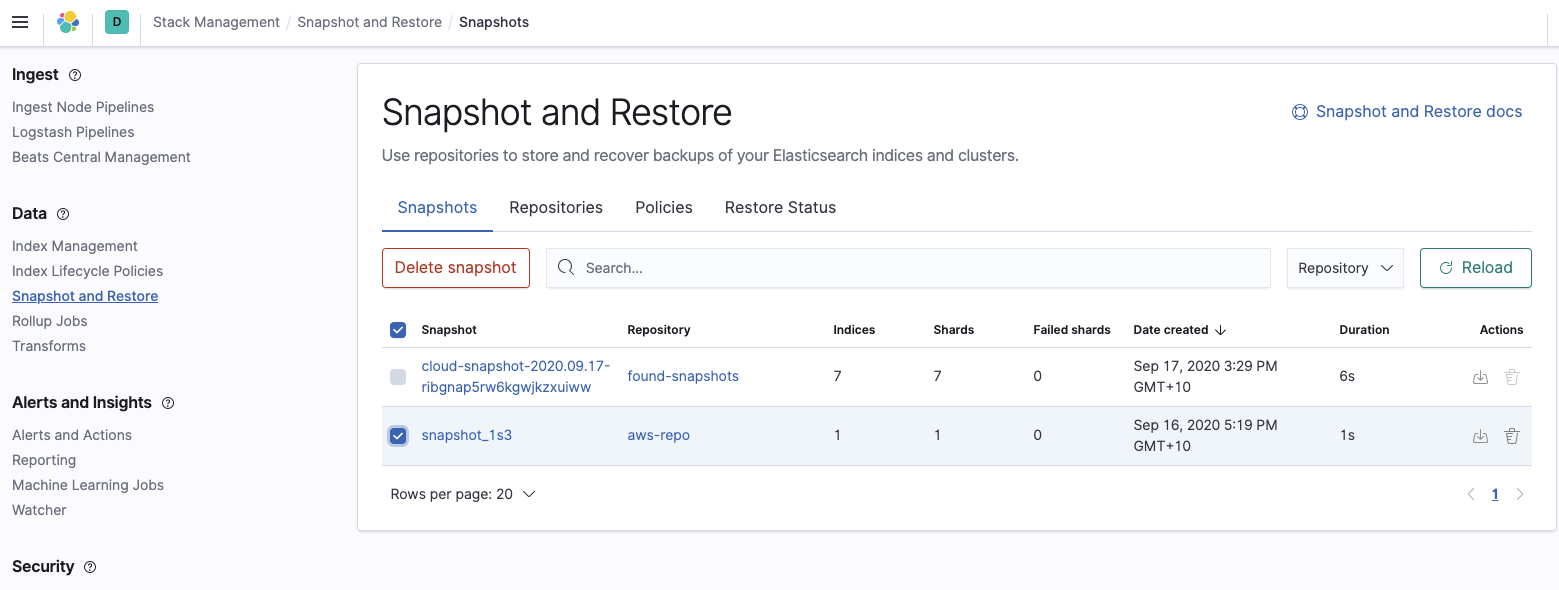
Restaurez le cluster Elasticsearch Service à partir du snapshot
Pour restaurer le snapshot, accédez à la console API du cluster Elasticsearch Service dans la console Elasticsearch Service et exécutez les trois commandes ci-après. Vous remarquerez que les trois commandes sont exécutées en tant que POST dans la console API.
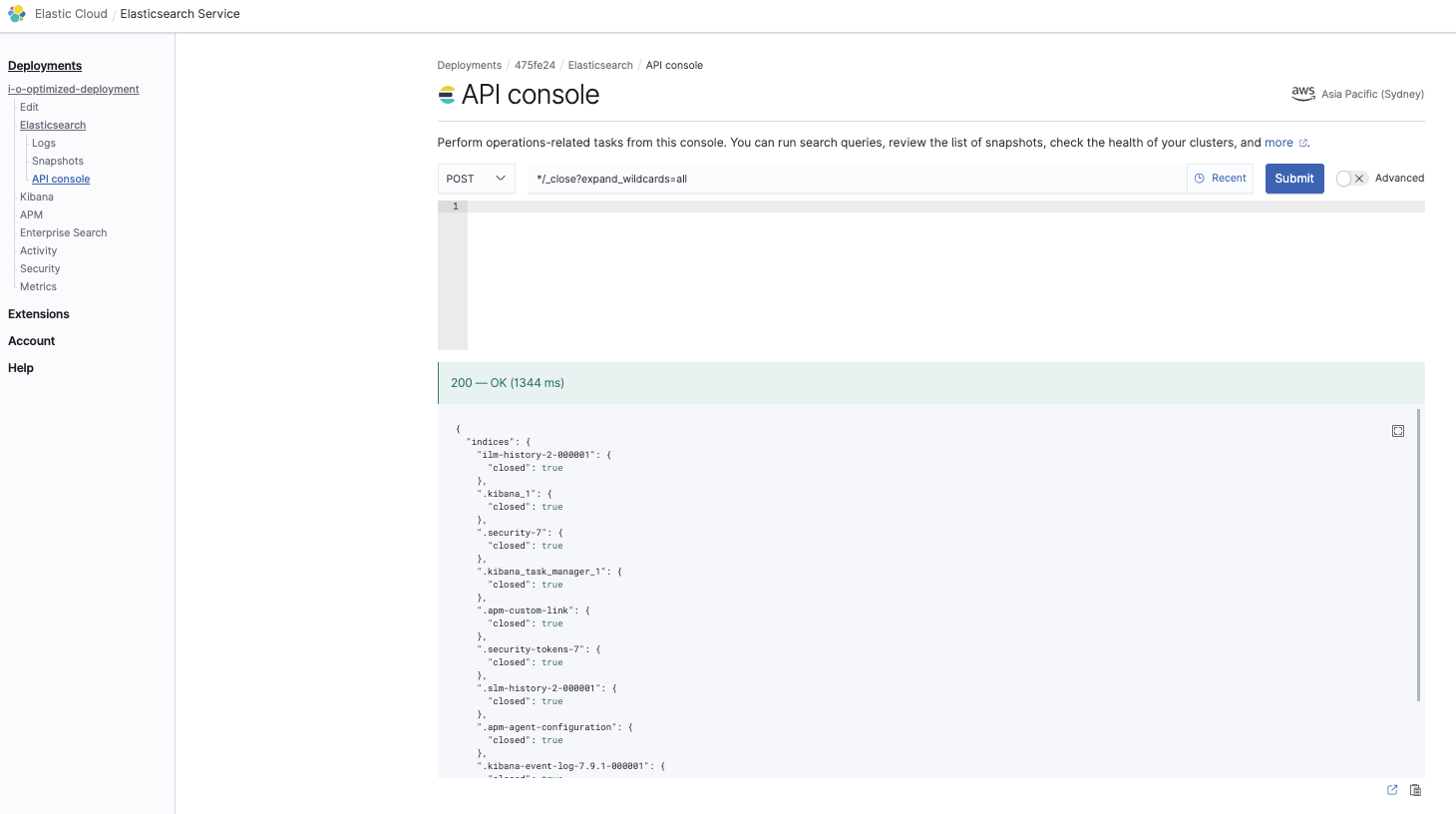
Fermez tous les index
*/_close?expand_wildcards=all
Cette commande permet de s’assurer de fermer tous les index afin d’éviter tout conflit lors de la phase de restauration :
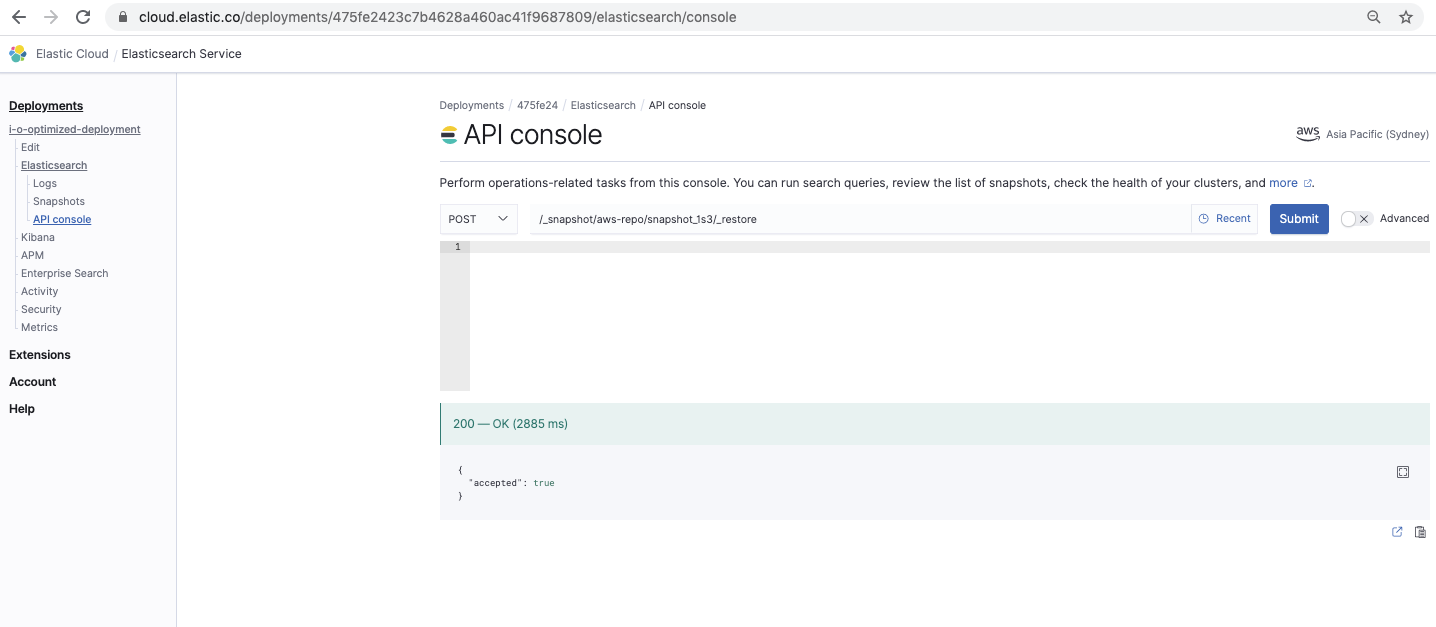
Restaurez le snapshot
/_snapshot// /_restore
Cette commande restaure le snapshot :
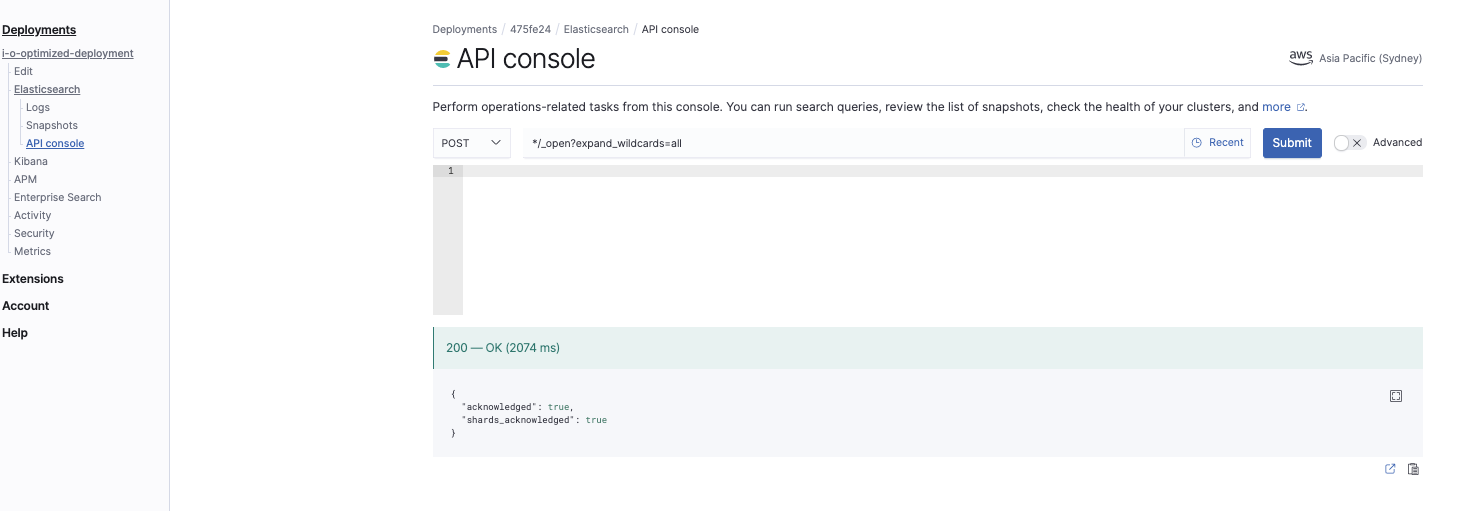
Ouvrez tous les index
*/_open?expand_wildcards=all
Cette commande ouvre tous les index :
Vérifiez la restauration du snapshot
Vérifiez que vous avez restauré le snapshot avec tous les index. Accédez à Kibana et exécutez la commande suivante dans Dev Tools :
GET _cat/indices
Le nouveau cluster devrait maintenant s’exécuter sur Elasticsearch Service avec les données du cluster autogéré dont vous avez créé le snapshot. Vous pouvez désormais refaire pointer vos sources d’ingestion, telles que Beats ou Logstash, vers le nouveau point de terminaison Elasticsearch Service, que vous trouverez dans la console Elastic Cloud.