Protecting GDPR Personal Data with Pseudonymization
If you’ve had the chance to read our GDPR white paper or our previous GDPR primer blog post, you’ve, no doubt, seen the word "pseudonymization" used extensively to describe one technical measure that can be used to protect Personal Data. In this post, we explore techniques that can be used to pseudonymize data during its ingestion into Elasticsearch.
As a reminder, we’ll use capitalized "Personal Data" to refer to personal data as defined by GDPR.
Background
First, a little background on the topic. In the context of GDPR, part of securing Personal Data means employing multiple levels of protection to ensure that data is not lost, destroyed, or disclosed to unauthorized individuals. One GDPR principle for securing Personal Data is Pseudonymization, which is defined as "...the processing of personal data in such a way that the data can no longer be attributed to a specific Data Subject without the use of additional information."
Motivation
Beyond the fact that the GDPR lists pseudonymization amongst appropriate technical and organisational measures designed to implement data-protection principles [Article 25, Recital 1], and we can bet that auditors will be looking to see if it has been implemented, there are two practical benefits of using pseudonymized Personal Data:
Allows organizations to continue to use many existing operations and processes that might otherwise be impossible to perform if the Personal Data was simply deleted, and
Reduces the cost to appropriately protect the data, versus if the Personal Data were left intact.
Additionally, pseudonymization allows for the ultimate reassociation of the Personal Data with the individual when required by authorized individuals, or as part of a data subject’s exercise of their rights under GDPR, such as the right to erasure.
Requirements
There is a distinction between pseudonymous data and anonymous data. If data is anonymous, it contains no information that could potentially identify an individual and is thus not considered Personal Data by GDPR. This can be achieved through a number of techniques, not described here. Pseudonymized data, meanwhile, is still considered Personal Data, since it can be used for re-identification of the data subject, if combined with additional information. However, without this information, re-identification should be practically impossible, taking into account current known techniques and technology.
Because it contains no data that can directly identify an individual, pseudonymous data may represent a lower risk of privacy impact in the event of an unintended disclosure, so according to GDPR , it may be subject to less stringent security requirements, as appropriate to that risk [Article 32, Recital 1]. This enables us to explore a variety of techniques for pseudonymization on data types for which it must be performed.
Several types of data should be considered candidates for pseudonymization. We’ll refer to the fields that contain such data as "identifier fields."
Direct identifiers, that can be used to identify a person without any additional information or cross-linking with publicly available data e.g. social security number.
Indirect identifiers that do not identify an individual in isolation, but can when combined with other data points. The requirement here is less stringent and acknowledges that re-identification must not be "reasonably likely" with respect to both cost and time, considering both current technology and technological development.
"Reasonably likely" is open to interpretation, and may change over time. In proposing solutions using the Elastic Stack, we allow the level and strength of pseudonymization to be configured, thus allowing the user to select settings with which they (or their legal or audit departments) are comfortable.
GDPR allows pseudonymized data to be attributed to a specific individual given the use of additional information - effectively allowing reversal and re-identification of individuals. This additional information must however be "kept separately" and is subject to technical and organizational measures to ensure that the personal data are not attributed to an identified or identifiable natural person." [Chapter 1, Article 4, Recital 5] This additional information can take several forms, including but not limited to:
- a key or set of keys required to reverse the process e.g. encryption key and/or function.
- the original data with a link to the pseudonymized data which has been hashed securely (i.e., a straight key lookup on a per value basis.)
Finally, GDPR acknowledges that some risk exists for this "additional information" to be compromised and thus data owners should ensure both technical (e.g., encryption, access controls) and organizational measures (e.g., policies) are enforced which separate pseudonymous data from its identification key and/or original Personal Data.
Approaches
With regards to the Elastic Stack, we can quickly identify four potential methods in which pseudonymization might be accomplished. The simple map below illustrates these various pseudonymization methods.
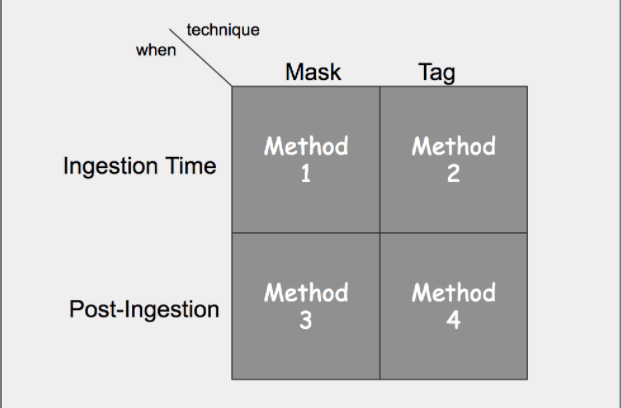
Ideally all Personal Data would be pseudonymized prior to being indexed in Elasticsearch, and indeed, this first blog post focuses on ingestion time methods. However, we are aware that our users likely have data that already resides in Elasticsearch that will also need to comply with the same GDPR requirements. In this post, we’ll focus on Method 1 from the diagram above. We’ll explore methods for using the Elasticsearch ingest node in a future blog post.
Achieving Pseudonymization
To meet the above requirements, we propose using a fingerprinting technique where we replace the value of identifier fields with a hashed representation, and store the original data and a generated key (as a key-value pair) as additional information in either a separate data store or separate index, thus allowing future reversal if required. In future blog posts we will propose approaches to achieving this reversal at scale.
This raises the question of where the additional information should be stored. For the purposes of example, we propose a different Elasticsearch index secured appropriately with X-Pack security features. This could, however, easily be a different Elasticsearch instance or even an entirely different data store. We subsequently refer to this separate data store as the "identity store."
Ingestion Time
Logstash represents an ideal processing engine for pseudonymization of data during ingestion into Elasticsearch. The rich set of available filters means we can easily satisfy the pseudonymization requirements, whilst the diverse set of outputs allow us to store our additional information in most common data stores.
For the same reason utilising salts in password storage is always recommended, the following proposes using hashing (HMAC with a key) and lookup tables. In its simplest implementation, using a single key value, the approach is susceptible to a brute force attack and single point of failure (i.e., if the key is compromised) - especially on sets of values with "small" value spaces (e.g., IP addresses). We therefore consider key rotation as beneficial and thus discuss its implication on data discovery. The below approach relies on the principle of storing every hash+value pair separately from the data in an identity store for use in a potential lookup, therefore allowing a psedomonized value to be reversed by an authorised individual.
The Logstash fingerprint filter allows the consistent hashing of fields and storing of the hash result in the document. Here the hash becomes the pseudonymized data, and is used to overwrite the original identifier field value. The hashes and original identifier field values are stored separately new documents for lookup purposes, as shown below:
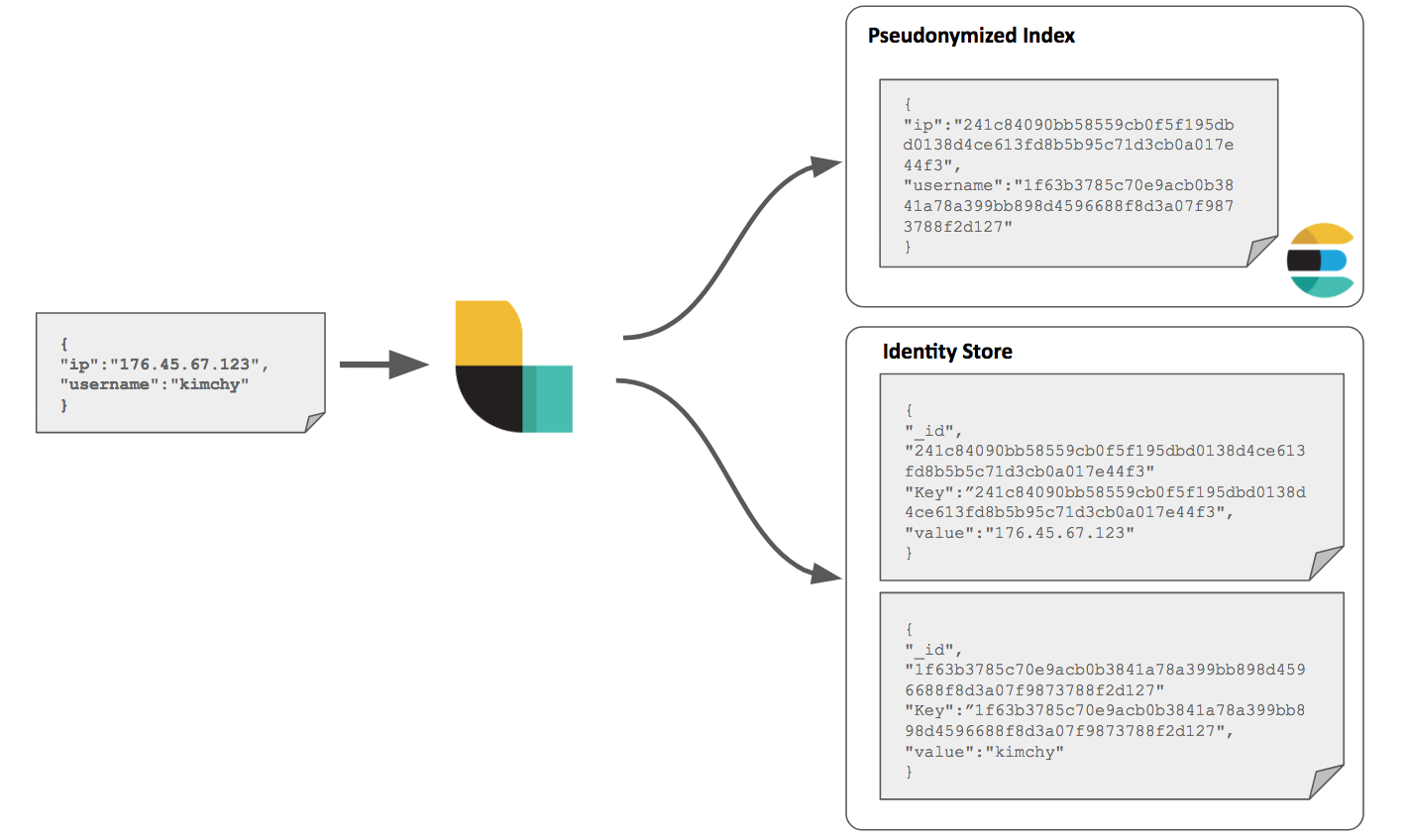
The following example Logstash configuration assumes the user has a single Elasticsearch instance running on port TCP/9200. This cluster stores both our pseudonymized data in one index and our "identity documents" in another. Both are secured with X-Pack security features. This chain could easily be modified to send these documents to separate clusters, if it was felt a greater degree of separation was required.
For the purposes of example we assume raw data (JSON) is passed to Logstash, through a simple tcp input, containing the Personal Data identifier fields "ip" and "username." All other fields are assumed to not contain Personal Data, and are ignored in this example.
input {
tcp {
port => 5000
codec => json_lines
}
}
filter {
ruby {
code => "event.set('identities',[])"
}
# pseudonymize ip field
#fingerprint ip
fingerprint {
method => "SHA256"
source => ["ip"]
key => "${FINGERPRINT_KEY}"
}
#create sub document under identities field
mutate { add_field => { '[identities][0][key]' => "%{fingerprint}" '[identities][0][value]' => "%{ip}" } }
#overwrite ip field with fingerprint
mutate { replace => { "ip" => "%{fingerprint}" } }
# pseudonymize username field
#fingerprint username
fingerprint {
method => "SHA256"
source => ["username"]
key => "${FINGERPRINT_KEY}"
}
#create sub document under identities field
mutate { add_field => { '[identities][1][key]' => "%{fingerprint}" '[identities][1][value]' => "%{username}" } }
#overwrite username field with fingerprint
mutate { replace => { "username" => "%{fingerprint}" } }
#extract sub documents and yield a new document for each one into the LS pipeline. See https://www.elastic.co/guide/en/logstash/current/plugins-filters-ruby.html#_inline_ruby_code
ruby {
code => "event.get(identities).each { |p| e=LogStash::Event.new(p); e.tag(identities); new_event_block.call(e); } "
}
#remove fields on original doc
mutate { remove_field => ["fingerprint","identities"] }
}
output {
if "identities" in [tags] {
#route identities to a new index
elasticsearch {
index => "identities"
#use the key as the id to minimise number of docs and to allow easy lookup
document_id => "%{[key]}"
hosts => ["localhost:9200"]
#create action to avoid unnecessary deletions of existing identities
action => "create"
user => "logstash"
password => "${ES_PASSWORD}"
#don't log messages for identity docs which already exist
failure_type_logging_whitelist => ["version_conflict_engine_exception"]
}
} else {
#route events to a different index
elasticsearch {
index => "events"
hosts => ["localhost:9200"]
user => "logstash"
password => "${ES_PASSWORD}"
}
}
}
Whilst obviously highlighting the configuration of the fingerprint filter, the above configuration additionally illustrates how the Logstash mutate filter plugin is used to construct sub "identity documents," each containing the original field value and its corresponding fingerprint, under the object "identities". A ruby filter in turn converts these subdocuments into new logstash documents through the method call "new_event_block.call". The "identities" field is removed from the original document and sent to an "events" index , whilst the new "identity documents" are routed elsewhere - in this case to a different "identities" elasticsearch index.
All hashing utilises a key specified in the config, thus providing a random "salting" effect - see "A note on credentials, secrets & rotation"1 for the benefits and implications of rotating this. Here we have used a SHA256 method for our fingerprint, which represents a good compromise between robustness and speed. The specific choice of hash algorithm is left for the user to select from multiple supported, each with its own properties and tradeoffs. For enhanced resiliency, users may to consider a using a key-stretching algorithm, such as bcrypt, which deliberately slow down the hashing algorithm to make many attacks unfeasible. This would require a custom implementation however, as it is currently not supported by the above Logstash filter.
Notice also the _id of each identity document is the associated unique hash fingerprint, thus avoiding data duplication - we only have 1 document for each unique value in our identity store. This also has the benefit of allowing administrators to lookup fingerprint values with a simple doc id lookup in Elasticsearch.
The above approach is obviously a little unwieldy; every time we want to pseudonymize a new field we have to copy a block of configuration, and ensure that we change each occurrence of the fieldname and increment the array references. This is an error prone process, and potentially results in a long and complex configuration. Fortunately, Logstash 6.1 added support for the ruby filter to utilise a file. This allows us to capture the above logic generically, and achieve all of the above operations in a single configuration block. For the purposes of brevity, we won’t describe the script in detail, but it can be found here. Our filter declaration now becomes much simpler:
filter {
ruby {
path => "/etc/logstash/pseudonymize.rb"
script_params => {
"fields" => ["username","ip"]
"tags" => "identities"
"key" => "${FINGERPRINT_KEY}"
}
}
}
Pseudonymising a new field now simply requires updating the "fields" parameter of the "script_params". This snippet in no way represents a final solution - the script is missing tests for a start, doesn’t handle complex data structures and only supports SHA256! Rather it highlights one possible approach and provides a starting point. The use of a script here allows the user to potentially explore other hashing algorithms not exposed in the fingerprint filter such as more resilient key stretching variants e.g. PBKDF2, or even perform multiple hash rotations to add equivalent complexity. In reality users may wish to consider creating their own Logstash filter, incorporating more functionality and providing greater configuration flexibility.
Try it for yourself
If you are interested in trying the above, all of the code and steps for testing (using docker) can be found here.
A note on credentials, secrets & rotation
In the above examples you may have noted the need to manage several secrets in our configuration. As well as the usual password for elasticsearch - "ES_PASSWORD", we also pass "FINGERPRINT_KEY" to the fingerprint filter and custom script. These keys should be treated with the same diligence as the passwords - although a compromise of SHA256 key is less critical than a cipher key. Whilst we appear to reference environment variables with the "${KEY}" syntax, these can now actually be stored securely in the secrets store introduced in Logstash 6.2.
Users may consider rotating both keys (when using fingerprints) periodically to avoid potential brute force attacks through rainbow tables - how often becomes a risk assessment decision and is left to the user. The current requirements of GDPR are undefined with respect to hashing approaches, but the user should be aware both keys are vulnerable without proper measures. Users may consider a sufficiently complex salt (e.g., min 20 chars/bytes), to reduce the exposure to any rainbow table style attacks.
To rotate keys, the user could add a new value to the the secret store, before modifying the Logstash config to use the new entry. Provided a new key name is utilised each time, and automatic reload is enabled, Logstash will reflect these changes on new documents without the need for a restart.
For users who need additional security guarantees, a random key could even be generated per document and used in the hash. Whilst increasing resilience and making brute force attacks impossible, this would be at the expense of increasing the number of documents in the Identity Store (the same value would result in different docs). This is likely to also be overkill and represents the extreme interpretation of the GDPR requirements.
Most importantly, once a key is rotated, data correlation against historical data becomes much harder. Values will map to a new space (e.g., value X will map to Z, instead of Y). Not only will this increase the cardinality of values, but make terms aggregations and visualizations, as well as most machine learning jobs ineffective - see "Other Challenges of Pseudonymization". Users should consider choosing keys based on the relative importance of data correlation and usefulness of data versus GDPR compliance and risk assessment.
Conclusion and Future Posts
In this post we have shown how to achieve ingestion time pseudonymization of identifier field data using Logstash, and discussed some of the concerns around management of keys to minimise potential exposure to hash reversal techniques. In subsequent posts we will discuss how pseudonymized data can be reversed at scale, and approaches for pseudonymization of data that has already been indexed into Elasticsearch using ingest node. Finally, we will explore techniques for tagging Personal Data at both ingestion time and post ingestion, before addressing the pseudonymization of data whilst preserving information properties - thus enabling the use of X-Pack Machine Learning and other analysis functions (e.g., high_information_content) on pseudonymized Personal Data.
1here defined as low probability of collisions and susceptibility to attack through brute force/rainbow attack