No Elasticsearch, unir dois índices não é tão simples quanto em bancos de dados relacionais SQL tradicionais. No entanto, é possível obter resultados semelhantes usando certas técnicas e recursos fornecidos pelo Elasticsearch.
Historicamente, muitas pessoas usavam o tipo de campo nestedcomo um mecanismo para unir diferentes índices. No entanto, era limitado devido a consultas caras e suporte incompleto no Kibana, especificamente visualizações do Lens.
Este artigo se aprofundará no processo de junção de dois índices no Elasticsearch, com foco nas seguintes abordagens:
- Usando a consulta
terms - Usando o processador
enrichem pipelines de ingestão - Plug-in de filtro Logstash
elasticsearch - ES|QL
ENRICH - ES|QL
LOOKUP JOIN
Usando os termos consulta
A consulta de termos é uma das maneiras mais eficazes de unir dois índices no Elasticsearch. Esta consulta é usada para recuperar documentos que contêm um ou mais termos exatos em um campo específico. Aqui discutimos como usá-lo para unir dois índices.
Primeiro, você precisa recuperar os dados necessários do primeiro índice. Isso pode ser feito usando uma simples solicitação GET e extraindo os valores do atributo _source .
Depois de obter os dados do primeiro índice, você pode usá-los para consultar o segundo índice. Isso é feito usando a consulta terms , onde você especifica o campo e os valores que deseja corresponder.
Aqui está um exemplo:
Neste exemplo, field_in_second_index é o campo no segundo índice que você deseja corresponder aos valores do primeiro índice. value1_from_first_index e value2_from_first_index são os valores do primeiro índice que você deseja corresponder no segundo índice.
A consulta de termos também fornece suporte para executar as duas etapas acima de uma só vez usando uma técnica chamada pesquisa de termos. O Elasticsearch se encarregará de recuperar de forma transparente os valores correspondentes de outro índice. Por exemplo, se você tiver um índice de equipes contendo uma lista de jogadores:
É possível consultar um índice de pessoas para todas as pessoas que jogam no time1, conforme mostrado abaixo:
No exemplo acima, o Elasticsearch recuperará de forma transparente os nomes dos jogadores do documento com id team1 no índice de equipes (ou seja, “john”, “bill” e “michael”) e encontrar todos os documentos no índice de pessoas que contenham qualquer um desses valores no campo de nome.
Para os curiosos, a consulta SQL equivalente seria:
Usando o processador de enriquecimento
O processador enriché outra ferramenta poderosa que pode ser usada para unir dois índices no Elasticsearch. Este processador enriquece os dados de documentos recebidos adicionando dados de um índice de enriquecimento predefinido.
Veja como você pode usar o processador de enriquecimento para unir dois índices:
1. Primeiro, você precisa criar uma política de enriquecimento. Esta política define qual índice usar para enriquecimento, qual campo corresponder e qual(is) campo(s) usar para enriquecimento de documentos recebidos.
Aqui está um exemplo:
2. Depois que a política for criada, você precisa executá-la para criar o índice de enriquecimento a partir da sua política recém-criada:
Isso criará um novo índice enriquecido oculto que será usado durante o enriquecimento. Dependendo do tamanho do índice de origem, esta operação pode levar algum tempo. Certifique-se de que a política de enriquecimento esteja totalmente criada antes de prosseguir para a próxima etapa.
3. Após a criação da política de enriquecimento, você pode usar o processador de enriquecimento em um pipeline de ingestão para enriquecer os dados de documentos recebidos:
Neste exemplo, field_in_second_index é o campo no segundo índice que precisa corresponder ao match_field do primeiro índice. enriched_field é o novo campo no segundo índice que conterá os dados enriquecidos do enrich_fields no primeiro índice.
Uma desvantagem dessa abordagem é que, se os dados mudarem em first_index, a política de enriquecimento precisará ser reexecutada. O índice enriquecido não é atualizado ou sincronizado automaticamente a partir do índice de origem do qual foi criado. Entretanto, se first_index for relativamente estável, então essa abordagem funciona bem.
Plug-in de filtro ElasticSearch do Logstash
Se estiver usando o Logstash, outra opção semelhante ao processador enrich descrito acima é usar o plug-in de filtro elasticsearch para adicionar campos relevantes ao evento com base em uma consulta especificada. A configuração do nosso pipeline Logstash residiria em um arquivo .conf , como my-pipeline.conf.
Vamos imaginar que nosso pipeline está extraindo logs do Elasticsearch usando o plugin de entrada elasticsearch , com uma consulta para restringir a seleção:
Se quisermos enriquecer essas mensagens com informações de um determinado índice, podemos usar o plugin de filtro elasticsearchna seção filter para enriquecer nossos logs:
O código acima encontrará os documentos do índice index_name onde type é o início e o campo de operação corresponde ao opid especificado e, em seguida, copiará o valor do campo @timestamp em um novo campo chamado started.
Os documentos enriquecidos seriam então enviados para a fonte de saída apropriada, neste caso para o Elasticsearch usando o plugin de saída elasticsearch :
Se você já estiver usando o Logstash, esta opção pode ser útil para consolidar sua lógica de enriquecimento em um único lugar e processá-la conforme novos eventos chegam. No entanto, se você não fizer isso, isso adicionará complexidade à sua solução e será outro componente que você precisa executar e manter.
ES|QL ENRIQUECER
A introdução do ES|QL, que foi disponibilizado gratuitamente na versão 8.14, é uma linguagem de consulta canalizada suportada pelo Elasticsearch que permite a filtragem, transformação e análise de dados. Usar o comando de processamento ENRICH nos permite adicionar dados de índices existentes usando uma política de enriquecimento.
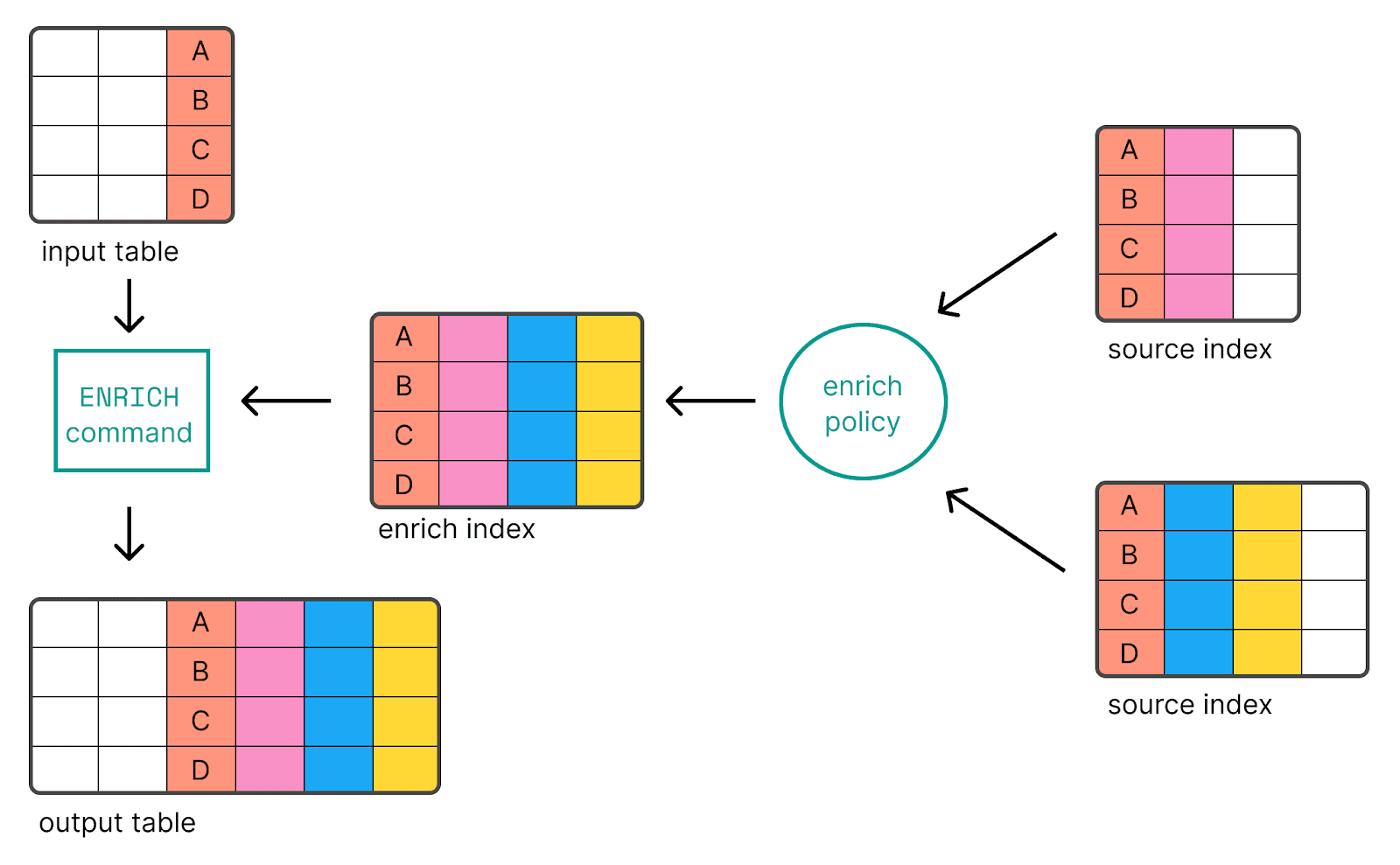
Tomando a mesma política my_enrich_policy do exemplo original do processador de enriquecimento, o exemplo ES|QL ficaria assim:
Também é possível substituir os campos de correspondência e enriquecimento, que em nosso exemplo são field_in_first_index e field_to_enrich respectivamente:
Embora a limitação óbvia seja que você precisa especificar uma política de enriquecimento primeiro, o ES|QL oferece a flexibilidade de ajustar os campos conforme necessário.
ES|QL LOOKUP JOIN
O Elasticsearch 8.18 apresenta uma nova maneira de unir índices no Elasticsearch, o comando LOOKUP JOIN . Este comando opera como um LEFT OUTER JOIN no estilo SQL usando o novo modo de índice de pesquisa no lado direito da junção.

Revisitando nosso exemplo anterior, a nova consulta é a seguinte, onde match_field precisa estar presente em first_index e second_index:
A vantagem do LOOKUP JOIN sobre as outras abordagens é que ele não requer nenhuma política enrich e, portanto, o processamento adicional associado à configuração da política. É útil ao trabalhar com dados de enriquecimento que mudam frequentemente, diferentemente das outras abordagens discutidas neste artigo.
Conclusão
Concluindo, embora o Elasticsearch não suporte operações de junção tradicionais, ele fornece vários recursos que podem ser usados para obter resultados semelhantes. Especificamente, abordamos como realizar operações de junção usando:
- A consulta
terms - O processador
enrichem pipelines de ingestão - Plug-in de filtro Logstash
elasticsearch - ES|QL
ENRICH - ES|QL
LOOKUP JOIN
É importante observar que esses métodos têm suas limitações e devem ser usados criteriosamente com base nos requisitos específicos e na natureza dos dados.
Conteúdo relacionado

14 de novembro de 2025
Como implantar o Elasticsearch no Azure AKS automaticamente
Aprenda como implantar o Elasticsearch com o Kibana no Azure usando o AKS Automatic e o ECK para uma configuração parcialmente gerenciada do Elasticsearch.

11 de novembro de 2025
Configurando o particionamento recursivo para documentos estruturados no Elasticsearch
Aprenda como configurar o particionamento recursivo no Elasticsearch com tamanho de partição, grupos de separadores e listas de separadores personalizadas para indexação ideal de documentos estruturados.

7 de novembro de 2025
Apresentando a interface de usuário de regras de consulta do Elasticsearch no Kibana.
Aprenda a usar a interface de regras de consulta do Elasticsearch para adicionar ou excluir documentos de consultas de pesquisa usando conjuntos de regras personalizáveis no Kibana, sem afetar o ranking orgânico.

3 de outubro de 2025
Como implantar o Elasticsearch no AWS Marketplace
Aprenda como configurar e executar o Elasticsearch usando o Elastic Cloud Service no AWS Marketplace neste guia passo a passo.

14 de agosto de 2025
Fragmentos e réplicas do Elasticsearch: um guia prático
Domine os conceitos de shards e réplicas do Elasticsearch e aprenda como otimizá-los.