2025년 12월 3일
Elasticsearch에서 NVIDIA cuVS를 활용하여 벡터 색인화 속도 최대 12배 향상: GPU 가속화 챕터 2
Elasticsearch가 GPU 가속 벡터 색인화와 NVIDIA cuVS로 어떻게 거의 12배 더 높은 색인화 처리량을 달성하는지 알아보세요.


Elasticsearch와 SigLIP-2로 산봉우리에 대한 멀티모달 검색
SigLIP-2 임베딩과 Elasticsearch kNN 벡터 검색을 사용해 텍스트 대 이미지 및 이미지 대 이미지 다중 모드 검색을 구현하는 방법을 알아보세요. 프로젝트 초점: 에베레스트 트레킹에서 아마다블람 산 정상 사진 찾기.

하이브리드 검색 재랭킹을 통한 다국어 임베딩 모델 관련성 향상
Elasticsearch에서 Cohere의 재랭커와 하이브리드 검색을 사용해 E5 다국어 임베딩 모델 검색 결과의 정확도를 개선하는 방법을 알아보세요.

Elasticsearch에서 다국어 임베딩 모델 배포하기
Elasticsearch에서 벡터 검색 및 언어 간 검색을 위한 e5 다국어 임베딩 모델을 배포하는 방법을 알아보세요.

벡터 검색 필터링: 관련성 유지
쿼리와 가장 유사한 결과를 찾기 위해 벡터 검색을 수행하는 것만으로는 충분하지 않습니다. 검색 결과의 범위를 좁히기 위해 필터링이 필요한 경우가 많습니다. 이 문서에서는 Elasticsearch와 Apache Lucene에서 벡터 검색을 위한 필터링이 어떻게 작동하는지 설명합니다.

임베딩을 Elasticsearch 필드 유형에 매핑하기: semantic_text, dense_vector, sparse_vector
semantic_text, dense_vector 또는 sparse_vector를 사용하는 방법과 시기, 그리고 임베딩 생성과의 관계에 대해 논의합니다.
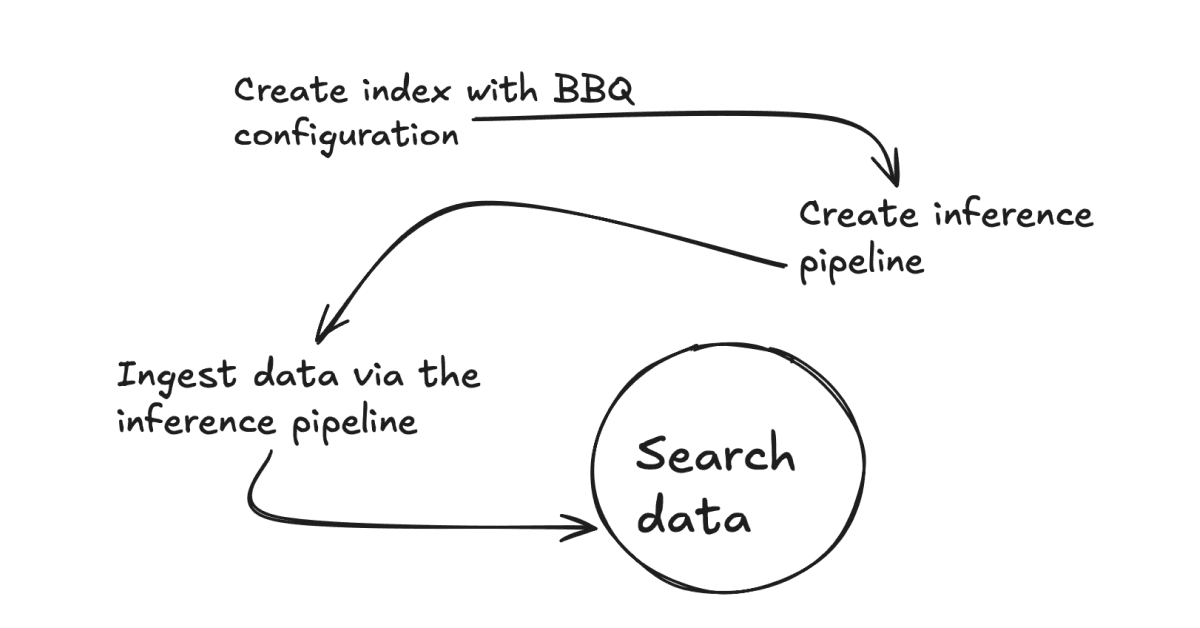
더 나은 바이너리 정량화(BBQ)를 사용 사례에 구현하는 방법
사용 사례에서 더 나은 이진 정량화(BBQ)를 구현하는 이유와 그 방법을 살펴보세요.

2025년 4월 15일
Elasticsearch BBQ와 OpenSearch FAISS: 벡터 검색 성능 비교
Elasticsearch BBQ와 OpenSearch FAISS의 성능 비교.

2025년 4월 9일
구글 클라우드의 버텍스 AI 플랫폼에서 기본 접지를 위한 Elasticsearch 벡터 데이터베이스
Google Cloud의 Vertex AI를 위한 최초의 써드파티 기본 접지 엔진인 Elasticsearch가 어떻게 기업 데이터에 Gemini 모델을 접지하여 맞춤형 GenAI 환경을 구축할 수 있는지 알아보세요.