このブログ記事では、エージェント RAG ワークフローについて詳しく説明し、その主な機能と一般的な設計パターンについて説明します。さらに、Elasticsearch をベクター ストアとして使用し、LangChain を使用してエージェント RAG フレームワークを構築する実践的な例を通じて、これらのワークフローを実装する方法を示します。最後に、この記事では、このようなアーキテクチャの設計と実装に関連するベスト プラクティスと課題について簡単に説明します。このJupyter ノートブックに従って、シンプルなエージェント RAG パイプラインを作成できます。
エージェントRAGの紹介
検索拡張生成 ( RAG ) は LLM ベースのアプリケーションの基礎となり、モデルがユーザーのクエリに基づいて関連するコンテキストを取得することで最適な回答を提供できるようになりました。RAG システムは、事前にトレーニングされた LLM 知識に限定されるのではなく、API またはデータ ストアからの外部情報を利用することで、LLM 応答の精度とコンテキストを強化します。一方、AI エージェントは自律的に動作し、指定された目的を達成するために意思決定とアクションを実行します。
Agentic RAG は、検索強化生成とエージェント推論の両方の長所を統合したフレームワークです。RAG をエージェントの意思決定プロセスに統合することで、システムはデータ ソースを動的に選択し、クエリを改良してコンテキスト検索を改善し、より正確な応答を生成し、フィードバック ループを適用して出力品質を継続的に向上できるようになります。
エージェントRAGの主な特徴
エージェント RAG フレームワークは、従来の RAG システムに比べて大きな進歩を遂げています。固定された検索プロセスに従うのではなく、結果をリアルタイムで計画、実行、最適化できる動的エージェントを活用します。
エージェント RAG パイプラインを区別する主な機能のいくつかを見てみましょう。
- 動的な意思決定: Agentic RAG は推論メカニズムを使用してユーザーの意図を理解し、各クエリを最も関連性の高いデータ ソースにルーティングして、正確でコンテキストに応じた応答を生成します。
- 包括的なクエリ分析: Agentic RAG は、サブ質問とその全体的な意図を含むユーザークエリを詳細に分析します。クエリの複雑さを評価し、最も関連性の高いデータ ソースを動的に選択して情報を取得し、正確で完全な応答を保証します。
- 多段階コラボレーション: このフレームワークは、専門エージェントのネットワークを通じて多段階コラボレーションを可能にします。各エージェントは、より大きな目標の特定の部分を担当し、一貫した結果を達成するために順次または同時に作業します。
- 自己評価メカニズム: エージェント RAG パイプラインは、自己反映を使用して、取得したドキュメントと生成された応答を評価します。取得した情報がクエリに完全に対応しているかどうかを確認し、出力の正確性、完全性、事実の一貫性を確認できます。
- 外部ツールとの統合: このワークフローは、外部 API、データベース、リアルタイム情報ソースと対話して、最新の情報を取り込み、進化するデータに動的に適応できます。
エージェントRAGのワークフローパターン
ワークフロー パターンは、エージェント AI が LLM ベースのアプリケーションを信頼性と効率性をもって構築、管理、調整する方法を定義します。LangChain 、 LangGraph 、 CrewAI 、 LlamaIndexなどのいくつかのフレームワークとプラットフォームを使用して、これらのエージェント ワークフローを実装できます。
- 順次取得チェーン: 順次ワークフローは、複雑なタスクを単純な順序付けられたステップに分割します。各ステップで次のステップの入力が改善され、より良い結果が得られます。たとえば、顧客プロファイルを作成する場合、1 人のエージェントが CRM から基本的な詳細を取得し、別のエージェントがトランザクション データベースから購入履歴を取得し、最後のエージェントがこの情報を組み合わせて推奨事項やレポート用の完全なプロファイルを生成します。
- ルーティング取得チェーン: このワークフロー パターンでは、ルーター エージェントが入力を分析し、最も適切なプロセスまたはデータ ソースに送信します。このアプローチは、重複が最小限で複数の異なるデータ ソースが存在する場合に特に効果的です。たとえば、顧客サービス システムでは、ルータ エージェントが技術的な問題、払い戻し、苦情などの受信リクエストを分類し、適切な部門にルーティングして効率的に処理します。
- 並列検索チェーン: このワークフロー パターンでは、複数の独立したサブタスクが同時に実行され、それらの出力が後で集約されて最終的な応答が生成されます。このアプローチにより、処理時間が大幅に短縮され、ワークフローの効率が向上します。たとえば、顧客サービスの並列ワークフローでは、1 人のエージェントが過去の同様のリクエストを取得し、別のエージェントが関連するナレッジベースの記事を参照します。アグリゲータはこれらの出力を組み合わせて包括的な解決策を生成します。
- オーケストレーター ワーカー チェーン: このワークフローは、独立したサブタスクを利用するため、並列化と類似点があります。ただし、重要な違いはオーケストレーター エージェントの統合にあります。このエージェントは、ユーザークエリを分析し、実行時にそれらをサブタスクに動的に分割し、正確な応答を作成するために必要な適切なプロセスまたはツールを識別する役割を担います。

エージェントRAGパイプラインをゼロから構築する
エージェント RAG の原理を説明するために、LangChain と Elasticsearch を使用してワークフローを設計してみましょう。このワークフローはルーティングベースのアーキテクチャを採用しており、複数のエージェントが連携してクエリを分析し、関連情報を取得し、結果を評価し、一貫した応答を生成します。この例に従うには、このJupyter ノートブックを参照してください。
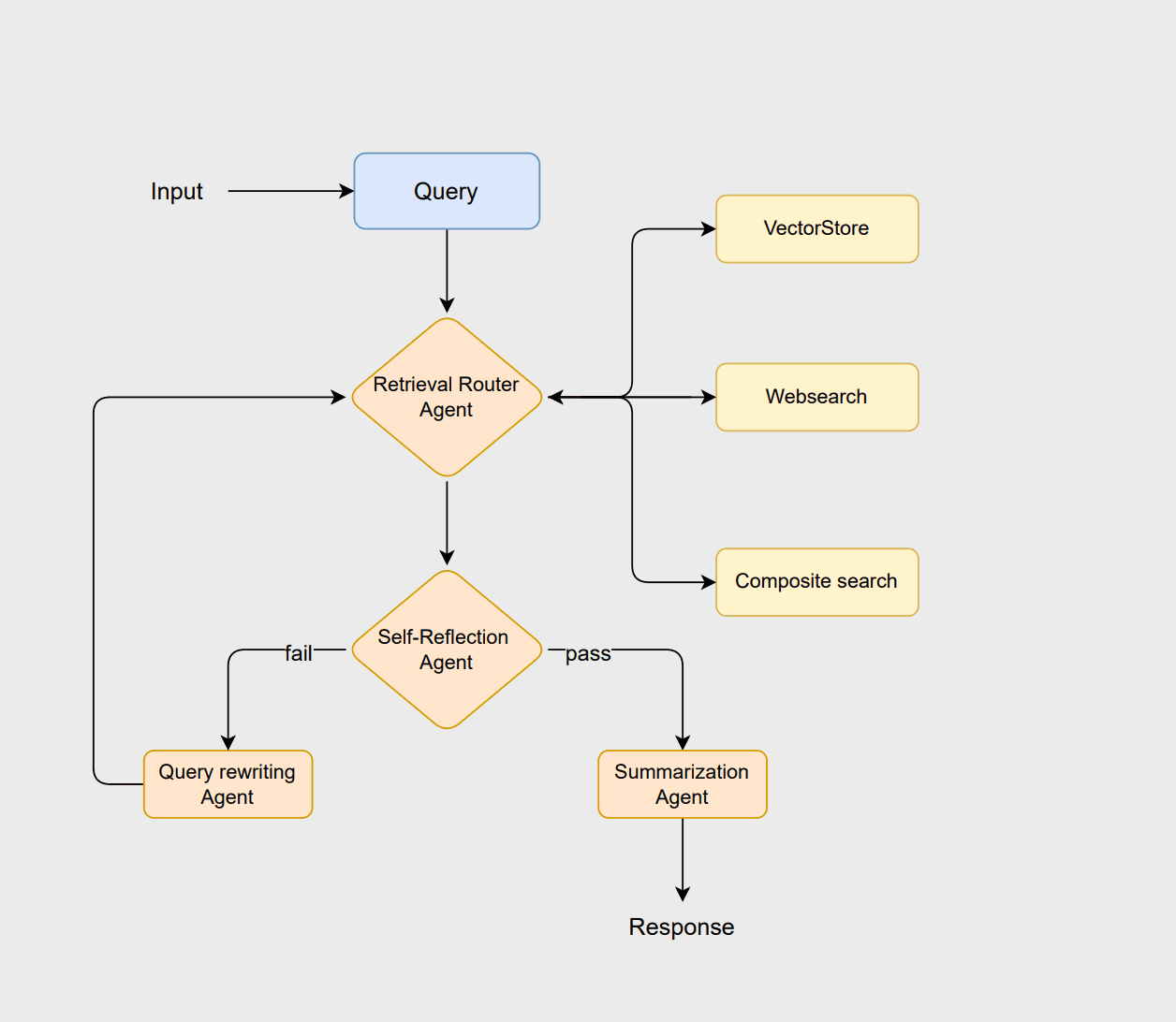
ワークフローはルータ エージェントから開始され、ルータ エージェントはユーザーのクエリを分析して最適な取得方法 ( vectorstore 、 websearch 、またはcompositeのいずれかのアプローチ) を選択します。ベクターストアは従来の RAG ベースのドキュメント検索を処理し、Web 検索はベクターストアに保存されていない最新の情報を取得し、複合アプローチは複数のソースからの情報が必要な場合に両方を組み合わせます。
ドキュメントが適切であると判断された場合、要約エージェントは明確で文脈に適した応答を生成します。ただし、ドキュメントが不十分または無関係な場合、クエリ書き換えエージェントはクエリを再作成して検索を改善します。この修正されたクエリによりルーティング プロセスが再開され、システムは検索を絞り込み、最終出力を強化できるようになります。
要件
このワークフローは、例を効果的に実行するために次のコア コンポーネントに依存しています。
- Python 3.10
- Jupyterノートブック
- Azure OpenAI
- Elasticsearch
- LangChain
続行する前に、この例に必要な次の環境変数のセットを構成するように求められます。
データソース
このワークフローは、AG ニュース データセットのサブセットを使用して説明されています。このデータセットは、国際、スポーツ、ビジネス、科学技術など、さまざまなカテゴリのニュース記事で構成されています。
ElasticsearchStore モジュールは、 langchain_elasticsearchからベクター ストアとして利用されます。検索には、Elastic 独自の埋め込みモデルであるELSERを採用した SparseVectorStrategy を実装します。ベクター ストアを開始する前に、ELSER モデルが Elasticsearch 環境に正しくインストールされ、デプロイされていることを確認することが重要です。
Web 検索機能は、LangChain コミュニティ ツールのDuckDuckGoSearchRunを使用して実装されており、これによりシステムは Web からライブ情報を効率的に取得できます。より関連性の高い結果を提供できる他の検索 API の使用も検討できます。このツールは、API キーを必要とせずに検索できるため選択されました。
複合リトリーバーは、ソースの組み合わせを必要とするクエリ用に設計されています。これは、Web からリアルタイム データを取得すると同時に、ベクター ストアから過去のニュースを参照することで、包括的かつ文脈的に正確な応答を提供するために使用されます。
エージェントの設定
次のステップでは、このワークフロー内で推論および意思決定機能を提供する LLM エージェントが定義されます。作成する LLM チェーンには、 router_chain 、 grade_docs_chain 、 rewrite_query_chain 、 summary_chainが含まれます。
ルータ エージェントは LLM アシスタントを使用して、実行時に特定のクエリに最適なデータ ソースを決定します。グレーディングエージェントは、取得したドキュメントの関連性を評価します。ドキュメントが関連していると判断された場合、それらは要約エージェントに渡され、要約が生成されます。それ以外の場合、書き換えクエリ エージェントはクエリを再作成し、別の取得を試行するためにルーティング プロセスに送り返します。すべてのエージェントの手順は、ノートブックの LLM チェーン セクションに記載されています。
llm.with_structured_outputは、モデルの出力をRouteQueryクラスの BaseModel によって定義された定義済みスキーマに従うように制限し、結果の一貫性を保証します。2 行目は、 router_promptとrouter_structuredを接続してRunnableSequenceを構成し、入力プロンプトが言語モデルによって処理され、構造化されたスキーマ準拠の結果が生成されるパイプラインを形成します。
グラフノードを定義する
この部分では、システムのさまざまなコンポーネント間を流れるデータを表すグラフの状態を定義します。これらの状態を明確に指定することで、ワークフロー内の各ノードがアクセスおよび更新できる情報を確実に認識できるようになります。
状態が定義されたら、次のステップはグラフのノードを定義することです。ノードは、データに対して特定の操作を実行するグラフの機能単位のようなものです。パイプラインには 7 つの異なるノードがあります。
query_rewriterノードはワークフロー内で 2 つの目的を果たします。まず、自己反省エージェントによって評価された文書が不十分または無関係であると判断された場合に、 rewrite_query_chainを使用してユーザークエリを書き換え、検索を改善します。2 番目に、クエリが書き換えられた回数を追跡するカウンターとして機能します。
ノードが呼び出されるたびに、ワークフロー状態に格納されているretry_countが増加します。このメカニズムにより、ワークフローが無限ループに陥るのを防ぎます。retry_countが事前定義されたしきい値を超えた場合、システムはエラー状態、デフォルトの応答、または選択したその他の定義済み条件にフォールバックできます。
グラフのコンパイル
最後のステップは、グラフのエッジを定義し、コンパイルする前に必要な条件を追加することです。すべてのグラフは、ワークフローのエントリ ポイントとして機能する指定された開始ノードから開始する必要があります。グラフ内のエッジはノード間のデータの流れを表し、次の 2 つのタイプがあります。
- 直線エッジ: 1 つのノードから別のノードへの直接的で無条件のフローを定義します。最初のノードがタスクを完了すると、ワークフローは直線に沿って次のノードに自動的に進みます。
- 条件付きエッジ: これにより、現在の状態またはノードの計算結果に基づいてワークフローを分岐できます。次のノードは、評価結果、ルーティングの決定、再試行回数などの条件に応じて動的に選択されます。
これで、最初のエージェント RAG パイプラインの準備が整い、コンパイルされたエージェントを使用してテストできるようになります。
エージェントRAGパイプラインのテスト
次に、以下の 3 つの異なるタイプのクエリを使用してこのパイプラインをテストします。結果は異なる場合があり、以下に示す例は潜在的な結果の 1 つを示しているにすぎないことに注意してください。
最初のクエリでは、ルータはデータ ソースとしてwebsearchを選択します。クエリは自己反映評価に失敗し、出力に示されているように、その後クエリ書き換えステージにリダイレクトされます。
次に、2 番目のクエリで示されているように、 vectorstore検索が使用される例を調べます。
最後のクエリは、ベクターストアと Web 検索の両方を活用する複合検索に向けられます。
上記のワークフローでは、エージェント RAG は、ユーザー クエリの情報を取得するときに使用するデータ ソースをインテリジェントに決定し、応答の精度と関連性を向上させます。追加の例を作成してエージェントをテストし、出力を確認して興味深い結果が得られるかどうかを確認できます。
エージェント型 RAG ワークフローを構築するためのベストプラクティス
エージェント RAG の仕組みがわかったので、次にこれらのワークフローを構築するためのベスト プラクティスをいくつか見てみましょう。これらのガイドラインに従うことで、システムを効率的に維持し、保守を容易にすることができます。
- フォールバックの準備: ワークフローのいずれかのステップが失敗するシナリオに備えて、事前にフォールバック戦略を計画します。これらには、デフォルトの回答を返すこと、エラー状態をトリガーすること、代替ツールを使用することなどが含まれます。これにより、全体的なワークフローを中断することなく、システムが障害を適切に処理できるようになります。
- 包括的なログ記録を実装する: 再試行、生成された出力、ルーティングの選択、クエリの書き換えなど、ワークフローの各段階でログ記録を実装してみます。これらのログは、透明性の向上、デバッグの容易化、プロンプト、エージェントの動作、および取得戦略の継続的な改善に役立ちます。
- 適切なワークフロー パターンを選択する: ユースケースを調べて、ニーズに最適なワークフロー パターンを選択します。ステップごとの推論には順次ワークフローを使用し、独立したデータ ソースには並列ワークフローを使用し、複数のツールや複雑なクエリにはオーケストレーター ワーカー パターンを使用します。
- 評価戦略を組み込む: ワークフローのさまざまな段階で評価メカニズムを統合します。これらには、自己反省エージェント、取得したドキュメントの採点、自動品質チェックなどが含まれます。評価は、取得されたドキュメントが関連性があり、応答が正確であり、複雑なクエリのすべての部分が処理されていることを確認するのに役立ちます。
課題
エージェント RAG システムは、適応性、精度、動的推論の点で大きな利点を提供しますが、設計および実装の段階で対処する必要がある特定の課題も伴います。主な課題は次のとおりです。
- 複雑なワークフロー: エージェントと決定ポイントが追加されるにつれて、全体的なワークフローはますます複雑になります。これにより、実行時にエラーや障害が発生する可能性が高くなります。可能な限り、冗長なエージェントと不要な意思決定ポイントを排除して、合理化されたワークフローを優先します。
- スケーラビリティ: 大規模なデータセットと大量のクエリを処理するためにエージェント RAG システムを拡張するのは難しい場合があります。効率的なインデックス作成、キャッシュ、分散処理戦略を組み込んで、大規模なパフォーマンスを維持します。
- オーケストレーションと計算オーバーヘッド: 複数のエージェントによるワークフローの実行には、高度なオーケストレーションが必要です。これには、ボトルネックや競合を防ぐための慎重なスケジュール設定、依存関係の管理、エージェントの調整が含まれますが、これらはすべてシステム全体の複雑さを増大させます。
- 評価の複雑さ: これらのワークフローの評価には、各段階で異なる評価戦略が必要になるため、固有の課題が伴います。たとえば、RAG ステージでは、取得したドキュメントの関連性と完全性を評価する必要があり、生成された要約については品質と正確性をチェックする必要があります。同様に、クエリの再定式化の有効性には、書き換えられたクエリによって検索結果が改善されるかどうかを判断するための別の評価ロジックが必要です。
まとめ
このブログ投稿では、エージェント RAG の概念を紹介し、エージェント AI の自律機能を組み込むことで従来の RAG フレームワークをどのように強化するかについて説明しました。私たちは、エージェント RAG のコア機能を探り、Elasticsearch をベクター ストアとして使用し、LangChain を使用してエージェント フレームワークを作成するニュース アシスタントを構築するという実践的な例を通じて、これらの機能を実演しました。
さらに、エージェント RAG パイプラインを設計および実装する際に考慮すべきベスト プラクティスと主な課題についても説明しました。これらの洞察は、検索、推論、意思決定を効果的に組み合わせた、堅牢でスケーラブルかつ効率的なエージェント システムを開発者が作成できるようにするためのものです。
次のステップ
私たちが構築したワークフローはシンプルで、改善と実験の余地が十分にあります。さまざまな埋め込みモデルを試し、検索戦略を改良することで、これを強化できます。さらに、検索されたドキュメントに優先順位を付ける再ランク付けエージェントを統合すると有益となる可能性があります。もう一つの調査領域は、エージェント フレームワークの評価戦略の開発、具体的にはさまざまな種類のフレームワークに適用可能な共通かつ再利用可能なアプローチの特定です。最後に、これらのフレームワークを大規模でより複雑なデータセットで実験します。
その間、同様の実験を共有していただける場合は、ぜひお聞かせください。お気軽にフィードバックをお寄せください。また、コミュニティの Slack チャンネルやディスカッション フォーラムを通じてご連絡いただくこともできます。
各種資料
関連記事

2026年4月8日
MastraとElasticsearchを使用してエージェント型AIアプリケーションを構築する方法
MastraとElasticsearchを使用してエージェント型AIアプリケーションを構築する方法を実例を通じて学びましょう。

2026年3月25日
シェルツールはコンテキストエンジニアリングの万能薬ではありません
コンテキストエンジニアリングに利用できるコンテキスト検索ツールにはどのようなものがあるのか、それらがどのように機能するのか、そしてそれぞれのトレードオフについて学びましょう。

Elasticsearch Inference APIとHugging Faceモデルを組み合わせて使用
推論エンドポイントを使用してElasticsearchをHugging Faceモデルに接続する方法と、セマンティック検索とチャット補完機能を備えた多言語ブログ推奨システムを構築する方法を学びましょう。

TypeScriptを使用したElasticsearch MCPサーバーの作成
TypeScriptとClaude Desktopを使用してElasticsearch MCPサーバーを作成する方法を学びます。
ElasticsearchのGemini CLI拡張機能(ツールとスキル付き)
GoogleのGemini CLIでElasticsearchのデータを検索、取得、分析するためのElasticの拡張機能(開発者およびエージェントのワークフロー向け)をご紹介します。