La création de listes de jugement est une étape cruciale dans l'optimisation de la qualité des résultats de recherche, mais elle peut s'avérer une tâche compliquée et difficile. Une liste d'évaluation est un ensemble de requêtes de recherche associées à des notes de pertinence pour les résultats correspondants, également connu sous le nom de collection de tests. Les mesures calculées à l'aide de cette liste servent de référence pour mesurer les performances d'un moteur de recherche. Pour simplifier le processus de création des listes de jugement, l'équipe d'OpenSource Connections a développé Quepid. Le jugement peut être explicite ou basé sur un retour d'information implicite de la part des utilisateurs. Ce blog vous guidera dans la mise en place d'un environnement collaboratif dans Quepid afin de permettre aux évaluateurs humains d'effectuer des jugements explicites, ce qui est la base de toute liste de jugements.
Quepid soutient les équipes de recherche dans le processus d'évaluation de la qualité de la recherche :
- Construire des ensembles de requêtes
- Créer des listes de jugement
- Calculer les indicateurs de qualité de la recherche
- Comparer différents algorithmes de recherche/rankers sur la base de paramètres de qualité de recherche calculés
Pour notre blog, supposons que nous gérons un magasin de location de films et que notre objectif est d'améliorer la qualité de nos résultats de recherche.
Produits requis
Ce blog utilise les données et les correspondances du référentiel es-tmdb. Les données proviennent de The Movie Database. Pour continuer, créez un index appelé tmdb avec les mappings et indexez les données. Peu importe que vous mettiez en place une instance locale ou que vous utilisiez un déploiement Elastic Cloud pour cela - l'un ou l'autre fonctionne parfaitement. Pour ce blog, nous supposons un déploiement d'Elastic Cloud. Vous pouvez trouver des informations sur la manière d'indexer les données dans le README du dépôt es-tmdb.
Effectuez une simple recherche de correspondance dans le champ du titre pour rocky afin de confirmer que vous disposez des données nécessaires à la recherche :
Vous devriez voir 8 résultats.
Se connecter à Quepid
Quepid est un outil qui permet aux utilisateurs de mesurer la qualité des résultats de recherche et de mener des expériences hors ligne pour l'améliorer.
Vous pouvez utiliser Quepid de deux manières : soit vous utilisez la version gratuite et publiquement disponible à l'adresse https://app.quepid.com, ou installez Quepid sur une machine à laquelle vous avez accès. Cet article suppose que vous utilisez la version hébergée gratuite. Si vous souhaitez mettre en place une instance de Quepid dans votre environnement, suivez le Guide d'installation.
Quelle que soit la configuration choisie, vous devrez créer un compte si vous n'en avez pas déjà un.
Comment configurer un cas Quepid
Quepid est organisé autour des cas "." Un cas stocke les requêtes avec les paramètres de réglage de la pertinence et la façon d'établir une connexion avec votre moteur de recherche.
- Pour les nouveaux utilisateurs, sélectionnez Créer votre premier cas de pertinence.
- Les utilisateurs qui reviennent peuvent sélectionner Cas de pertinence dans le menu de haut niveau et cliquer sur + Créer un cas.
Donnez un nom descriptif à votre cas, par exemple "Movie Search Baseline,", car nous voulons commencer à mesurer et à améliorer notre recherche de base.
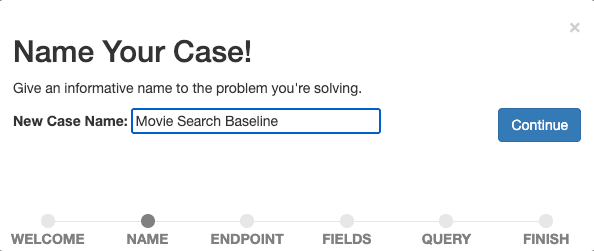
Confirmez le nom en sélectionnant Continuer.
Ensuite, nous établissons une connexion entre Quepid et le moteur de recherche. Quepid peut se connecter à une variété de moteurs de recherche, y compris Elasticsearch.
La configuration diffère en fonction de la configuration d'Elasticsearch et de Quepid. Pour connecter Quepid à un déploiement Elastic Cloud, nous devons activer et configurer CORS pour notre déploiement Elastic Cloud et avoir une clé API prête. Les instructions détaillées se trouvent dans le guide pratique correspondant dans la documentation de Quepid.
Saisissez les informations relatives à votre point de terminaison Elasticsearch (https://YOUR_ES_HOST:PORT/tmdb/_search) et toute autre information nécessaire à la connexion (la clé API dans le cas d'un déploiement Elastic Cloud dans les options de configuration avancées ), testez la connexion en cliquant sur ping it et sélectionnez Continue pour passer à l'étape suivante.

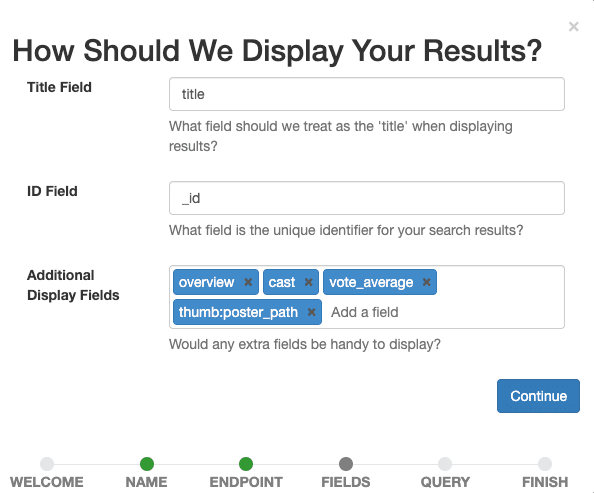
Nous définissons maintenant les champs que nous voulons voir apparaître dans le dossier. Sélectionner tout ce qui aide nos évaluateurs humains à évaluer ultérieurement la pertinence d'un document pour une requête donnée.
Définissez title comme champ de titre, laissez _id comme champ d'identification et ajoutez overview, tagline, cast, vote_average, thumb:poster_path comme champs d'affichage supplémentaires. La dernière entrée affiche de petites vignettes pour les films de nos résultats afin de nous guider visuellement, ainsi que les évaluateurs humains.
Confirmez les paramètres d'affichage en sélectionnant le bouton Continuer.
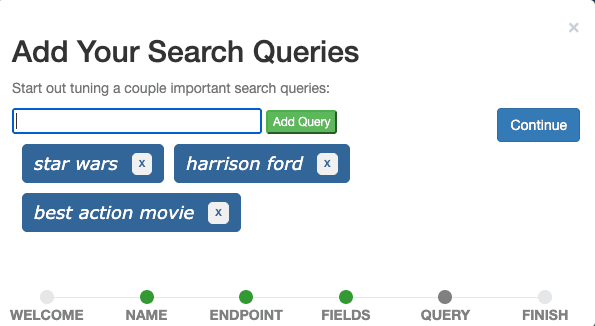
La dernière étape consiste à ajouter des requêtes de recherche au dossier. Ajoutez les trois requêtes star wars, harrison ford, et meilleur film d'action une par une dans le champ de saisie et continuez.
Idéalement, un cas contient des requêtes qui représentent des requêtes réelles d'utilisateurs et illustrent différents types de requêtes. Pour l'instant, nous pouvons imaginer que Star Wars est une requête représentant toutes les demandes de titres de films, que Harrison Ford est une requête représentant toutes les demandes de noms d'acteurs, et que le meilleur film d'action est une requête représentant toutes les demandes de films d'un genre spécifique. C'est ce que l'on appelle généralement un ensemble de requêtes.
Dans un scénario de production, nous échantillonnerions les requêtes à partir des données de suivi des événements en appliquant des techniques statistiques telles que l'échantillonnage proportionnel à la taille et importerions ces requêtes échantillonnées dans Quepid pour inclure les requêtes de la tête (requêtes fréquentes) et de la queue (requêtes peu fréquentes) par rapport à leur fréquence, ce qui signifie que nous privilégions les requêtes les plus fréquentes sans exclure les requêtes rares.
Enfin, sélectionnez Terminer et vous serez redirigé vers l'interface du cas où vous verrez les trois requêtes définies.
Requêtes et besoins d'information
Pour parvenir à l'objectif global d'une liste de jugement, les évaluateurs humains devront juger un résultat de recherche (généralement un document) pour une requête donnée. C'est ce qu'on appelle une paire requête/document.
Parfois, il semble facile de savoir ce que l'utilisateur voulait en regardant la requête. L'objectif de la requête harrison ford est de trouver des films mettant en scène l'acteur Harrison Ford. Qu'en est-il de la requête action? Je sais que je serais tenté de dire que l'intention de l'utilisateur est de trouver des films appartenant au genre action. Mais lesquels ? Les plus récents, les plus populaires, les meilleurs d'après les évaluations des utilisateurs ? Ou bien l'utilisateur souhaite-t-il trouver tous les films intitulés "Action" ? Il y a au moins 12 ( !) films appelés "Action" dans The Movie Database et leurs noms diffèrent principalement par le nombre de points d'exclamation dans le titre.
Deux évaluateurs humains peuvent interpréter différemment une requête dont l'intention n'est pas claire. Le besoin d'information : Un besoin d'information est un désir conscient ou inconscient d'obtenir des informations. La définition d'un besoin d'information aide les évaluateurs humains à juger les documents pour une requête, et joue donc un rôle important dans le processus d'élaboration des listes de jugement. Les utilisateurs experts ou les experts en la matière sont de bons candidats pour spécifier les besoins d'information. Une bonne pratique consiste à définir les besoins d'information du point de vue de l'utilisateur, car c'est à ses besoins que les résultats de la recherche doivent répondre.
Besoins en informations pour les requêtes de notre cas "Recherche de films de référence" :
- la guerre des étoiles: L'utilisateur souhaite trouver des films ou des émissions de la franchise Star Wars. Les documentaires sur la Guerre des étoiles sont potentiellement pertinents.
- harrison ford: L'utilisateur souhaite trouver des films mettant en scène l'acteur Harrison Ford. Les films dans lesquels Harrison Ford joue un rôle différent, comme celui de narrateur, sont potentiellement pertinents.
- meilleur film d'action: L'utilisateur souhaite trouver des films d'action, de préférence ceux dont la moyenne des votes des utilisateurs est élevée.
Comment définir les besoins en information dans Quepid
Pour définir un besoin d'information dans Quepid, accédez à l'interface du cas :
1. Ouvrez une requête (par exemplestar wars) et sélectionnez Toggle Notes.
2. Inscrivez le besoin d'information dans le premier champ et toute note supplémentaire dans le deuxième champ :
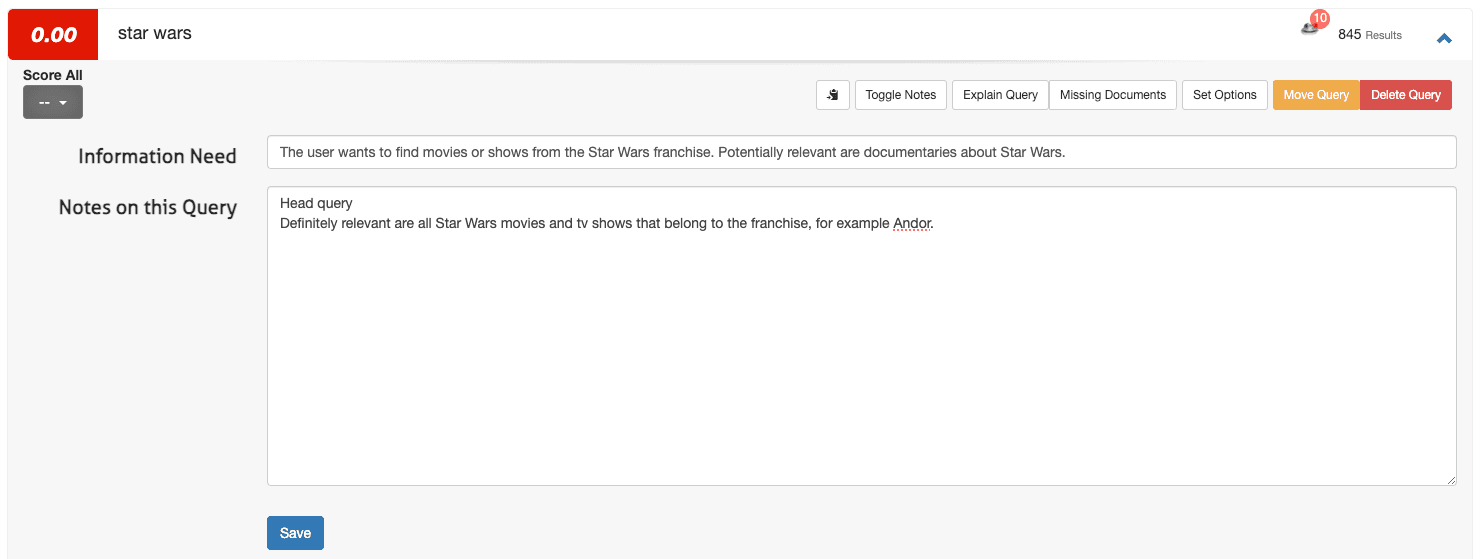
3. Cliquez sur Enregistrer.
Pour une poignée de requêtes, ce processus est satisfaisant. Cependant, lorsque vous passez de trois à 100 requêtes (les cas Quepid sont souvent compris entre 50 et 100 requêtes), vous pouvez définir les besoins d'information en dehors de Quepid (par exemple, dans une feuille de calcul), puis les télécharger via Import et sélectionner Besoins d'information.
Créez une équipe dans Quepid et partagez votre cas
Les jugements collaboratifs améliorent la qualité des évaluations de la pertinence. Mettre en place une équipe :
1. Naviguez jusqu'à Équipes dans le menu de haut niveau.

2. Cliquez sur + Ajouter nouveau, saisissez un nom d'équipe (par exemple, "Search Relevance Raters"), puis cliquez sur Créer.
3. Ajoutez des membres en saisissant leur adresse électronique et en cliquant sur Ajouter un utilisateur.
4. Dans l'interface du dossier, sélectionnez Partager le dossier.
5. Choisissez l'équipe appropriée et confirmez.
Créer un livre de jugements dans Quepid
Un livre dans Quepid permet à plusieurs évaluateurs d'évaluer systématiquement les paires requête/document. Pour en créer un :
1. Dans l'interface du dossier, allez dans Jugements et cliquez sur + Créer un livre.
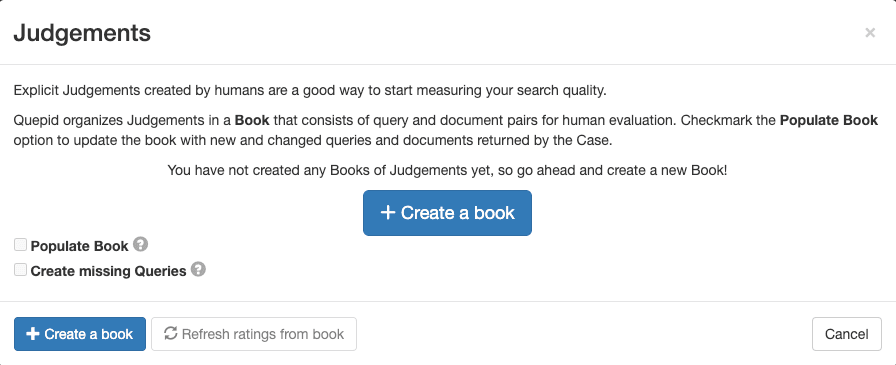
2. Configurez le livre avec un nom descriptif, assignez-le à votre équipe, sélectionnez une méthode de notation (par exemple, DCG@10) et définissez la stratégie de sélection (un ou plusieurs évaluateurs). Utilisez les paramètres suivants pour le livre :
- Nom: "Recherche de films échelle 0-3"
- Équipes avec lesquelles partager ce livre: Cochez la case de l'équipe que vous avez créée.
- Marqueur: DCG@10
3. Cliquez sur Créer un livre.
Le nom est descriptif et contient des informations sur l'objet de la recherche ("Films") ainsi que l'échelle des jugements ("0-3"). Le scoreur DCG@10 sélectionné définit la manière dont la métrique de recherche sera calculée. "DCG" est l'abréviation de Discounted Cumulative Gain (gain cumulatif actualisé ) et "@10" est le nombre de résultats à partir du sommet pris en considération lors du calcul de la mesure.
Dans ce cas, nous utilisons un indicateur qui mesure le gain d'information et le combine avec la pondération positionnelle. D'autres mesures de recherche peuvent être plus adaptées à votre cas d'utilisation et le choix de la bonne mesure est un défi en soi.
Remplir le book avec des paires requête/document
Afin d'ajouter des paires requête/document pour l'évaluation de la pertinence, suivez les étapes suivantes :
1. Dans l'interface du cas, naviguez vers "Judgements."

2. Sélectionnez le livre que vous avez créé.
3. Cliquez sur "Populate Book" et confirmez en sélectionnant "Refresh Query/Doc Pairs for Book."
Cette action génère des paires basées sur les meilleurs résultats de recherche pour chaque requête, prêtes à être évaluées par votre équipe.
Laissez votre équipe d’évaluateurs humains juger
Jusqu'à présent, les étapes franchies étaient plutôt techniques et administratives. Maintenant que cette préparation nécessaire est faite, nous pouvons laisser notre équipe de juges faire son travail. En substance, le travail du juge consiste à évaluer la pertinence d'un document particulier pour une requête donnée. Le résultat de ce processus est la liste de jugement qui contient tous les labels de pertinence pour les paires de documents de la requête jugés. Ensuite, ce processus et son interface sont expliqués plus en détail.
Aperçu de l'interface Human Rating

L'interface Human Rating de Quepid est conçue pour des évaluations efficaces :
- Requête : Affiche le terme de la recherche.
- Besoin d'information : Indique l'intention de l'utilisateur.
- Lignes directrices pour la notation : Fournit des instructions pour des évaluations cohérentes.
- Métadonnées du document : Présente des détails pertinents sur le document.
- Boutons d'évaluation : Permet aux évaluateurs d'attribuer des jugements à l'aide des raccourcis clavier correspondants.
Utilisation de l'interface Human Rating
En tant qu'évaluateur humain, j'accède à l'interface via l'aperçu du livre :
1. Accédez à l'interface du dossier et cliquez sur Jugements.
2. Cliquez sur Plus de jugements sont nécessaires !
Le système présentera une paire requête/document qui n'a pas encore été évaluée et qui nécessite des jugements supplémentaires. Elle est déterminée par la stratégie de sélection du Livre :
- Un seul évaluateur: Un seul jugement par paire requête/document.
- Plusieurs évaluateurs: Jusqu'à trois évaluations par paire requête/document.
Évaluation des paires requête/document
Voyons quelques exemples. Lorsque vous suivrez ce guide, vous serez probablement confronté à différents films. Cependant, les principes de notation restent les mêmes.
Notre premier exemple est le film "Heroes" pour la requête harrison ford:
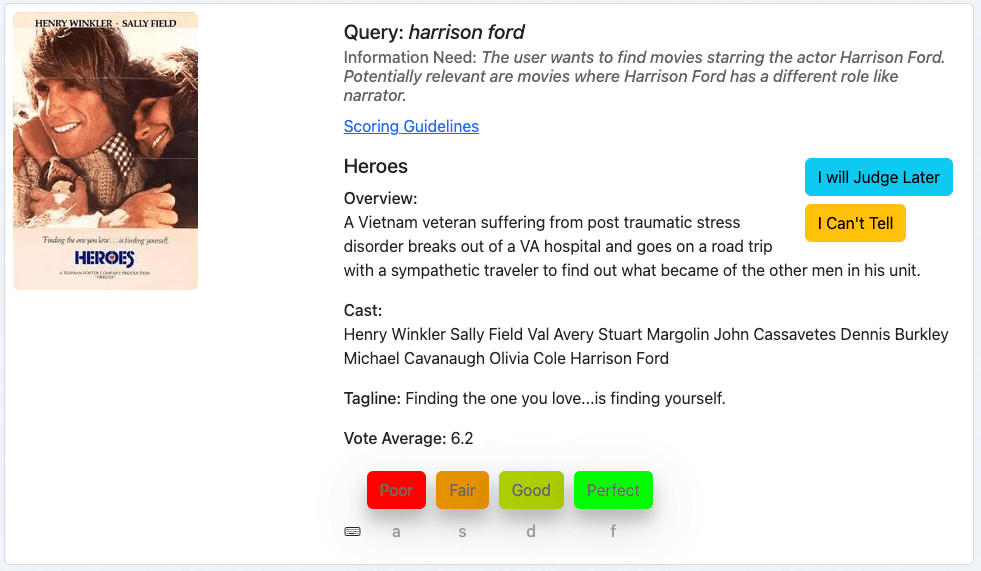
Nous examinons d'abord la requête, puis le besoin d'information et jugeons ensuite le film sur la base des métadonnées fournies.
Ce film est un résultat pertinent pour notre requête, puisque Harridson Ford en fait partie. Nous pouvons considérer subjectivement que les films plus récents sont plus pertinents, mais cela ne fait pas partie de notre besoin d'information. Nous attribuons donc à ce document la note "parfait", qui correspond à un 3 dans notre échelle de notation.
Notre prochain exemple est le film "Ford contre Ferrari" pour la requête harrison ford:

Selon la même pratique, nous évaluons cette requête/document en examinant la requête, le besoin d'information et la correspondance entre les métadonnées du document et le besoin d'information.
C'est un mauvais résultat. Ce résultat est probablement dû au fait que l'un des termes de notre requête, "ford", figure dans le titre. Mais Harrison Ford ne joue aucun rôle dans ce film, ni dans aucun autre. Nous attribuons donc à ce document la note "médiocre", ce qui correspond à un 0 dans notre échelle de notation.
Notre troisième exemple est le film "Action Jackson" pour la requête meilleur film d'action :
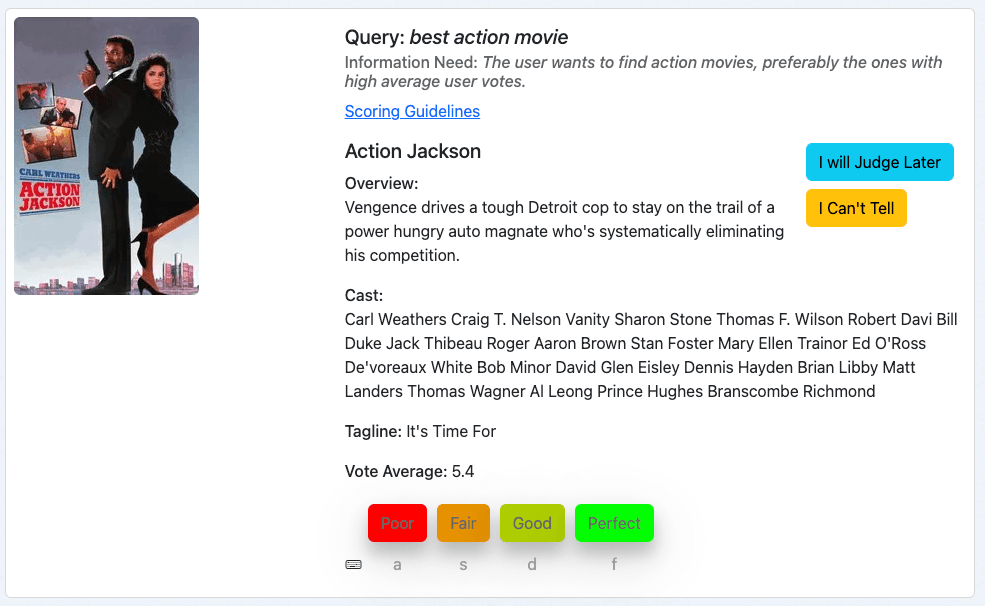
Cela ressemble à un film d'action, donc le besoin d'information est au moins partiellement satisfait. Cependant, la moyenne des votes est de 5,4 sur 10. Ce qui fait que ce film n'est probablement pas le meilleur film d'action de notre collection. Cela m'amènerait, en tant que juge, à attribuer à ce document la note "Passable", qui correspond à la note 1 dans notre échelle de notation.
Ces exemples illustrent le processus d'évaluation des paires requête/document avec Quepid en particulier, à un niveau élevé et aussi en général.
Bonnes pratiques pour les évaluateurs humains
Les exemples présentés peuvent donner l'impression qu'il est facile de parvenir à des jugements explicites. Mais la mise en place d'un programme d'évaluation humaine fiable n'est pas une mince affaire. C'est un processus plein de défis qui peut facilement compromettre la qualité de vos données :
- Les évaluateurs humains peuvent être fatigués par des tâches répétitives.
- Les préférences personnelles peuvent fausser les jugements.
- Les niveaux d'expertise varient d'un juge à l'autre.
- Les évaluateurs jonglent souvent avec de multiples responsabilités.
- La pertinence perçue d'un document peut ne pas correspondre à sa pertinence réelle par rapport à une requête.
Ces facteurs peuvent entraîner des jugements incohérents et de faible qualité. Mais ne vous inquiétez pas - il existe des bonnes pratiques éprouvées qui peuvent vous aider à minimiser ces problèmes et à mettre en place un processus d'évaluation plus solide et plus fiable :
- Évaluation cohérente : Examiner la requête, le besoin d'information et les métadonnées du document dans l'ordre.
- Se référer aux lignes directrices : Utiliser les lignes directrices pour la notation afin de maintenir la cohérence. Les lignes directrices en matière de notation peuvent contenir des exemples illustrant le processus de jugement et indiquant quand appliquer telle ou telle note. La vérification des évaluateurs humains après le premier lot de jugements s'est avérée être une bonne pratique pour connaître les cas limites difficiles et les domaines dans lesquels une aide supplémentaire est nécessaire.
- Utilisez les options : En cas d'incertitude, utilisez "I Will Judge Later" ou "I Can't Tell," en fournissant des explications si nécessaire.
- Faire des pauses : Des pauses régulières permettent de maintenir la qualité du jugement. Quepid facilite les pauses régulières en lançant des confettis chaque fois qu'un évaluateur humain termine un lot de jugements.
En suivant ces étapes, vous établissez une approche structurée et collaborative pour créer des listes d'arrêts dans Quepid, améliorant ainsi l'efficacité de vos efforts d'optimisation de la pertinence des recherches.
Étapes suivantes
Que faire maintenant ? Les listes de jugement ne sont qu'une étape fondamentale vers l'amélioration de la qualité des résultats de recherche. Voici les prochaines étapes :
Calculer les indicateurs et commencer à expérimenter
Une fois que les listes de jugements sont disponibles, l'exploitation des jugements et le calcul des mesures de la qualité de la recherche constituent une progression naturelle. Quepid calcule automatiquement la mesure configurée pour l'affaire en cours lorsque les jugements sont disponibles. Les mesures sont implémentées en tant que "Scorers" et vous pouvez fournir les vôtres lorsque les mesures supportées n'incluent pas vos préférées !
Accédez à l'interface du cas, naviguez jusqu'à Sélectionner un évaluateur, choisissez DCG@10 et confirmez en cliquant sur Sélectionner un évaluateur. Quepid va maintenant calculer le DCG@10 par requête ainsi que la moyenne des requêtes globales afin de quantifier la qualité des résultats de recherche pour votre cas.
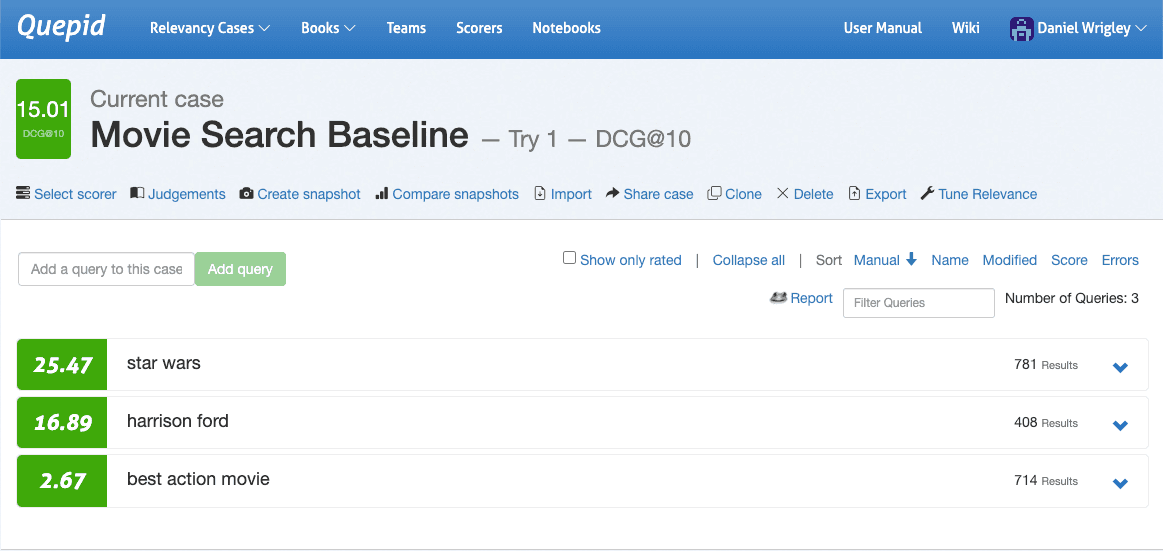
Maintenant que la qualité de vos résultats de recherche est quantifiée, vous pouvez lancer les premières expériences. L'expérimentation commence par la formulation d'hypothèses. En examinant les trois requêtes de la capture d'écran après avoir effectué un classement, il est évident que les trois requêtes ont des performances très différentes en termes de qualité de recherche : la guerre des étoiles est assez performante, harrison ford semble correct mais le plus grand potentiel réside dans le meilleur film d'action.
En développant cette requête, nous voyons ses résultats et pouvons nous plonger dans les détails les plus infimes et explorer les raisons pour lesquelles les documents correspondent et ce qui influence leurs scores :

En cliquant sur "Explain Query" et en entrant dans l'onglet "Parsing", nous voyons que la requête est une DisjunctionMaxxQuery qui recherche trois champs : cast, overview et title:

En général, en tant qu'ingénieurs de recherche, nous connaissons certaines spécificités de notre plateforme de recherche. Dans ce cas, nous pouvons savoir que nous avons un champ de genre. Ajoutons-le à la requête et voyons si la qualité de la recherche est améliorée.
Nous utilisons l'Environnement de recherche qui s'ouvre lorsque l'on sélectionne Accorder la pertinence dans l'interface du cas. Allez-y et explorez cette possibilité en ajoutant le champ des genres dans lequel vous effectuez votre recherche :
Cliquez sur Réexécuter mes recherches ! Et consultez les résultats. Ont-ils changé ? Malheureusement, ce n'est pas le cas. Nous avons maintenant beaucoup d'options à explorer, essentiellement toutes les options de requête offertes par Elasticsearch :
- Nous pourrions augmenter le poids du champ sur le champ des genres.
- Nous pourrions ajouter une fonction qui augmente les documents en fonction de leur moyenne de votes.
- Nous pourrions créer une requête plus complexe qui n'augmenterait les documents en fonction de leur moyenne de vote que s'il existe une forte correspondance des genres.
- …
L'avantage d'avoir toutes ces options et de les explorer dans Quepid est que nous avons un moyen de quantifier les effets non seulement sur la requête que nous essayons d'améliorer, mais aussi sur toutes les requêtes que nous avons dans notre cas. Cela nous évite d'améliorer une requête peu performante en sacrifiant la qualité des résultats de recherche pour les autres. Nous pouvons itérer rapidement et à peu de frais et valider la valeur de notre hypothèse sans aucun risque, ce qui fait de l'expérimentation hors ligne une capacité fondamentale pour toutes les équipes de recherche.
Mesurer la fiabilité inter-évaluateurs
Même avec des descriptions de tâches, des besoins d'information et une interface d'évaluation humaine comme celle fournie par Quepid, les évaluateurs humains peuvent ne pas être d'accord.
Le désaccord en soi n'est pas une mauvaise chose, bien au contraire : mesurer le désaccord peut mettre en lumière des questions que vous pourriez vouloir aborder. La pertinence peut être subjective, les requêtes peuvent être ambiguës et les données peuvent être incomplètes ou incorrectes. Le Kappa de Fleiss est une mesure statistique de l'accord entre les évaluateurs et il existe un cahier d'exemples dans Quepid que vous pouvez utiliser. Pour le trouver, sélectionnez Notebooks dans la navigation de haut niveau et sélectionnez le carnet Fleiss Kappa.ipynb dans le dossier examples.

Conclusion
Quepid vous permet de relever les défis les plus complexes en matière de pertinence des recherches et continue d'évoluer : à partir de la version 8, Quepid prend en charge les jugements générés par l'IA, ce qui est particulièrement utile pour les équipes qui souhaitent faire évoluer leur processus de génération de jugements.
Les flux de travail de Quepid vous permettent de créer efficacement des listes d'arrêts évolutives, ce qui se traduit par des résultats de recherche qui répondent réellement aux besoins des utilisateurs. Une fois les listes de jugement établies, vous disposez d'une base solide pour mesurer la pertinence des recherches, procéder à des améliorations itératives et améliorer l'expérience des utilisateurs.
N'oubliez pas que l'optimisation de la pertinence est un processus continu. Les listes de jugement vous permettent d'évaluer systématiquement vos progrès, mais elles sont plus efficaces lorsqu'elles sont associées à l'expérimentation, à l'analyse des mesures et aux améliorations itératives.
Lecture complémentaire
- Docs Quepid :
- Dépôt Github de Quepid
- Meet Pete, une série de blogs sur l'amélioration de la recherche dans le domaine du commerce électronique
- Relevance Slack: rejoignez le canal #quepid
Associez-vous à Open Source Connections pour transformer vos capacités de recherche et d'IA et donner à votre équipe les moyens de les faire évoluer en permanence. Nous avons fait nos preuves dans le monde entier et nos clients ont constamment amélioré la qualité de leurs recherches, les capacités de leurs équipes et les performances de leurs entreprises. Contactez-nous dès aujourd'hui pour en savoir plus.
Questions fréquentes
Qu'est-ce que Quepid ?
Quepid est un outil qui permet aux utilisateurs de mesurer la qualité des résultats de recherche et d'exécuter des expériences hors ligne pour l'améliorer.
Quels types d'expériences de qualité des résultats de recherche pouvez-vous créer dans Quepid ?
Vous pouvez effectuer de nombreuses expériences dans Quepid, notamment la création d'ensembles de requêtes, la création de listes de jugement, le calcul d'indicateurs de qualité de la recherche, la comparaison de différents algorithmes/classeurs de recherche sur la base d'indicateurs de qualité de la recherche calculés afin d'améliorer la pertinence de la recherche.
Comment utiliser Quepid et Elasticsearch ?
L'environnement de test de requêtes vous permet d'itérer rapidement et à moindre coût. Vous pouvez ajouter des poids de champs, augmenter les scores ou modifier la logique des requêtes et voir immédiatement comment cela impacte vos indicateurs de qualité de recherche (comme nDCG ou DCG@10) pour vos données dans Elasticsearch.
Pour aller plus loin

20 février 2026
Garantir une précision sémantique avec un score minimum
Améliorez la précision sémantique en utilisant des seuils de score minimum. Cet article présente des exemples concrets de recherche sémantique et hybride.

11 décembre 2025
Évaluer la pertinence des requêtes de recherche à l’aide de listes de jugement
Découvrez comment créer des listes de jugement pour évaluer objectivement la pertinence des requêtes de recherche et améliorer des indicateurs de performance comme le rappel, dans le cadre de tests de recherche scalable avec Elasticsearch.

27 novembre 2025
La recherche hybride sans prise de tête : simplifier la recherche hybride avec des extracteurs
Découvrez comment simplifier la recherche hybride dans Elasticsearch avec un format de requête à champs multiples pour les extracteurs linéaires et RRF, et créez des requêtes sans aucune connaissance préalable de votre index Elasticsearch.

12 novembre 2025
Vous savez, pour le contexte - Partie I : L'évolution de la recherche hybride et de l'ingénierie contextuelle
Découvrez comment la recherche hybride et l'ingénierie contextuelle ont évolué à partir de bases lexicales pour permettre la prochaine génération de flux de travail d'IA agentique.

28 mai 2025
La recherche hybride revisitée : introduction de la recherche linéaire dans Elasticsearch !
Découvrez comment le récupérateur linéaire améliore la recherche hybride en exploitant les scores pondérés et la normalisation MinMax pour des classements plus précis et plus cohérents, et apprenez à l'utiliser.