Dans Elasticsearch, joindre deux index n'est pas aussi simple que dans les bases de données relationnelles SQL traditionnelles. Cependant, il est possible d'obtenir des résultats similaires en utilisant certaines techniques et fonctionnalités fournies par Elasticsearch.
Historiquement, de nombreuses personnes ont utilisé le nested type de champ comme un mécanisme permettant de relier différents indices entre eux. Cependant, elle a été limitée par des requêtes coûteuses et une prise en charge incomplète dans Kibana, en particulier pour les visualisations de Lens.
Cet article se penche sur le processus de jonction de deux index dans Elasticsearch, en se concentrant sur les approches suivantes :
- Utilisation de la requête
terms - Utilisation du processeur
enrichdans les pipelines d'ingestion - Logstash
elasticsearchfilter plugin - ES|QL
ENRICH - ES|QL
LOOKUP JOIN
Utilisation des termes de la requête
La requête terms est l'un des moyens les plus efficaces de joindre deux index dans Elasticsearch. Cette requête permet de retrouver des documents contenant un ou plusieurs termes exacts dans un champ spécifique. Nous verrons ici comment l'utiliser pour joindre deux indices.
Tout d'abord, vous devez extraire les données requises du premier index. Cela peut être fait en utilisant une simple requête GET et en extrayant les valeurs de l'attribut _source.
Une fois que vous avez les données du premier index, vous pouvez les utiliser pour interroger le deuxième index. Cette opération s'effectue à l'aide de la requête terms, dans laquelle vous indiquez le champ et les valeurs que vous souhaitez faire correspondre.
En voici un exemple :
Dans cet exemple, field_in_second_index est le champ du deuxième index que vous souhaitez faire correspondre aux valeurs du premier index. value1_from_first_index et value2_from_first_index sont les valeurs du premier index que vous voulez faire correspondre au deuxième index.
La recherche de termes permet également d'effectuer les deux étapes ci-dessus en une seule fois à l'aide d'une technique appelée " recherche de termes". Elasticsearch se chargera de récupérer de manière transparente les valeurs à faire correspondre à partir d'un autre index. Par exemple, si vous disposez d'un index des équipes contenant une liste de joueurs :
Il est possible d'interroger un index de personnes pour connaître toutes les personnes jouant dans l'équipe 1, comme indiqué ci-dessous :
Dans l'exemple ci-dessus, Elasticsearch récupère de manière transparente les noms des joueurs à partir du document avec l'identifiant team1 dans l'index teams (c'est-à-dire "john", "bill" et "michael") et trouver tous les documents de l'index des personnes contenant l'une de ces valeurs dans le champ "nom".
Pour les curieux, la requête SQL équivalente serait la suivante :
Utilisation du processeur d'enrichissement
Le enrich processeur est un autre outil puissant qui peut être utilisé pour joindre deux index dans Elasticsearch. Ce processeur enrichit les données des documents entrants en ajoutant des données provenant d'un index d'enrichissement prédéfini.
Voici comment utiliser le processeur d'enrichissement pour joindre deux indices :
1. Tout d'abord, vous devez créer une politique d'enrichissement. Cette politique définit l'index à utiliser pour l'enrichissement, le champ à utiliser et le(s) champ(s) à utiliser pour enrichir les documents entrants.
En voici un exemple :
2. Une fois la politique créée, vous devez l'exécuter pour créer l'index d'enrichissement à partir de votre nouvelle politique :
Cela permet de créer un nouvel index caché enrichi qui sera utilisé lors de l'enrichissement. Selon la taille de l'index source, cette opération peut prendre un certain temps. Assurez-vous que la politique d'enrichissement est entièrement construite avant de passer à l'étape suivante.
3. Une fois la politique d'enrichissement élaborée, vous pouvez utiliser le processeur d'enrichissement dans un pipeline d'acquisition pour enrichir les données des documents entrants :
Dans cet exemple, field_in_second_index est le champ du deuxième index qui doit correspondre au champ match_field du premier index. enriched_field est le nouveau champ du deuxième index qui contiendra les données enrichies de enrich_fields dans le premier index.
L'un des inconvénients de cette approche est que si les données changent sur first_index, la politique d'enrichissement doit être réexécutée. L'index enrichi n'est pas mis à jour ou synchronisé automatiquement à partir de l'index source à partir duquel il a été construit. Cependant, si first_index est relativement stable, cette approche fonctionne bien.
Plugin de filtre Logstash elasticsearch
Si vous utilisez Logstash, une autre option similaire au processeur enrich décrit ci-dessus consiste à utiliser le plugin de filtre elasticsearch pour ajouter des champs pertinents à l'événement sur la base d'une requête spécifiée. La configuration de notre pipeline Logstash se trouve dans un fichier .conf, tel que my-pipeline.conf.
Imaginons que notre pipeline extrait des logs d'Elasticsearch à l'aide du elasticsearch plugin d'entrée, avec une requête pour réduire la sélection :
Si nous voulons enrichir ces messages avec des informations provenant d'un index donné, nous pouvons utiliser le elasticsearch plugin de filtre dans la filter section pour enrichir nos journaux :
Le code ci-dessus trouvera les documents de l'index index_name où type est le début et le champ opération correspond au champ spécifié opid, puis copiera la valeur du champ @timestamp dans un nouveau champ nommé started.
Les documents enrichis sont ensuite envoyés à la source de sortie appropriée, en l'occurrence Elasticsearch à l'aide du elasticsearch plugin de sortie:
Si vous utilisez déjà Logstash, cette option peut être utile pour consolider votre logique d'enrichissement en un seul endroit et la traiter au fur et à mesure de l'arrivée de nouveaux événements. Cependant, si vous ne l'êtes pas, cela ajoute de la complexité à votre solution, et un autre composant que vous devez gérer et entretenir.
ES|QL ENRICH
L'introduction d'ES|QL, qui a été généralisée dans la version 8.14, est un langage de requête en ligne pris en charge par Elasticsearch qui permet le filtrage, la transformation et l'analyse des données. La commande de traitement ENRICH permet d'ajouter des données à partir d'indices existants à l'aide d'une politique d'enrichissement.
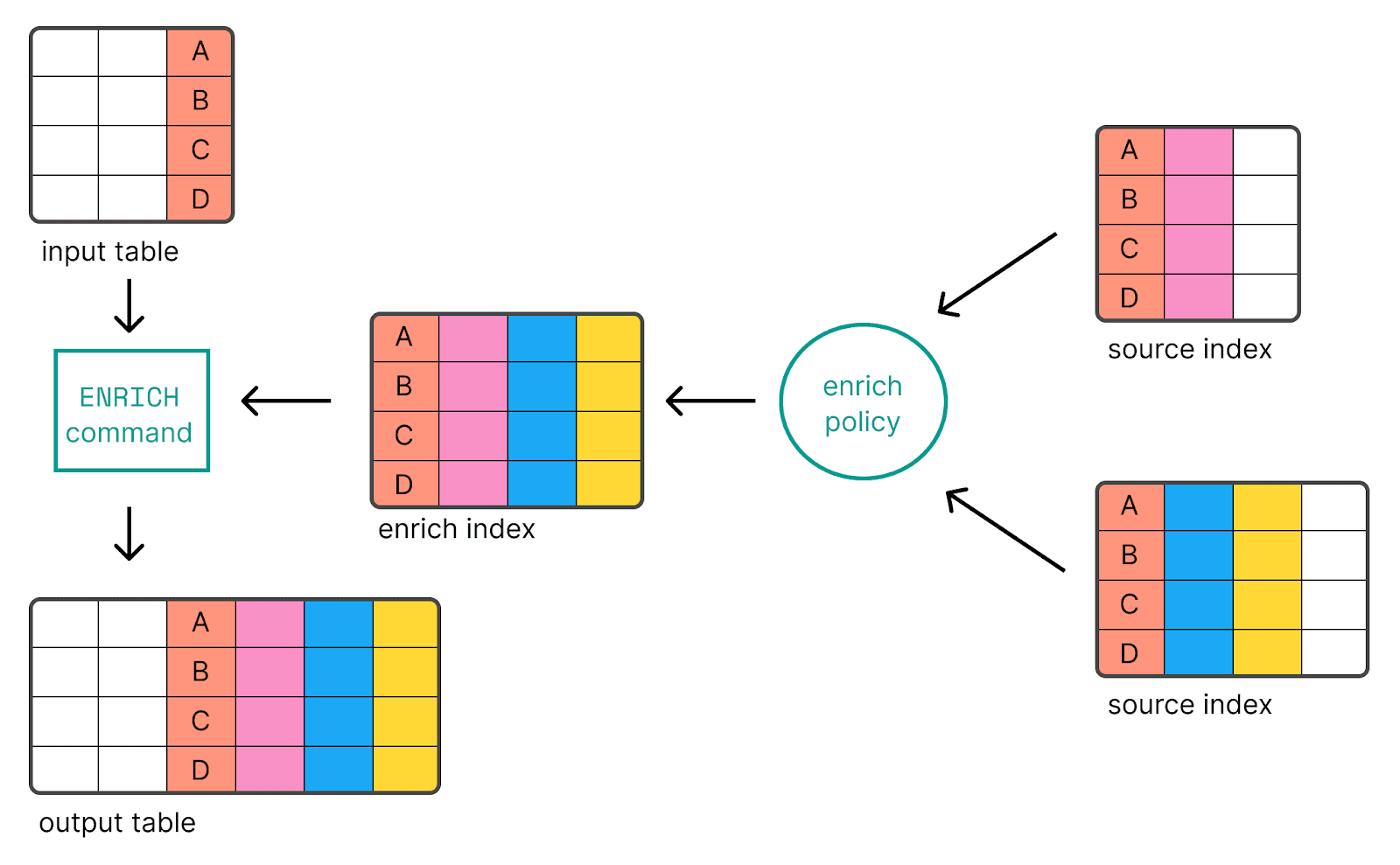
En reprenant la même politique my_enrich_policy que dans l'exemple original du processeur d'enrichissement, l'exemple ES|QL ressemblerait à ce qui suit :
Il est également possible de remplacer les champs de correspondance et d'enrichissement qui, dans notre exemple, sont respectivement field_in_first_index et field_to_enrich:
Bien que la limitation évidente soit que vous devez d'abord spécifier une politique d'enrichissement, ES|QL offre la flexibilité de modifier les champs selon les besoins.
ES|QL LOOKUP JOIN
Elasticsearch 8.18 introduit une nouvelle façon de joindre des index dans Elasticsearch, à savoir la commande LOOKUP JOIN. Cette commande fonctionne comme une jointure gauche-externe de type SQL en utilisant le nouveau mode d'indexation du côté droit de la jointure.

Si l'on reprend l'exemple précédent, la nouvelle requête est la suivante, où match_field doit être présent à la fois dans first_index et second_index:
L'avantage de LOOKUP JOIN par rapport aux autres approches est qu'il ne nécessite pas de politique enrich, et donc le traitement supplémentaire associé à la mise en place de la politique. Elle est utile lorsque l'on travaille avec des données d'enrichissement qui changent fréquemment, contrairement aux autres approches abordées dans cet article.
Conclusion
En conclusion, bien qu'Elasticsearch ne prenne pas en charge les opérations de jointure traditionnelles, il offre diverses fonctionnalités qui peuvent être utilisées pour obtenir des résultats similaires. Plus précisément, nous avons vu comment réaliser des opérations de jointure à l'aide de :
- La requête
terms - Le processeur
enrichdans les pipelines d'acquisition - Logstash
elasticsearchfilter plugin - ES|QL
ENRICH - ES|QL
LOOKUP JOIN
Il est important de noter que ces méthodes ont leurs limites et doivent être utilisées judicieusement en fonction des besoins spécifiques et de la nature des données.
Pour aller plus loin

14 novembre 2025
Comment déployer Elasticsearch sur Azure AKS Automatic
Découvrez comment déployer Elasticsearch avec Kibana sur Azure en utilisant AKS Automatic et ECK pour une configuration Elasticsearch partiellement gérée.

11 novembre 2025
Configurer le découpage récursif pour les documents structurés dans Elasticsearch
Apprenez à configurer le découpage récursif dans Elasticsearch avec la taille des morceaux, les groupes de séparateurs et les listes de séparateurs personnalisées pour une indexation optimale des documents structurés.

7 novembre 2025
Présentation de l'interface utilisateur des règles de requête Elasticsearch dans Kibana
Découvrez comment utiliser l'interface utilisateur Elasticsearch Query Rules pour ajouter ou exclure des documents des requêtes de recherche à l'aide d'ensembles de règles personnalisables dans Kibana, sans affecter le classement organique.

3 octobre 2025
Comment déployer Elasticsearch sur AWS Marketplace
Découvrez comment configurer et exécuter Elasticsearch à l'aide d'Elastic Cloud Service sur AWS Marketplace grâce à ce guide étape par étape.

14 août 2025
Shards et répliques Elasticsearch : Un guide pratique
Maîtriser les concepts de shards et de réplicas Elasticsearch et apprendre à les optimiser.