La creación de listas de juicio es un paso crucial para optimizar la calidad de los resultados de búsqueda, pero puede ser una tarea complicada y difícil. Una lista de juicios es un conjunto seleccionado de consultas de búsqueda combinadas con valoraciones de relevancia para sus resultados correspondientes, también conocida como colección de prueba. Las métricas calculadas mediante esta lista actúan como referencia para medir el rendimiento de un motor de búsqueda. Para agilizar el proceso de creación de listas de juicio, el equipo de OpenSource Connections desarrolló Quepid. El juicio puede ser explícito o basar en la retroalimentación implícita de los usuarios. Este blog te guiará para establecer un entorno colaborativo en Quepid que permita eficazmente a los evaluadores humanos hacer juicios explícitos, que es la base de cada lista de juicios.
Quepid apoya a los equipos de búsqueda en el proceso de evaluación de la calidad de búsqueda:
- Construcción de conjuntos de consultas
- Crear listas de juicios
- Calcular métricas de calidad de búsqueda
- Compara diferentes algoritmos/rankingers de búsqueda basándote en métricas calculadas de calidad de búsqueda
Para nuestro blog, supongamos que gestionamos una tienda de alquiler de películas y que tenemos como objetivo mejorar la calidad de los resultados de búsqueda.
Prerrequisitos
Este blog emplea los datos y los mapeos del repositorio es-tmdb. Los datos provienen de The Movie Database. Para seguir el ritmo, configura un índice llamado tmdb con los mapeos e indexa los datos. No importa si configuras una instancia local o usas un despliegue de Elastic Cloud para esto: cualquiera de las dos funciona bien. Asumimos un despliegue de Elastic Cloud para este blog. Puedes encontrar información sobre cómo indexar los datos en el README del repositorio es-tmdb.
Haz una consulta sencilla de coincidencias en el campo del título para rocky confirmar que tienes datos para buscar:
Deberías ver 8 resultados.
Iniciar sesión en Quepid
Quepid es una herramienta que permite a los usuarios medir la calidad de los resultados de búsqueda y ejecutar experimentos offline para mejorarla.
Puedes usar Quepid de dos maneras: o bien usar la versión gratis y disponible públicamente alojada en https://app.quepid.com, o configura Quepid en una máquina a la que tengas acceso. Esta publicación asume que estás usando la versión alojada gratis. Si quieres configurar una instancia de Quepid en tu entorno, sigue la Guía de Instalación.
Sea cual sea la configuración que elijas, tendrás que crear una cuenta si aún no tienes una.
Cómo configurar un caso de Quepid
Quepid está organizado en torno a los "Casos". Un caso almacena consultas junto con ajustes de relevancia y cómo establecer una conexión con tu motor de búsqueda.
- Para usuarios primerizos, selecciona Crear tu primer caso de relevancia.
- Los usuarios que regresan pueden seleccionar Casos de Relevancia desde el menú superior y hacer clic en + Crear un caso.
Nombra tu caso de forma descriptiva, por ejemplo, "Línea base de búsqueda de películas", ya que queremos empezar a medir y mejorar nuestra búsqueda de referencia.
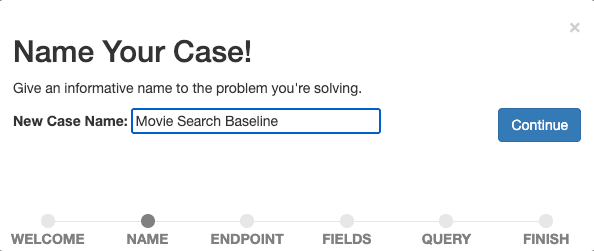
Confirma el nombre seleccionando Continuar.
A continuación, establecemos una conexión de Quepid con el motor de búsqueda. Quepid puede conectarse a una variedad de motores de búsqueda, incluido Elasticsearch.
La configuración variará según tu configuración de Elasticsearch y Quepid. Para conectar Quepid a un despliegue de Elastic Cloud, necesitamos habilitar y configurar CORS para nuestro despliegue de Elastic Cloud y tener lista una clave de API. Las instrucciones detalladas están en el tutorial correspondiente en la documentación de Quepid.
Introduce la información de tu endpoint de Elasticsearch (https://YOUR_ES_HOST:PORT/tmdb/_search) y cualquier información adicional necesaria para conectarte (la clave API en caso de un despliegue de Elastic Cloud en las opciones de configuración avanzada ), prueba la conexión haciendo clic en ping y selecciona Continuar para pasar al siguiente paso.

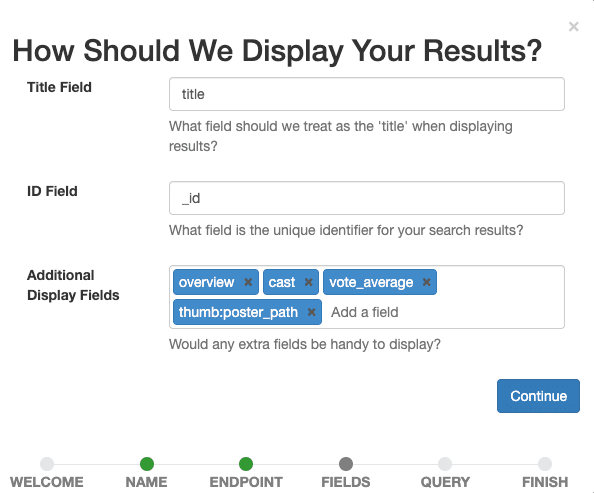
Ahora definimos qué campos queremos que se muestren en el caso. Selecciona todos los que ayuden a nuestros evaluadores humanos a evaluar posteriormente la relevancia de un documento para una consulta determinada.
Establece title como Campo de Título, deja _id como Campo ID y agrega overview, tagline, cast, vote_average, thumb:poster_path como Campos de Visualización Adicionales. La última entrada muestra pequeñas imágenes en miniatura de las películas en nuestros resultados para guiarnos visualmente a nosotros y a los evaluadores humanos.
Confirma la configuración de pantalla seleccionando el botón Continuar .
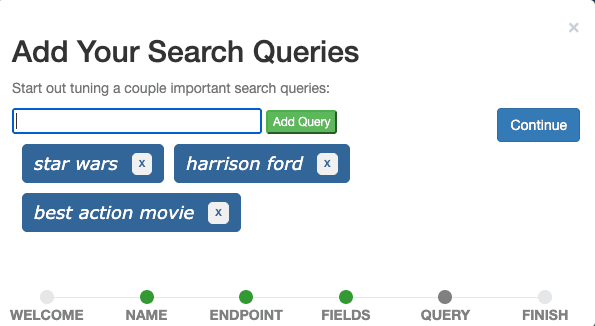
El último paso es agregar consultas de búsqueda al caso. Agrega las tres consultas Star Wars, Harrison Ford y la mejor película de acción una por una a través del campo de entrada y Continúa.
Idealmente, un caso contiene consultas que representan consultas reales de usuarios e ilustran diferentes tipos de consultas. Por ahora, podemos imaginar que Star Wars es una consulta que representa todas las consultas de títulos de películas, Harrison Ford una consulta que representa todas las consultas de los miembros del reparto, y Best Action Movie una consulta que representa todas las consultas que buscan películas de un género específico. Esto se denomina típicamente conjunto de consultas.
En un escenario de producción, muestrearíamos consultas de datos de seguimiento de eventos aplicando técnicas estadísticas como ejemplificación de probabilidad proporcional al tamaño e importaríamos estas consultas muestreadas a Quepid para incluir consultas desde la cabeza (consultas frecuentes) y cola (consultas poco frecuentes) en relación con su frecuencia, lo que significa que tendemos a optar por consultas más frecuentes sin excluir las raras.
Finalmente, selecciona Terminar y serás redirigido a la interfaz de casos donde verás las tres consultas definidas.
Búsquedas y necesidades de información
Para llegar a nuestro objetivo general de una lista de juicios, los evaluadores humanos deberán juzgar un resultado de búsqueda (normalmente un documento) para una consulta determinada. Esto se llama par consulta/documento.
A veces, parece fácil saber qué quería un usuario al revisar la consulta. La intención detrás de la harrison ford es encontrar películas protagonizadas por Harrison Ford, el actor. ¿Y qué pasa con la actionde la consulta? Sé que me tentaría decir que la intención del usuario es encontrar películas del género de acción. ¿Pero cuáles? ¿Los más recientes, los más populares, los mejores según las valoraciones de los usuarios? ¿O quizá el usuario quiere encontrar todas las películas que se llaman "Acción"? Hay al menos 12 (!) películas llamadas "Acción" en The Movie Database y sus nombres difieren principalmente en el número de signos de exclamación en el título.
Dos evaluadores humanos pueden diferir en la interpretación de una consulta cuando la intención no está clara. Entra en escena la necesidad de información: Una necesidad de información es un deseo consciente o inconsciente de información. Definir una necesidad de información ayuda a los evaluadores humanos a juzgar documentos para una consulta, por lo que desempeñan un papel importante en el proceso de elaboración de listas de juicio. Los usuarios expertos o expertos en la materia son buenos candidatos para especificar necesidades de información. Es buena práctica definir las necesidades de información desde la perspectiva del usuario, ya que es su necesidad la que los resultados de búsqueda deben satisfacer.
Necesidades de información para las consultas de nuestro caso "Línea de Base de Búsqueda de Películas":
- Star Wars: El usuario quiere encontrar películas o seriales de la franquicia Star Wars. Potencialmente relevantes son los documentales sobre Star Wars.
- Harrison Ford: El usuario quiere encontrar películas protagonizadas por el actor Harrison Ford. Potencialmente relevantes son las películas en las que Harrison Ford tiene un papel diferente, como el de narrador.
- mejor película de acción: El usuario quiere encontrar películas de acción, preferiblemente aquellas con votos medios altos.
Cómo definir las necesidades de información en Quepid
Para definir una necesidad de información en Quepid, accede a la interfaz de casos:
1. Abre una consulta (por ejemplo,s tar wars) y selecciona Alternar Notas.
2. Introduce la Necesidad de Información en el primer campo y cualquier nota adicional en el segundo campo:
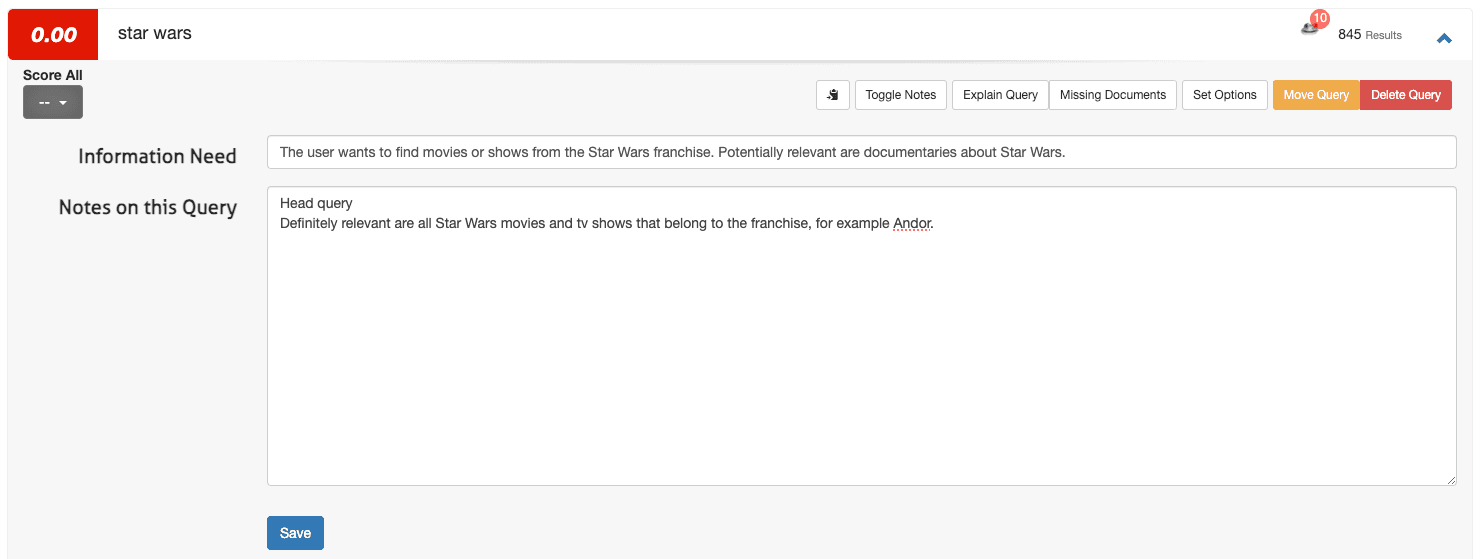
3. Haz clic en almacenar.
Para un puñado de consultas, este proceso está bien. Sin embargo, cuando amplías tu caso de tres a 100 consultas (los casos de Quepid suelen estar en el rango de 50 a 100 consultas), puede que quieras definir necesidades de información fuera de Quepid (por ejemplo, en una hoja de cálculo) y luego subirlas mediante Importar y seleccionar Necesidades de Información.
Crea un equipo en Quepid y comparte tu caso
Los juicios colaborativos mejoran la calidad de las evaluaciones de relevancia. Para formar un equipo:
1. Navega a Teams en el menú superior.

2. Haz clic + Agregar Nuevo, introduce el nombre de un equipo (por ejemplo, "Search Relevance Raters") y haz clic en Crear.
3. Agregar miembros escribiendo sus direcciones de email y haciendo clic en Agregar usuario.
4. En la interfaz de casos, selecciona Compartir Caso.
5. Elegir el equipo adecuado y confirmarlo.
Crea un libro de evaluaciones en Quepid
Un libro en Quepid permite a varios evaluadores evaluar sistemáticamente los pares consulta/documento. Para crear uno:
1. Ve a Sentencias en la interfaz del caso y haz clic + Crear un libro.
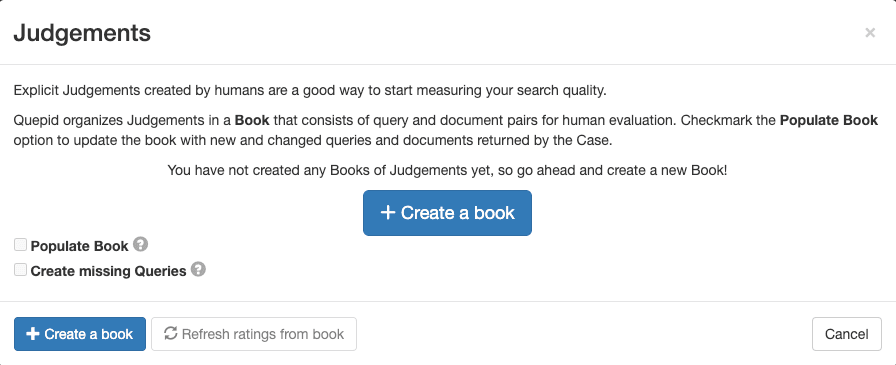
2. Configura el libro con un nombre descriptivo, asigna el libro a tu equipo, selecciona un método de puntaje (por ejemplo, DCG@10) y establece la estrategia de selección (uno o varios evaluadores). Emplea los siguientes ajustes para el libro:
- Nombre: "Búsqueda de películas a escala 0-3"
- Equipos con los que compartir este libro: Marca la casilla con el equipo que creaste
- Goleador: DCG@10
3. Haz clic en Crear libro.
El nombre es descriptivo y contiene información sobre lo que se busca en ("Películas") y también la escala de las sentencias ("0-3"). El DCG@10 seleccionado de Scorer define la forma en que se calculará la métrica de búsqueda. "DCG" es la abreviatura de Ganancia Acumulada Descontada y "@10" es el número de resultados desde la parte superior que se tiene en cuenta al calcular la métrica.
En este caso, estamos usando una métrica que mide la ganancia de información y la combina con ponderación posicional. Puede que haya otras métricas de búsqueda más adecuadas para tu caso de uso y elegir la adecuada es un desafío en sí mismo.
Llena el libro con pares de búsqueda/documento
Para agregar pares de consulta/documento para la evaluación de relevancia, sigue estos pasos:
1. En la interfaz del caso, navega a "Sentencias".

2. Selecciona tu libro creado.
3. Haz clic en "Poblar libro" y confirma seleccionando "Actualizar pares de consulta/documentos para libro."
Esta acción genera pares basados en los principales resultados de búsqueda de cada consulta, listos para su evaluación por parte de su equipo.
Deja que tu equipo de evaluadores humanos juzgue
Hasta ahora, los pasos completados fueron bastante técnicos y administrativos. Ahora que esta preparación necesaria está hecha, podemos dejar que nuestro equipo de jueces haga su trabajo. En esencia, el trabajo del juez es valorar la relevancia de un documento concreto para una consulta determinada. El resultado de este proceso es la lista de juicios que contiene todas las etiquetas de relevancia para los pares de documentos de consulta evaluados. A continuación, se explica este proceso y la interfaz para él con más detalle.
Visión general de la interfaz de calificación humana

La interfaz de calificación humana de Quepid está diseñada para evaluaciones eficientes:
- Consulta: Muestra el término de búsqueda.
- Necesidad de información: Muestra la intención del usuario.
- Directrices de puntaje: Proporciona instrucciones para evaluaciones consistentes.
- Metadatos del documento: Presenta detalles relevantes sobre el documento.
- Botones de valoración: Permite a los evaluadores asignar juicios con los atajos de teclado correspondientes.
Uso de la interfaz de calificación humana
Como evaluador humano, accedo a la interfaz a través de la visión general del libro:
1. Navega a la interfaz del caso y haz clic en Sentencias.
2. ¡Haz clic en Más Juicios Se Necesitan!
El sistema presentará un par de consulta/documento que aún no fue valorado y que requiere juicios adicionales. Esto está determinado por la estrategia de selección del Libro:
- Evaluador único: Un único juicio por par de consulta/documento.
- Evaluadores múltiples: hasta tres juicios por par de consulta/documento.
Calificación de pares de búsqueda/documento
Vamos a repasar un par de ejemplos. Al seguir esta guía, lo más probable es que te presenten diferentes películas. Sin embargo, los principios de clasificación se mantienen igual.
Nuestro primer ejemplo es la película "Heroes" para la consulta de Harrison Ford:
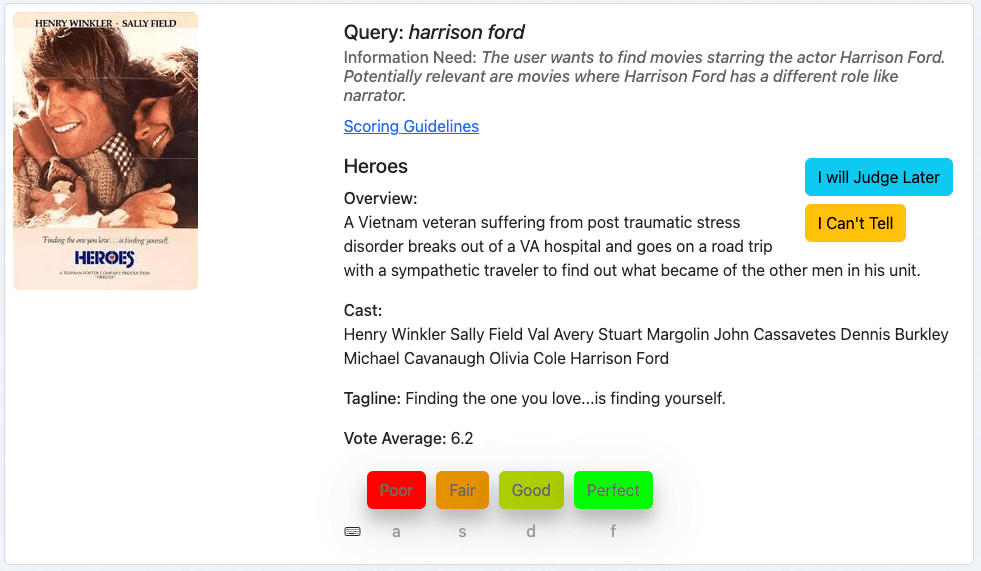
Primero analizamos la consulta, seguida de la necesidad de información y después juzgamos la película en función de los metadatos proporcionados.
Esta película es un resultado relevante para nuestra consulta, ya que Harridson Ford forma parte del reparto. Puede que consideremos las películas más recientes como más relevantes subjetivamente, pero esto no forma parte de nuestra necesidad informativa. Así que calificamos este documento con "Perfecto", que es un 3 en nuestra escala de calificación.
Nuestro siguiente ejemplo es la película "Ford v Ferrari" para la consulta Harrison Ford:

Siguiendo la misma práctica, juzgamos esta consulta/documento analizando la consulta, la necesidad de información y luego cuán bien los metadatos del documento coinciden con la necesidad de información.
Este es un resultado pobre. Probablemente veamos este resultado como uno de nuestros términos de consulta, "ford", coincide en el título. Pero Harrison Ford no tiene ningún papel en esta película, ni en ningún otro. Así que calificamos este documento como "Pobre", que es un 0 en nuestra escala de calificación.
Nuestro tercer ejemplo es la película "Action Jackson" para la mejor película de acción que se pregunta:
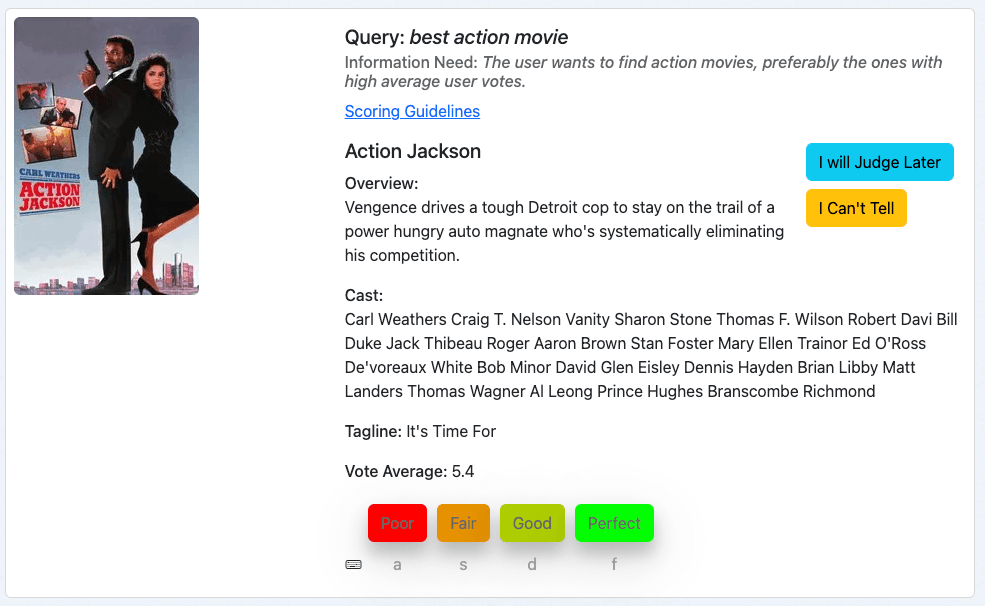
Esto parece una película de acción, así que la necesidad de información está al menos parcialmente cubierta. Sin embargo, la media de votos es de 5,4 sobre 10. Y eso hace que esta película probablemente no sea la mejor de acción de nuestra colección. Esto me llevaría, como juez, a calificar este documento como "Justo", que es un 1 en nuestra escala de calificación.
Estos ejemplos ilustran el proceso de valorar pares de consulta/documento con Quepid en individua, tanto a nivel general como en general.
Mejores prácticas para evaluadores humanos
Los ejemplos mostrados pueden hacer que parezca fácil llegar a juicios explícitos. Pero establecer un programa fiable de valoración humana no es tarea fácil. Es un proceso lleno de desafíos que pueden comprometer fácilmente la calidad de tus datos:
- Los evaluadores humanos pueden fatigar por tareas repetitivas.
- Las preferencias personales pueden sesgar los juicios.
- Los niveles de experiencia en el sector varían de un juez a otro.
- Los evaluadores suelen compaginar múltiples responsabilidades.
- La relevancia percibida de un documento puede no coincidir con su verdadera relevancia para una consulta.
Estos factores pueden dar lugar a juicios inconsistentes y de baja calidad. Pero no te preocupes: existen buenas prácticas probadas que pueden ayudarte a minimizar estos problemas y construir un proceso de evaluación más estable y fiable:
- Evaluación constante: Revisa la consulta, la necesidad de información y los metadatos del documento en orden.
- Consulte las Directrices: Emplea directrices de puntaje para mantener la consistencia. Las directrices de puntaje pueden incluir ejemplos de cuándo aplicar cada nota, lo que ilustra el proceso de evaluación. Tener una consulta con evaluadores humanos tras la primera tanda de sentencias resultó ser una buena práctica para aprender sobre casos límite difíciles y dónde se necesita apoyo adicional.
- Aprovecha las opciones: Si tienes dudas, emplea "Juzgaré más tarde" o "No puedo saberlo", proporcionando explicaciones cuando sea necesario.
- Toma descansos: Las pausas regulares ayudan a mantener la calidad del juicio. Quepid ayuda con los descansos regulares haciendo estallar confeti cada vez que un evaluador humano termina un serial de juicios.
Siguiendo estos pasos, estableces un enfoque estructurado y colaborativo para crear listas de juicios en Quepid, mejorando la eficacia de tus esfuerzos de optimización de relevancia en búsqueda.
Pasos siguientes
¿A dónde ir a partir de aquí? Las listas de juicio son solo un paso fundamental para mejorar la calidad de los resultados de búsqueda. Aquí están los siguientes pasos:
Calcula métricas y comienza a experimentar
Una vez que hay listas de juicios disponibles, aprovechar dichos juicios y calcular métricas de calidad de búsqueda es una progresión natural. Quepid calcula automáticamente la métrica configurada para el caso actual cuando hay sentencias disponibles. Las métricas se implementan como "Puntuadores" y puedes proporcionar las tuyas propias cuando las compatibles no incluyen a tu favorito.
Ve a la interfaz del caso, navega hasta Seleccionar Anotador, elige DCG@10 y confirma haciendo clic en Seleccionar Anotador. Quepid ahora calculará DCG@10 por consulta y también promediará el número total de consultas para cuantificar la calidad de los resultados de búsqueda de tu caso.
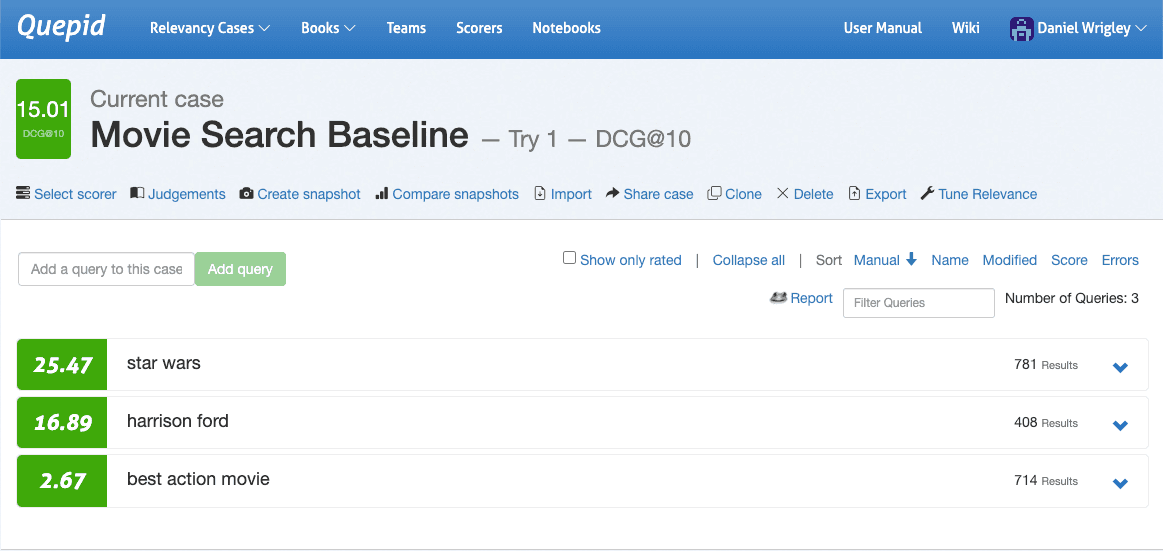
Ahora que la calidad de los resultados de búsqueda está cuantificada, puedes realizar los primeros experimentos. La experimentación comienza generando hipótesis. Mirar las tres consultas en la captura de pantalla tras hacer algunas valoraciones queda claro que las tres consultas rinden de forma muy diferente en cuanto a la métrica de calidad de búsqueda: Star Wars funciona bastante bien, Harrison Ford parece aceptable pero el mayor potencial está en la mejor película de acción.
Ampliando esta consulta, vemos sus resultados y podemos profundizar en los detalles más minuciosos y explorar por qué los documentos coincidieron y qué influye en sus puntajes:

Al hacer clic en "Explicar la consulta" y entrar en la pestaña "Análisis sintáctico" vemos que la consulta es una búsqueda de DisjunctionMaxxQuery en tres campos: cast, resumen y título:

Normalmente, como ingenieros de búsqueda, conocemos algunos detalles específicos de nuestro dominio sobre nuestra plataforma de búsqueda. En este caso, puede que sepamos que tenemos un campo de géneros . Vamos a agregar eso a la consulta y ver si la calidad de búsqueda mejora.
Usamos el Sandbox de Consultas que se abre al seleccionar Relevancia de Ajuste en la interfaz de casos. Adelante, explora esto agregando el campo de géneros en el que busques:
¡Haz clic en Volver a Ejecutar Mis Búsquedas! Y mira los resultados. ¿Cambiaron? Desgraciadamente no. Ahora tenemos muchas opciones para explorar, básicamente todas las opciones de consulta que ofrece Elasticsearch:
- Podríamos aumentar el peso del campo en el campo de géneros.
- Podríamos agregar una función que aumente los documentos por su media de votos.
- Podríamos crear una consulta más compleja que solo mejore los documentos por su promedio de votos si hay una coincidencia fuerte de géneros.
- …
Lo mejor de tener todas estas opciones y explorarlas en Quepid es que tenemos una forma de cuantificar los efectos no solo en la única consulta que intentamos mejorar, sino en todas las consultas que tenemos en nuestro caso. Eso nos impide mejorar una consulta que no rinde sacrificando la calidad de los resultados de búsqueda para otras. Podemos iterar rápida y barata y validar el valor de nuestra hipótesis sin ningún riesgo, haciendo de la experimentación offline una capacidad fundamental de todos los equipos de búsqueda.
Mide la confiabilidad entre evaluadores
Incluso con descripciones de tareas, necesidades de información y una interfaz de evaluador humano como la que ofrece Quepid, los evaluadores humanos pueden discrepar.
El desacuerdo en sí mismo no es algo malo, todo lo contrario: medir el desacuerdo puede sacar a la luz cuestiones que quizá quieras abordar. La relevancia puede ser subjetiva, las consultas pueden ser ambiguas y los datos pueden ser incompletos o incorrectos. El Kappa de Fleiss es una medida estadística del acuerdo entre evaluadores y hay un cuaderno de ejemplo en Quepid que puedes usar. Para encontrarlo, selecciona Cuadernos en la navegación superior y selecciona el cuaderno Fleiss Kappa.ipynb en la carpeta de ejemplos .

Conclusión
Quepid te permite afrontar incluso los retos de relevancia en búsquedas más complejos y sigue evolucionando: desde la versión 8, Quepid soporta juicios generados por IA, lo cual es especialmente útil para equipos que quieren escalar su proceso de generación de juicios.
Los flujos de trabajo quepid te permiten crear listas de juicios escalables de forma eficiente, lo que finalmente resulta en resultados de búsqueda que realmente satisfacen las necesidades de los usuarios. Con listas de juicios establecidas, tienes una base estable para medir la relevancia en las búsquedas, iterar mejoras y mejorar la experiencia de usuario.
A medida que avanzas, recuerda que la afinación de la relevancia es un proceso continuo. Las listas de juicio te permiten evaluar sistemáticamente tu progreso, pero son más poderosos cuando se combinan con experimentación, análisis métrico y mejoras iterativas.
Lecturas adicionales
- Documentos de Quepid:
- Repositorio de Quepid en Github
- Conoce a Pete, un serial de blogs sobre cómo mejorar la búsqueda en comercio electrónico
- Relevance Slack: únete al canal #quepid
Colabora con Open Source Connections para transformar tus capacidades de búsqueda e inteligencia artificial y empoderar a tu equipo para que las evolucione continuamente. Nuestro historial probado abarca todo el mundo, con clientes que logran de forma constante mejoras notables en la calidad de búsqueda, la capacidad del equipo y el rendimiento empresarial. Contacta con nosotros hoy mismo para obtener más información.
Preguntas frecuentes
¿Qué es Quepid?
Quepid es una herramienta que permite a los usuarios medir la calidad de los resultados de búsqueda y ejecutar experimentos offline para mejorarla.
¿Qué tipos de experimentos de calidad de resultados de búsqueda puedes crear en Quepid?
Hay muchos experimentos que puedes ejecutar en Quepid, como la construcción de conjuntos de consultas, la creación de listas de juicio, el cálculo de métricas de calidad de búsqueda, la comparación de diferentes algoritmos/rankings de búsqueda basados en métricas de calidad de búsqueda calculadas para mejorar la relevancia en las búsquedas.
¿Cómo usar Quepid y Elasticsearch?
Query Sandbox te permite iterar de manera rápida y económica. Puedes agregar ponderaciones de campos, aumentar puntajes o cambiar la lógica de consulta y ver al instante el impacto en las métricas de calidad de búsqueda (como nDCG o DCG@10) para tus datos en Elasticsearch.
Contenido relacionado

20 de febrero de 2026
Garantizar la precisión semántica con una puntuación mínima
Mejora la precisión semántica con umbrales de puntuación mínima. El artículo incluye ejemplos concretos de búsqueda semántica e híbrida.

11 de diciembre de 2025
Evaluación de la relevancia de las consultas de búsqueda con listas de evaluaciones
Explora cómo crear listas de evaluación para evaluar objetivamente la relevancia de las consultas de búsqueda y mejorar métricas de rendimiento como la recuperación, para pruebas de búsqueda escalables en Elasticsearch.

27 de noviembre de 2025
Búsqueda híbrida sin dolores de cabeza: simplificando la búsqueda híbrida con retrievers
Explora cómo simplificar la búsqueda híbrida en Elasticsearch con un formato de consulta multicampo para retrievers lineales y RRF, y crea consultas sin conocimientos previos sobre tu índice de Elasticsearch.

12 de noviembre de 2025
Para contexto, Parte I: La evolución de la búsqueda híbrida y la ingeniería del contexto
Explora cómo la búsqueda híbrida y la ingeniería contextual evolucionaron desde fundamentos léxicos hasta permitir la próxima generación de flujos de trabajo de IA agente.

28 de mayo de 2025
Búsqueda híbrida revisitada: ¡presentando el retriever lineal en Elasticsearch!
Descubre cómo el retriever lineal mejora la búsqueda híbrida aprovechando puntajes ponderados y la normalización MinMax para clasificaciones más precisas y consistentes, y aprende a usarlo.