En Elasticsearch, unir dos índices no es tan sencillo como en las bases de datos relacionales SQL tradicionales. Sin embargo, es posible lograr resultados similares empleando ciertas técnicas y características proporcionadas por Elasticsearch.
Históricamente, muchas personas usaban el tipo de campo nestedcomo un mecanismo para unir diferentes índices. Sin embargo, fue limitado debido a consultas costosas y soporte incompleto en Kibana, específicamente visualizaciones de Lens.
Este artículo profundizará en el proceso de unir dos índices en Elasticsearch, centrar en los siguientes enfoques:
- Uso de la consulta
terms - Uso del procesador
enrichen canalizaciones de ingesta - Complemento de filtro
elasticsearchLogstash - ES|QL
ENRICH - ES|QL
LOOKUP JOIN
Uso de la consulta de términos
La consulta de términos es una de las formas más efectivas de unir dos índices en Elasticsearch. Esta consulta se emplea para recuperar documentos que contienen uno o más términos exactos en un campo específico. Aquí discutimos cómo usarlo para unir dos índices.
En primer lugar, debe recuperar los datos necesarios del primer índice. Esto se puede hacer usando una simple solicitud GET y extrayendo los valores del atributo _source .
Una vez que tenga los datos del primer índice, puede usarlos para consultar el segundo índice. Esto se hace mediante la consulta terms , donde se especifica el campo y los valores que desea que coincidan.
Aquí hay un ejemplo:
En este ejemplo, field_in_second_index es el campo del segundo índice que desea hacer coincidir con los valores del primer índice. value1_from_first_index y value2_from_first_index son los valores del primer índice que desea que coincidan en el segundo índice.
La consulta de términos también proporciona soporte para realizar los dos pasos anteriores de una sola vez mediante una técnica denominada búsqueda de términos. Elasticsearch se encargará de recuperar de forma transparente los valores para que coincidan con otro índice. Por ejemplo, si tiene un índice de equipos que contiene una lista de jugadores:
Es posible consultar un índice de personas para todas las personas que juegan en team1, como se muestra a continuación:
En el ejemplo anterior, Elasticsearch recuperará de forma transparente los nombres de los jugadores del documento con id team1 en el índice de equipos (es decir, "John", "Bill" y "Michael") y busque todos los documentos en el índice de personas que contengan cualquiera de esos valores en su campo de nombre.
Para aquellos que tienen curiosidad, la consulta SQL equivalente sería:
Uso del procesador enrich
El procesador enriches otra herramienta poderosa que se puede usar para unir dos índices en Elasticsearch. Este procesador enriquece los datos de los documentos entrantes agregando datos de un índice de enriquecimiento predefinido.
A continuación, le indicamos cómo puede usar el procesador de enriquecimiento para unir dos índices:
1. Primero, debe crear una política de enriquecimiento. Esta directiva define qué índice usar para el enriquecimiento, en qué campo coincidir y qué campos usar para enriquecer los documentos entrantes.
Aquí hay un ejemplo:
2. Una vez creada la política, debe ejecutarla para crear el índice de enriquecimiento a partir de la política recién creada:
Esto creará un nuevo índice enriquecido oculto que se usará durante el enriquecimiento. En función del tamaño del índice de origen, esta operación puede tardar algún tiempo. Cerciorar de que la política de enriquecimiento esté completamente desarrollada antes de continuar con el siguiente paso.
3. Una vez creada la directiva de enriquecimiento, puede emplear el procesador de enriquecimiento en una canalización de ingesta para enriquecer los datos de los documentos entrantes:
En este ejemplo, field_in_second_index es el campo del segundo índice que debe coincidir con el match_field del primer índice. enriched_field es el nuevo campo del segundo índice que contendrá los datos enriquecidos de la enrich_fields del primer índice.
Un inconveniente de este enfoque es que si los datos cambian en first_index, la política de enriquecimiento debe volver a ejecutar. El índice enriquecido no se actualiza ni sincroniza automáticamente desde el índice de origen a partir del cual se creó. Sin embargo, si first_index es relativamente estable, entonces este enfoque funciona bien.
Complemento de filtro Logstash elasticsearch
Si usa Logstash, otra opción similar al procesador de enrich descrito anteriormente es usar el complemento de filtro elasticsearch para agregar campos relevantes al evento en función de una consulta específica. La configuración de nuestra canalización de Logstash residiría en un archivo .conf , como my-pipeline.conf.
Imaginemos que nuestra canalización está extrayendo registros de Elasticsearch usando el complemento de entrada elasticsearch, con una consulta para reducir la selección:
Si queremos enriquecer estos mensajes con información de un índice determinado, podemos usar el complemento de filtro elasticsearchen la sección filter para enriquecer nuestros registros:
El código anterior buscará los documentos del índice index_name donde se inicia type y el campo de operación coincide con el opidespecificado y, a continuación, copiará el valor del campo @timestamp en un nuevo campo denominado started.
Los documentos enriquecidos se enviarían a la fuente de salida adecuada, en este caso a Elasticsearch mediante el complemento de salida elasticsearch:
Si ya está empleando Logstash, esta opción puede ser útil para consolidar su lógica de enriquecimiento en un solo lugar y procesar a medida que ingresan nuevos eventos. Sin embargo, si no lo está, agrega complejidad a su solución y otro componente que necesita ejecutar y mantener.
ES|ENRIQUECER QL
La introducción de ES|QL, que pasó a ser GA en la versión 8.14, es un lenguaje de consulta canalizado compatible con Elasticsearch que permite filtrar, transformar y analizar datos. El uso del comando de procesamiento ENRICH nos permite agregar datos de índices existentes mediante una política de enriquecimiento.
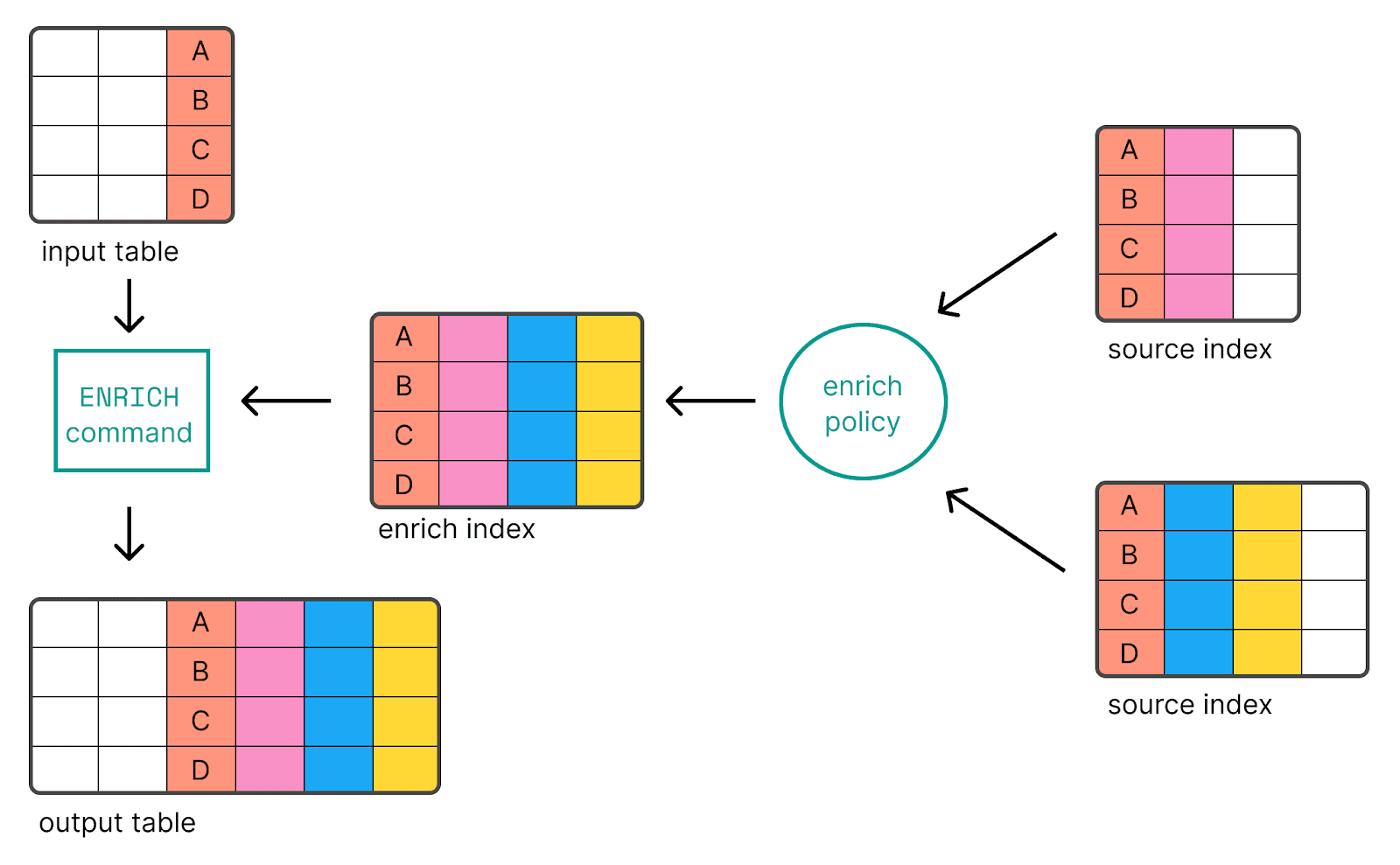
Tomando la misma my_enrich_policy de políticas del ejemplo original del procesador de enriquecimiento, el ES|El ejemplo de QL se vería así:
También es posible anular los campos de coincidencia y enriquecimiento, que en nuestro ejemplo son field_in_first_index y field_to_enrich respectivamente:
Si bien la limitación obvia es que primero debe especificar una política de enriquecimiento, ES|QL proporciona la flexibilidad para ajustar los campos según sea necesario.
ES|UNIÓN DE BÚSQUEDA DE QL
Elasticsearch 8.18 presenta una nueva forma de unir índices en Elasticsearch, a saber, el comando LOOKUP JOIN . Este comando funciona como una LEFT OUTER JOIN de estilo SQL empleando el nuevo modo de índice de búsqueda en el lado derecho de la unión.

Revisando nuestro ejemplo anterior, la nueva consulta es la siguiente, donde match_field debe estar presente tanto en first_index como en second_index:
El beneficio de LOOKUP JOIN sobre los otros enfoques es que no requiere ninguna directiva de enrich y, por lo tanto, el procesamiento adicional asociado con la configuración de la directiva. Es útil cuando se trabaja con datos de enriquecimiento que cambian con frecuencia, a diferencia de los otros enfoques que se analizan en este artículo.
Conclusión
En conclusión, si bien Elasticsearch no admite operaciones de unión tradicionales, proporciona varias características que se pueden usar para lograr resultados similares. Específicamente, cubrimos cómo lograr operaciones de unión usando:
- La consulta
terms - El procesador
enrichen canalizaciones de ingesta - Complemento de filtro
elasticsearchLogstash - ES|QL
ENRICH - ES|QL
LOOKUP JOIN
Es importante tener en cuenta que estos métodos tienen sus limitaciones y deben usar juiciosamente según los requisitos específicos y la naturaleza de los datos.
Contenido relacionado

14 de noviembre de 2025
Cómo desplegar Elasticsearch en Azure AKS Automatic
Aprende cómo desplegar Elasticsearch con Kibana en Azure usando AKS Automatic y ECK para una configuración parcialmente gestionada de Elasticsearch.

11 de noviembre de 2025
Configuración del fragmento recursivo para documentos estructurados en Elasticsearch
Aprende a configurar el chunking recursivo en Elasticsearch con tamaño de bloque, grupos de separadores y listas de separadores personalizadas para una indexación óptima de documentos estructurados.

7 de noviembre de 2025
Introducción de la interfaz de reglas de consulta Elasticsearch en Kibana
Aprende a usar la interfaz de Reglas de Consulta de Elasticsearch para agregar o excluir documentos de consultas de búsqueda usando conjuntos de reglas personalizables en Kibana, sin afectar al ranking orgánico.

3 de octubre de 2025
Cómo desplegar Elasticsearch en AWS Marketplace
Aprende a configurar y ejecutar Elasticsearch utilizando Elastic Cloud Service en AWS Marketplace con esta guía paso a paso.

14 de agosto de 2025
Fragmentos y réplicas de Elasticsearch: Una guía práctica
Domina los conceptos de fragmentos y réplicas de Elasticsearch y aprende a optimizarlos.