创建判断列表是优化搜索结果质量的关键步骤,但这可能是一项复杂而艰巨的任务。判断列表是一组经过整理的搜索查询,并对其相应结果进行相关性评级,也称为测试集合。使用该列表计算的指标可作为衡量搜索引擎性能的基准。为了帮助简化创建判断列表的过程,OpenSource Connections团队开发了Quepid。判断可以是明确的,也可以基于用户的隐性反馈。本博客将指导您在 Quepid 中建立一个协作环境,以便有效地让人类评分员进行明确的判断,这是每个判断列表的基础。
Quepid 在搜索质量评估过程中为搜索团队提供支持:
- 建立查询集
- 创建判断列表
- 计算搜索质量指标
- 根据计算得出的搜索质量指标,比较不同的搜索算法/排名器
在我们的博客中,假设我们经营一家电影租赁店,目标是提高搜索结果的质量。
准备工作
本博客使用es-tmdb 资源库中的数据和映射。数据来自电影数据库。接下来,使用映射建立名为 tmdb 的索引,并为数据建立索引。不管是建立本地实例还是使用弹性云部署,都可以正常工作。我们假设本博客使用的是弹性云部署。你可以在es-tmdb 软件仓库的 README 中找到有关如何为数据建立索引的信息。
对rocky 的标题字段进行简单的匹配查询,以确认有数据可供搜索:
您将看到 8 项结果。
登录 Quepid
Quepid是一款能让用户衡量搜索结果质量并进行离线实验以提高质量的工具。
您可以通过两种方式使用 Quepid:一种是使用https://app.quepid.com 上的免费公开托管版本、或在你可以访问的机器上设置 Quepid。本帖假设您使用的是免费托管版本。如果您想在自己的环境中建立一个 Quepid 实例,请遵循《安装指南》。
无论您选择哪种设置,如果还没有账户,您都需要创建一个账户。
如何设置 Quepid 案例
Quepid 的组织结构围绕"案例展开。"案例可存储查询、相关性调整设置以及如何与搜索引擎建立连接。
- 对于首次使用的用户,请选择创建第一个相关性案例。
- 老用户可以从顶层菜单中选择相关性案例,然后点击+ 创建案例。
请描述性地命名您的案例,例如"电影搜索基线," ,因为我们希望开始测量和改进我们的基线搜索。
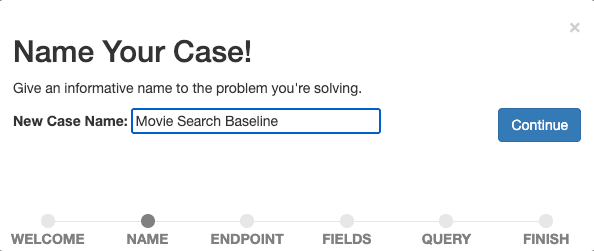
选择继续,确认名称。
接下来,我们建立 Quepid 与搜索引擎的连接。Quepid 可以连接各种搜索引擎,包括 Elasticsearch。
配置会因 Elasticsearch 和 Quepid 设置的不同而有所差异。要将 Quepid 连接到 Elastic Cloud 部署,我们需要为 Elastic Cloud 部署启用和配置 CORS,并准备好 API 密钥。详细说明见 Quepid 文档中的 相应 操作 指南。
输入 Elasticsearch 端点信息 (https://YOUR_ES_HOST:PORT/tmdb/_search) 和连接所需的其他信息(如果在高级配置选项中部署了 Elastic Cloud,则输入 API 密钥),点击ping测试连接,然后选择继续进入下一步。

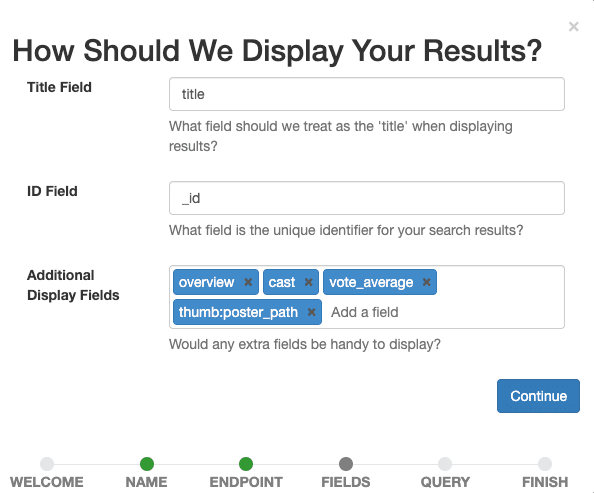
现在,我们定义要在案例中显示的字段。选择所有有助于我们的人工评判员稍后评估文档与给定查询相关性的内容。
将title 设置为标题字段,将_id 保留为ID 字段,将overview, tagline, cast, vote_average, thumb:poster_path 添加为附加显示字段。最后一个条目显示了结果中电影的小缩略图,为我们和人类评分员提供视觉指导。
选择继续按钮确认显示设置。
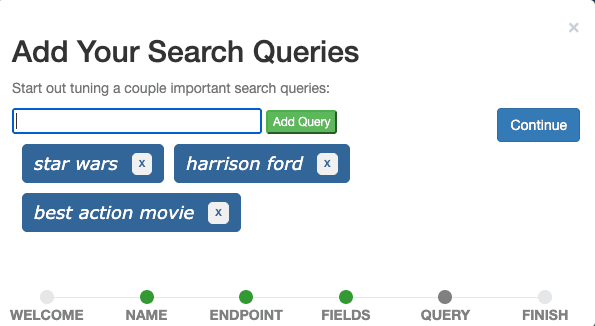
最后一步是在案例中添加搜索查询。通过输入框逐一添加 "星球大战"、"哈里森-福特"和 "最佳动作片"三个查询,然后继续。
理想情况下,案例包含的查询能代表真实的用户查询,并能说明不同类型的查询。现在,我们可以把《星球大战》想象成一个查询,代表所有关于电影名称的查询;把哈里森-福特想象成一个查询,代表所有关于演员的查询;把最佳动作片想象成一个查询,代表所有搜索特定类型电影的查询。这通常称为查询集。
在生产场景中,我们将通过应用概率比例大小采样等统计技术,从事件跟踪数据中抽取查询样本,并将这些采样查询导入 Quepid,以根据查询频率包含头部(频繁查询)和尾部(不频繁查询)的查询,这意味着我们会偏向于更频繁的查询,而不会排除罕见的查询。
最后,选择 "完成",您将转到案例界面,看到三个已定义的查询。
查询和信息需求
为了实现我们的总体目标--评判列表,人类评判者需要对给定查询的搜索结果(通常是文档)进行评判。这就是所谓的查询/文档对。
有时,在查看查询时似乎很容易知道用户想要什么。查询harrison ford 的目的是查找演员哈里森-福特主演的电影。查询action 如何?我知道我很想说用户的意图是寻找动作类型的电影。但是是哪些呢?最新的、最受欢迎的、用户评价最好的?或者,用户是否想找到所有名为 "动作 "的电影?在电影数据库中,至少有 12 部(!)电影被称为 "动作片",它们的名称主要区别在于片名中感叹号的数量。
如果查询的意图不明确,两名人工评分员对查询的解释可能会有所不同。输入信息需求:信息需求是一种有意识或无意识的信息渴望。定义信息需求有助于人类评判员判断查询的文档,因此他们在建立判断列表的过程中发挥着重要作用。专家用户或主题专家是明确信息需求的最佳人选。从用户的角度来定义信息需求是一种很好的做法,因为搜索结果应该满足用户的需求。
电影搜索基线 "案例查询的信息需求:
- 星球大战用户希望查找《星球大战》系列电影或节目。有可能相关的是关于《星球大战》的纪录片。
- 哈里森-福特用户希望查找演员 Harrison Ford 主演的电影。哈里森-福特扮演不同角色的电影也可能与此相关,比如旁白。
- 最佳动作片:用户希望找到动作片,最好是用户平均票数高的动作片。
如何在 Quepid 中定义信息需求
要在 Quepid 中定义信息需求,请访问案例界面:
1.打开一个查询(例如星际大战)并选择切换备注。
2.在第一个字段中输入信息需求,并在第二个字段中输入任何附加说明:
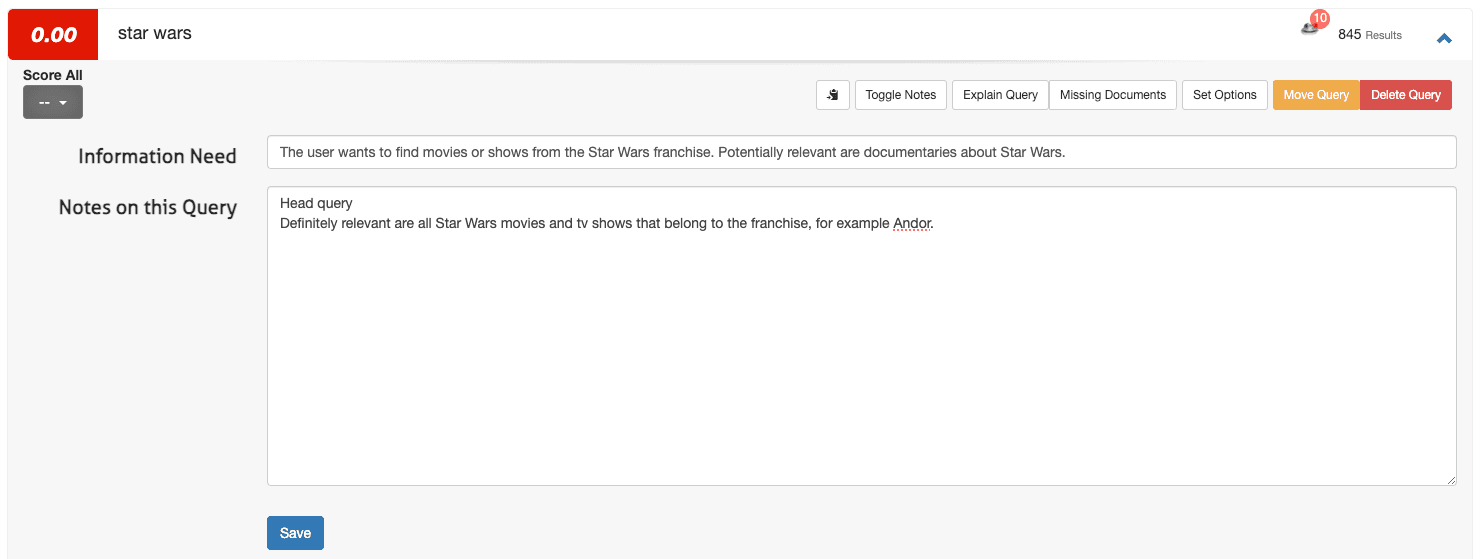
3.单击保存。
对于少数几个查询,这个过程没有问题。但是,当您将案例从 3 个查询扩展到 100 个查询时(Quepid 案例通常在 50 到 100 个查询之间),您可能希望在 Quepid 之外定义信息需求(例如,在电子表格中),然后通过导入并选择信息需求来上传。
在 Quepid 中创建团队并共享案例
合作判断可提高相关性评估的质量。组建团队:
1.在顶层菜单中导航至团队。

2.单击+ 添加新成员,输入团队名称(例如"Search Relevance Raters" ),然后单击创建。
3.输入成员的电子邮件地址并单击 "添加用户",添加成员。
4.在个案界面,选择共享个案。
5.选择合适的团队并确认。
在 Quepid 中创建评估手册
Quepid 中的一本书允许多个评分者对查询/文档对进行系统评估。创建一个
1.转到案件界面中的 判决书 ,点击 + 创建一本书 。
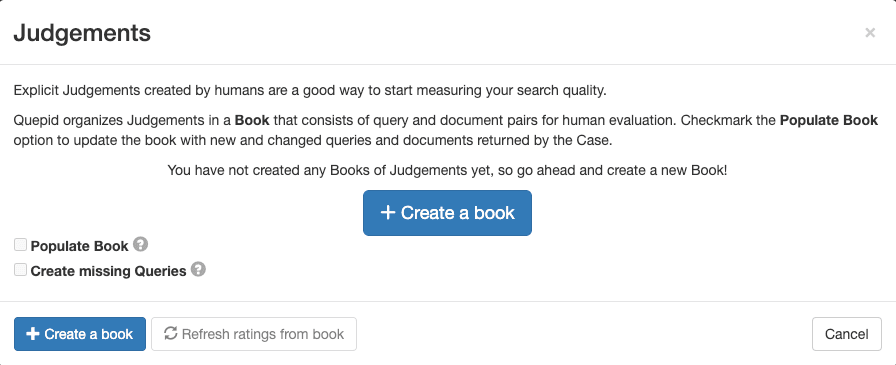
2.为图书配置一个描述性的名称,将其分配给您的团队,选择一种评分方法(例如 DCG@10),并设置选择策略(单个或多个评分者)。图书使用以下设置:
- 名称:"电影搜索 0-3 刻度"
- 要与之分享此书的团队:勾选您创建的团队
- 得分者DCG@10
3.单击创建图书。
名称具有描述性,包含搜索内容("电影")和评判标准("0-3")的信息。所选的 Scorer DCG@10 定义了搜索指标的计算方式。DCG "是 "贴现累积收益"的缩写,"@10 "是在计算该指标时,从顶部开始考虑的结果数量。
在这种情况下,我们使用一种衡量信息增益的指标,并将其与位置加权相结合。可能还有其他搜索指标更适合您的使用情况, 选择合适的 指标 本身就是一项挑战 。
用查询/文档对填充评估手册
要添加查询/文档对进行相关性评估,请按照以下步骤操作:
1.在案件界面中,导航至"判决。"

2.选择您创建的图书。
3.单击"Populate Book" ,然后选择"Refresh Query/Doc Pairs for Book 进行确认。"
该操作根据每个查询的热门搜索结果生成配对,供团队评估。
让您的人工评分团队进行评估
到目前为止,已完成的步骤都是相当技术性和行政性的。现在,这些必要的准备工作已经完成,我们可以让我们的评委团队开展工作了。从本质上讲,法官的工作就是评定特定文档与给定查询的相关性。这一过程的结果就是判断列表,其中包含了被判断的查询文档对的所有相关性标签。接下来,我们将进一步详细解释这一过程及其界面。
人工评分界面概览

Quepid 的人工评分界面专为高效评估设计:
- 查询:显示搜索词。
- 信息需求:显示用户的意图。
- 评分指南:提供一致评价的说明。
- 文件元数据:介绍文件的相关详细信息。
- 评级按钮:允许评定者使用相应的键盘快捷键指定评定结果。
使用人工评分界面
作为一名人工评审员,我通过图书概览进入界面:
1.导航至案件界面并单击判决。
2.点击 "需要更多判决!"。
系统会显示一个尚未评级的查询/文件对,该查询/文件对需要额外的判断。这是由图书的选择策略决定的:
- 单一评判者:每个查询/文档对只有一个评判。
- 多个评分者:每个查询/文档对最多可有三个评判。
评估查询/文档对
让我们举几个例子。当您按照本指南进行操作时,很可能会看到不同的电影。不过,评级原则保持不变。
第一个例子是电影 "英雄 "中的查询 "哈里森-福特":
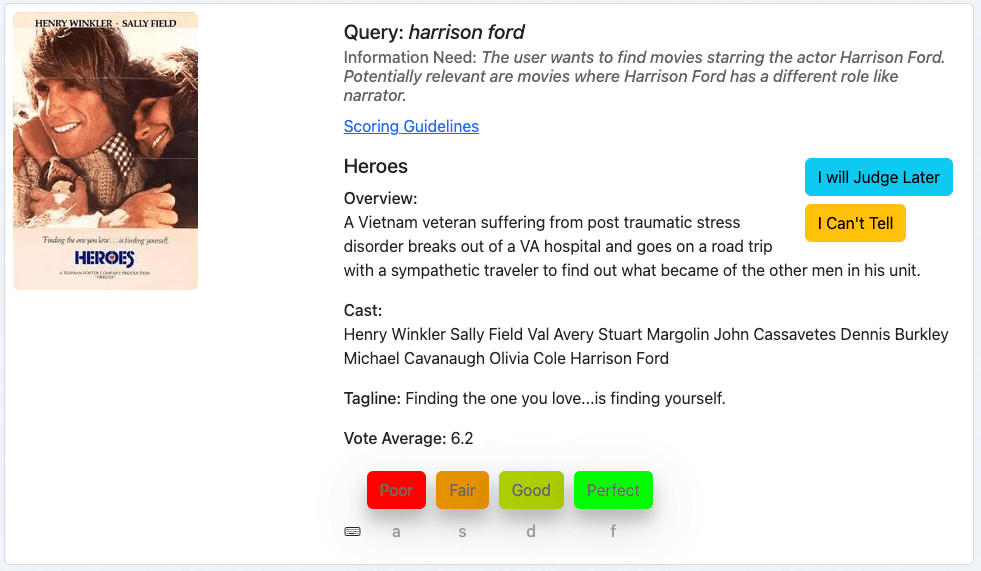
我们首先查看查询,然后是信息需求,最后根据给出的元数据对电影进行判断。
这部电影与我们的查询结果相关,因为演员中有哈里森-福特(Harridson Ford)。我们可能会主观地认为近期的电影更具相关性,但这并不是我们信息需求的一部分。因此,我们给这份文件的评分是 "完美",在我们的评分标准中是 3 分。
下一个例子是电影 "福特诉法拉利",查询条件是哈里森-福特:

按照同样的做法,我们通过查看查询、信息需求以及文档元数据与信息需求的匹配程度来判断该查询/文档。
这是一个糟糕的结果。我们可能会看到这个结果,因为我们的查询词之一 "福特 "在标题中匹配。但哈里森-福特在这部电影中没有扮演任何角色,也没有扮演任何其他角色。因此,我们将这份文件评为 "差",在我们的评分标准中是 0 分。
第三个例子是电影 "动作杰克逊 "的最佳动作片查询:
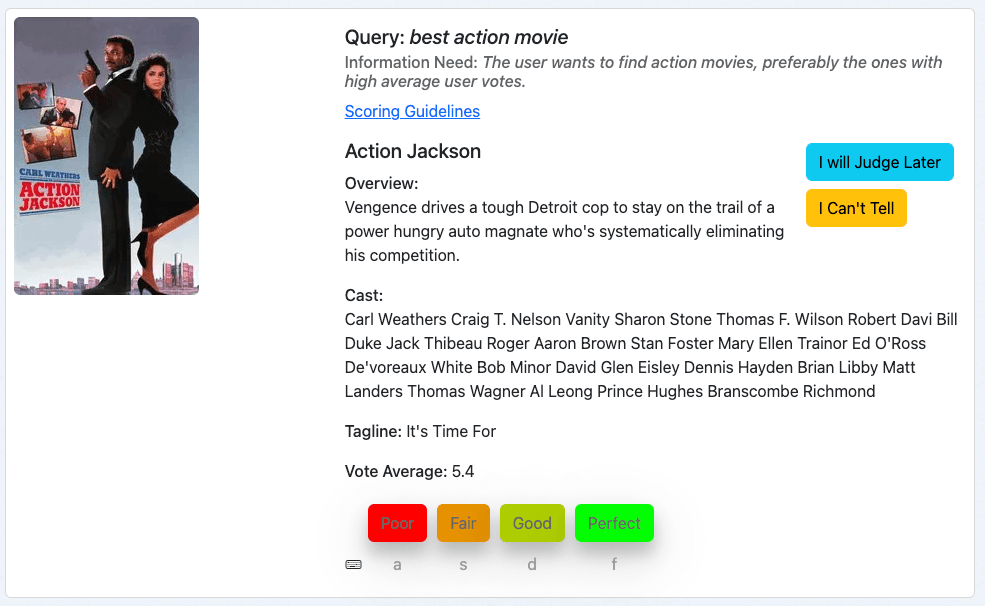
这看起来像是一部动作片,因此至少满足了部分信息需求。不过,投票的平均值为 5.4(满分 10 分)。因此,这部电影可能不是我们收藏的最好的动作片。因此,作为评委,我给这份文件的评分是 "尚可",在我们的评分标准中是 1 分。
这些示例特别说明了使用 Quepid 对查询/文档进行评级的过程,既有高层次的,也有一般的。
人工评分员最佳实践
所展示的示例可能会让人觉得可以直接得出明确的判断。但是,建立一个可靠的人工评级程序并非易事。这是一个充满挑战的过程,很容易影响数据质量:
- 人类评分员可能会因重复性工作而感到疲劳。
- 个人喜好可能会影响判断。
- 不同法官的领域专业知识水平各不相同。
- 评级员往往身兼数职。
- 文档的感知相关性可能与查询的真实相关性不一致。
这些因素可能导致判决不一致、质量不高。不过不用担心,有一些经过验证的最佳实践可以帮助你最大限度地减少这些问题,并建立一个更强大、更可靠的评估流程:
- 一致的评估:依次审查查询、信息需求和文件元数据。
- 参考指南:使用评分指南以保持一致性。评分指南可以举例说明何时采用哪种等级,从而说明评审过程。事实证明,在第一批评判结束后与人工评判员进行核对是一种很好的做法,可以了解具有挑战性的边缘案例以及在哪些方面需要额外的支持。
- 利用选项:如果不确定,可使用"I Will Judge Later" 或"I Can't Tell," ,必要时提供解释。
- 休息:定期休息有助于保持判断质量。每当人工评判员完成一批评判时,Quepid 都会弹出彩纸,帮助用户定期休息。
按照这些步骤,您就可以在 Quepid 中建立一个结构化的协作方法来创建判断列表,从而提高搜索相关性优化工作的效率。
后续步骤
何去何从?判断列表只是提高搜索结果质量的一个基础步骤。下面是接下来的步骤:
计算指标并开始实验
一旦有了判断列表,利用判断和计算搜索质量指标就水到渠成了。当有判决书时,Quepid 会自动计算当前案件的配置指标。指标以 "计分器 "的形式实现,如果支持的指标不包括您最喜欢的指标,您可以提供自己的指标!
进入案例界面,导航至 "选择评分员",选择DCG@10,点击 "选择评分员"确认。现在,Quepid 将计算每次查询的 DCG@10,并计算总体查询的平均值,以量化搜索结果的质量。
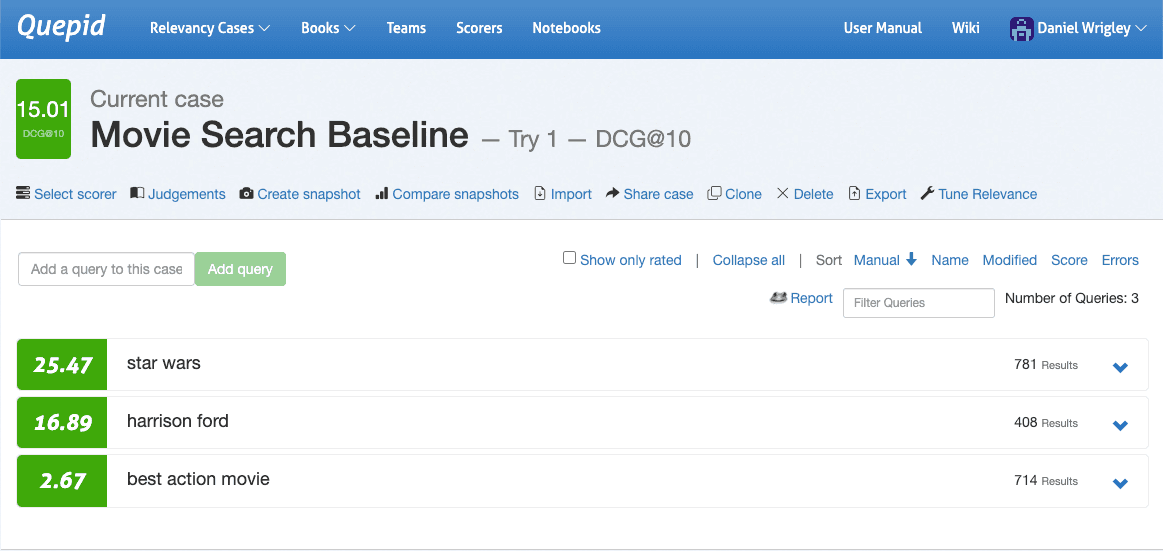
既然已经量化了搜索结果的质量,那么就可以进行第一次实验了。实验从提出假设开始。在对截图中的三个查询进行评级后,可以明显看出这三个查询在搜索质量指标方面的表现截然不同:《星球大战》表现不错,《哈里森-福特》看起来还行,但《最佳动作片》的潜力最大。
扩大查询范围后,我们就能看到查询结果,并能深入研究细节,探索文档匹配的原因以及影响其得分的因素:

点击 "Explain Query(解释查询)"并进入 "Parsing(解析)"选项卡,我们可以看到该查询是一个 DisjunctionMaxxQuery,搜索三个字段:演员、概述和标题:

通常情况下,作为搜索工程师,我们对搜索平台的一些特定领域了如指掌。在这种情况下,我们可能知道我们有一个基因字段。让我们将其添加到查询中,看看搜索质量是否有所提高。
我们使用在案例界面选择 " 调整相关性"时打开的 " 查询沙盒"。请添加您搜索的流派字段,继续探索:
单击重新运行我的搜索!并查看结果。他们变了吗?遗憾的是没有。我们现在有很多选项可以探索,基本上是 Elasticsearch 提供的所有查询选项:
- 我们可以增加基因字段的字段权重。
- 我们可以添加一个功能,根据文件的平均得票率来提升文件。
- 我们可以创建一个更复杂的查询,只在有强基因匹配的情况下,才按投票平均值提升文档。
- …
在 Quepid 中拥有所有这些选项并对其进行探索的最大好处是,我们不仅可以量化我们试图改进的查询的效果,还可以量化我们的所有查询的效果。这就避免了我们通过牺牲其他搜索结果的质量来改善一个表现不佳的查询。我们可以快速、低成本地迭代,并在没有任何风险的情况下验证我们假设的价值,这使得离线实验成为所有搜索团队的基本能力。
评估评分员间信度
即使有任务说明、信息需求和类似 Quepid 提供的人工评定界面,人工评定者也会出现分歧。
意见分歧本身并不是坏事,恰恰相反:衡量意见分歧可以让你发现你可能想要解决的问题。相关性可能是主观的,查询可能是模糊的,数据可能是不完整或不正确的。弗莱斯卡帕(Fleiss' Kappa)是衡量评分者之间一致性的一种统计方法,Quepid 中有一个示例笔记本可供使用。要找到它,请在顶层导航中选择 笔记本 ,然后在 示例 文件夹中选择笔记本 Fleiss Kappa.ipynb 。

结论
Quepid 使您能够应对最复杂的搜索相关性挑战,并将继续发展:从第 8 版开始,Quepid 支持人工智能生成判断,这对希望扩展判断生成流程的团队特别有用。
Quepid工作流程使您能够高效地创建可扩展的判断列表,最终产生真正满足用户需求的搜索结果。有了判断列表,您就有了衡量搜索相关性、迭代改进和改善用户体验的坚实基础。
在前进的过程中,请记住相关性调整是一个持续的过程。判断列表可以让你系统地评估自己的进步,但如果能与实验、指标分析和迭代改进相结合,判断列表的作用会更加强大。
延展阅读
- Quepid docs:
- Quepid Github 存储库
- 认识皮特,关于改进电子商务搜索的系列博客
- 相关性 Slack:加入 #quepid 频道
与 Open Source Connections 合作 ,改造您的搜索和人工智能能力,并使您的团队能够不断发展这些能力。我们的业绩记录遍布全球,客户在搜索质量、团队能力和业务绩效方面不断取得显著提高。现在就联系我们,了解更多信息。
常见问题
Quepid是什么?
Quepid 是一款工具,使用户能够衡量搜索结果质量,并通过离线实验对其进行改进。
您可以在 Quepid 中创建哪些类型的搜索结果质量实验?
您可以在 Quepid 中运行多种实验,包括构建查询集、创建判定列表、计算搜索质量指标,基于计算出的搜索质量指标比较不同搜索算法/排序器,以提高搜索相关性。
如何使用 Quepid 和 Elasticsearch?
查询沙箱允许您快速、低成本地进行迭代。您可以添加字段权重、提升分数或更改查询逻辑,并立即查看其对 Elasticsearch 中数据的搜索质量指标(如 nDCG 或 DCG@10)产生的影响。
相关内容



混合搜索不头疼:用检索器简化混合搜索
探索如何利用线性和 RRF 检索器的多字段查询格式简化 Elasticsearch 中的混合搜索,并在不了解 Elasticsearch 索引的情况下创建查询。


混合搜索重温:在 Elasticsearch 中引入线性检索器!
了解线性检索器如何利用加权分数和 MinMax 归一化来增强混合搜索,从而获得更精确、更一致的排名,并学习如何使用它。