刚接触 Elasticsearch 吗?欢迎参加我们的 Elasticsearch 入门网络研讨会。您也可以开始免费云服务试用,或立即在您的计算机上试用 Elastic。
堆大小是指分配给 Elasticsearch 节点 Java 虚拟机的 RAM 容量。
从 7.11 版开始,Elasticsearch 默认会根据节点的角色和总内存自动设置 JVM 堆大小。建议大多数生产环境使用默认大小。不过,如果要手动设置 JVM 堆大小,一般来说,应将 -Xms 和 -Xmx 设置为相同的值,即总可用内存的 50% ,最大(约)为 31GB。
堆大小越大,节点用于索引和搜索操作的内存就越大。不过,节点也需要内存进行缓存,因此使用 50% 可以在两者之间保持健康的平衡。出于同样的原因,在生产中应避免在 Elasticsearch 的同一节点上使用其他内存密集型进程。
通常情况下,堆使用量会呈现锯齿状,在最大堆使用量的 30 到 70% 之间摇摆。这是因为 JVM 会稳步增加堆使用百分比,直到垃圾回收过程再次释放内存。当垃圾回收进程跟不上时,就会出现堆使用率高的情况。堆使用率高的一个指标是垃圾回收无法将堆使用率降低到 30% 左右。

在上图中,您可以看到 JVM 堆的正常锯齿形。
你还会看到有两种类型的垃圾回收,即年轻的 GC 和年老的 GC。
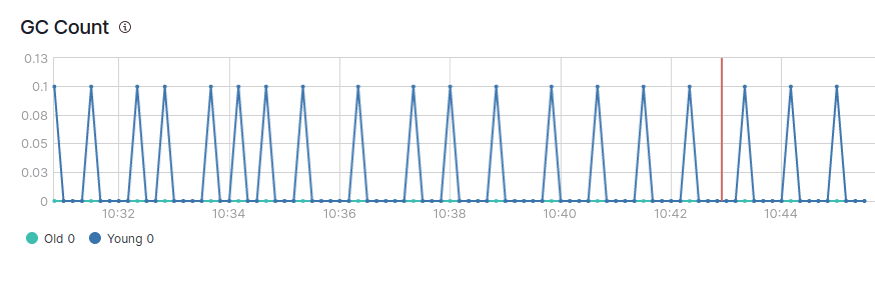
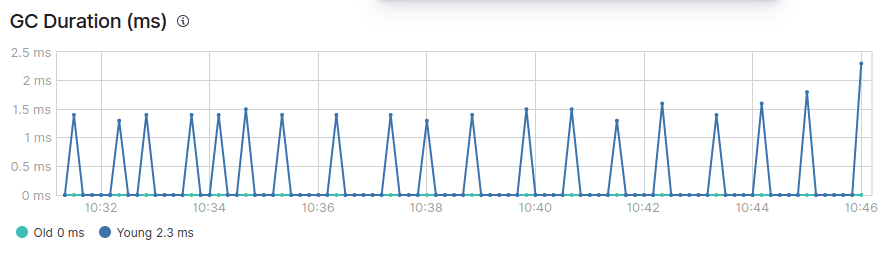
在健康的 JVM 中,垃圾回收最好能满足以下条件:
- 年轻 GC 的处理速度很快(50 毫秒内)。
- 年轻的 GC 执行频率不高(约 10 秒)。
- 旧 GC 处理速度很快(1 秒内)。
- 旧 GC 执行频率不高(每 10 分钟或更长时间执行一次)。
如何解决堆内存使用率过高或 JVM 性能不佳的问题
堆内存使用量增加有多种原因:
过度包庇
请点击此处查看有关过度储藏的文件。
聚合规模大
为了避免聚合大小过大,请尽量减少查询中聚合桶的数量(大小)。
您可以使用慢查询日志(慢日志),并通过以下方式在特定索引上实施。
需要很长时间才能返回结果的查询可能是资源密集型查询。
批量索引大小过大
如果您发送的请求很大,那么这可能是堆消耗大的原因。尝试减少批量索引请求的大小。
制图问题
特别是,如果您使用 "fielddata: true",那么这将成为 JVM 堆的主要用户。
堆大小设置错误
堆大小可以通过以下方式手动定义:
设置环境变量
编辑 Elasticsearch 配置目录中的 jvm.options 文件:
环境变量设置优先于文件设置。
必须重新启动节点才能将设置考虑在内。
JVM 新比率设置错误
通常无需设置,因为 Elasticsearch 默认设置此值。该参数定义 JVM 中 "新一代 "和 "老一代 "对象的可用空间比例。
如果发现旧 GC 变得非常频繁,可以尝试在 Elasticsearch 配置目录下的 jvm.options 文件中专门设置该值。
在大型 Elasticsearch 集群中,管理堆大小使用和 JVM 垃圾收集的最佳实践是什么?
在大型 Elasticsearch 集群中,管理堆大小使用和 JVM 垃圾收集的最佳做法是确保堆大小最多设置为可用 RAM 的 50% ,并根据具体使用情况优化 JVM 垃圾收集设置。必须监控堆大小和垃圾回收指标,以确保群集以最佳状态运行。具体来说,监控 JVM 堆大小、垃圾收集时间和垃圾收集暂停非常重要。此外,监控垃圾回收周期的次数和垃圾回收所花费的时间也很重要。通过监控这些指标,可以发现堆大小或垃圾回收设置方面的任何潜在问题,并在必要时采取纠正措施。
相关内容

2025年11月14日
如何在 Azure AKS 上自动部署 Elasticsearch
了解如何使用 AKS Automatic 和 ECK 在 Azure 上部署带有 Kibana 的 Elasticsearch,以实现部分托管的 Elasticsearch 设置配置。


介绍 Kibana 中的 Elasticsearch 查询规则用户界面
了解如何使用 Elasticsearch 查询规则用户界面,在 Kibana 中使用可定制的规则集从搜索查询中添加或排除文档,而不影响有机排名。

2025年10月3日
如何在 AWS Marketplace 上部署 Elasticsearch
通过这份分步指南,您将了解如何在 AWS Marketplace 上使用 Elastic Cloud Service 来设置和运行 Elasticsearch。
