モデルコンテキストプロトコル(MCP)とは?
MCPが作成された理由とは?標準的な統合レイヤーの必要性
モデルコンテキストプロトコル(MCP)は、エージェンティックAIアプリケーションの構築における基本的な課題、つまり分離した大規模言語モデル(LLM)を外部の世界に接続するために作成されました。デフォルトでは、LLMは強力な推論エンジンですが、その知識は静的で、学習期限に関係しており、ライブデータへのアクセスや外部システムでのアクションの実行を行うネイティブ機能が欠落しています。
外部システムへのLLMの接続には、従来、直接的なカスタムAPI統合が使用されてきました。このアプローチは効果的ですが、各アプリケーション開発者がすべてのツールに特化したAPIを学習し、クエリを処理して結果を解析するコードを記述し、経時的にその接続を保守する必要があります。AIアプリケーションと利用可能なツールの数が増えるにつれて、より標準化された効率的な方法の機会が生まれます。
MCPは、Webサービス用のRESTや開発者ツール用のLanguage Server Protocol (LSP) などの実証された基準からインスピレーションを得て、この標準化されたプロトコルを提供します。すべてのアプリケーション開発者が各ツールのAPIの専門家になることを強制す代わりに、MCPはこの接続レイヤーに共通言語を確立します。
これにより、懸念事項が明確に分離されます。プラットフォームおよびツールのプロバイダーは、本質的にLLMフレンドリーな1つの再利用可能なMCPサーバーを通じてサービスを公開できるようになります。統合の保守責任は、個々のAIアプリケーション開発者から外部システムの所有者に移行できます。これにより、準拠したアプリケーションが任意の準拠したツールに接続できる堅牢で相互運用可能なエコシステムが促進され、開発と保守が大幅に簡素化されます。

MCPの仕組み:コアアーキテクチャ
MCPアーキテクチャ
MCPは、推論エンジン(LLM)を一連の外部機能に接続するように設計されたクライアントサーバーモデルで動作します。アーキテクチャはLLMから始まり、それが外部と相互作用できるようにするコンポーネントを徐々に公開します。
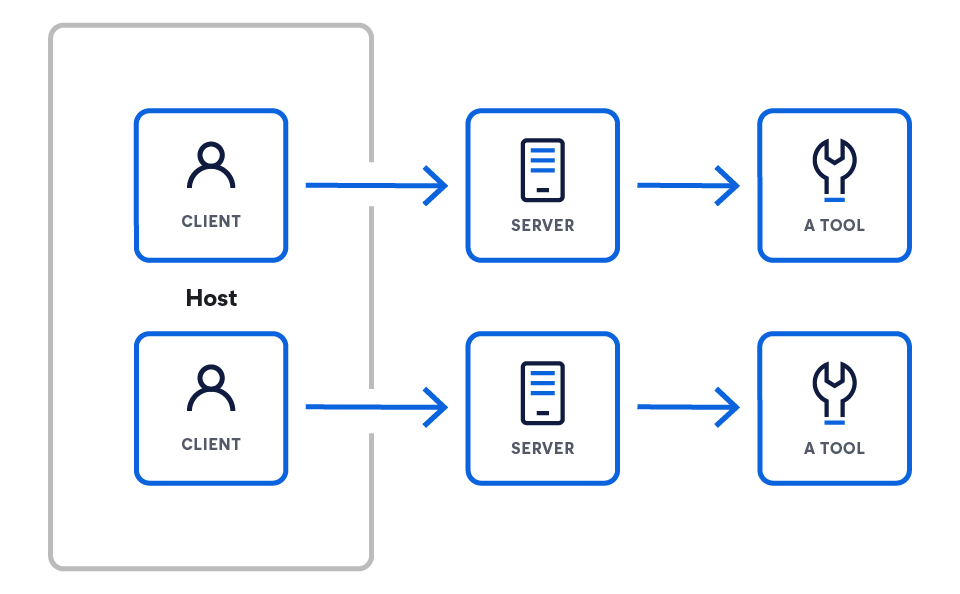
このアーキテクチャは、3つの主要コンポーネントで構成されています。
- ホストは、MCP(例:Claude Desktop、IDE、AIエージェント)を介してデータにアクセスしたいLLMアプリケーションです。
- サーバーは、MCPを通じてそれぞれ特定の機能を公開する軽量プログラムです。
- クライアントはホストアプリケーション内でサーバーとの1対1の接続を維持します。
MCPクライアントまたはホスト

MCPクライアントまたはホストは、LLMと1つ以上のMCPサーバー間のインタラクションを管理するアプリケーションです。クライアントは重要であり、アプリ固有のロジックを含んでいます。サーバーは生の機能を提供しますが、それを使用するのはクライアントの責任です。それを行うために以下の機能を利用します。
- プロンプトアセンブリ:さまざまなサーバーからコンテキストを収集し、LLM向けに最終的かつ効果的なプロンプトを構築
- 状態管理:複数のインタラクションにわたる会話履歴とユーザーコンテキストを保守
- オーケストレーション:LLMがツールを使用することを決定した際に、サーバーがクエリを行う情報と実行するロジックを決定
MCPクライアントは、既知のサーバーエンドポイントへの標準ネットワークリクエスト(通常はHTTPS経由)を介してサーバーに接続します。プロトコルの能力は、それらの間のコミュニケーション契約を標準化することです。プロトコル自体はJSONベースのフォーマットで、言語に依存しません。したがって、どのクライアントも構築された言語にかかわらず、あらゆるサーバーと正しく通信できます。
MCPサーバー
MCPサーバーは、特定のデータソースやツール向けの標準化されたラッパーとして機能するバックエンドプログラムです。MCP仕様を実装し、実行可能なツールやデータリソースなどの機能をネットワーク経由で公開します。本質的には、特定のサービス(データベースクエリやサードパーティのREST APIなど)の固有のプロトコルをMCPの共通言語に変換し、すべてのMCPクライアントが理解できるようにします。
実践:最初のMCPサーバーを作成する方法とは?
ツールを公開するサーバーの例を見てみましょう(ツールの内容については以下をご覧ください)。このサーバーは、クライアントからの2つの主要なリクエストを処理する必要があります。
- SDKをインストールします。
# Python pip install mcp # Node.js npm install @modelcontextprotocol/sdk # Or explore the specification git clone https://github.com/modelcontextprotocol/specification
- 最初のサーバーを作成します。
from mcp.server.fastmcp import FastMCP import asyncio mcp = FastMCP("weather-server") @mcp.tool() async def get_weather(city: str) -> str: """Get weather for a city.""" return f"Weather in {city}: Sunny, 72°F" if __name__ == "__main__": mcp.run() - Claude Desktop に接続してください。
{ "mcpServers": { "weather": { "command": "python", "args": ["/full/path/to/weather_server.py"], "env": {} } } }
公式SDKとリソース
公式のオープンソースSDKを使用して、独自のMCPクライアントとサーバーの構築を開始できます。
MCPツール
ツールとは、MCPサーバーがクライアントに公開する、特定の実行可能な機能です。パッシブデータリソース(ファイルやドキュメントなど)とは異なり、ツールはメールの送信、プロジェクトチケットの作成、ライブデータベースのクエリなど、LLMが呼び出しを決定できるアクションを表します。
ツールは次の方法でサーバーとやりとりします:MCPサーバーが提供するツールを宣言。たとえば、Elasticサーバーは`list_indices`ツールを公開し、その名前、目的、必要なパラメータ(例:`list_indices`、`get_mappings`、`get_shards`、および`search`)を定義します。
クライアントはサーバーに接続し、利用可能なツールを発見します。クライアントは、システムプロンプトまたはコンテキストの一部として、利用可能なツールをLLMに提示します。LLMの出力がツールを使用する意図を示している場合、クライアントはこれを解析し、指定されたパラメータを使用してそのツールを実行するように適切なサーバーに正式なリクエストを行います。
実践:低レベルのMCPサーバーの実装
低レベルの例はプロトコルの仕組みを理解するのに役立ちますが、ほとんどの開発者はオフィシャルSDKを使用してサーバーを構築します。SDKは、メッセージの解析やリクエストのルーティングなどのプロトコルの定型句を処理するため、ツールのコアロジックに集中できます。
次の例では、オフィシャルのMCP Python SDKを使用して、get_current_timeツールを公開する単純なサーバーを作成します。このアプローチは、低レベルの実装よりもはるかに簡潔で宣言的です。
import asyncio
import datetime
from typing import AsyncIterator
from mcp.server import (
MCPServer,
Tool,
tool,
)
# --- ツールの実装 ---
# SDKの@toolデコレータは登録とスキーマ生成を処理します。
# MCPツールとして公開される単純な非同期関数を定義します。
@tool
async def get_current_time() -> AsyncIterator[str]:
"""
現在のUTC時刻と日付をISO 8601文字列として返します。
このdocstringは、LLMのツールの説明として自動的に使用されます。
"""
# SDKは非同期イテレータを想定しているため、結果を生成します。
yield datetime.datetime.now(datetime.timezone.utc).isoformat()
# --- サーバー定義 ---
# MCPServerのインスタンスを作成し、公開するツールを渡します。
# SDKは@toolで装飾された関数を自動的に検出します。
SERVER = MCPServer(
tools=[
# SDKは装飾された関数を自動的に選択します。
Tool.from_callable(get_current_time),
],
)
# --- メイン実行ブロック ---
# SDKは、サーバーを実行するためのメインエントリポイントを提供します。
# これは、基礎となるすべての通信ロジック (stdio、HTTP など) を処理します。
async def main() -> None:
"""シンプルツールサーバーを実行します。"""
await SERVER.run()
if __name__ == "__main__":
asyncio.run(main())
この実践的な例では、SDKを使用してMCPサーバーを構築する能力を示しています。
- @tool デコレータ: このデコレータは、get_current_time関数をMCPツールとして自動的に登録します。関数シグネチャとdocstringを調べて、プロトコルに必要なスキーマと説明を生成するので、手動で書く手間が省けます。
- MCPServerインスタンス:MCPServerクラスはSDKのコアです。公開したいツールのリストを提供するだけで、残りの処理は自動的に行われます。
- SERVER.run(): この単一のコマンドは、サーバーを起動し、stdioやHTTPなどのさまざまなトランスポート方法の処理を含む、すべての低レベルの通信を管理します。
ご覧のとおり、SDKはプロトコルのほぼすべての複雑さを抽象化し、わずか数行のPythonコードで強力なツールを定義できるようになります。
3つのコアプリミティブ
MCPは、サーバーが公開できる3つのコアプリミティブを定義することで、LLMが外部と交信する方法を標準化します。これらのプリミティブは、LLMを外部機能に接続するための完全なシステムを提供します。
- リソース:コンテキストの提供
- 機能:データアクセス
- アナロジー:GETエンドポイント
- リソースは、LLMにコンテキストを提供する主なメカニズムです。これらは、ドキュメント、データベースレコード、検索クエリの結果など、モデルが取得してデータの対応に使用できるデータソースを表します。通常、これらは読み取り専用の操作です。
- ツール:アクションの有効化
- 機能:アクションと計算
- アナロジー:POSTまたはPUTエンドポイント
- ツールは、LLMがアクションを実行し、外部システムに直接影響を与えることを可能にする実行可能な関数です。これにより、エージェントは単純なデータ検索を超えて、メールの送信、プロジェクトチケットの作成、サードパーティのAPIの呼び出しなどを行うことができます。
- プロンプト:対話のガイド
- 機能:インタラクションテンプレート
- アナロジー:ワークフローレシピ
- プロンプトは、LLMがユーザーまたはシステムと対話する際のガイドとなる再利用可能なテンプレートです。これにより、開発者は一般的または複雑な会話フローを標準化し、モデルからより一貫性と信頼性の高い動作を確保できます。
モデルコンテキストプロトコル自体
コアコンセプト
MCPは、LLMアプリケーション(ホスト)が外部データや機能(サーバー)と統合するための標準化された方法を提供します。この仕様はJSON-RPC 2.0メッセージフォーマットに基づいて構築されており、必須および任意のコンポーネントのセットを定義して充実したステートフルなインタラクションを可能にします。
コアプロトコルと機能
本質的に、MCPは通信層を標準化します。すべての実装は、基本プロトコルとライフサイクル管理をサポートする必要があります。
- 基本プロトコル: すべての通信は、標準のJSON-RPCメッセージ(リクエスト、レスポンス、通知)を使用します。
- サーバー機能:サーバーは、以下の特徴を任意に組み合わせてクライアントに提供できます。
- リソース:ユーザーまたはモデルが消費するコンテキストデータ
- プロンプト:テンプレート化されたメッセージとワークフロー
- ツール:LLMが呼び出す実行可能な関数
- クライアント機能:クライアントはこれらの機能をサーバーに提供して、より高度な双方向ワークフローを実現できます。
- サンプリング:サーバーがエージェント動作または再帰的なLLMインタラクションを開始できるようにします。
- 誘発:サーバーがユーザーに追加情報をリクエストできるようにします。
MCP基本プロトコル
MCPは、基本プロトコルとライフサイクル管理という必須の基盤の上に構築されます。クライアントとサーバー間のすべての通信は、3つのメッセージタイプを定義するJSON-RPC 2.0仕様に準拠する必要があります。
- リクエスト:操作を開始するために送信されます。追跡には一意の文字列または整数のidが必要であり、同じセッション内でidを再利用してはいけません。
- レスポンス:リクエストの返信として送信されます。これには元のリクエストのIDが含まれ、成功した操作の場合はresultオブジェクト、失敗した場合はerrorオブジェクトのいずれかが含まれている必要があります。
- 通知:IDなしで送信され、受信者からのレスポンスを必要としない一方向のメッセージです。
クライアント機能:高度ワークフローの有効化
より複雑な双方向通信の場合、クライアントはサーバーに次の機能を提供することもできます。
- サンプリング:サンプリングは、サーバーがクライアントを介してLLMに推論をリクエストするのを可能にします。これは、タスクを完了する前に、ツールがより多くの情報を取得するためにLLMに「質問し返す」必要がある複数ステップのエージェンティックワークフローを可能にする強力なツールです。
- 誘発:誘発は、サーバーがエンドユーザーに詳細情報を求めるための正式なメカニズムです。これは、アクションを続行する前に説明や確認が必要になる可能性のある対話型ツールにとって非常に重要です。
サーバー機能:性能の公開
サーバーは、一連の標準化された機能を通じてクライアントにその性能を公開します。サーバーは以下の任意の組み合わせを実装できます。
- ツール:ツールは、LLMがアクションを実行するための主要なメカニズムです。これらはサーバーが公開する実行可能な関数であり、サードパーティAPIの呼び出し、データベースのクエリ、ファイルの変更など、LLMが外部システムと対話できるようにします。
- リソース:リソースは、LLMが取得できるコンテキストデータのソースを表します。アクションを実行するツールとは異なり、リソースは主に読み取り専用のデータの取得を目的としています。これらは、リアルタイムで外部情報をLLMにグラウンディングするためのメカニズムであり、高度RAGパイプラインの主要な部分を形成します。
- プロンプト:サーバーは、クライアントが使用できる定義済みのプロンプトテンプレートを公開できます。これにより、共通で複雑、または高度に最適化されたプロンプトの共有と標準化が可能になり、一貫したインタラクションが実現します。
セキュリティと信頼
この仕様ではセキュリティを重視しており、実装者が従うべき重要な原則を概説しています。プロトコル自体はこれらのルールを強制できません。責任はアプリケーション開発者にあります。
- ユーザーの同意と管理:ユーザーは、すべてのデータアクセスおよびツールの呼び出しについて、明示的に同意し、管理権を維持する必要があります。認証のためにUIを明確にすることが必須です。
- データプライバシー:ホストは、明示的な同意なしにユーザーデータをサーバーに送信してはならず、適切なアクセス制御を実施しなければなりません。
- ツールの安全性:ツールの呼び出しは任意のコードの実行を意味するため慎重に取り扱う必要があります。ホストは、ツールを呼び出す前に明示的なユーザーの同意を得る必要があります。
MCPがなぜそれほど重要なのでしょうか?
MCPの主な利点は、モデルとツール間の通信とインタラクションレイヤーの標準化にあります。これは開発者にとって予測可能で信頼性の高いエコシステムを創造します。以下は標準化の主な分野です。
- 統一されたコネクタAPI:あらゆる外部サービスを接続するための単一で一貫したインターフェース
- 標準化されたコンテキスト:セッション履歴、埋め込み、ツール出力、長期の記憶など重要な情報を伝達するための汎用メッセージフォーマット
- ツール呼び出しプロトコル:外部ツールを呼び出すための合意されたリクエストとレスポンスパターンにより、予測可能性が確保されます
- データフロー制御:プロンプトの構築を最適化するためのコンテキストのフィルタリング、優先順位付け、ストリーミング、バッチ処理向けの組み込みルール
- セキュリティと認証パターン:APIキーまたはOAuth認証、レート制限、データ交換の安全を確保するための暗号化
- ライフサイクルとルーティングルール:コンテキストを取得するタイミング、キャッシュする期間、システム間でデータをルーティングする方法を定義する規則
- メタデータとオブザーバビリティ:接続されたすべてのモデルとツール全体で一貫したログ、メトリクス、分散トレーシングを可能にする統一されたメタデータフィールド
- 拡張ポイント:前処理と後処理の手順、カスタム検証ルール、プラグイン登録など、カスタムロジックを追加するための定義済みのフック
大規模: 「M×N」または乗法スケーリング統合における問題を解決
急速に拡大するAI環境において、開発者は統合についての重大な課題に直面しています。AIアプリケーション (M) は、データベースや検索エンジンからAPIやコードリポジトリまで、多数の外部データソースやツール (N) にアクセスする必要があります。標準化されたプロトコルがなければ、開発者は「M×N問題」を解決し、アプリケーションとソースのペアごとに独自のカスタム統合を構築および保守する必要があります。
このアプローチは、いくつかの重要な問題につながります。
- 開発者の作業の重複:チームは新しいAIアプリケーションごとに同じ統合問題を繰り返し解決する必要があり、貴重な時間とリソースを無駄にしてしまいます。
- 圧倒的な複雑さ:異なるデータソースが同様の機能を独自の方法で処理するため、複雑で一貫性のない統合レイヤーができます。
- 過剰なメンテナンス:標準化が不十分であるため、カスタム統合による脆弱なエコシステムが生じます。単一のツールのAPIで小さな更新や変更を行うと接続が切断される可能性があり、継続的で反応的なメンテナンスが必要になります。
MCPは、このM×N問題をはるかに単純なM+N方程式に変換します。共通の基準を作成することで、開発者はMクライアント(アプリケーション用)とNサーバー(ツール用)を構築するだけで済み、複雑さとメンテナンス費用を大幅に削減できます。
エージェンティックアプローチの比較
MCPは、Retrieval-Augmented Generation(RAG)のような人気のパターンやLangChainのようなフレームワークの代替ではありません。より強力でモジュラー、管理を簡単にする基礎的な接続プロトコルです。統合の「ラストマイル」を標準化することで、アプリケーションを外部ツールに接続するという普遍的な問題を解決します。
MCPが現代のAIスタックにどのように適合するかを以下に示します。
高度なRAGを強化
標準のRAGは強力ですが、静的なベクトルデータベースに接続することが多いです。より高度なユースケースでは、ライブの複雑なシステムから動的な情報を取得する必要があります。
- MCPを使用しない場合:開発者は、RAGアプリケーションをElasticsearchなどの検索APIの特定のクエリ言語に直接接続するためのカスタムコードを記述する必要があります。
- MCPを使用する場合:検索システムは、標準のMCPサーバーを介してその機能を公開します。RAGアプリケーションは、基盤となるシステムの特定のAPIを知らなくても、シンプルで再利用可能なMCPクライアントを使用してこのライブデータソースをクエリできるようになりました。これにより、RAGの実装がよりクリーンになり、将来的に他のデータソースとの交換が容易になります。
エージェントフレームワーク(例:LangChain、LangGraph)との統合
エージェンティックフレームワークはアプリケーションロジックを構築するための優れたツールを提供しますが、外部ツールに接続する方法がまだ必要です。
- 代替案:
- カスタムコード:ゼロから直接統合を記述することは、多大なエンジニアリング作業と継続的なメンテナンスを必要とします。
- フレームワーク固有のツールキット:事前構築されたコネクタをを使用するか、特定のフレームワーク用のカスタムラッパーを記述します(これにより、そのフレームワークのアーキテクチャに依存するようになり、エコシステムに閉じ込められます)。
- MCPの利点:MCPは、オープンで共通の基準を提供します。ツールプロバイダーは、自社製品用に単一のMCPサーバーを作成できます。現在、LangChain、LangGraph、カスタムビルドのソリューションなど、どのフレームワークでも、汎用MCPクライアントを使用してそのサーバーと交信できます。このアプローチはより効率的であり、ベンダーロックインを防御します。
プロトコルがすべてを簡素化する理由
結局のところ、MCPの価値は2つの極端な統合に対して、オープンで標準化された代替方法を提供することにあります。
- カスタムコードの記述は不安定で、高額のメンテナンスコストが発生します。
- フレームワーク固有のラッパーを使用すると、半閉鎖的なエコシステムが生まれ、ベンダーに依存するようになります。
MCPは統合の所有権を外部システムの所有者に移し、単一の安定したMCPエンドポイントを提供できるようにします。これにより、アプリケーション開発者はこれらのエンドポイントを簡単に使用できるため、強力でコンテキスト認識型のAIアプリケーションの構築、拡張、保守に必要な作業が大幅に簡素化されます。
Elasticsearch MCPサーバーの使用を開始
Elasticsearchは現在、フルマネージド型のマネージドMCPサーバーを提供しています。これにより、スタンドアロンのDockerコンテナやローカルのNode.js環境の必要性が排除され、MCP準拠のホストに対して永続的で安全なゲートウェイが提供されます。
マネージドエンドポイントへのアクセス
バージョン9.3以降およびサーバーレスでは、検索プロジェクトではMCPサーバーがデフォルトで有効化されています。ObservabilityおよびSecurityのユーザーは、AI Assistantの設定によりAgent Builderを有効にすることで、MCPサーバーを公開できます。
実装の詳細やプラットフォーム固有の指示については、 Agent Builderの公式ドキュメントをご参照ください。
MCPクライアントを構成する
有効にしたら、MCPホスト(Claude Desktop、VS Code、Cursorなど)を独自のElasticエンドポイントにポイントするだけです。
Claude Desktopの構成例:
JSON
{
"mcpServers": {
"elastic": {
"command": "npx",
"args": [
"-y",
"@elastic/mcp-server-elasticsearch",
"--hosted-url",
"https://YOUR_KIBANA_URL/api/agent_builder/mcp"
],
"env": {
"ES_API_KEY": "YOUR_ELASTIC_API_KEY"
}
}
}
}
マネージドバージョンを使用すると、Elasticのネイティブセキュリティレイヤーを活用し、コンテキストを認識するエージェントがローカルプロセス管理なしで24時間365日データにアクセスできるようになります。
MCPとAIについてのお問い合わせ
Elasticでの構築をさらに深く掘り下げる
AIとインテリジェント検索アプリケーションに関するあらゆる情報を入手しましょう。Elasticでの構築についての詳細は、リソースをご覧ください。
無料のハンズオンワークショップ「Elasticsearch MCP Serverを使用したMCP入門」で、今すぐ構築を始めましょう。