Searching for needle in haystack
This project was shortlisted for this year’s inaugural Elastic Cause Awards, which recognizes organizations using the Elastic Stack to do great good in the world.
In 2010, we deployed in production the first version of a system that would change the way documents were managed in the State of Goiás Justice Prosecutor's Office, Brazil. It was an Electronic Document Manager named Atena (Athens), the "Goddess of Wisdom", which was responsible for registering all the Citizen Claims as well as the Judicial, Extrajudicial, and Administrative processes, and their procedural steps, engaging them in workflows, among many other functionalities related to the management of documents within a judicial government institution.
Each process has an average of 7 related documents, which totalized, in the end of 2015, an amount of 15,626,816 processes. The global search functionality that was developed was unable to retrieve data in a satisfied manner. It used a PostgreSQL Full Text Search, which enabled phonetic matching, fuzzy search, ranking etc. However, the results weren't effective and also contributing to resource overhead, as the text search indexes (Gin) were much larger than the other PostgreSQL indexes. We defined some denormalized tables to store data redundantly and use them for search purpose. Although it improves performance, it was taking up more than 25% of disk space, in comparison to the other database tables. Besides all these issues, there wasn’t enough available documentation for setting and tuning the PostgreSQL searches.
The users then began to face an annoying situation: the processes (and their documents) simply couldn't be found using it: precision, relevance, and performance issues were far from ideal. Slowly, the functionality became useless and, in the meantime, the complaints increased exponentially!
Getting to work
Something needed to be done. How could we search among all this data in such a way that the users could find exactly (or at least, very close to) the information they wanted? It was like "searching for needle in haystack". That's when Elasticsearch came on the scene!
It was set with 4 nodes, being all master and data, having 32GB RAM, 16 CPUs, 3 SSD disks (30GB for data and 150GB for log), each.
Due to technology issues, we needed to build a fresh new system. It was named Delfos and the first step was to design the index structure: which metadata would be relevant? Which filters should be applied? Which fields should be analyzed?
After a couple of meetings among users and team members, we decided for just one type, the process. The index mapping was defined with 56 fields that included objects (and their inner fields), strings, integers, longs, boolean and dates. We defined a single analyzer containing the filters: lowercase, asciifolding (our vocabulary had a lot of accent marks) and a customized stopword filter to the brazilian language. This analyzer was applied to 23 fields, which would be the searchable ones.
The Search
The search phase design was the most painful. We defined two types of queries: a should term query and a query string. Just one of them is executed according to the user search term:
(1) should term query: defined for the exact processes' number, documents' number and some other numerical fields (a simple regular expression would verify the search term length and its type), which is shown below;
bool:{
should: [
{
term: {
process_number:
{
value: query,
boost: 2.0
}
}
},
{
term: {
reference_number:
{
value: query
}
}
},
{
term: {
'document.number':
{
value: query
}
}
},
{
term: {
'court_hearing.number':
{
value: query
}
}
},
{
term: {
'session_of_jury.number':
{
value: query
}
}
}
],
minimum_should_match: 1
}
(2) a query_string: defined for the full-text search. Boost levels were specified for each searchable field. This feature was extremely important for our use case, as we had 23 searchable fields and some of them were much more used for querying than others, i.e., the name of a person involved in a specific process and the process's subject were much more required than the name of the process's creator department. We also set the following parameters:
- 'analyze_wildcard': true, our users often searched for part of the processes' or documents' numbers, i.e., '*765993';
- default_operator: 'AND', we prioritized the precision rather than the volume.
The query_string clause was almost done, but there was one more thing we needed to deal with: the most recent processes should have more relevance than the older ones. The sort clause couldn't be an option, as it would override the Elasticsearch relevance algorithm. We then inserted our query_string inside a function_score and defined a gauss_function to analyze the process date. The function_score was declared as follows:
function_score:{
query: {
bool: {
must: [
{
query_string: {
query: <em>query</em>,
fields: %w(
process_number^12
involved.name^11
involved.type^11
subjects^10
court_hearing.number^7
documents.number^7
session_of_jury.number^7
reference_number^7
original_department^6
court_hearing.verdict^5
documents.type^5
session_of_jury.verdict^5
category.description^5
process_type^4
current_department_owner.name^4
court_hearing.document.description^3
court_hearing.document.files.content^3
documents.description^3
documents.files.content^3
session_of_jury.document.description^3
session_of_jury.document.files.content^3
department_creator^2
current_owner.name^1
police_inquiry_number^1
notes^1
),
analyze_wildcard: true
default_operator: 'AND'
}
}
]
}
},
functions: [
{
gauss: {
process_date: {
origin: "now",
scale: "30d",
decay: "0.8"
}
},
weight: 20
}
]
}
The gauss function balanced the final results exactly the way we were looking for! The group work query_string, boost levels and gauss function did a great job! Together, they put our global search in the next level!
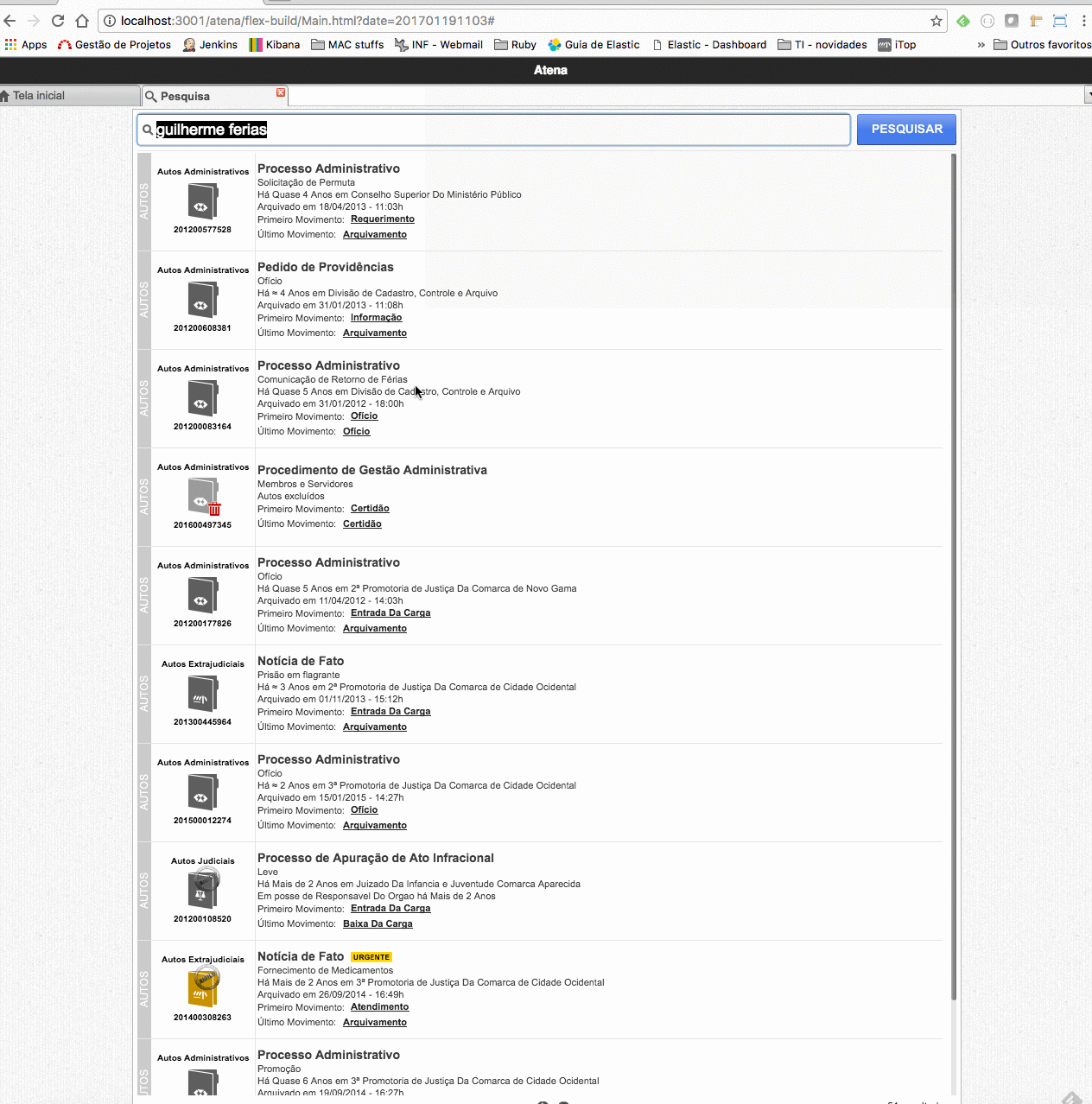
A comparison among the legacy's global search and the new one shows how elasticsearch has improved it. Figure 1 shows the search result for 'guilherme ferias' ('Férias' means 'vacation' in Portuguese). It's expected that the first retrieved processes were related to the subject 'ferias' and also contains the term 'guilherme' in it, maybe as an involved person. It's possible to verify through figure 1 that the two first retrieved processes are not exactly what we needed, as their subjects were not 'ferias': the first one's subject is "Solicitação de permuta", which means "Exchange Request" in English, and the second one's subject is "Ofício", which means "Letter" in English. Besides, the processes were not so recent as expected, as both dated from 2012. Searching for multiple terms on distinct fields were a problem that the previous application didn't deal with very well.
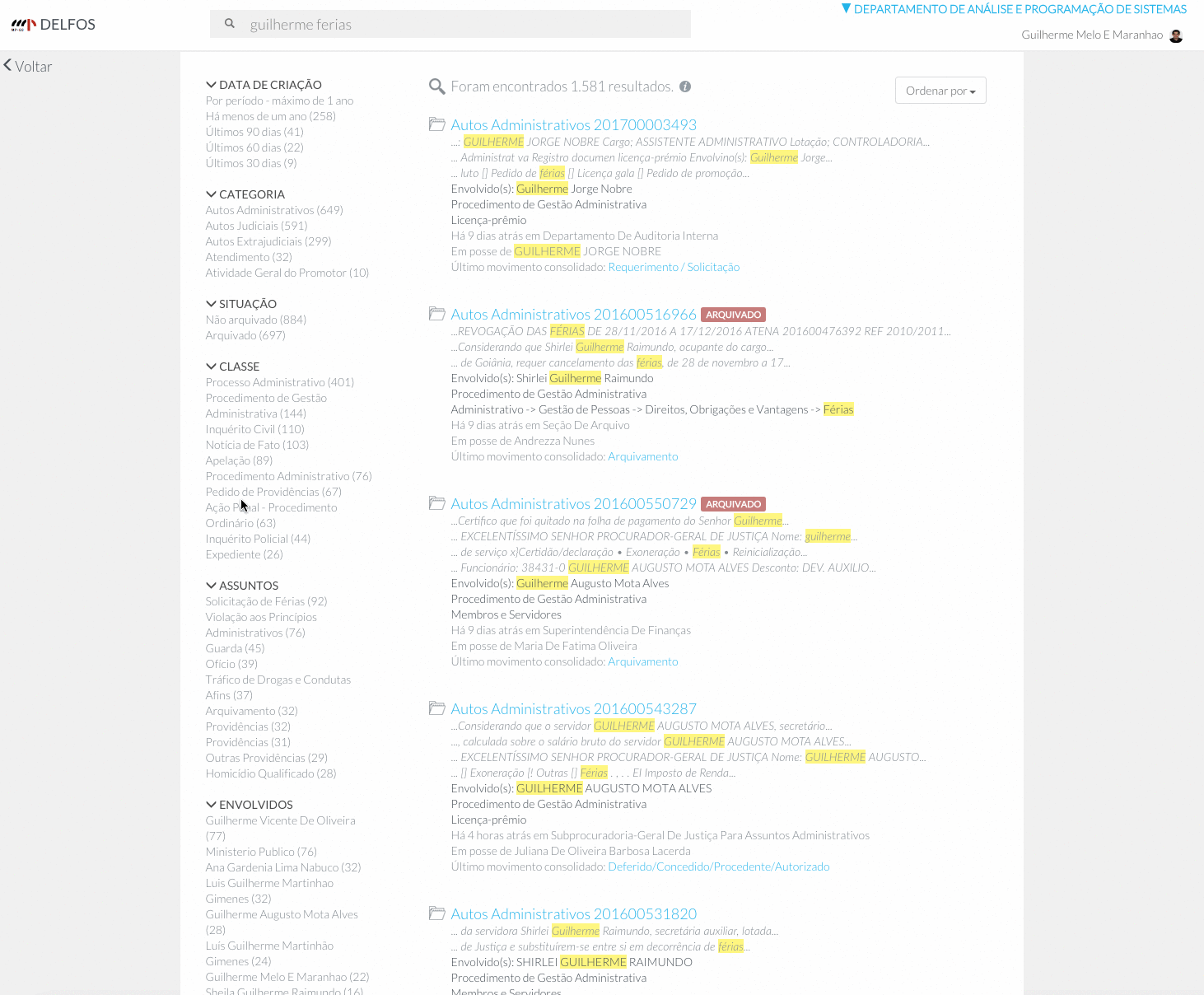
On the other hand, the same search resulted in a much more relevant retrieval in the new application. According to figure 2, it is possible to check that the processes returned on the first positions were very recent and were also related to 'Guilherme' and 'ferias'.
Aggregations
Our index structure was very complex, with lots of lists, objects, strings, dates, and numerical fields. The full-text search would help incredibly, but it wasn't enough. The next step was to ease (even more) the user’s life! There were millions of documents and an aggregation display would be very useful: we then mapped 13 new raw fields in our index! It was almost impossible not to find what you wanted! Now, with just a few clicks, the users could get the single document they were searching for! Figure 2 shows some of these aggregation items.
The aggregation clause nested to our search definition was defined with the following terms: process type, current owner, current department owner, original department, creator department, document type, court hearing verdict, session of jury verdict, subject, involved ones, category, archived and process creation date.
Each selected term aggregation was inserted as a term clause inside the function_score -> query -> must clause array.
The process creation date was implemented to retrieve the following 5 range options, depending on the search result:
- Earlier than a year
- Last 90 days
- Last 60 days
- Last 30 days
- Range date (one year maximum)
When selected, this date field term aggregation is included as a date filter in our search body. Our search body was complemented with highlight, sort and source features. In the moment this post was being written, our index consisted of 2,920,960 documents stored in 65 GB, which resulted in a document average size of 22kb! These numbers show how large in average our documents are. Because of that, we then decided to use highlight to help users finding the terms they are searching for among the thousands of words the retrieved documents possibly have. Figure 2 shows the highlighted terms in yellow.
Although the default sort was based on the score, we also specified two others possibilities: ordering by the last process and ordering by the last process's document.
Technology stack - A brief history
When we decided to upgrade our Electronic Document Manager, besides the search engine solution, the front-end and the back-end layers should also urgently be upgraded. The current Flex layer wouldn't be supported by the most popular browsers within the next years, as well as the Rails version we were using, 2.3.8, didn't support many features we would like to develop.
Concerning the front-end issue, the team chose the AngularJS framework to replace it. It was a very good decision. One of its best contribution was the ui-sref parameter set to the <a> tag. It eases the developer's job while building the aggregation requests. We used the mergeMultipleValuesIntoParam and the pullValueFromParam methods to insert and remove, respectively, the aggregation terms selected and deselected by the user in a transparent way.
As we had to build a fresh new system, we couldn't simply stop the current one. The diagram in figure 3 shows how both applications communicate with each other.
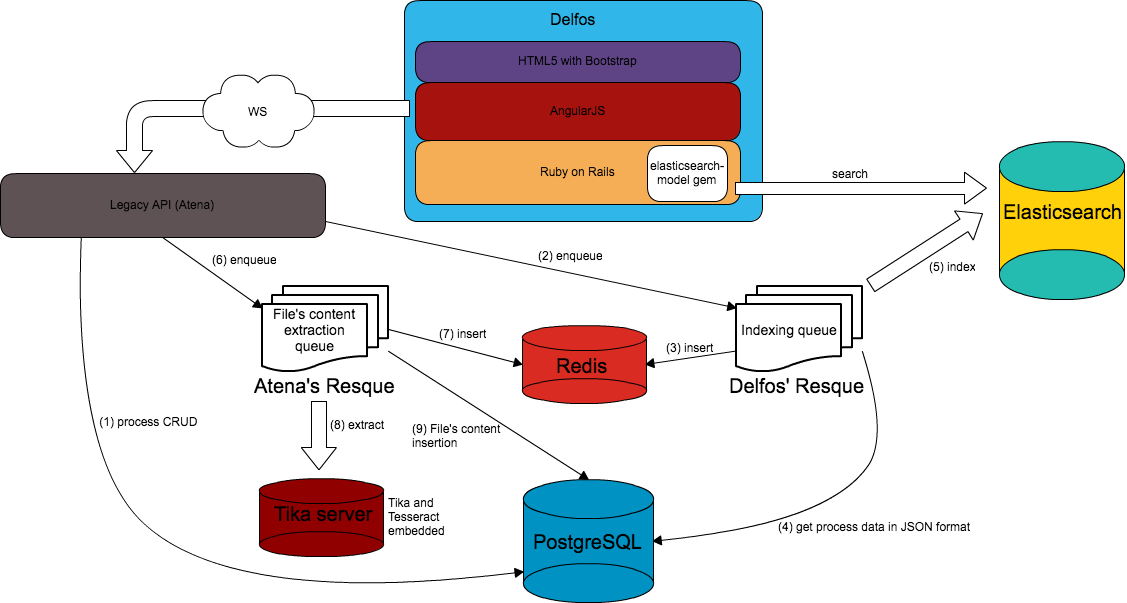
We decided for using the Resque service to call elasticsearch to index the data produced in the legacy system: (1) After any change occurred in a process registered in the legacy system, (2) (3) it immediately enqueued a job in a Redis server. This job is then executed by the Delfos' workers: (4) they call a Postgres function which retrieves the process data in the JSON format and then (5) call the elasticsearch to index it.
If a new file was uploaded to a process in the legacy system (6), a specific job was enqueued (7) so that its content could be extracted by a tika server (8) (9). An ingenious solution grouping both tika lib and tesseract was developed so that if a document had embedded both text and image, the server could extract the content transparently. After the extraction, a resque job was enqueued so that the process could be indexed with the recent uploaded file (2).
What comes next?
There is still a lot of work to do: from simple adjustments to complex features. These are some of them:
- Suggesters: as there are some complicated terms related to the judicial vocabulary, this feature would help users searching for the correct terms;
-
Forcing highlight fields to be returned in the
_sourceclause. This would enable us to highlight the fields, after the document selection, allowing users, for instance, to check which file (one of our fields) contains the highlighted term. Due to data traffic restrictions, we can't simply include the file content in the_sourceclause, as it may be too large. So, it would be interesting to include it only if it occurs a match on it - Context: often, users from different areas or functions have distinct interests in terms of document relevance. For instance, it would be most relevant for users from some specific areas, the prioritization of processes created in by them or by their own department. On the other hand, for users from others areas, the most relevant are the processes which are on their ownership, regardless they were created by them. After defining these areas and their specific interests, a possible solution would be applying, dynamically, specific function score clauses associated to relevant fields which would set the appropriate weight according to the user's context
- Indexing the search terms: We consider creating an index to map: the user’s search terms, the index of the document selected by the user on the page and the highlighted fields related to that selection. The purpose of this index is to help us figuring out which are the most common fields searched by the users so that we can update the boost levels of our query string fields. With respect to the selected document index, we aim to check the relevance of the search result to the users' majority;
- Auto-complete: Everybody enjoys the feeling that the system guesses what we are thinking of!
Conclusion
We are one of the first public institutions in Brazil with a real case of Elasticsearch delivering value in seconds for our customers with a massive volume of data. Today, we have approximately 2.9 million indexed processes having 21 million documents associated, resulting in approximately 65 GB in size. These numbers comprise processes beginning in 2010 and continuing to the present. As the population grows and so the number of processes for each prosecutor, the elasticsearch scalability will enable us to always deliver a great search solution to our users.
As there are some complex business rules to deal with and there is a lot of fields to be queried over, with distinct boosts and weights, it leads us to explore some real nice search capabilities Elasticsearch offers. The aggregations and the highlights features were the frosting on the cake.
Elasticsearch has exceeded our expectations. Arranged with services, third party products and libraries, and mainly, the team, it has enabled us to deliver the search product the institution was looking for. At least in the State of Goiás Justice Prosecutor's Office, searching for a needle in haystack is no longer so painful.

Guilherme Melo e Maranhão is a software engineer at State of Goiás Justice Prosecutor's Office (MP-GO) and responsible for the Delfos project. He has experience in web development, especifically with Ruby on Rails, and since 2016, he has been involved with the Elastic world. For further information on this project, please contact guilhermemaranhao@mpgo.mp.br.