Elastic Cloud Serverlessを構築するためのElasticの道のり
データ、使用状況、パフォーマンスのニーズに関係なく自動でスケールするステートレスアーキテクチャー


 Share on Twitter
Share on TwitterTwitter

 Share on LinkedIn
Share on LinkedInリンクトイン

 Share on Facebook
Share on FacebookFacebook

 Share by Email
Share by Emailメール

 Print this page
Print this page印刷
高いパフォーマンスと状態管理が重要なシステムであるElasticsearchを、どのようにしてサーバーレス化するのでしょうか?
Elasticでは、ストレージからオーケストレーションに至るまで、すべてを再構築し、お客様が安心して使える真のサーバーレスプラットフォームを実現しました。
Elastic Cloud Serverlessは、Elastic Stackの力を運用の負担なしに開発者に提供するために設計された、フルマネージドかつクラウドネイティブなプラットフォームです。本記事では、Elasticがこのプラットフォームを構築した理由、アーキテクチャの設計方針、そしてその過程で得た知見についてご紹介します。
サーバーレスとすべき理由
ここ数年で、顧客の期待は劇的に変化しました。ユーザーは、サイジング、監視、スケーリングなど、インフラ管理の複雑さに関心を持つ必要がなくなり、純粋にワークロードに集中できるシームレスなエクスペリエンスを求めています。この進化する需要に応え、弊社は、運用上のオーバーヘッドを削減し、摩擦のないSaaSエクスペリエンスを提供し、従量課金制の価格設定モデルを導入するソリューションの構築に踏み切りました。お客様が手動でリソースを提供して保守する必要をなくすことで、効率を最適化しながら需要に基づいて動的にスケールできるプラットフォームを構築しました。
マイルストーン
Elastic Cloud Serverlessは、お客様のニーズに応えるべく急速に拡大しており、AWSで2024年12月に、GCPで2025年4月に、そしてAzureで2025年6月に一般提供(GA)を開始しました。その後、4つのリージョン(AWS)、3つのリージョン(GCP)、1つのリージョン(Azure)へと展開を拡大しており、今後もすべてのクラウドサービスプロバイダー(CSP)においてさらなるリージョンの追加を予定しています。
アーキテクチャーの再考:ステートフルからステートレスへ
Elastic Cloud Hosted(ECH)は、もともとローカルのNVMeベースのストレージやマネージドディスクに依存するステートフルなシステムとして構築されており、データの永続性を担保していました。しかしElastic Cloudのグローバル展開が進む中で、運用効率と将来的な成長をより強力に支えるため、アーキテクチャを進化させる好機が訪れました。分散環境における永続的な状態の管理に対する当社のマネージドアプローチは効果的であることが証明されましたが、ノードの置き換えやメンテナンス、可用性ゾーン間の冗長性確保、インデックス作成や検索といった高負荷なワークロードのスケーリングにおいて、運用の複雑性を伴うことが課題となっていました。
弊社は、システムアーキテクチャを進化させるにあたり、ステートレスアプローチを採用することを決断しました。最大の転換点は、永続性記憶装置をコンピュートノードからクラウドネイティブなオブジェクトストレージへと移管したことです。この設計変更により、複数の利点がもたらされました。具体的には、インデックス作成に必要なインフラ負荷の削減、検索とインデックス処理の分離の実現、レプリケーションの不要化、そしてCSPが提供する内蔵の冗長性メカニズムを活用したデータ耐久性の向上です。
オブジェクトストレージへの移行
弊社のアーキテクチャにおける大きな変革のひとつは、クラウドネイティブなオブジェクトストレージを主要なデータストアとして採用したことです。従来のElastic Cloud Hosted(ECH)では、ローカルのNVMe SSDやマネージドSSDディスクにデータを保存する設計となっていました。しかし、データ量の増加に伴い、ストレージを効率的にスケールさせることが課題となっていました。この課題に対応する第一歩として、ECHに検索可能なスナップショットを導入し、オブジェクトストレージ上のデータに直接検索をかけられるようにしました。これによりストレージコストは大幅に削減されましたが、さらなる進化が必要であると認識していました。
主な課題のひとつは、オブジェクトストレージが高負荷なデータインジェスト処理に対応できるか、そしてElasticsearchを利用するユーザーが求めるパフォーマンスレベルを維持できるかを見極めることでした。弊社は厳密なテストと段階的な実装を通じて、オブジェクトストレージが大規模なインデックス作成の要件を満たせることを検証しました。オブジェクトストレージへの移行により、インデックスのレプリケーションが不要となり、インフラ要件が軽減されました。さらに、可用性ゾーン間でのデータ複製によって耐久性が向上し、高い可用性とレジリエンスを実現しています。
以下の図は、新しい「ステートレス」アーキテクチャと、従来の「ECH」アーキテクチャとの比較を示しています。

オブジェクトストアの効率を最適化
オブジェクトストレージへの移行は運用と耐久性の利点をもたらしましたが、オブジェクトストアAPIのコストという新たな課題を生み出しました。Elasticsearchへの書き込み、特にトランザクションログの更新とリフレッシュはオブジェクトストアAPI呼び出しに直接変換されるため、特に高インジェストまたは高リフレッシュのワークロード下では予測不可能な速度でスケールアップする可能性があります。
この問題に対処するために、ノードごとにトランザクションログバッファリングメカニズムを実装し、書き込みをオブジェクトストアにフラッシュする前にまとめて、書き込みの増幅を大幅に削減しました。また、リフレッシュをオブジェクトストアの書き込みから切り離し、代わりにリフレッシュされたセグメントを検索ノードに直接送信し、オブジェクトストアへの永続化を延期しました。このアーキテクチャの改良により、データの耐久性を損なうことなく、リフレッシュ関連のオブジェクトストアAPI呼び出しが2桁減少しました。詳細については、こちらのブログ記事をご参照ください。
オーケストレーションのためのKubernetesの選択
ECHでは、Elastic Cloud Enterprise(ECE)にも採用されている自社開発のコンテナオーケストレーターを使用しています。ECEの開発はKubernetes(K8s)が登場する前に始まったため、サーバーレス対応にあたっては、ECEを拡張するか、K8sを採用するかの選択肢がありました。業界全体でのK8sの急速な普及と、そのエコシステムの成長を踏まえ、Elastic Cloud Serverlessでは、CSP各社のマネージドKubernetesサービスを活用する方針を採用しました。これにより、Elasticの運用効率とスケーリング戦略に合致する柔軟な基盤が実現しています。
Kubernetesを採用することで、運用の複雑さを軽減し、APIを標準化して拡張性を向上させ、Elastic Cloudを長期的なイノベーションに向けて位置付けました。Kubernetesの採用により、弊社はコンテナオーケストレーションを一から構築することなく、より付加価値の高い機能開発に注力できるようになりました。
CSP管理型Kubernetesと自己管理型Kubernetesの比較
Kubernetesへの移行中、弊社はKubernetesクラスターを自社管理するか、CSP提供のマネージドKubernetesサービスを利用するかの決断に直面しました。CSPによってKubernetesの実装は大きく異なりますが、導入のタイムラインを短縮し、運用上のオーバーヘッドを減らすために、AWS、GCP、Azure上のCSPマネージドKubernetesサービスを選択しました。このアプローチにより、Kubernetesクラスター管理の複雑さに対処するのではなく、アプリケーションの構築と業界のベストプラクティスを採用することに集中することができました。
弊社の主な要件には、複数のCSP間で一貫してKubernetesクラスターをプロビジョニングおよび管理する機能、コンピューティング、ストレージ、データベースを管理するためのクラウドに依存しないAPI、そして費用対効果の高い簡素化された運用が含まれていました。さらに、CSPが管理するKubernetesを選択することで、 Crossplaneのようなオープンソースプロジェクトのアップストリームに貢献し、進化する機能の恩恵を受けながらKubernetesエコシステム全体を改善することができました。
ネットワーキングの課題とCiliumの選択
Kubernetesクラスターあたり数万のポッドを使用してKubernetesを大規模に運用するには、クラウドに依存せず、最小限のレイテンシーで高いパフォーマンスを提供し、高度なセキュリティポリシーをサポートするネットワーキングソリューションが必要です。これらの要件を満たすため、最新のeBPFベースのソリューション Cilium を選択しました。当初はすべてのCSPに統一された自己管理型のCiliumソリューションを実装することを目指していましたが、クラウドの実装に違いがあったため、AWSでの自己管理型導入を維持しつつ、利用可能な場合はCSPネイティブのCiliumソリューションを使用するハイブリッドアプローチを採用しました。この柔軟性により、パフォーマンスとセキュリティのニーズを満たすことができ、不必要な複雑さを伴わずに済みました。
イングレストラフィック
イングレスについては、ECHの既存の実戦テスト済みのプロキシを採用して引き続き使用することを選択しました。評価のポイントは、「市販のソリューションに置き換えられるか」ではなく、「置き換えるべきかどうか」という判断でした。
標準的なリバースプロキシでも基本的な機能は提供できますが、ECHのプロキシがすでに対応している差別化された機能は備えていません。インバウンドトラフィックに対応するには、トラフィックフィルターの拡張機能の構築や、AWS PrivateLinkおよびGoogle Cloud Private Service Connectのサポート、さらにFIPS準拠のTLS終端などを実現する必要がありました。既存のプロキシは、すでにすべての関連コンプライアンス監査およびペネトレーションテストをクリアしています。
新たなソリューションから始めるには多大な労力が必要でありながら、お客様にとっての追加価値は得られないという結果になっていたでしょう。プロキシをKubernetesに適応させる際には、サービスエンドポイントの認識をどのように配信するかを更新することが主な対応事項であり、コアとなる信頼性の高い機能はそのまま維持されました。このアプローチには、以下のような複数の利点があります:
ECHとKubernetes間でお客様から見た挙動の一貫性が保たれることを保証します。
市販のソリューションではスクリプトや拡張が必要となるような新機能の実装においても、慣れ親しんだ理解のあるコードベースで作業できるため、チームの生産性が向上します。
ECHとKubernetesの両プラットフォームを単一のコードベースで進化させることができるため、ある環境での改善がもう一方にも波及し、相乗効果を生み出します。
サポートチームは、既存の知識をそのまま活用できるため、新しいプラットフォームへの習熟にかかる時間や負担を大幅に軽減できます。
Kubernetesプロビジョニングレイヤー
Elastic Cloud ServerlessにKubernetesを採用した後、弊社はCrossplaneをインフラ管理ツールとして選定しました。Crossplaneは、Kubernetes APIを拡張するオープンソースプロジェクトで、Kubernetesネイティブのツールと運用方法を使ってクラウドインフラやサービスをプロビジョニング・管理できるようにします。Crossplaneを活用することで、複数のクラウドサービスプロバイダー(CSP)にまたがって、Kubernetesクラスタ内からクラウドリソースを一貫してプロビジョニング・管理・オーケストレーションすることが可能になります。これは、カスタムリソース定義(CRD)を使ってクラウドリソースを定義し、Kubernetesマニフェストで指定された理想状態と実際のクラウドリソースの状態をコントローラーが同期することで実現されています。Kubernetesの宣言的な構成と制御メカニズムを活用することで、コードとしてのインフラをスケーラブルかつ一貫して運用できるようになります。
Crossplaneを活用することで、サービスのデプロイに使用しているのと同じツールや手法を用いて、インフラの管理とプロビジョニングが可能になります。これには、Kubernetesリソースの活用、一貫したGitOpsアーキテクチャの適用、および統一されたオブザーバビリティツールの活用が含まれます。さらに、開発者は、実稼働環境を反映する周辺インフラストラクチャを含む完全な Kubernetes ベースの開発環境を構築できます。両方の環境が同じ基礎コードから生成されるため、Kubernetes リソースを作成するだけでこれを実現できます。
インフラストラクチャーの管理
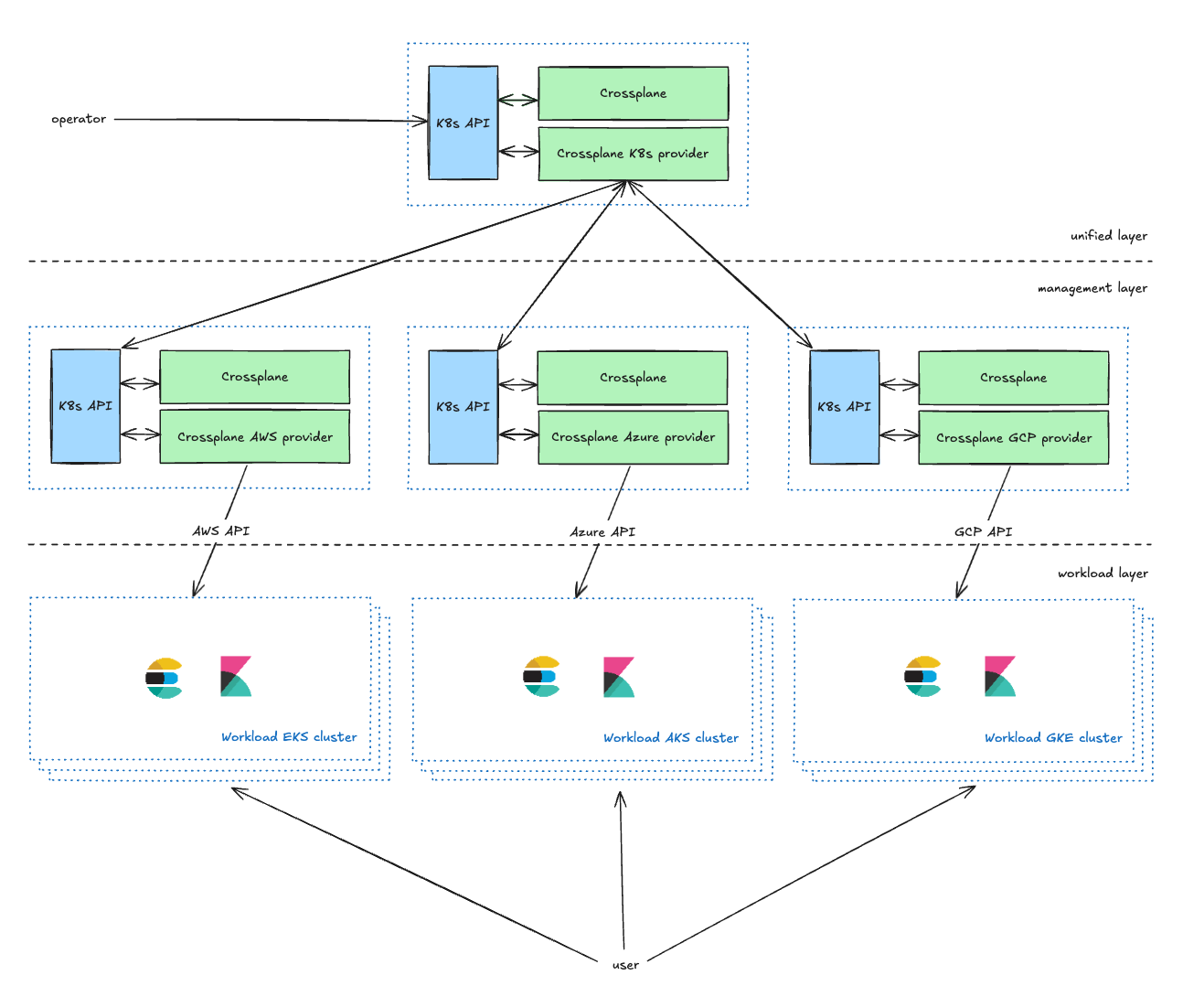
Unifiedレイヤーは、オペレーター向けの管理レイヤーであり、Kubernetes CRD(Custom Resource Definitions)を通じて、サービスオーナーが自らのKubernetesクラスターを管理できるようにします。サービスオーナーは、使用するCSP(クラウドサービスプロバイダー)やリージョン、タイプ(詳細は次のセクションで解説)などのパラメーターを定義可能です。Unifiedレイヤーは、これらのリクエストに情報を付加したうえで、Managementレイヤーへと転送します。
Managementレイヤーは、Unifiedレイヤーとクラウドサービスプロバイダー(CSP)のAPIとの間に立つプロキシとして機能します。Unifiedレイヤーからのリクエストを、各CSPに対応したリソースリクエストに変換し、その実行状況や結果をUnifiedレイヤーに返します。
現在の設定では、各環境内の各CSPに対して2つの管理用Kubernetesクラスターを保守しています。このデュアルクラスターアプローチには、主に2つの目的があります。1つ目は、Crossplaneで発生する可能性のある拡張性に関する懸念に効果的に対処できることです。2つ目は、より重要な点として、クラスターの1つをカナリア環境として使用できることです。このカナリア導入戦略により、各環境の小規模で管理されたサブセットから段階的に変更を展開できるため、リスクを最小限に抑えることができます。
Workloadレイヤーには、ユーザーが利用するアプリケーション(Elasticsearch、Kibana、MISなど)が稼働するすべてのKubernetesワークロードクラスタが含まれています。
クラウド容量の管理:「容量不足」エラーの回避
クラウドには無限のキャパシティがあるというのは一般的な誤解ですが、実際にはCSP(クラウドサービスプロバイダー)にはさまざまな制約があり、「キャパシティ不足」エラーが発生することもあります。特定のインスタンスタイプが利用できない場合、再試行を繰り返すか、別のインスタンスタイプへの切り替えが必要になります。Elastic Cloud Serverlessではこれを回避するために、優先度ベースのキャパシティプールを導入し、必要に応じてワークロードを新しいまたは他のキャパシティプールに移動できるようにしました。さらに、プロアクティブなキャパシティ計画にも注力し、需要の急増に先んじてコンピューティングリソースをあらかじめ確保しています。これらの仕組みにより、リソース利用の最適化を図りつつ、高い可用性を確保しています。
常に最新の状態に維持
Kubernetesクラスターのアップグレードには時間がかかります。これを合理化するために、完全に自動化されたエンドツーエンドのプロセスを利用し、自動的に解決できない問題に対してのみ手動の介入を要求します。内部テストが完了し、新しいKubernetesバージョンが承認されたら、それを一元的に構成します。その後、自動化されたシステムが、制御された同時実行性と特定の順序を使用して、各クラスターのコントロールプレーンのアップグレードを開始します。その後、カスタムKubernetesコントローラーはブルーグリーン導入を実行してノードプールをアップグレードします。このプロセス中に顧客のポッドが異なるKubernetesノードに移行されるにもかかわらず、プロジェクトの可用性とパフォーマンスは影響を受けません。
アーキテクチャーのレジリエンス
弊社はセルベースのアーキテクチャーを使用して拡張性とレジリエンスを兼ね備えたサービスを提供しています。すべてのKubernetesクラスターとその周辺インフラは、CSPの制限に影響されずに適切なスケーリングを可能にし、最大限のセキュリティと分離を提供するために、個別のCSPアカウントにデプロイされています。個々のワークロード(それぞれが個別のセル)は、システムの特定の側面を管理します。これらのセルは独立して動作し、分離されたスケーリングと管理を可能にします。このモジュール設計により、障害の影響範囲が最小限に抑えられ、ターゲットを絞ったスケーリングが容易になり、システム全体への影響を回避できます。問題による潜在的な影響をさらに最小限に抑えるために、アプリケーションと基盤となるインフラの両方にカナリアデプロイメントを採用しています。
コントロールプレーンとデータプレーンの比較:プッシュモデル
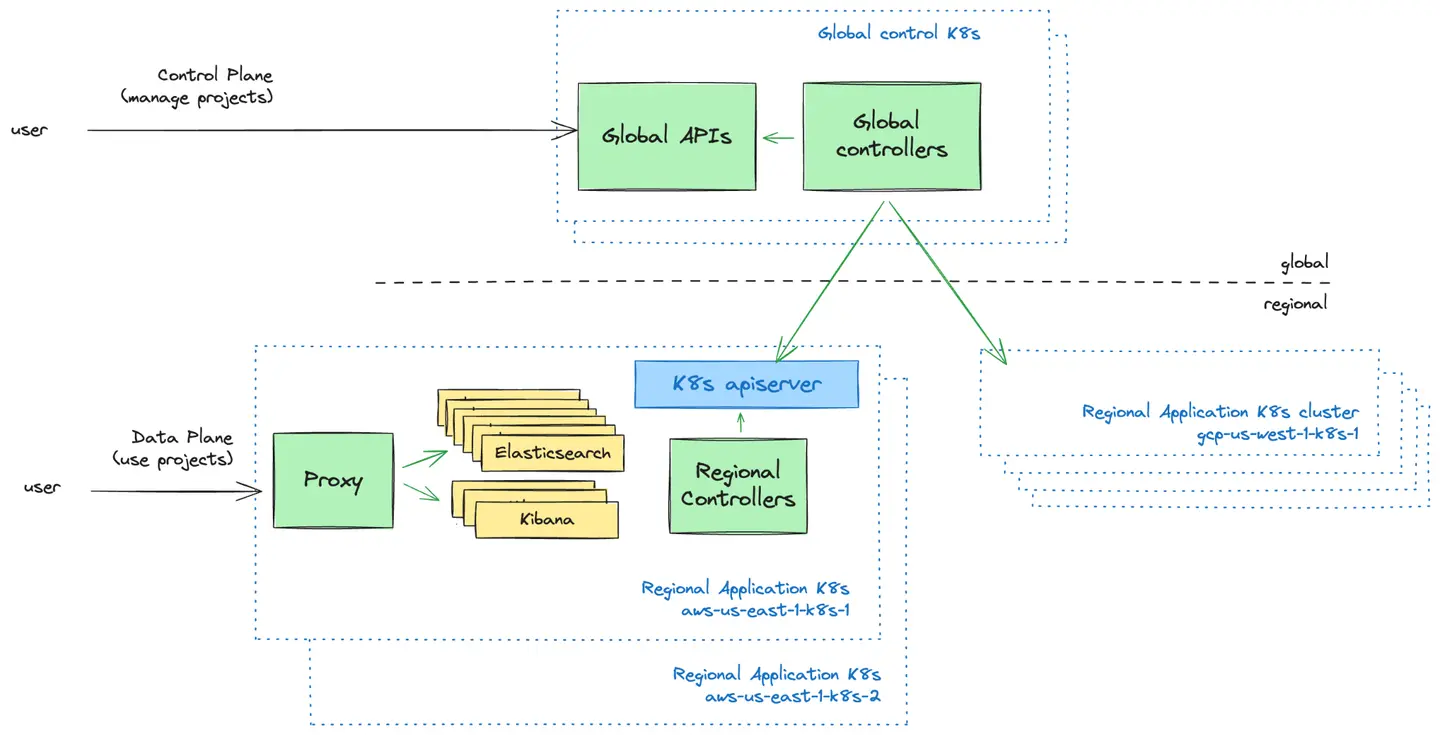
コントロールプレーンはユーザー向けの管理レイヤーです。Elastic Cloud Serverlessプロジェクトを管理するためのUIとAPIを提供しています。ここでユーザーは新しいプロジェクトを作成し、プロジェクトへのアクセス権を持つユーザーを制御し、プロジェクトの概観を確認できます。
データプレーンは、Elastic Cloud Serverless プロジェクトを動かすインフラストラクチャレイヤーであり、ユーザーがプロジェクトを使用するときに操作するものです。
弊社が直面した基本的な設計上の決定は、グローバルコントロールプレーンがデータプレーン内のKubernetesクラスタとどのように通信するかということでした。2つのモデルを検討しました:
プッシュモデル:コントロールプレーンは、構成を地域のKubernetesクラスターに積極的にプッシュします。
プルモデル:リージョナルKubernetesクラスターは、コントロールプレーンから定期的に構成を取得します。
両方のアプローチを評価した結果、プッシュモデルを採用しました。そのシンプルさ、一方向のデータフロー、障害発生時にコントロールプレーンから独立してKubernetesクラスタを運用できるためです。このモデルにより、運用上のオーバーヘッドと障害回復の複雑さを軽減しつつ、シンプルなスケジューリングロジックを保守することができました。
自動スケーリング:水平スケーリングと垂直スケーリングを超えて
真にサーバーレスな体験を提供するためには、ワークロードの需要に応じてリソースを動的に調整するインテリジェントなオートスケーリングメカニズムが必要でした。弊社の取り組みは、基本的な水平スケーリングから始まりましたが、すぐにサービスごとに異なるスケーリングのニーズがあることに気付きました。追加のコンピューティングリソースを必要とするものもあれば、より高いメモリ割り当てを要求するものもあります。
弊社は、カスタムオートスケーリングコントローラーを構築することでアプローチを進化させました。これらのコントローラーは、ワークロード固有のリアルタイムメトリクスを分析し、応答性とリソース効率を両立した動的なスケーリングを可能にします。その結果、Elasticsearchのインデキシングと検索層の両方のオペレーションを、オーバープロビジョニングなしでシームレスにスケールできます。この戦略により、多次元ポッドオートスケーリングが可能となり、CPU、メモリ、そしてワークロードによって生成されるカスタムメトリクスに基づいて、ワークロードを水平方向と垂直方向にスケールできます。
弊社のElasticsearchワークロードでは、クラスターに関する特定の主要なメトリックを返すサーバーレス特有のElasticsearch APIを使用しています。仕組みは次のとおりです:レコメンダーが、特定の階層に必要なコンピュートリソース(レプリカ、メモリ、CPU)とストレージを提案します。これらの推奨事項は、マッパーによってコンテナに適用可能な具体的なコンピュートおよびストレージの構成に変換されます。急激なスケーリングの変動を防ぐために、スタビライザーはこれらの推奨事項をフィルタリングします。次にリミッターが機能し、最小および最大のリソース制約を強制します。リミッターの出力は、いくつかのオプションの制限ポリシーを考慮した後、Kubernetes導入にパッチを適用するために使用されます。
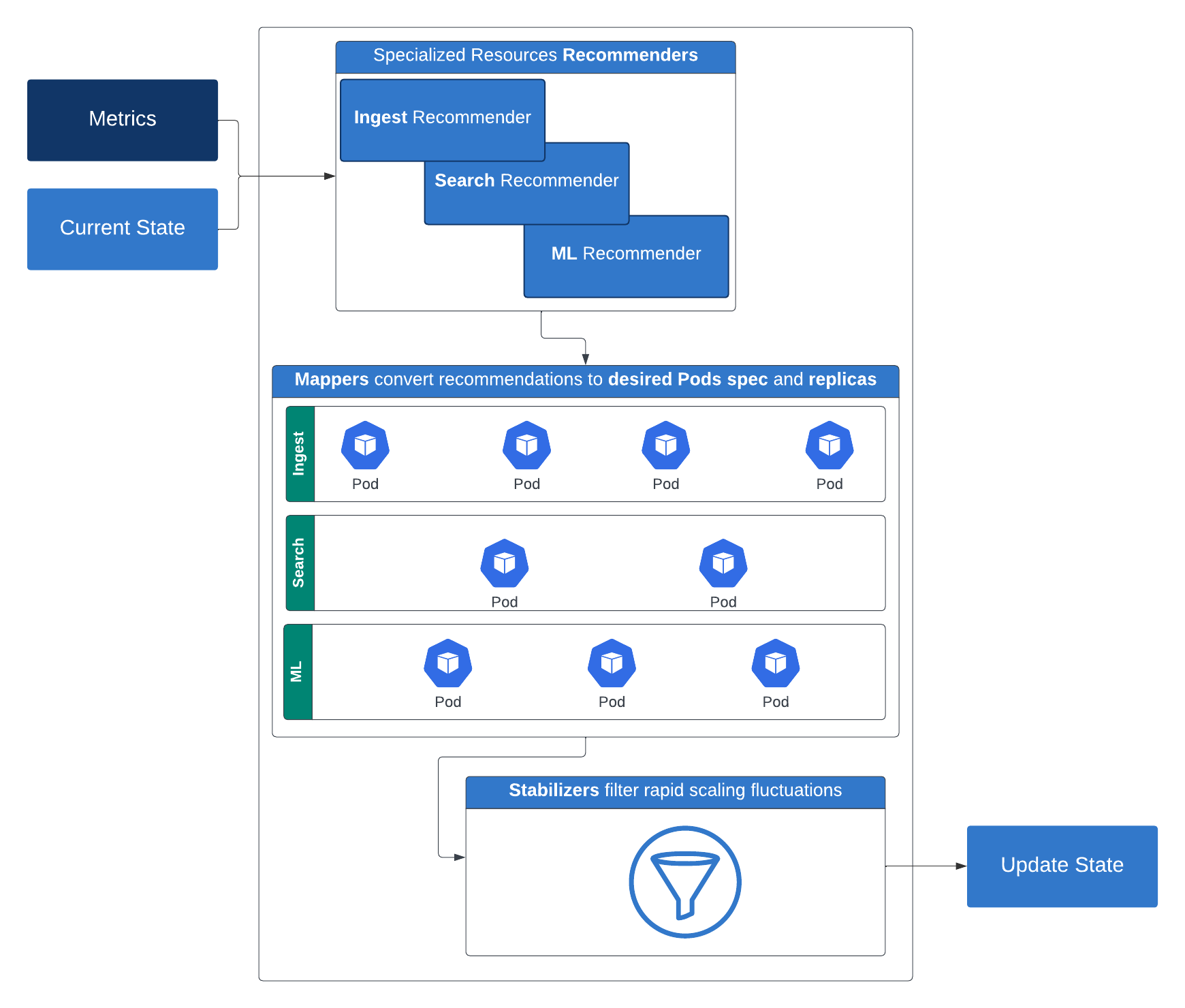
この階層化されたインテリジェントなスケーリング戦略により、多様なワークロードでパフォーマンスと効率が確保され、真のサーバーレスプラットフォームへの大きな一歩が実現します。
Elastic Cloud Serverlessは、ブーストされたデータウィンドウ、検索パワー設定、検索負荷メトリクス(スレッドプールの負荷やキューの負荷など)などの入力を活用して、検索階層に合わせた微妙なオートスケーリング機能を導入しています。これらのシグナルは連携してベースライン構成を定義し、顧客の検索使用パターンに基づいて動的なスケーリングの決定をトリガーします。検索階層の自動スケーリングの詳細については、こちらのブログ記事をご覧ください。インデキシング層の自動スケーリングの仕組みの詳細については、こちらのブログ記事をご覧ください。
柔軟な価格設定モデルの構築
サーバーレスコンピューティングの重要な原則は、コストを実際の使用量に合わせることです。弊社が求めていたのは、シンプルで柔軟性があり、透明性のある価格設定モデルでした。さまざまなアプローチを評価した後、弊社はコアソリューション全体で異なるワークロードのバランスを取るモデルを設計しました。
可観測性とセキュリティ: 取り込まれ保持されるデータに基づいて課金され、階層型料金体系が適用されます
Elasticsearch(検索): インジェスト、検索、機械学習、データ保持を含む仮想コンピュートユニットに基づいた料金体系
このアプローチは、お客様に利用量に応じた課金を提供し、柔軟性とコスト予測性の向上を実現します。
この料金モデルを実装するために(開発段階では何度も改良が加えられました)、スケーラブルで柔軟なアーキテクチャが必要であることは明らかでした。最終的に、エンドツーエンドのプロセスの各コンポーネントを異なるチームが担当する分散型の責任モデルを支えるパイプラインを構築しました。以下では、このパイプラインの2つの主要セグメント、使用量パイプラインによる使用量の収集と、請求パイプラインによる請求計算について説明します。
使用量パイプライン
ElasticsearchやKibanaなどのユーザー向けコンポーネントは、各ワークロードクラスターで実行されるusage-apiサービスに従量制の使用状況データを送信します。このサービスは、データに対して一部のエンリッチメントを実行し、キューに配置します。その後、usage-shipper サービスは、このデータをキューからプルし、オブジェクトストレージに転送します。この分離されたアーキテクチャーは、リージョンやCSP間でデータを出荷するときにパイプラインの回復性を高めるために必要です。これは、レイテンシよりも配信を優先するためです。データがオブジェクトストレージに到達すると、他のプロセスで読み取り専用で、さらなる変換や集計(請求や分析など)に利用できます。
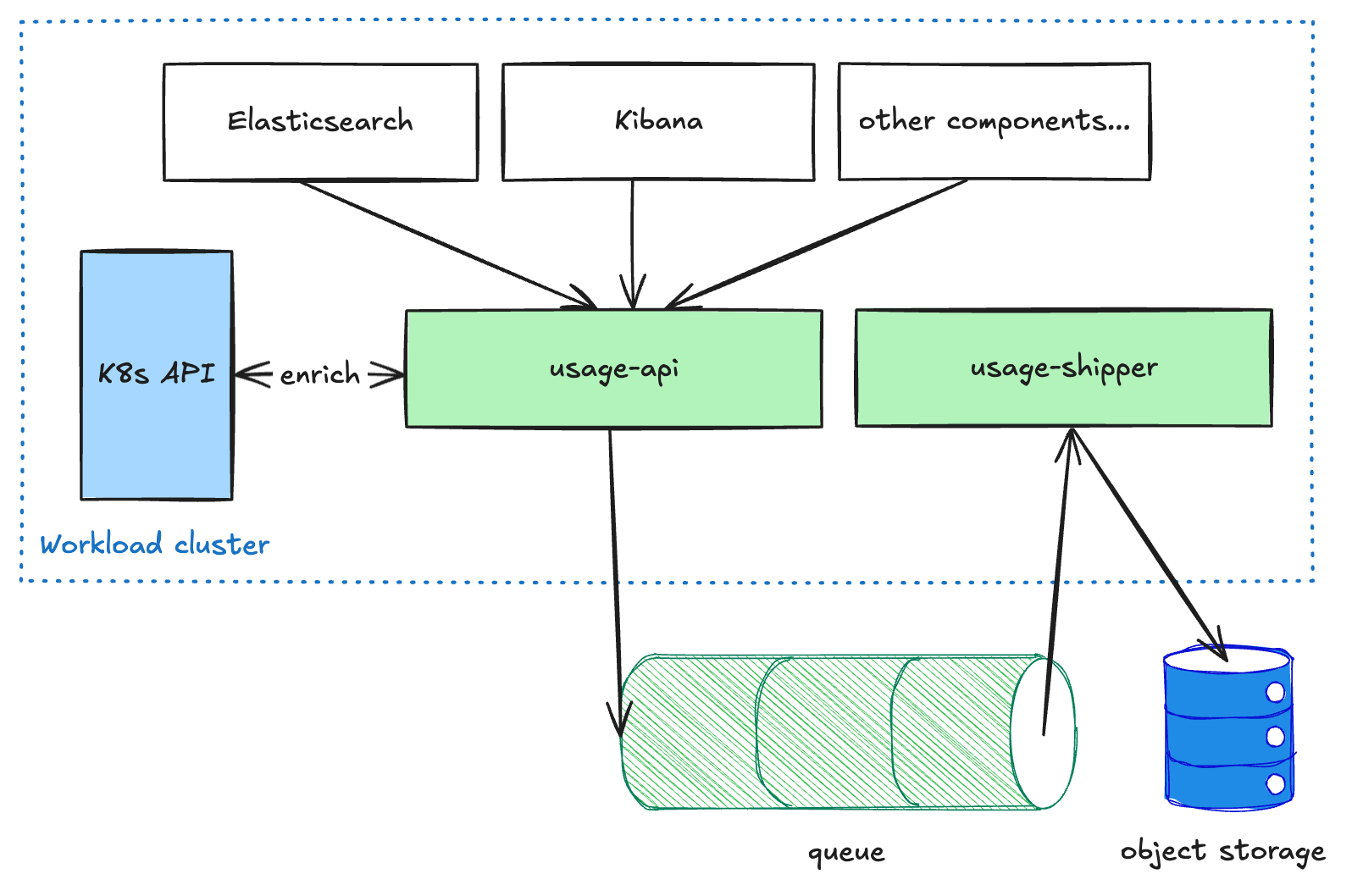
請求パイプライン
利用記録がオブジェクトストレージに保存されると、課金パイプラインがデータを取得し、ECU(Elastic Consumption Units、通貨に依存しない課金単位)の量に変換して請求します。基本的なプロセスは次のようになります:
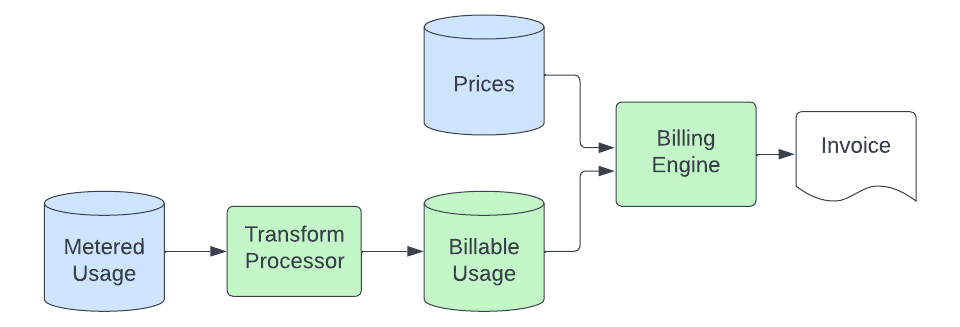
変換プロセスは、オブジェクトストレージから計測された使用記録を取り込み、実際に請求可能な記録に変換します。このプロセスには、単位の変換(メーター処理されたアプリケーションではストレージをバイト単位で測定していても、請求はGB単位で行う場合があります)、請求対象外の使用ソースのフィルタリング、特定の製品へのレコードのマッピング(使用レコード内のメタデータを解析し、使用状況を一意の価格を持つソリューション固有の製品に紐付ける作業)、およびこのデータをElasticsearchクラスターに送信する処理が含まれます。このクラスターは請求エンジンによってクエリされます。この変換ステージの目的は、汎用的なメーター使用量レコードを、価格付け可能な製品固有の数量に変換するロジックを集約して管理するための中央ステージを提供することです。これにより、この特殊なロジックを従量制アプリケーションや請求エンジンから切り離すことができます。これらはシンプルで製品に依存しない状態にしておきたいと考えています。
その後、請求エンジンはこれらの課金対象の使用レコードに対してレーティングを行います。これらのレコードには、価格データベース内の製品にマッピングされる識別子が含まれています。このプロセスでは、最低限、特定期間の使用量を合計し、その数量に製品の単価を掛けてECU(Elastic Compute Units)を算出します。場合によっては、月間の累積使用量に基づいて使用量を階層に分割し、それぞれの階層に設定された個別の価格にマッピングする必要もあります。上流処理の遅延によりレコードが欠落するのを防ぐため、使用レコードは課金対象データストアに到達した時点で請求処理されますが、発生時点の価格に基づいて価格付けされます(遅れて届いた使用量に誤った価格が適用されないようにするため)。この仕組みにより、請求プロセスに「自己修復」機能がもたらされます。
最後に、ECUが算出された後、サポートなどの追加費用を評価し、それを請求計算に反映させます。この結果として請求書が作成され(当社またはクラウドマーケットプレイスのパートナーのいずれかから送付されます)。このプロセスの最終部分はServerlessに特有のものではなく、マネージドプロダクトの請求と同じシステムによって処理されます。
ポイント
複数のクラウドサービスプロバイダー(CSP)にわたって同様の機能を提供するインフラストラクチャプラットフォームを構築することは、非常に複雑な課題です。信頼性、スケーラビリティ、コスト効率のバランスを取るには、継続的な反復とトレードオフが必要です。Kubernetesの実装はクラウドサービスプロバイダーごとに大きく異なり、それらにまたがって一貫した体験を提供するには、広範なテストとカスタマイズが不可欠です。
さらに、サーバーレスアーキテクチャの採用は、単なる技術的変革にとどまらず、組織文化の変革でもあります。問題発生後の対応から、システムの事前最適化への移行を求められ、運用負荷を最小限に抑えるために自動化を優先することが求められます。この取り組みを通じて弊社が学んだのは、サーバーレスプラットフォームの成功は、アーキテクチャ上の決定だけでなく、継続的なイノベーションと改善を受け入れるマインドセットの醸成にも大きく関わっているということです。
今後の展開
サーバーレスの世界で成功するためには、卓越したカスタマーエクスペリエンスの提供、運用の事前最適化、そして信頼性・スケーラビリティ・コスト効率の継続的なバランスが不可欠です。今後も弊社は、Elastic Cloud Serverless上でお客様向けの新機能を開発し、すべてのユーザーにとってElasticsearchを実行する最適な場所としてのサーバーレスを築いていくことに注力していきます。
スピード、スケール、コストを犠牲にすることなく、検索、セキュリティ、オブザーバビリティの未来がここにあります。Elastic Cloud ServerlessとSearch AI Lakeを体験し、データ活用の新たな可能性を解き放ちましょう。詳細はこちらをご覧いただくか、今すぐ無料トライアルを開始してください。
本記事に記述されているあらゆる機能ないし性能のリリースおよびタイミングは、Elasticの単独裁量に委ねられます。現時点で提供されていないあらゆる機能ないし性能は、すみやかに提供されない可能性、または一切の提供が行われない可能性があります。
このブログ記事では、それぞれのオーナーが所有・運用するサードパーティの生成AIツールを使用したり、参照している可能性があります。Elasticはこれらのサードパーティのツールについていかなる権限も持たず、これらのコンテンツ、運用、使用、またはこれらのツールの使用により生じた損失や損害について、一切の責任も義務も負いません。個人情報または秘密/機密情報についてAIツールを使用する場合は、十分に注意してください。提供したあらゆるデータはAIの訓練やその他の目的に使用される可能性があります。提供した情報の安全や機密性が確保される保証はありません。生成AIツールを使用する前に、プライバシー取り扱い方針や利用条件を十分に理解しておく必要があります。
Elastic、Elasticsearch、および関連するマークは、米国およびその他の国におけるElasticsearch N.V.の商標、ロゴ、または登録商標です。その他の会社名および製品名はすべて、それぞれの所有者の商標、ロゴ、または登録商標です。
シェアする
- Share on Twitter
Twitter
- Share on LinkedIn
リンクトイン
- Share on Facebook
Facebook
- Share by Email
メール
- Print this page
印刷