High availability Elasticsearch on Kubernetes with ECK and GKE
Elastic Cloud on Kubernetes (ECK) is an operator that allows you to automate the deployment of the Elastic Stack — including Elasticsearch, Kibana, and Elastic APM, Elastic SIEM, and more — using Kubernetes. By using this ECK, you can quickly and easily deploy Elasticsearch clusters with Kubernetes, as well as secure and upgrade your Elasticsearch clusters. It is the only official Elasticsearch operator.
In this article, you will learn how to:
- Create a Kubernetes cluster using Google Kubernetes Engine (GKE)
- Deploy an Elasticsearch cluster using ECK across three zones
- Scale out the Elasticsearch cluster
- Expose the Elasticsearch cluster externally (using Google Cloud’s load balancer)
Prerequisites
To run the instructions on this page, you must first install the following:
- Google Cloud SDK
- kubectl
Create GKE cluster
Creating a Kubernetes cluster using GKE is very straightforward. Navigate to the Kubernetes Engine page and select Create Cluster. To ensure high-availability and prevent data loss, you want to create a cluster with nodes that go across three availability zones in a region, so select Regional under Location Type. This will create Kubernetes nodes across multiple zones in the region selected.
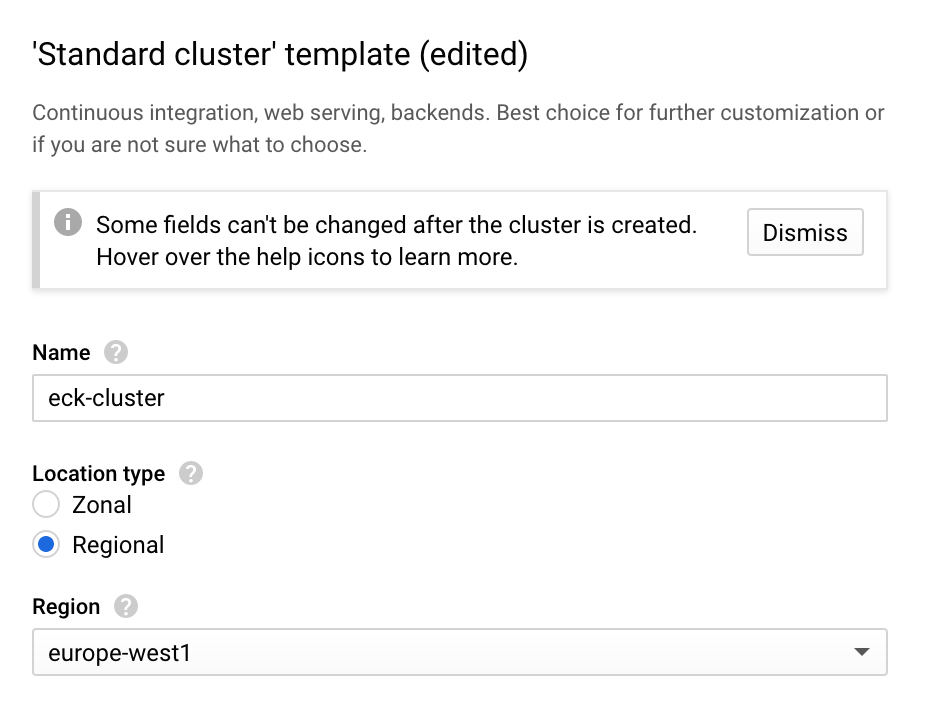
Set up kubectl context
Now that you have set up the Kubernetes cluster, you need a way to communicate with it. kubectl is the command line tool for Kubernetes which is used to run commands against the Kubernetes cluster. To interact with the Kubernetes cluster you’ve set up, you need to configure the context kubectl should use. You can do this easily using the gcloud command:
gcloud container clusters get-credentials [CLUSTER_NAME]
This creates an entry into the kubeconfig file with default credentials, which you can then use to set the context for kubectl. You should see the following:
Fetching cluster endpoint and auth data. kubeconfig entry generated for <cluster-name>.
You can see the entry that’s been added using:
kubectl config view
Now specify the context (cluster name) to use for kubectl with:
kubectl config use-context <cluster name>
The name of the cluster should follow the pattern of gke_<project_name>_<region>_<cluster name>. This will be listed under name in kubeconfig.
Check the context being used by kubectl:
kubectl config current-context
Installing Elastic Cloud on Kubernetes
Now the Kubernetes cluster has been set up in Google Cloud, the next step is to install the ECK operator. Follow these instructions to install ECK.
Create storage class
Since we chose to deploy to multiple zones, we’ll need to ensure that persistent volumes are created in the correct zone (matching the zone the node is deployed in). To do so you will need to create a new storage class using the following configuration:
kind: StorageClass apiVersion: storage.k8s.io/v1 metadata: name: zone-storage provisioner: kubernetes.io/gce-pd volumeBindingMode: WaitForFirstConsumer
Create it by running:
kubectl create -f storage_class.yml
Now switch the default storage class from standard to the one you’ve just created. First switch the default class to false for the standard storage class:
kubectl patch storageclass standard -p '{"metadata": {"annotations":{"storageclass.kubernetes.io/is-default-class":"false"}}}'
Then switch the default class to true for the custom storage class:
kubectl patch storageclass zone-storage -p '{"metadata": {"annotations":{"storageclass.kubernetes.io/is-default-class":"true"}}}'
Deploy Elasticsearch using ECK
You can now deploy your Elasticsearch cluster by following the steps in the ECK documentation using the following configuration file. You will need to change the node.attr.zone value to match the node zones used in your GKE cluster.
apiVersion: elasticsearch.k8s.elastic.co/v1
kind: Elasticsearch
metadata:
name: ha
spec:
version: 7.5.2
nodeSets:
- name: zone-b
count: 1
config:
node.attr.zone: europe-west1-b
cluster.routing.allocation.awareness.attributes: zone
podTemplate:
spec:
initContainers:
- name: sysctl
securityContext:
privileged: true
command: ['sh', '-c', 'sysctl -w vm.max_map_count=262144']
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: failure-domain.beta.kubernetes.io/zone
operator: In
values:
- europe-west1-b
- name: zone-c
count: 1
config:
node.attr.zone: europe-west1-c
cluster.routing.allocation.awareness.attributes: zone
podTemplate:
spec:
initContainers:
- name: sysctl
securityContext:
privileged: true
command: ['sh', '-c', 'sysctl -w vm.max_map_count=262144']
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: failure-domain.beta.kubernetes.io/zone
operator: In
values:
- europe-west1-c
- name: zone-d
count: 1
config:
node.attr.zone: europe-west1-d
cluster.routing.allocation.awareness.attributes: zone
podTemplate:
spec:
initContainers:
- name: sysctl
securityContext:
privileged: true
command: ['sh', '-c', 'sysctl -w vm.max_map_count=262144']
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: failure-domain.beta.kubernetes.io/zone
operator: In
values:
- europe-west1-d
This creates 3 pods in 3 separate zones (in this example: europe-west1-b, europe-west1-c, and europe-west1-d, which are the 3 zones the Kubernetes cluster was created in) with a node set in each zone. To monitor the creation of the Elasticsearch cluster, follow instructions in the ECK monitoring documentation.
Update strategy
Now the cluster has been created, you might decide you need more capacity and need to increase the number of nodes in your cluster. You can do so by updating the deployment configuration and applying the updates.
The updated configuration file has a master-eligible only node and two data nodes in each of the three zones.
apiVersion: elasticsearch.k8s.elastic.co/v1
kind: Elasticsearch
metadata:
name: ha
spec:
version: 7.5.2
nodeSets:
- name: zone-b
count: 1
config:
node.master: true
node.data: false
node.ingest: false
node.attr.zone: europe-west1-b
cluster.routing.allocation.awareness.attributes: zone
podTemplate:
spec:
initContainers:
- name: sysctl
securityContext:
privileged: true
command: ['sh', '-c', 'sysctl -w vm.max_map_count=262144']
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: failure-domain.beta.kubernetes.io/zone
operator: In
values:
- europe-west1-b
- name: zone-b-data
count: 2
config:
node.master: false
node.data: true
node.ingest: false
node.attr.zone: europe-west1-b
cluster.routing.allocation.awareness.attributes: zone
podTemplate:
spec:
initContainers:
- name: sysctl
securityContext:
privileged: true
command: ['sh', '-c', 'sysctl -w vm.max_map_count=262144']
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: failure-domain.beta.kubernetes.io/zone
operator: In
values:
- europe-west1-b
- name: zone-c
count: 1
config:
node.master: true
node.data: false
node.ingest: false
node.attr.zone: europe-west1-c
cluster.routing.allocation.awareness.attributes: zone
podTemplate:
spec:
initContainers:
- name: sysctl
securityContext:
privileged: true
command: ['sh', '-c', 'sysctl -w vm.max_map_count=262144']
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: failure-domain.beta.kubernetes.io/zone
operator: In
values:
- europe-west1-c
- name: zone-c-data
count: 2
config:
node.master: false
node.data: true
node.ingest: false
node.attr.zone: europe-west1-c
cluster.routing.allocation.awareness.attributes: zone
podTemplate:
spec:
initContainers:
- name: sysctl
securityContext:
privileged: true
command: ['sh', '-c', 'sysctl -w vm.max_map_count=262144']
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: failure-domain.beta.kubernetes.io/zone
operator: In
values:
- europe-west1-c
- name: zone-d
count: 1
config:
node.master: true
node.data: false
node.ingest: false
node.attr.zone: europe-west1-d
cluster.routing.allocation.awareness.attributes: zone
podTemplate:
spec:
initContainers:
- name: sysctl
securityContext:
privileged: true
command: ['sh', '-c', 'sysctl -w vm.max_map_count=262144']
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: failure-domain.beta.kubernetes.io/zone
operator: In
values:
- europe-west1-d
- name: zone-d-data
count: 2
config:
node.master: false
node.data: true
node.ingest: false
node.attr.zone: europe-west1-d
cluster.routing.allocation.awareness.attributes: zone
podTemplate:
spec:
initContainers:
- name: sysctl
securityContext:
privileged: true
command: ['sh', '-c', 'sysctl -w vm.max_map_count=262144']
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: failure-domain.beta.kubernetes.io/zone
operator: In
values:
- europe-west1-d
You can now create additional nodes by running:
kubectl apply -f es.yml
To find out more about the update strategy, check out the ECK update documentation.
Exposing the service
Now the cluster has been created, the next question is how to access Elasticsearch outside of Kubernetes. You can first test locally by port forwarding to localhost:
kubectl port-forward service/ha-es-http 9200
The password for the elastic user is stored as a Kubernetes secret and can be retrieved with:
kubectl get secret ha-es-elastic-user -o=jsonpath='{.data.elastic}' | base64 --decode
You can now connect to the Elasticsearch cluster on https://localhost:9200. For more details, check out the accessing ECK documentation.
To expose the service externally, you can specify the service to be of LoadBalancer type by including http.service.spec.type in the deployment configuration:
spec:
version: 7.5.1
http:
service:
spec:
type: LoadBalancer
By changing the type to LoadBalancer, the service is assigned an external IP which can be used to access the Elasticsearch cluster externally.
kubectl get svc NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE ha-es-http LoadBalancer 10.0.44.239 35.241.231.57 9200:31857/TCP 31m
You can also create an Ingress for better control of external access.
Conclusions
You now have a highly available Elasticsearch cluster deployed across 3 zones! If you haven’t run out of energy yet, follow our Getting started with Elastic Cloud on Kubernetes: Data ingestion blog to get some data into your cluster. And if you’re feeling really ambitious, why not try deploying Kibana or Elastic APM using ECK next? If you run into any problems, reach out on our ECK Discuss forum. Enjoy!