Elasticsearch, Kibana und Elastic Cloud 7.16: Integrationen und verwertbare Erkenntnisse


 Share on Twitter
Share on TwitterAuf Twitter teilen

 Share on LinkedIn
Share on LinkedInAuf LinkedIn teilen

 Share on Facebook
Share on FacebookAuf Facebook teilen

 Share by Email
Share by EmailPer E-Mail teilen

 Print this page
Print this pageDrucken
Mit der Elastic-Version 7.16 können Sie Ihre Daten einfacher als je zuvor sicher, in großem Umfang und für beliebige Anwendungsfälle erfassen, speichern, durchsuchen und analysieren. Mit externen Lösungen wie ServiceNow und cloudnativen Integrationen wie Amazon Web Services (AWS) FireLens können Sie Ihre Daten nutzbar machen und Workflows über Teams und Systeme hinweg vereinfachen.
In Version 7.16 haben wir außerdem die Leistung verbessert und die Ressourcennutzung mit verschiedenen Erweiterungen von Elasticsearch optimiert, damit unsere Nutzer mehr Kontext für ihre Kibana-Visualisierungen bereitstellen können, und vieles mehr.
Sind Sie bereit, die Ärmel hochzukrempeln und loszulegen? Besuchen Sie die folgenden Links:
- Neue Features in der Elastic Cloud ausprobieren
- Aktuelle Versionen von Elasticsearch, Kibana, Elastic Cloud on Kubernetes herunterladen
- Lesen Sie die Versionshinweise: Elasticsearch, Kibana, Elastic Cloud, Elastic Cloud on Kubernetes
- Wichtige Änderungen an Elasticsearch
Neue Möglichkeiten, Ihre Daten mit Integrationen zu erfassen und miteinander zu verknüpfen
Mühelos Erkenntnisse aus Daten gewinnen
Mit unserer ständig wachsenden Bibliothek von Integrationen – inklusive nativer Integrationen für Microsoft Azure, Google Cloud und AWS – können Sie mühelos Daten aus verschiedenen Anwendungen, öffentlichen Inhaltsquellen erfassen, miteinander verknüpfen und vieles mehr.
Mit der in 7.16 eingeführten neuen und einheitlichen GUI für Integrationen in Kibana können Sie Daten aus neuen Quellen noch schneller ingestieren, und zwar mit nur wenigen Klicks für Integrationen, die den Elastic Agent unterstützen. Mit der GUI für Integrationen können Sie sämtliche Integrationen durchsuchen, die vom Elastic Agent, Beats, Logstash, dem Elastic App Search-Webcrawler, Workplace Search-Konnektoren für Inhaltsquellen und den Elasticsearch-Sprachclients unterstützt werden.
Entwickler, Fachexperten und Analysten können an einem zentralen Ort die passende Ingestionsmethode für ihre Anforderungen auswählen. Und dank der wachsenden Anzahl von allgemein verfügbaren Integrationen, die den Elastic Agent unterstützen, können die Nutzer mehr Zeit damit verbringen, ihre Daten mit dem Elastic Stack zu erkunden, anstatt benutzerdefinierte Ingestionspipelines zu bändigen und lange YAML-Dateien zu bearbeiten.
ServiceNow-Workflows vereinfachen

Neue ServiceNow-zertifizierte Anwendungen für vorhandene Integrationen in den Bereichen IT Service Management (ITSM) und Security Incident Response (SIR) sowie eine neue Integration für IT Operations Management (ITOM) verbessern die Automatisierung beim Generieren von Anwendungs-, Sicherheits- oder Infrastruktur-Incidents in ServiceNow und reduzieren den erforderlichen Zeit- und Ressourcenaufwand für das manuelle Erstellen von Incidents und das doppelte Dokumentieren von Informationen.
Mit diesen Aktualisierungen können Ihre Teams sicherstellen, dass sie immer mit den aktuellsten Informationen in ServiceNow arbeiten, wenn sie Elastic-Quelldaten verwenden, um Incidents und Fälle zu generieren und zu aktualisieren. Die Teams können Warnregeln in Kibana für Observability- und Sicherheitsanwendungsfälle konfigurieren, um Follow-Ups zu automatisieren, überwachbare Elemente an ServiceNow zu übermitteln und Untersuchungen anzureichern. Demnächst können Sie Ihre Workflows noch weiter vereinfachen, denn diese Integrationen werden durch die andauernde Partnerschaft zwischen Elastic und ServiceNow noch weiter vertieft.
Einfachere Betriebsabläufe mit der neuen nativen Integration für AWS FireLens

Wir freuen uns, mit der nativen Integration für AWS FireLens eine neue Methode zur Vereinfachung der Dateningestion in die Elastic Cloud zu präsentieren. AWS FireLens ist ein Container-Logdaten-Router für die Amazon Elastic Container Service (Amazon ECS)-Starttypen: Amazon Elastic Compute Cloud (Amazon EC2) und AWS Fargate. Sie können jetzt ECS- und Fargate-Logdaten zur weiteren Verbesserung von Observability und Sicherheit Ihrer AWS-Workloads nutzen, ohne dafür spezielle Datenshipper installieren und verwalten zu müssen. Ingestieren Sie Daten noch schneller in die Elastic Cloud mit einer vereinfachten Datenarchitektur und einfacheren Betriebsabläufen.
Bessere Leistung, niedrigere Gesamtkosten
Mit 7.16 haben wir verschiedene Features eingeführt, um Leistung und Resilienz zu verbessern und die Datenträger- und Arbeitsspeichernutzung zu reduzieren, was letztlich auch Ihre Gesamtkosten reduziert.
Skalierung in neue Dimensionen
Ab sofort können Sie den geringeren Heap-Datenverbrauch pro Feld für Datenknoten nutzen. Laut unserer Tests haben 1.000 Beats-Indizes auf Datenknoten vor Version 7.16 etwa 4 GB an Heap-Speicher für die Datenstrukturen belegt. Aktuell werden dafür nur noch wenige Hundert MB benötigt. Die Suchgeschwindigkeit wurde ebenfalls deutlich verbessert. Anstatt Anfragen wie bisher gemäß des Indexmusters an alle Shards zu verteilen, wird jetzt nur noch eine einzige Anfrage pro Knoten gestellt. Dank des geringeren Heap-Speicherverbrauchs und der optimierten Shard-Anfragen können Sie auch weiterhin mit Ihren Daten wachsen und Ihre Elasticsearch-Cluster in neue Dimensionen skalieren.
Leistungsverbesserungen in Elasticsearch
Die in Elasticsearch 7.9 eingeführte Event Query Language (EQL) ist eine Korrelationssprache, die Ereignisse über verschiedene Zeitreihen für ereignisbasierte Zeitreihendaten abgleicht, wie etwa Logs, Metriken und Traces. In 7.16 haben wir die Leistung von EQL verbessert, indem wir keine null-Werte mehr als Join-Schlüssel in Sequenzen verwenden. Mit diesem Schritt konnten wir die Leistung um mehr als den Faktor 830 verbessern!
Die Leistung von search_after über sortierte long-Felder (inklusive Zeitstempel) wurde ebenfalls deutlich verbessert. Wir haben diese wichtige Fähigkeit für Lucene entwickelt und als Beitrag übermittelt und sofort in Elasticsearch 7.16 bereitgestellt. Mit dieser Änderung erhalten Sie eine bis zu vierfache Leistungsverbesserung beim Abrufen von Ergebnissen aus einem Index von computergenerierten Daten, die nach Zeitstempel sortiert sind und keine aggregierten Daten benötigen. Eine ausführlichere Erklärung dieser Änderung finden Sie in unserem Blogeintrag zur Optimierung von Sortieranfragen in Elasticsearch.
Zuletzt bietet die in 7.16 allgemein verfügbare Vektorkacheln-API dramatische Verbesserungen im Hinblick auf Leistung und Skalierbarkeit, wenn nach geo_points und geo_shapes gesucht wird, die (mit Vektorkacheln) auf eine Karte gezeichnet wurden. Dieser neue Standard und API-Typ gibt nicht wie unsere anderen APIs ein JSON-Dokument zurück, sondern eine MapBox-Vektorkachel-Spezifikation, die mühelos von allen Karten dargestellt werden kann, die dieses Format unterstützen.
Die Vorteile sind in der Gegenüberstellung klar ersichtlich. Durch die Auslagerung dieser Berechnungen in die lokale GPU konnten wir die Leistung deutlich verbessern und die Anzeige flüssig und skalierbar zoomen.

Flüssige und skalierbare UX mit Vektorkacheln (links) und ohne Vektorkacheln (rechts). Das Video auf der rechten Seite wird mit doppelter Geschwindigkeit abgespielt und ist trotzdem langsamer als die linke Seite.
Durch den Einsatz von Vektorkacheln erfolgt die Vereinfachung der Geometrien auf dem Datenknoten. Auf diese Weise werden weniger Daten sowohl an die Endnutzer als auch zwischen Datenknoten und Koordinationsknoten innerhalb des Clusters übertragen. Damit werden nicht nur Leistung und Skalierbarkeit verbessert, sondern auch die Gesamtkosten reduziert.
Andere Updates in Elastic Stack und Elastic Cloud
Kibana
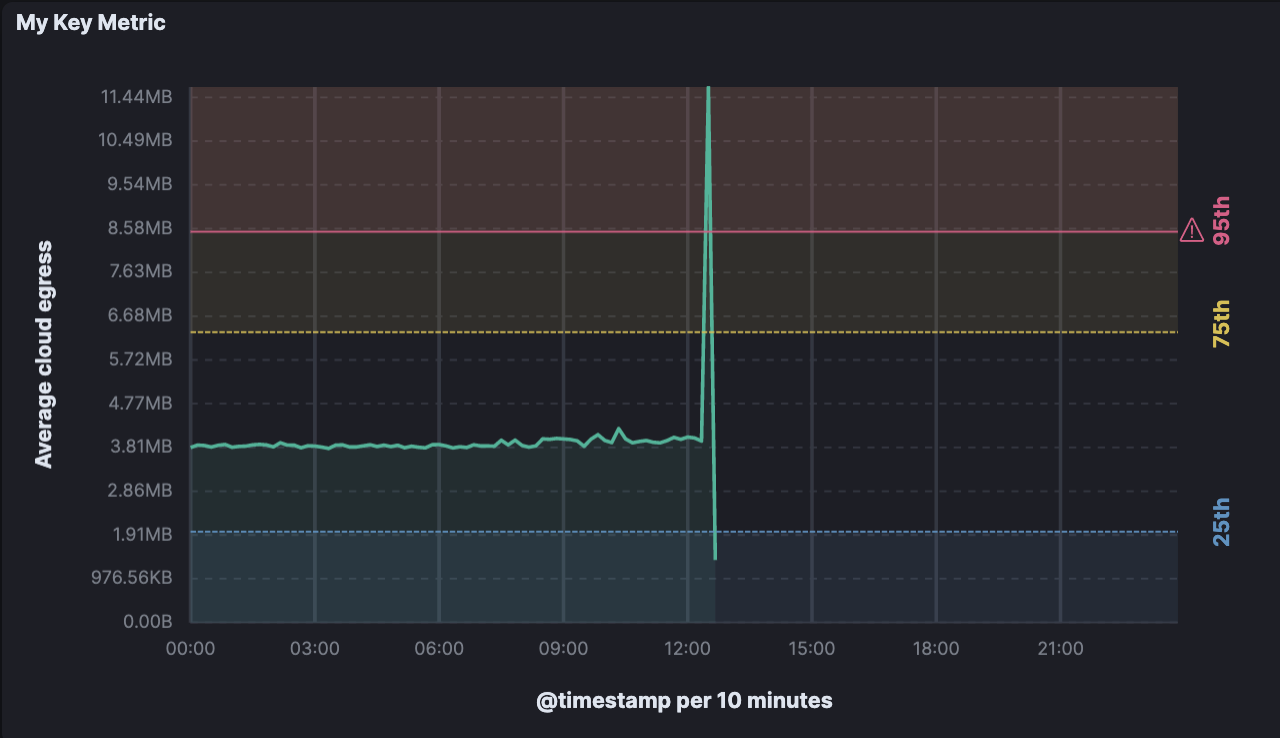
- Zielerfüllung visualisieren: Mit Referenzlinien in Kibana-Visualisierungen können Sie Metriken mit Zielen, Warnbereichen und anderen wichtigen Metrikstandards für Ihre Teams und Ihre Organisation abgleichen. Auf diese Weise können Sie Schwellenwerte, wichtige Ergebnisse und Leistungskriterien in Visualisierungen darstellen, um Ihre Daten noch robuster aufzubereiten.
- Upgrade auf 8.0 und darüber hinaus: Der Upgrade Assistant zeigt Ihnen, welche Schritte Sie ausführen müssen, um einen Cluster aktualisieren zu können, und identifiziert alle veralteten Elasticsearch- oder Kibana-Einstellungen in 7.16-Konfigurationen. Der Assistent führt Sie durch sämtliche Problembehebungsprozesse und liefert zusätzlichen Kontext für zukünftige Entscheidungen. In dieser ElasticON-Sitzung erfahren Sie mehr zu diesem Thema.
- Mühelose Überwachung der Integrität von Transformationen: Mit einem neuen Regeltyp für Kibana-Warnungen können Sie sich jederzeit informieren lassen, wenn Probleme in fortlaufenden Transformationen für Machine Learning-Prozesse auftreten. Sie können beispielsweise überprüfen, ob eine Transformation aufgehört hat, Daten zu indexieren, oder sich in einem Fehlerstatus befindet.
- Weitere Informationen zu den Features in 7.16 finden Sie in der Kibana-Dokumentation.
Elastic Cloud
- Elastic Cloud in AWS ist jetzt in drei neuen Regionen in EMEA verfügbar: Sie können Ihr Elastic Cloud-Deployment in AWS jetzt auch in Bahrain, Kapstadt und Mailand ausführen. Wir unterstützen neuerdings die Regionen Mittlerer Osten (Bahrain), Afrika (Kapstadt) und Südeuropa (Mailand). Sie können Ihre Anwendungen, Daten und Infrastrukturen jetzt in mehr als 45 Regionen und bei drei Cloudanbietern durchsuchen, überwachen und schützen. Informationen zu weiteren unterstützten Regionen finden Sie auf unserer Regionen-Seite.
- Mehrbenutzerzugriff: Wussten Sie, dass Sie mit dem Mehrbenutzerzugriff mehrere Nutzer dazu einladen können, innerhalb einer einzigen Organisation in Elastic Cloud zusammenzuarbeiten? Alle Nutzer, die zur Organisation gehören, können mühelos Elastic Cloud-Deployments für die Organisation erstellen, löschen und betreiben. Auf diese Weise müssen Sie nicht mehr dieselben Anmeldedaten für mehrere Nutzer verwenden. Weitere Informationen finden Sie in unserem Blogpost.
Elasticsearch
- Vorab erstellte ILM-Richtlinien: In 7.16 haben wir fünf vorab erstellte Index-Lifecycle-Management-Richtlinien (ILM) eingeführt, die Sie als Ausgangspunkt verwenden können, bis Sie eine benutzerdefinierte ILM-Richtlinie verwenden.
- Arbeiten Sie gerne mit Logstash Grok? Der Grok-Prozessor unterstützt jetzt das Elastic Common Schema (ECS), und Sie können ECS-Muster im Logstash Grok-Filter verwenden.
- Probieren Sie Textkategorisierungs-Aggregationen aus: Vor 7.16 war die Textkategorisierung nur in der Anomalieerkennung mittels Machine Learning verfügbar. Ab sofort können Sie Textkategorien ohne Anomalieerkennungsjob erkennen und erkunden. Beantworten Sie Fragen wie „Welche Arten von Lognachrichten treten bei hohen Netzwerklatenzen auf?“ oder „Welche Lognachrichten treten typischerweise nach Upgrades auf?“.
- Weitere Informationen zu den Features in 7.16 finden Sie in der Elasticsearch-Dokumentation.
Jetzt ausprobieren
Wenn Sie bereits Elastic Cloud-Kunde sind, können Sie direkt von der Elastic Cloud-Konsole aus auf viele dieser Features zugreifen. Wenn Sie noch nie mit Elastic Cloud gearbeitet haben, empfehlen wir unsere Quick Start-Anleitungen (kurze Schulungsvideos für einen schnellen Einstieg) oder unsere kostenlosen Grundlagenschulungen. Sie können jederzeit mit einer kostenlosen 14-tägigen Testversion von Elastic Cloud einsteigen oder die selbstverwaltete Version des Elastic Stack kostenlos herunterladen.
Lesen Sie mehr über diese und weitere Funktionen in den Versionshinweisen zu 7.16 (Elasticsearch, Kibana, Elastic Cloud, Elastic Cloud on Kubernetes) und über weitere Highlights in Elastic 7.16 im Blogeintrag zur Ankündigung von Elastic 7.16.
Die Entscheidung über die Veröffentlichung der in diesem Blogeintrag beschriebenen Leistungsmerkmale und Features sowie deren Zeitpunkt liegt allein bei Elastic. Es ist möglich, dass noch nicht verfügbare Leistungsmerkmale oder Features nicht rechtzeitig oder überhaupt nicht veröffentlicht werden.
Teilen
- Share on Twitter
Auf Twitter teilen
- Share on LinkedIn
Auf LinkedIn teilen
- Share on Facebook
Auf Facebook teilen
- Share by Email
Per E-Mail teilen
- Print this page
Drucken