Operational Analytics with Elasticsearch at Elastic{ON} 2017 - Part 1
Each year at Elastic{ON}, we use demos to illustrate the capabilities of the Elastic Stack, hoping to both inspire attendees as well as provide discussion points around new features, use cases and common technical challenges. This year we had 4 demo booths, focussed on search, security analytics, operational analytics and Elastic Cloud Enterprise. This blog series focuses on the operational analytics demo, separating the discussion over two blog posts — the first post revolves around the "Architecture and Data Input", while the second focuses on "Visualizations (inc. custom Tile Maps)" and "Final Thoughts".
This is the first post in the blog series, expanding on the architecture and data ingestion pipeline.
Overview
But before we jump in, a little context on this demo.
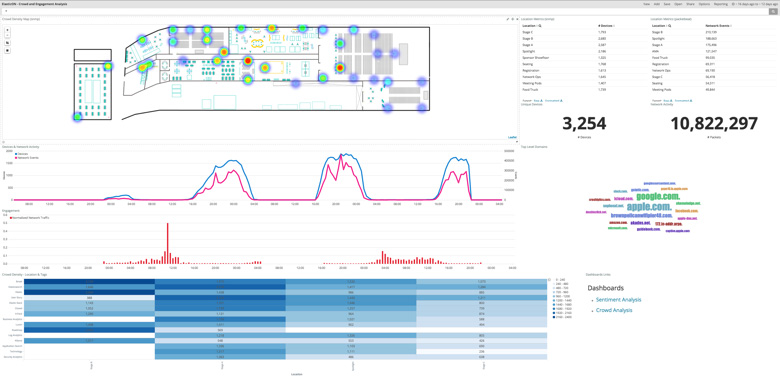
For anyone that has ever tried building an analytics demo, you know that finding a compelling dataset for a demo is a daunting task. And that was the case when we set out to build an Operational Analytics demo for Elastic{ON}. And then we realised, "Hey, we are at Elastic{ON}, an event that will generate plenty of real time operational data that could be used in so many ways to improve the attendee experience." A demo that was connected to the event itself also let us share realtime insights with attendees during the course of the 3 days. Post analysis of the dataset would also allow us to improve the experience for next year by addressing common marketing questions such as — what's the right mix of business and technical talks? Which talks should go in which halls based on anticipated interest?
To achieve this we focused on two data sources
- Wireless network traffic — to get a sense of crowd movement and engagement
- Active session feedback (gathered via sentiment consoles outside each session hall).
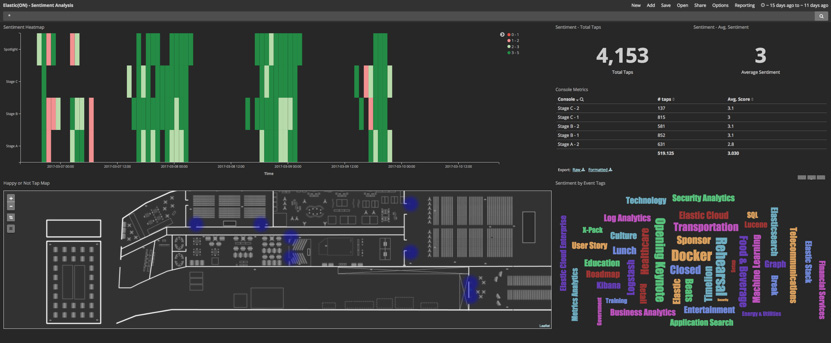
Sentiment data — understanding audience feedback
The latter represented the least technical challenge. We decided to deploy 8 happy or not consoles, placing these at the entrance to each stage for session feedback. Attendees were encouraged to tap these on their way out to let us know how they liked the talk. Ingesting this data into Elasticsearch involved a simple script which periodically polled the vendor-supplied API for changes. We'll return to insights from this sentiment capture in future blog posts, but here's a sneak preview.
Network data — Crowd movement & engagement
Background
Using network analysis we wanted to identify crowd activity hotspots and general movement of attendees, as well as confirming a few hypotheses regards attendee engagement. Capturing this traffic had many more moving parts and was technically more involved that polling data from the sentiment consoles. For the rest of this post, we will therefore focus on the data capture for this aspect of the demo.
With no knowledge of the WiFi infrastructure at Pier 48, we reached out to the vendor for the intended network configuration, after identifying the following requirements:
- Identify main domains accessed and protocols used by the devices connected to the Wifi.
- Identify the number of concurrent unique devices and connections.
- Ability to estimate the location of a connection within the building and associate a geo_point.
- Indicate total bandwidth used, ideally by location using geo aggregations to identify hotspots within the venue.
- Identify locations where network connectivity issues were occurring e.g. dropped packet, errors in transmission.
- Identify the session topics associated with network activity based on an agenda and location.
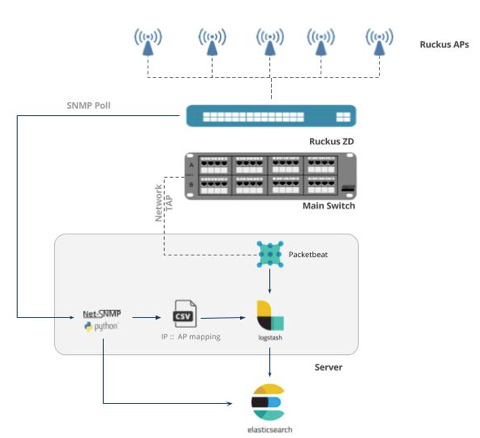
The vendor, Brown Pelican, planned to deploy around 35 Ruckus wireless Access Points (AP), located strategically throughout the venue to provide complete Wifi coverage. These would be coordinated by a Ruckus Zone Director (ZD) 3000, connected to a main Juniper switch responsible for all external routing. Brown Pelican provided us with the mac address and location of the access points ahead of time.
Packet data
Capturing all packet data was relatively straightforward and would allow us to solve requirements 1 and 2. We installed a small server with 2 interfaces next to the Juniper. The first interface, configured in promiscuous mode, was connected to the Juniper management interface and configured to receive a copy of all outbound packet data passing through the switch — effectively a network TAP. Packetbeat, running on this server, was configured to listen on this interface and send all data to an Elastic Cloud instance over the second interface connected to the main network. Sensitive to privacy concerns, we limited traffic collection to DNS requests on port 53 and http traffic on ports 80, 8080, 8000, 5000 and 8002. Using a test network provided by our vendor prior to the event, we established the client IPs of the devices would be preserved but the device and AP mac addresses dropped — the Juniper appeared to mirror at Layer 3. Although the data was extremely rich, it had a couple of deficiencies:
- The packet did not indicate the originating access point, thus preventing us from associating a network event to a location. All AP information would be switched out.
- Client IPs would be fairly transitive as users connected and roamed the building. Establishing a number of unique devices would therefore likely prove quite inaccurate.
Without further work we would therefore be unable to address requirements 3, 4 and 5.
Device connections data
Fortunately, the Rukus ZD provides a fairly comprehensive SNMP interface that not only exposes its own management statistics but also those of the AP's it is responsible for controlling — allowing us to partially address requirements 3 to 5. The device MIB files provide information on the number of connections per AP and the total traffic utilised, in addition to packet drop/error counts. More importantly, however, the ZD maintains device level connection information for each AP! This includes a list of the current device connections associated with each AP, their associated IP, mac address and traffic statistics e.g. bytes transferred. This information would allow us to not only augment the packet data captured at the Juniper, but allow us to determine the approximate location of where it was originating.
With little prior knowledge of SNMP and given the limited requirements, a simple python wrapper of net-snmp as deemed to be sufficient for our purposes. The scripts located here, were developed for the purposes of demonstration and are generic with respect to the Ruckus ZD. Whilst these do not represent a generic or production-ready means of obtaining SNMP data, they hopefully provide a useful starting point for others. In summary these scripts poll the configured ZD every N seconds and generate the following:
- A document summarising the status of each AP, with metrics such as packets_tx and bytes_tx.
- A document summarising the status of each connected device. This document type contains statistics such as the client ip, time_joined and bytes_tx. Whilst the mac address of the connected device is available, we obfuscated this by hashing to mitigate any privacy concerns.
These documents were indexed directly to our Elasticsearch instance (in Elastic Cloud) hosting the Packetbeat data.
Additionally, we also generated a csv file mapping client IP address to the mac address of the connected AP. This file was used to enrich the packet data, captured through the network TAP, with the mac address of the originating AP (we used the translate filter in Logstash for this) — thus allowing us to associate the packet events with a location.
Obviously this approach is imperfect in that the csv file generated by SNMP Poll, may be out of date as devices roamed throughout the venue — potentially data could be tagged with the incorrect AP. To mitigate this issue the poll interval for generating the csv was set to 10 seconds. Given the original objective was to summarise aggregate behaviour, not track individuals, this seemed an acceptable limitation.
Summarising the above, the architecture deployed:
Tagging it all
The above left us with a few final requirements. The first was to associate all SNMP and packet data with a specific geographical location completing requirements 3 to 5. Using this location information and the event timestamp, we additionally wanted to enrich the documents with the agenda for requirement 6 i.e. the topics of the session the user was attending when the data was generated. This would allow us to correlate talk topics with network traffic. Since now we had the AP mac address on each document, both of these requirements could be easily solved with an ingest pipeline.
For simplicity we assumed the conference floor plan covered an arbitrary land area between approximately -7°S, 0°E and -18°S, 38°E — more details next time! AP's were simply mapped from their physical location onto this scale, giving us a simple ingest time lookup map of mac address to lat, lon. For example,
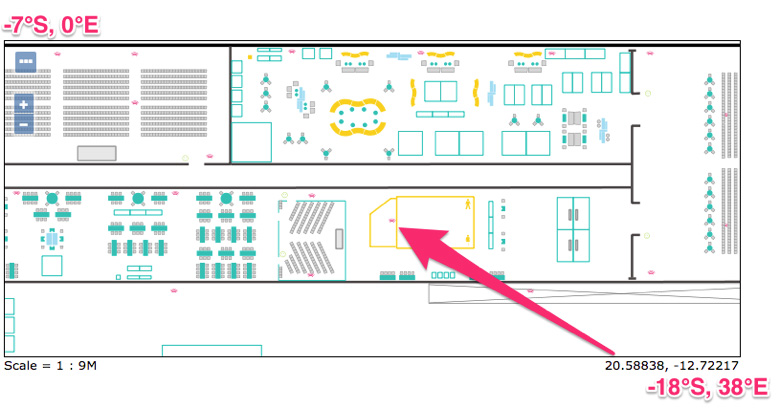
This JSON map was loaded into an ingest pipeline as a parameter, for use by a simple painless script processor which performed the lookup using the value from the field "access_point_mac" to tag each document with a lat and lon. A simplified example, with only one AP, is shown below. As you can see we also added the AP identifier, name and its location ("location_name").
{
"description": "Adds meta data based on Mac Address",
"processors": [
{
"script": {
"lang": "painless",
"inline": "if (params.key_fields != null && params.macs != null) { for (key_field in params.key_fields){ if (params.macs[ctx[key_field]] != null){ctx.meta = params.macs[ctx[key_field]];}}}",
"params": {
"macs": {
"38:ff:36:33:4:30": {
"name": "Stage B - 3",
"num": "20",
"location": {
"lat": "-10.22827",
"lon": "28.24585"
},
"location_name": "Stage B"
}
},
"key_fields": [
"access_point_mac"
]
}
}
}
]
}
Now each document had a named location ("location_name") and @timestamp field we were able to add one final ingest processor to add relevant session topics to the document. This required us to encode the agenda as a JSON map containing the timing (start and end time), location and topics. This map could in turn be passed to a script processor as a parameter during the pipeline creation. Finally, a painless function performed the location and @timestamp lookup for each document at index time, adding several fields:
- tags_all — list of topics occurring through the entire conference at the document time
- tags_on — list of topics occurring at the document location AND time.
A simplified version of this processor, containing only one time period and the topics associated at each location, is shown below.
{
"description": "Adds event tags based on time and location",
"processors": [
{
"script": {
"lang": "painless",
"inline": "if (ctx['@timestamp'] != null && ctx?.meta?.location_name != null) {def f = DateTimeFormatter.ISO_DATE_TIME; def time_slot = params.tags.stream().filter(tag -> ZonedDateTime.parse(tag.start_time, f).isBefore(ZonedDateTime.parse(ctx['@timestamp'], f)) && ZonedDateTime.parse(tag.end_time, f).isAfter(ZonedDateTime.parse(ctx['@timestamp'], f))).findFirst(); if (time_slot.isPresent()) { ctx.meta.tags_all = time_slot.get().All; if (time_slot.get()[ctx.meta.location_name] != null) { ctx.meta.tags_on = time_slot.get()[ctx.meta.location_name]; } } }",
"params": {
"tags": [
{
"start_time": "2017-03-08T18:00:00+00:00",
"All": [
"User Story",
"Beats",
"Non Profit",
"X-Pack",
"Security Analytics",
"Logstash",
"Lucene",
"Elastic Stack",
"Elasticsearch",
"Financial Services",
"Elastic",
"Roadmap",
"Kibana"
],
"Stage A": [
"Elasticsearch",
"Lucene",
"Elastic",
"Roadmap"
],
"Stage B": [
"Logstash",
"Elastic",
"Roadmap"
],
"Spotlight": [
"User Story",
"Elastic Stack",
"Beats",
"X-Pack",
"Kibana",
"Security Analytics",
"Non Profit"
],
"end_time": "2017-03-08T18:25:00+00:00",
"Stage C": [
"Elasticsearch",
"Security Analytics",
"Financial Services",
"User Story"
]
}
]
}
}
}
]
}
Summary
In summary, the above used a combination of Packetbeat, SNMP polling, Logstash and ingest pipelines to continuously index the following data into our ES Cloud instance for the period of the conference:
- A document for each AP every 30 seconds indicating usage and number of connections
- A document for every device connection every 30 secs indicating traffic used, the AP to which it is connected and in turn is location. Enriched with geo information and in turn session topics using a lookup against the agenda based on location and time.
- Packetbeat documents for every device DNS request and HTTP connection, collected through a network TAP to the main switch. Enriched with geo information and in turn session topics using a lookup against the agenda based on location and time.
The next part of this blog series will discuss how we visualised this data in Kibana — including how we achieved the Tile map customisation shown below to overlay activity onto the Elastic{ON} floor map.