Direktes Ingestieren von Daten aus Google BigQuery in Elastic mit Google Dataflow


 Share on Twitter
Share on TwitterAuf Twitter teilen

 Share on LinkedIn
Share on LinkedInAuf LinkedIn teilen

 Share on Facebook
Share on FacebookAuf Facebook teilen

 Share by Email
Share by EmailPer E-Mail teilen

 Print this page
Print this pageDrucken
Wir freuen uns, heute die Einführung der Unterstützung für das direkte Ingestieren von BigQuery-Daten in den Elastic Stack bekannt geben zu können. Datenanalysten und Entwickler können jetzt mit ein paar wenigen Klicks in der Google Cloud Console Daten aus Google BigQuery in den Elastic Stack ingestieren. Dataflow-Vorlagen und native Integrationen erlauben es Nutzern, ihre Daten-Pipeline-Architektur zu vereinfachen und den mit der Installation und Verwaltung von Agents zusammenhängenden operativen Overhead zu eliminieren.
Viele Datenanalysten und Entwickler nutzen zum Speichern ihrer Daten Google BigQuery als Data-Warehouse-Lösung, während sie für die Suche und die Dashboard-Visualisierung auf den Elastic Stack zurückgreifen. Um das Nutzungserlebnis bei beiden Lösungen aufzuwerten, haben Google und Elastic zusammen eine einfachere Möglichkeit entwickelt, Daten aus BigQuery-Tabellen und ‑Ansichten in den Elastic Stack zu ingestieren. Das alles gelingt mit ein paar einfachen Klicks in der Google Cloud Console, ohne dass irgendwelche Datenshipper oder ETL-Tools zum Extrahieren, Transformieren und Laden installiert werden müssen.
In diesem Blogpost beschäftigen wir uns damit, wie Sie ganz ohne Agent Daten aus Google BigQuery in den Elastic Stack ingestieren können.
Vereinfachung von BigQuery- + Elastic-Anwendungsfällen
BigQuery ist eine weit verbreitete serverlose Data-Warehouse-Lösung zur Zentralisierung von Daten aus unterschiedlichen Quellen, wie selbst erstellten Anwendungen, Datenbanken, Marketo, NetSuite, Salesforce, Web-Klickstreams oder eben auch Elasticsearch. Die Lösung bietet die Möglichkeit, Daten aus unterschiedlichen Quellen miteinander zu verknüpfen und dann SQL-Abfragen auszuführen, um die Daten zu analysieren. Die Ausgabe von BigQuery-SQL-Jobs bildet häufig die Grundlage für die Erstellung weiterer Ansichten und Tabellen in BigQuery. Vielerorts werden auch Dashboards mit anderen Stakeholdern und Teams in der Organisation geteilt, wobei Kibana, das native Datenvisualisierungstool von Elastic, zum Einsatz kommt.
Ein weiterer wichtiger Anwendungsfall für BigQuery und den Elastic Stack ist die Volltextsuche. BigQuery-Nutzer können Daten in Elasticsearch ingestieren, sie durchsuchen und die Ergebnisse mithilfe von Elasticsearch-APIs oder Kibana analysieren.
Einfacheres und schnelleres Ingestieren von Daten
Google Dataflow ist ein serverloser, asynchroner Messaging-Dienst auf der Basis von Apache Beam. Dataflow stellt eine Alternative zu Logstash dar, wenn es darum geht, Daten direkt aus der Google Cloud Console zu ingestieren. Google und Elastic haben zusammen an der Entwicklung einer Dataflow-Vorlage gearbeitet, mit der Daten aus BigQuery ohne weiteren Konfigurationsaufwand direkt an den Elastic Stack gesendet werden können. Diese Vorlage ersetzt serverlos Datenverarbeitungsschritte wie die Formatumwandlung, die vorher von Logstash übernommen wurden, ohne dass Nutzer, die zuvor die Elasticsearch-Ingestions-Pipeline genutzt haben, weitere Änderungen vornehmen müssen.
Bisher war es so, dass Nutzer von BigQuery und Elastic Stack einen separaten Datenprozessor wie Logstash oder eine individuelle Lösung auf einer Google Compute Engine-VM (Virtual Machine) installieren und dann für das Senden von Daten von BigQuery an den Elastic Stack diesen Datenprozessor nutzen mussten. Für das Einrichten einer VM und das Installieren eines Datenprozessors ist immer mit einem gewissen Prozess- und Verwaltungs-Overhead verbunden. Jetzt können Sie diesen Schritt auslassen und Daten über ein Dropdown-Menü in Dataflow direkt aus BigQuery in Elastic ingestieren. Eine solche Beseitigung von potenziellen Reibungspunkten ist für viele Nutzer von großem Vorteil, zumal, wenn sich das Ganze mit ein paar Klicks in der Google Cloud Console erledigen lässt.
Die Abbildung unten gibt einen Überblick über den Ablauf beim Ingestieren von Daten. Die Integration funktioniert bei allen Nutzern unabhängig von der verwendeten Umgebung, also gleich ob in Elastic Stack auf Elastic Cloud, in Elastic Cloud im Google Cloud Marketplace oder in selbstverwalteten Umgebungen.
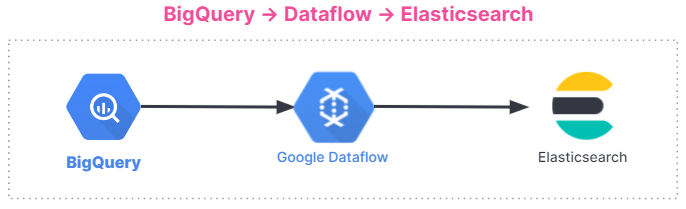
Erste Schritte
Um zu illustrieren, wie einfach es ist, Daten aus BigQuery in Elasticsearch zu ingestieren, werden wir im Folgenden einen öffentlich zugänglichen Satz von Daten aus dem beliebten Frage-und-Antwort-Forum Stack Overflow verwenden. Mit ein paar wenigen Klicks können Sie die Daten über den Dataflow-Batchjob ingestieren und sie dann in Kibana durchsuchen und analysieren.
Wir nutzen hier eine Tabelle namens stackoverflow_posts aus dem BigQuery-Dataset „stackoverflow“. Sie verfügt über mehrere strukturierte Felder, die als Spalten formatiert sind, wie post body, title, comment_count usw., die wir in Elasticsearch importieren, um eine freie Textsuche und Aggregation durchführen zu können.
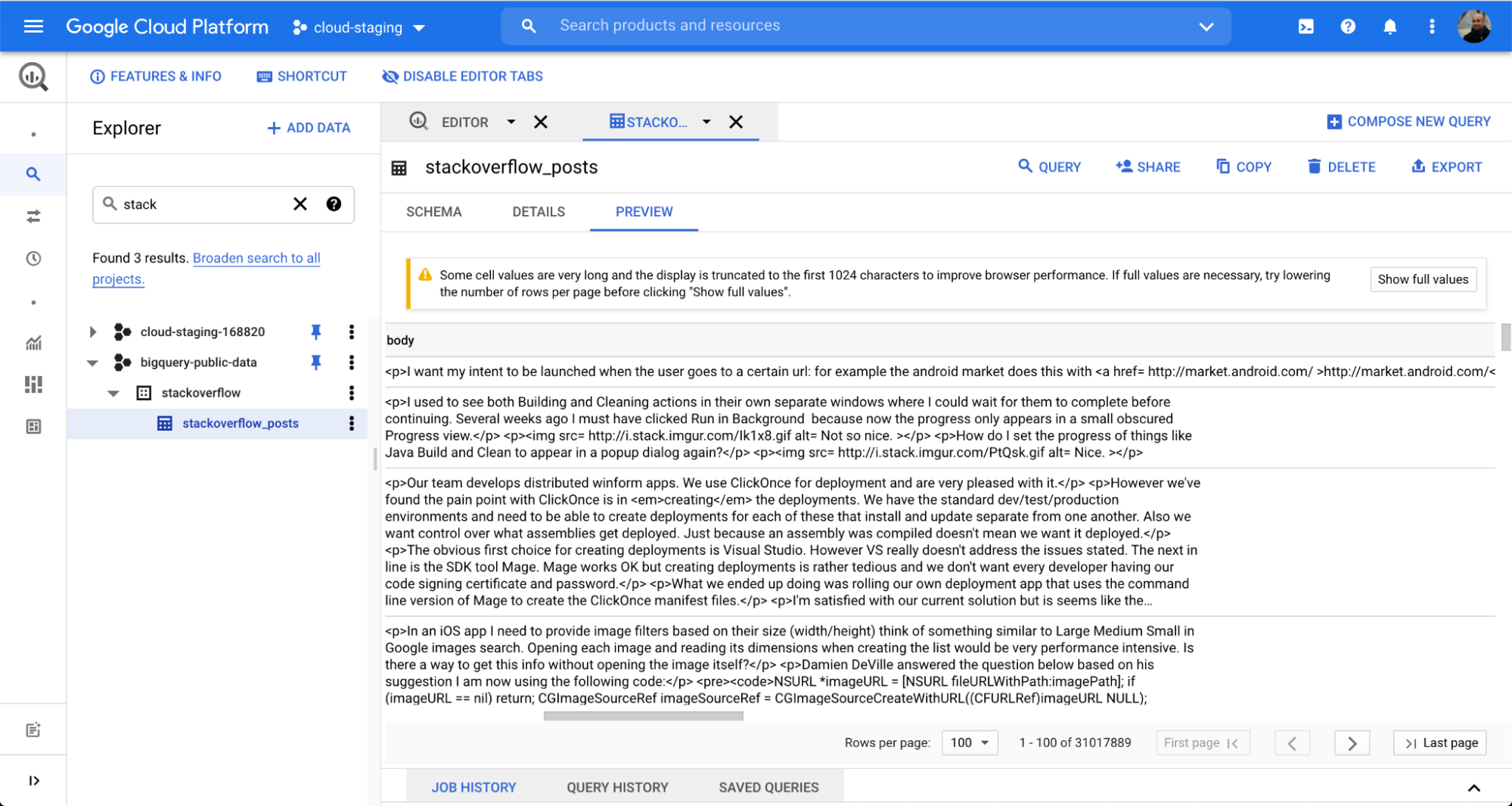
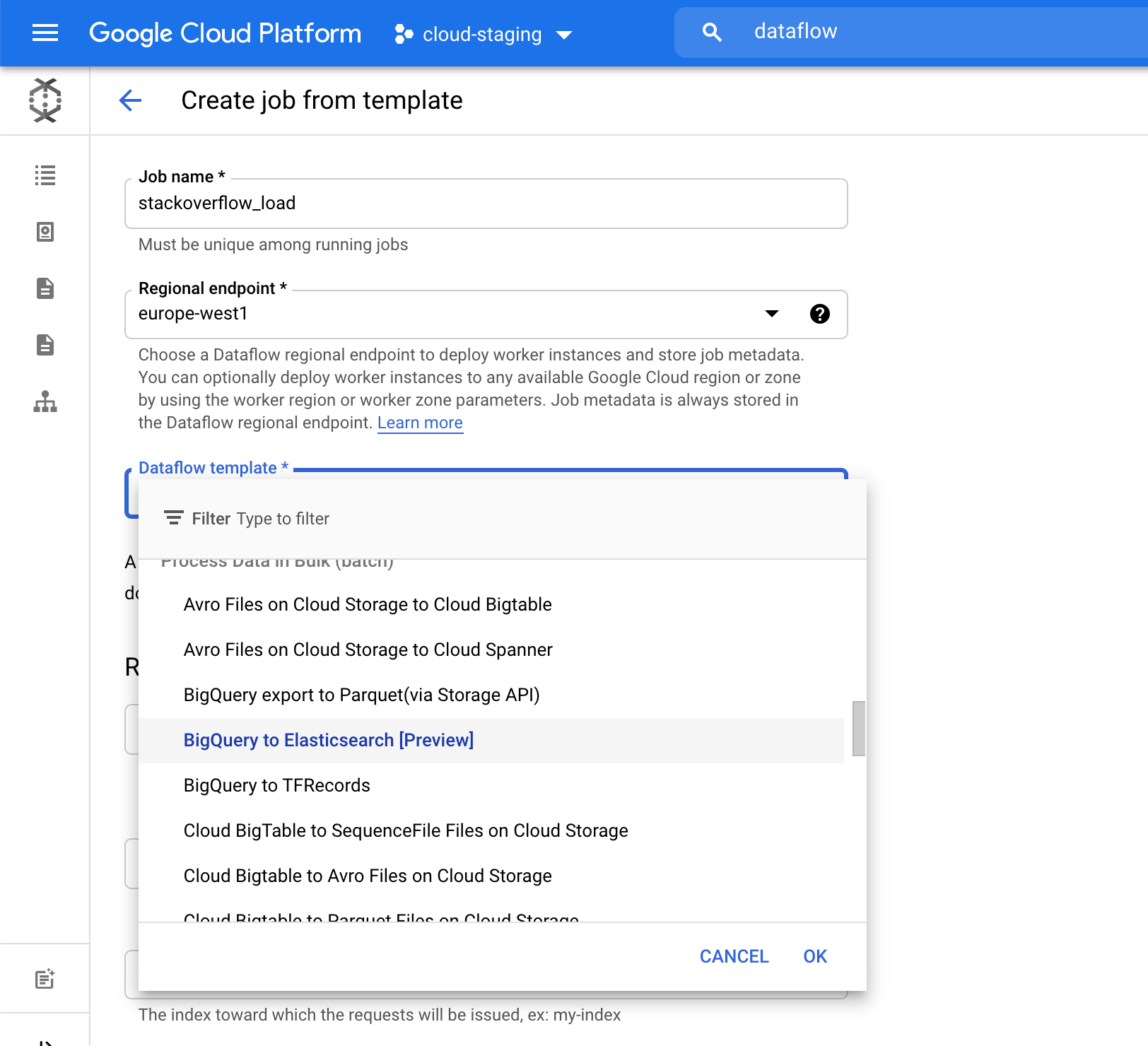
Wir wählen im Feld Elasticsearch Index den Namen des Index aus, in den unsere Daten geladen werden. In unserem Beispiel ist das der Index stack-posts. Die Tabelle in BigQuery, aus der gelesen werden soll, ist im folgenden Format anzugeben: „mein-projekt:mein-dataset.meine-tabelle“. In unserem Beispiel bedeutet das: bigquery-public-data:stackoverflow.stackoverflow_posts.
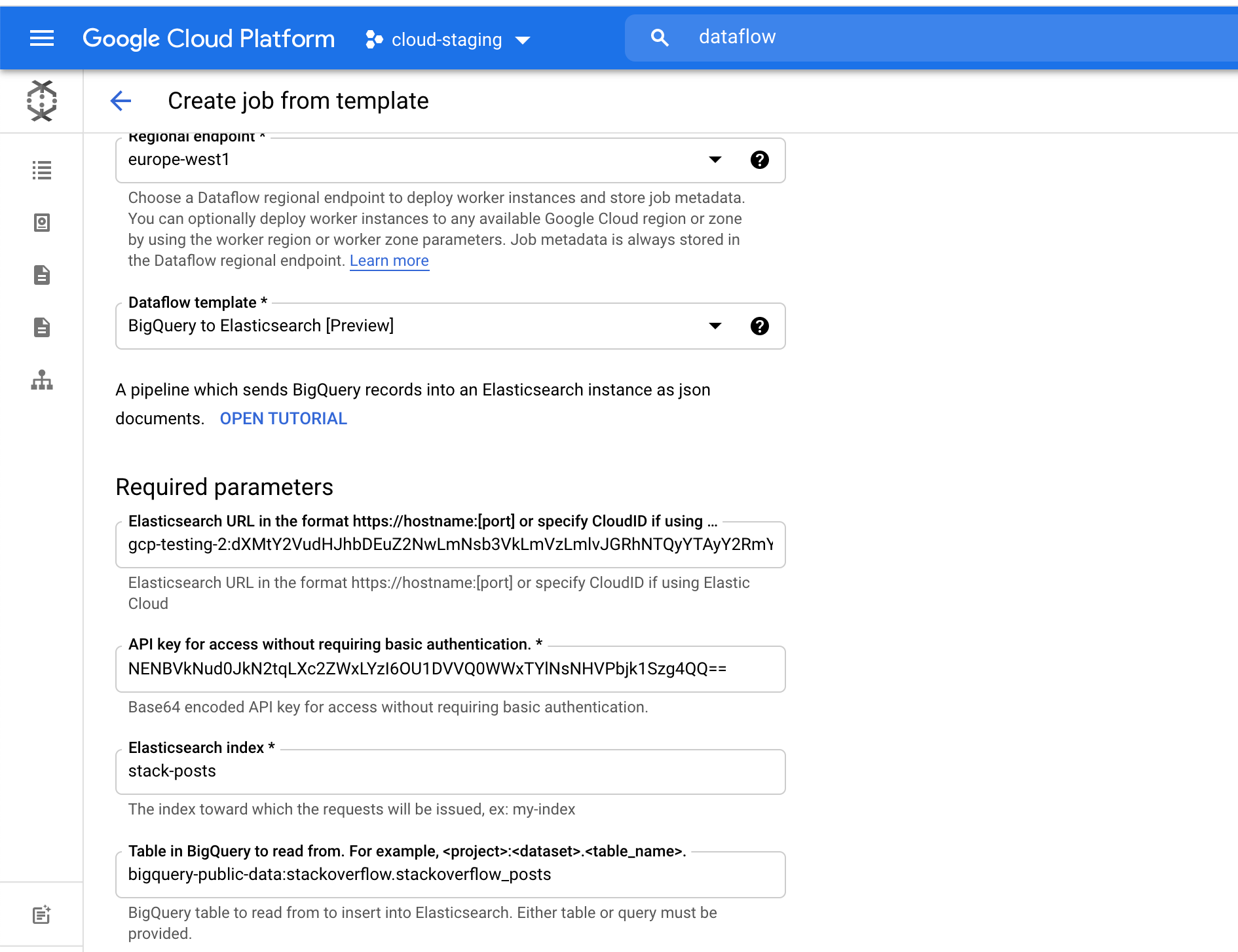
Mit einem Klick auf Job ausführen starten wir die Batchverarbeitung.
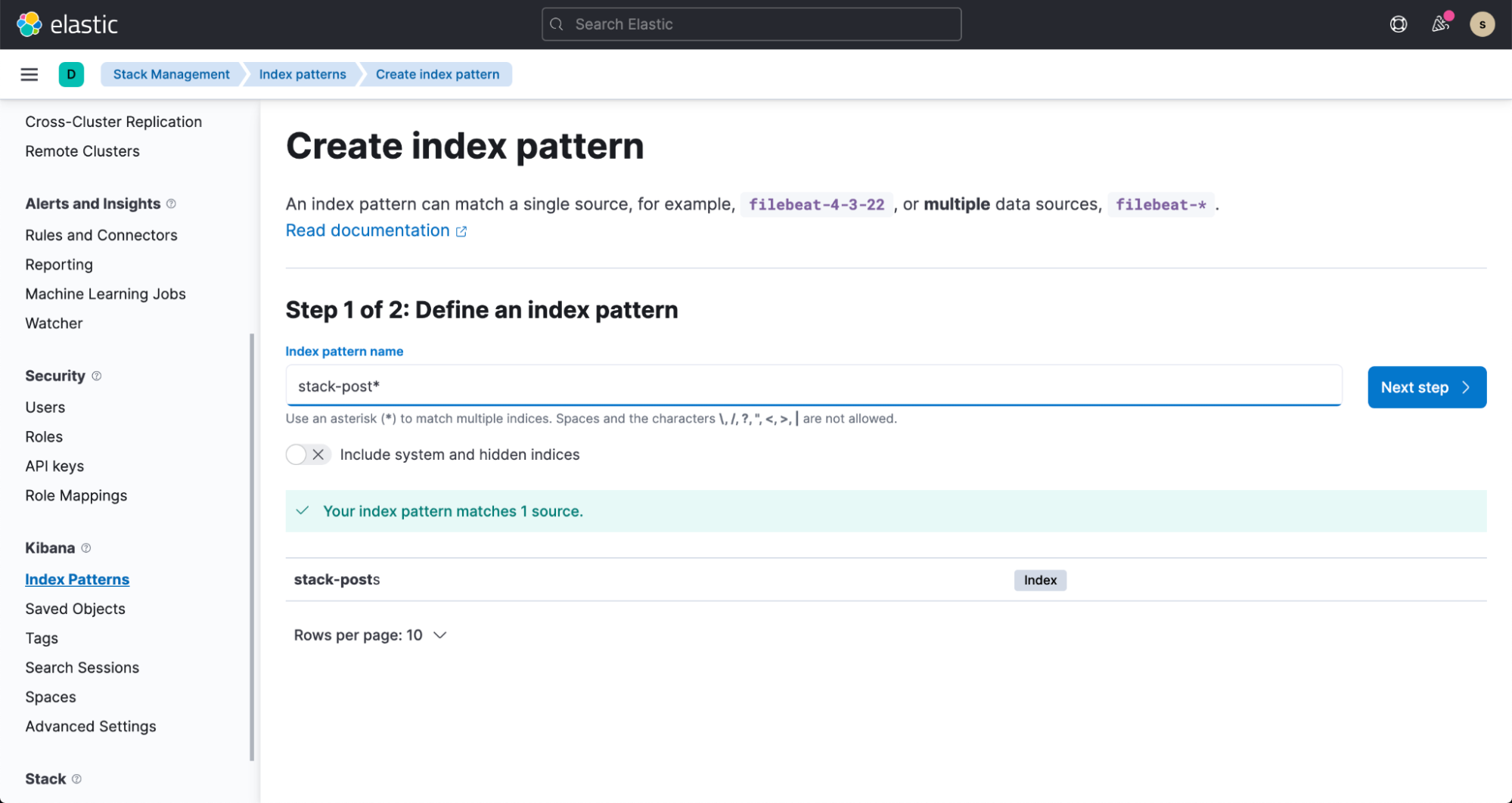
Es dauert nur ein paar Minuten, bis die ersten Daten in unserem Elasticsearch-Index ankommen. Wir können sie visualisieren, indem wir ein Indexmuster erstellen. Nähere Informationen dazu entnehmen Sie bitte der Dokumentation.
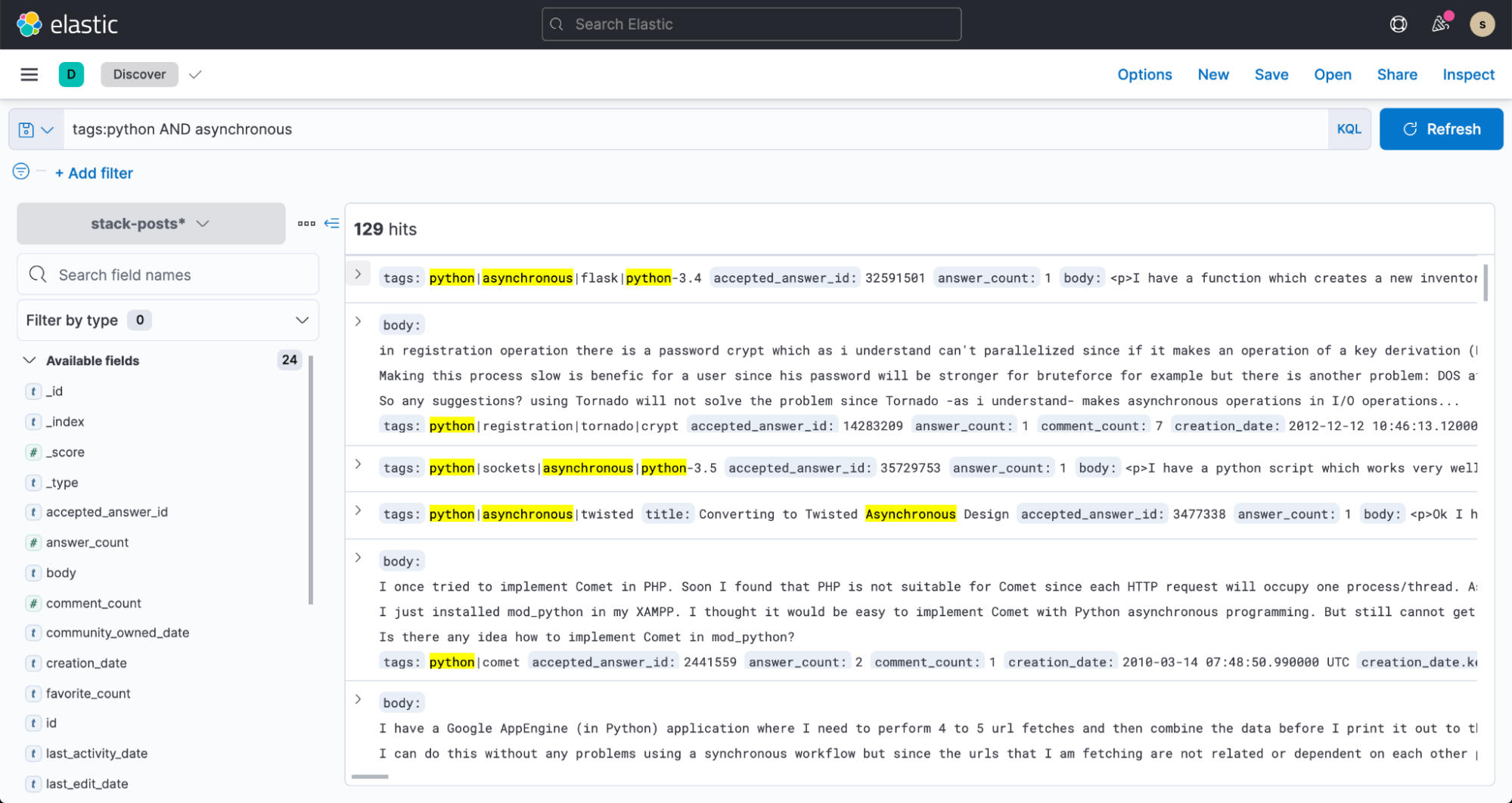
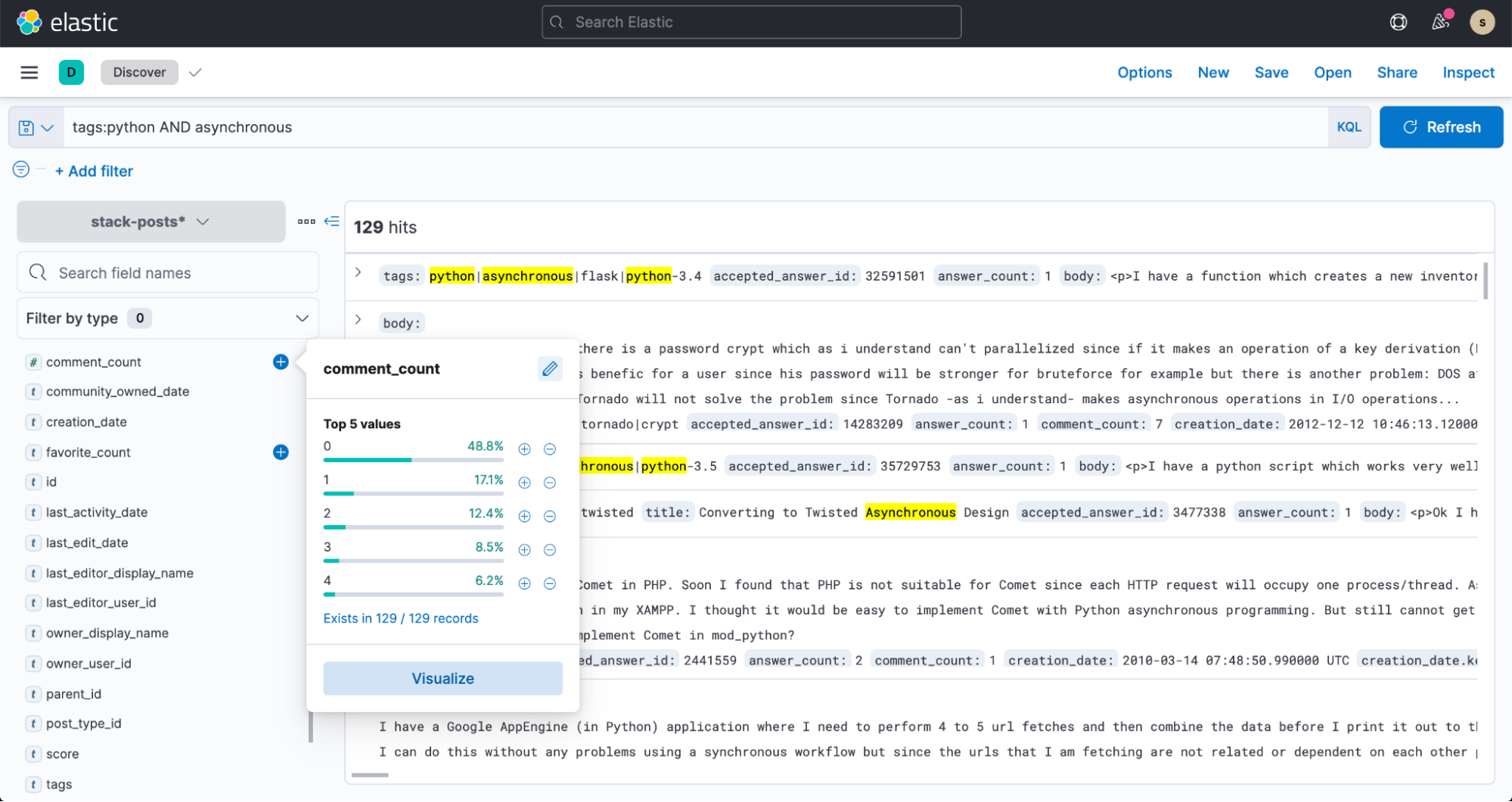
Jetzt können wir auch zu Discover in Kibana wechseln und damit beginnen, unsere Daten zu durchsuchen.
Fazit
Elastic erleichtert es Kunden immer mehr, selbst zu bestimmen, wo Jobs ausgeführt werden und was dabei genutzt wird. Diese optimierte Google Cloud-Integration ist das jüngste Beispiel dafür. Elastic Cloud macht den Elastic Stack noch wertvoller, denn Kunden können so schneller mehr erledigen – ideal, um das Potenzial unserer Plattform bestmöglich auszuschöpfen. Wenn Sie Elastic auf Google Cloud selbst erleben möchten, besuchen Sie den Google Cloud Marketplace oder elastic.co.Teilen
- Share on Twitter
Auf Twitter teilen
- Share on LinkedIn
Auf LinkedIn teilen
- Share on Facebook
Auf Facebook teilen
- Share by Email
Per E-Mail teilen
- Print this page
Drucken