Leader und Follower: Einführung in die Cluster-übergreifende Replikation in Elasticsearch
Grundbedürfnisse
Die Möglichkeit, Daten nativ aus einem Elasticsearch-Cluster in ein anderes Elasticsearch-Cluster replizieren zu können, ist unsere am häufigsten angefragte Funktion, nach der sich unsere Benutzer schon lange sehnen. Nachdem wir über Jahre hinweg die notwendige Basis geschaffen haben, neue und grundlegende Technologien in Lucene integriert haben und unser ursprüngliches Design iteriert und verfeinert haben, freuen wir uns sehr, ankündigen zu können, dass die Cluster-übergreifende Replikation (Cross-Cluster Replication, CCR) jetzt in Elasticsearch 6.7.0 verfügbar und produktionsbereit ist. Dieser erste in einer Reihe von Blogeinträgen enthält eine kurze Einführung in unsere Implementierung und technische Hintergrundinformationen zu CCR. In den kommenden Beiträgen werden wir einzelne CCR-Anwendungsfälle genauer unter die Lupe nehmen.
Die Cluster-übergreifende Replikation ermöglicht eine Vielzahl von missionskritischen Anwendungsfälle in Elasticsearch und im Elastic Stack:
- Disaster Recovery (DR) / Hochverfügbarkeit (HV): Viele missionskritische Anwendungen müssen den Ausfall eines Rechenzentrums oder einer Region verkraften können. Diese Anforderung wurde in Elasticsearch bisher durch zusätzliche Technologien erfüllt, was zu mehr Komplexität und einem höheren Verwaltungsaufwand führte. Rechenzentrumsübergreifende DR-/HV-Anforderungen können in Elasticsearch jetzt mit CCR ohne zusätzliche Technologien erfüllt werden.
- Data Locality: Replizieren Sie Daten in Elasticsearch, um näher an den Benutzern oder am Anwendungsserver zu sein, und reduzieren Sie Latenzen, die Kosten verursachen. Produktkataloge oder Referenzdatensätze können beispielsweise auf zwanzig oder mehr Rechenzentren weltweit repliziert werden, um den Abstand zwischen den Daten und dem Anwendungsserver zu minimieren. Ein weiterer möglicher Anwendungsfall ist ein Aktienhändler mit Niederlassungen in London und New York. Alle Transaktionen aus der Niederlassung in London werden lokal geschrieben und in die Niederlassung in New York repliziert, und die Transaktionen aus New York werden lokal geschrieben und nach London repliziert. Beide Niederlassungen haben eine globale Ansicht mit allen Transaktionen.
- Zentralisiertes Reporting: Replizieren Sie Daten aus vielen kleineren Clustern zurück in ein zentralisiertes Reporting-Cluster. Auf diese Weise können Sie ineffiziente Abfragen in großen Netzwerken vermeiden. Eine große, global tätige Bank hat etwa beispielsweise 100 Elasticsearch-Cluster in ihren weltweiten Niederlassungen. Mit CCR können wir Ereignisse aus allen 100 Banken weltweit zurück in einen zentralen Cluster replizieren, um sie lokal zu analysieren und zu aggregieren.
Vor Elasticsearch 6.7.0 konnten diese Anwendungsfälle teilweise mit externen Technologien umgesetzt werden. Diese Lösungen waren unpraktisch, erforderten erheblichen Verwaltungsaufwand und hatten zahlreiche Nachteile. Mit der nativ in Elasticsearch integrierten Cluster-übergreifenden Replikation sind unsere Benutzer frei von der Belastung und den Nachteilen dieser komplizierten Lösungen, können mehr Vorteile nutzen als vorhandene Lösungen (z. B. umfassende Fehlerbehandlung) und können APIs in Elasticsearch und Benutzeroberflächen in Kibana für die Verwaltung und Überwachung von CCR bereitstellen.
Halten Sie Ausschau nach den kommenden Beiträgen, in denen wir diese Anwendungsfälle ausführlich unter die Lupe nehmen werden.
Erste Schritte mit der Cluster-übergreifenden Replikation
Laden Sie die neuesten Versionen von Elastic und Kibana auf unserer Download-Seite herunter und folgen Sie unserer Anleitung für die ersten Schritte.
CCR ist Platin-Funktion und ist in der 30-tägigen Probelizenz enthalten, die Sie mit der API zum Starten des Testzeitraums oder direkt in Kibana aktivieren können.
Technische Einführung in die Cluster-übergreifende Replikation
CCR basiert auf einem Aktiv-Passiv-Indexmodell. Ein Index in einem Elasticsearch-Cluster kann so konfiguriert werden, dass er Änderungen aus einem Index in einem anderen Elasticsearch-Cluster repliziert. Der Index, der die Änderungen repliziert, wird auch als „Follower-Index“ bezeichnet, und der Index, aus dem repliziert wird, heißt „Leader-Index“. Der Follower-Index ist passiv und kann Leseanfragen und Suchen verarbeiten, akzeptiert aber keine direkten Schreibanfragen. Nur der Leader-Index ist für direkte Schreibanfragen aktiv. CCR wird auf der Indexebene verwaltet, und jedes Cluster kann sowohl Leader- als auch Follower-Indizes enthalten. Auf diese Weise können Sie einige Aktiv-Aktiv-Anwendungsfälle umsetzen, indem Sie bestimmte Indizes in einer Richtung replizieren (z. B. aus einem US-Cluster in ein europäisches Cluster) und andere Indizes in die andere Richtung (aus Europa in die USA).
Die Replikation erfolgt auf der Shard-Ebene. Jede Shard im Follower-Index ruft Änderungen aus der entsprechenden Shard im Leader-Index ab. Der Follower-Index hat also dieselbe Anzahl an Shards wie der Leader-Index. Alle Operationen zum Erstellen, Ändern und Löschen von Dokumenten werden vom Follower repliziert. Die Replikation erfolgt beinahe in Echtzeit. Sobald der globale Checkpoint in einer Shard erhöht wird, ist eine Operation für die Replikation durch eine Follower-Shard verfügbar. Die Operationen werden von der Follower-Shard effizient und paketweise abgerufen, und mehrere Anfragen zum Abrufen von Änderungen können parallel ausgeführt werden. Diese Leseanfragen können vom primären Index und von den Replikaten beantwortet werden und verursachen neben dem Lesen aus der Shard keine zusätzliche Last auf dem Leader. Mit diesem Design können Sie CCR parallel zu Ihrer Produktionslast skalieren und auch in Zukunft die leistungsstarken Indizierungsraten genießen, die Sie in Elasticsearch schätzen (und erwarten).
CCR unterstützt sowohl neu erstellte als auch vorhandene Indizes. Bei der Erstkonfiguration eines Followers führt dieser einen Bootstrap vom Leader-Index durch, indem die zugrunde liegenden Dateien aus dem Leader-Index auf ähnliche Weise wie beim Wiederherstellen eines Replikats vom primären Index kopiert werden. Nach Abschluss dieses Wiederherstellungsprozesses repliziert CCR alle weiteren Operationen vom Leader. Änderungen an Zuordnungen und Einstellungen werden bei Bedarf automatisch vom Leader-Index repliziert.
Beim Einsatz von CCR können gelegentlich Fehler auftreten (z. B. ein Netzwerkausfall). CCR klassifiziert diese Fehler automatisch in behebbare und schwerwiegende Fehler. Bei einem behebbaren Fehler startet CCR eine Wiederholungsschleife und kann die Replikation fortsetzen, sobald die Fehlerursache behoben wurde.
Sie können den Status der Replikation mit einer speziellen API überwachen. Mit dieser API können Sie ablesen, wie eng ein Follower dem Leader folgt, haben ausführliche Statistiken zur CCR-Leistung zur Verfügung und können alle Fehler nachverfolgen, die Ihre Aufmerksamkeit erfordern.
Wir haben CCR in die Überwachungs- und Verwaltungsanwendungen in Kibana integriert. In der Überwachungsoberfläche sehen Sie Ihren CCR-Fortschritt und eventuelle Fehler.

Benutzeroberfläche für die Elasticsearch CCR-Überwachung in Kibana
In dieser Verwaltungsoberfläche können Sie Remote-Cluster und Follower-Indizes konfigurieren und automatische Follower-Muster zur automatischen Replikation von Indizes verwalten.
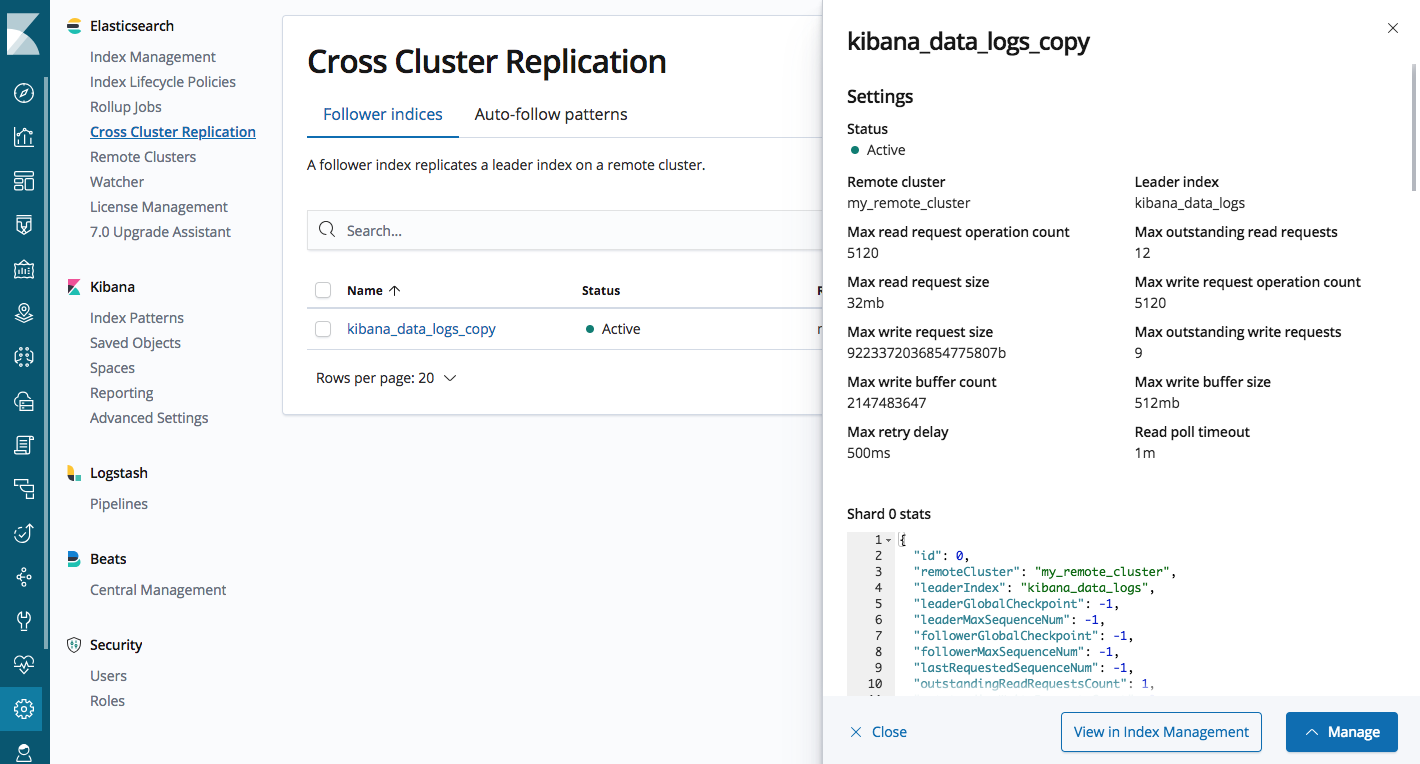
Benutzeroberfläche für die Elasticsearch CCR-Verwaltung in Kibana
Automatische Follow-Funktion für die Indizes des Tages
Viele unserer Benutzer verwenden Arbeitslasten, die regelmäßig neue Indizes erstellen. Mögliche Beispiele sind tägliche Indizes für Log-Dateien aus Filebeat, oder Indizes, die von einer Index-Lebenszyklusverwaltung automatisch rotiert werden. Um für die Replikation in diesen Fällen keine manuellen Follower-Indizes erstellen zu müssen, haben wir die automatische Follow-Funktion direkt in CCR integriert. Mit dieser Funktion können Sie Muster für Indizes konfigurieren, die automatisch aus einem Quell-Cluster repliziert werden sollen. CCR überwacht diese Cluster auf Indizes, die diesen Mustern entsprechen, und konfiguriert Follower-Indizes, um diese Leader-Indizes zu replizieren.
Außerdem haben wir CCR und ILM integriert, um zeitbasierte Indizes mit CCR replizieren und in Quell- und Ziel-Clustern mit ILM verwalten zu können. ILM erkennt beispielsweise, wenn ein Leader-Index von CCR repliziert wird und verwaltet destruktive Operationen wie Verkleinerungen (Shrinking) und Löschvorgänge sorgfältig, bis CCR die Replikation abgeschlossen hat.
Auf den Verlauf kommt es an
Um die Änderungen mit CCR replizieren zu können, brauchen wir einen Verlauf der Operationen in den Shards des Leader-Index sowie Zeiger in den einzelnen Shards, um zu erkennen, welche Operationen sicher repliziert werden können. Dieser Operationsverlauf wird mit Sequenz-IDs verwaltet, und der Zeiger wird auch als globaler Checkpoint bezeichnet. Die Sache hat jedoch einen Haken. Wenn Sie ein Dokument in Lucene ändern oder löschen, ändert Lucene ein Bit, um das Dokument als gelöscht zu markieren. Das Dokument ist weiterhin auf dem Datenträger vorhanden, bis die gelöschten Dokumente irgendwann bei einer Zusammenführung entfernt werden. Wenn CCR diese Operation repliziert, bevor der Löschvorgang beim Zusammenführen entfernt wird, ist alles in Ordnung. Die Zusammenführungen erfolgen jedoch nach einem eigenen Zeitplan, und gelöschte Dokumente werden möglicherweise entfernt, bevor CCR eine Chance hatte, die Operation zu replizieren. Ohne jegliche Kontrolle darüber, wann gelöschte Dokumente entfernt werden, kann es passieren, dass CCR Operationen verpasst und den Operationsverlauf nicht vollständig in den Follower-Index replizieren kann. Im Anfangsstadium der Planung von CCR hatten wir vor, das Elasticsearch-translog als Quelle für den Verlauf dieser Operationen zu verwenden. Damit hätten wir das Problem umgangen. Dabei fiel uns jedoch schnell auf, dass das translog nicht für die Zugriffsmuster entwickelt wurde, die CCR für den reibungslosen Betrieb benötigt. Wir haben mit dem Gedanken gespielt, zusätzliche Datenstrukturen im und neben dem translog hinzuzufügen, um die benötigte Leistung zu erreichen, aber dieser Ansatz hat ebenfalls Nachteile. Einerseits würden wir die Komplexität in einer der wichtigsten Komponenten in unserem System erhöhen, was nicht mit unserer Engineering-Philosophie vereinbar ist. Außerdem würden damit zukünftige Änderungen komplizierter, die wir für den Operationsverlauf geplant haben und bei denen wir entweder die unterstützten Sucharten für den Operationsverlauf einschränken oder Lucene für das translog komplett neu implementieren müssten. Nach dieser Erkenntnis wurde uns klar, dass wir einige Funktionen nativ in Lucene implementieren müssen, um steuern zu können, wann ein gelöschtes Dokument beim Zusammenführen entfernt wird, wodurch der Operationsverlauf praktisch komplett nach Lucene verschoben wurde. Wir nennen diese Technologie „Soft-Delete“ (sanfte Löschung). Diese Investition in Lucene wird sich im Lauf der nächsten Jahre auszahlen, da nicht nur CCR darauf basiert, sondern wir auch dabei sind, unser Replikationsmodell auf Basis von Soft-Deletes zu überarbeiten, und die demnächst erhältliche Änderungs-API arbeitet ebenfalls damit. Soft-Deletes müssen in Leader-Indizes aktiviert werden.
Anschließend können die Follower beeinflussen, wann die Soft-Deleted Dokumente auf dem Leader beim Zusammenführen entfernt werden. Zu diesem Zweck haben wir Aufbewahrungs-Leases für den Shard-Verlauf implementiert. Mit einer Aufbewahrungs-Lease für den Shard-Verlauf kann ein Follower im Operationsverlauf auf dem Leader den aktuellen Stand der Replikation markieren. Die Leader-Shards wissen, dass alle Operationen unterhalb dieser Markierung sicher entfernt werden können, und Operationen oberhalb der Markierung müssen aufbewahrt werden, bis der Follower die Chance hatte, sie zu replizieren. Diese Markierungen sorgen dafür, dass die noch nicht replizierten Operationen auf dem Leader aufbewahrt werden, wenn ein Follower vorübergehend ausfällt. Da dieser Verlauf zusätzlichen Speicherplatz auf dem Leader verbraucht, sind diese Markierungen nur für begrenzte Zeit gültig. Nach Ablauf dieser Frist verfällt die Markierung, und die Leader-Shards können ihren Verlauf zusammenführen. Der genaue Wert für diesen Zeitraum hängt davon ab, wie viel zusätzlichen Speicherplatz Sie für den Fall zurückhalten möchten, dass ein Follower ausfällt, und wie lange ein Follower offline sein darf, bevor ein neuer Bootstrap-Vorgang vom Leader ausgeführt werden muss.
Zusammenfassung
Wir freuen uns darauf, dass Sie CCR ausprobieren und Ihr Feedback zu dieser neuen Funktion mit uns teilen. Hoffentlich haben Sie genau so viel Freude an dieser Funktion wie wir bei ihrer Entwicklung hatten. Halten Sie Ausschau nach weiteren Beiträgen in dieser Reihe, in denen wir die Ärmel hochkrempeln und verschiedene Funktionen und Anwendungsfälle für CCR ausführlicher besprechen werden. Falls Sie Fragen zu CCR haben, erreichen Sie uns in unserem Diskussionsforum.
Das Urheberrecht für das Miniaturbild Bild zu diesem Beitrag gehört der NASA, und das Bild wurde unter der CC BY-NC 2.0-Lizenz veröffentlicht. Das Urheberrecht für das Banner Bild zu diesem Beitrag gehört Rawpixel Ltd, und das Bild wurde unter der CC BY 2.0-Lizenz veröffentlicht und zeigt einen Ausschnitt des Originals.