Verständnis von Daten-Mesh im öffentlichen Sektor: Säulen, Architektur und Beispiele


 Share on Twitter
Share on TwitterAuf Twitter teilen

 Share on LinkedIn
Share on LinkedInAuf LinkedIn teilen

 Share on Facebook
Share on FacebookAuf Facebook teilen

 Share by Email
Share by EmailPer E-Mail teilen

 Print this page
Print this pageDrucken
Denken Sie an all die Daten, die hinter Projekten wie dem Verteidigungsnachrichtendienst, Aufzeichnungen über das öffentliche Gesundheitswesen, Stadtplanungsmodellen und mehr stehen. Regierungsbehörden generieren ständig enorme Datenmengen. Noch komplizierter wird es, wenn die Daten über Cloud-Plattformen, On-Prem-Systeme oder spezielle Umgebungen wie Satelliten und Notrufzentralen verteilt sind. Es ist schwer, Informationen zu finden, geschweige denn, sie effizient zu nutzen. Und da verschiedene Teams mit vielen unterschiedlichen Apps und Datenformaten arbeiten, entsteht ein echter Mangel an Interoperabilität.
Trotz ihrer Bemühungen, datengesteuerte Organisationen aufzubauen, haben 65 % der Führungskräfte im öffentlichen Sektor immer noch Schwierigkeiten, Daten kontinuierlich, in Echtzeit und in großem Maßstab zu nutzen, so eine aktuelle Elastic-Studie.
„Es dauert länger, unsere Arbeit zu erledigen, was nicht gut ist, da die meisten unserer Aufgaben in Notfällen durchgeführt werden“, sagte ein führender Vertreter des öffentlichen Sektors gegenüber Elastic. „Wir müssen in der Lage sein, so schnell wie möglich Informationen zu erhalten.“
Der Datenberg wächst. Der Zugang dazu ist ein Engpass. Wie können öffentliche Einrichtungen also die Komplexität dieser zentralisierten Silos loswerden? Ein Daten-Mesh bietet eine alternative Möglichkeit zur Datenorganisation, die die Antwort sein könnte.
Was ist ein Daten-Mesh?
Vereinfacht ausgedrückt: Ein Daten-Mesh überwindet Silos. Daten, die im gesamten Netzwerk gesammelt werden, können an jedem beliebigen Punkt des Ökosystems abgerufen und analysiert werden – sofern der Nutzer die Zugriffsberechtigung hat. Es bietet eine einheitliche und dennoch verteilte Ebene, die Datenoperationen vereinfacht und standardisiert.

4 Säulen des Daten-Meshs
Ein Daten-Mesh basiert auf vier Hauptprinzipien:
Domänenbesitz: So verwalten Behörden und Abteilungen ihre eigenen Daten
Daten als Produkt: Wo diese Domäneninhaber sicherstellen, dass ihre Datensätze von hoher Qualität und leicht zugänglich sind
Self-Service-Plattformen: Ermöglichen Sie internen und externen Teams das Auffinden und Verwenden hochwertiger Daten ohne IT-Störungen.
Föderierte Governance: Stellt sicher, dass alles reibungslos und sicher über alle Systeme hinweg funktioniert
Schauen wir uns diese jeweils etwas genauer an.
Domänenbesitz
Anstatt sich auf ein zentrales IT-Team zu verlassen, das alle Daten verwaltet, ist das Eigentum an den Daten auf verschiedene Behörden und Abteilungen verteilt. Im Wesentlichen bauen Sie technische Teams auf, die die Zusammensetzung der Agentur selbst widerspiegeln. Sie möchten, dass die Daten den Personen gehören, die am besten mit ihnen vertraut sind. Das kann im öffentlichen Gesundheitswesen, in der Verteidigung, in der Stadtplanung und mehr angewendet werden – also in praktisch jedem Anwendungsfall im öffentlichen Sektor.
Beispielsweise verwendet die US Cybersecurity and Infrastructure Security Agency (CISA) einen Daten-Mesh-Ansatz, um Einblick in die Sicherheitsdaten von Hunderten von Bundesbehörden zu erhalten und gleichzeitig jeder Behörde die Kontrolle über ihre Daten zu ermöglichen.
Das führt uns zur zweiten (und wohl wichtigsten) Säule – der Säule, auf die die anderen drei Säulen ausgerichtet sind:
Daten als Produkt
Jeder Datensatz wird als Produkt mit klarer Dokumentation und Qualitätsstandards behandelt. Die Abteilung, der die Daten gehören, muss dafür sorgen, dass sie leicht zugänglich und organisiert sind, wenn andere Abteilungen sie benötigen. Mit anderen Worten: Sie sind verantwortlich und verpflichtet, diese Daten als nutzbares Produkt weiterzugeben.
Aus Sicht der Regierung könnten das zum Beispiel Volkszählungsinformationen, Notfalldaten oder Geheimdienstberichte sein. Es hängt alles von der Struktur des Projekts oder der Regierungsbehörde ab. Wichtig ist, dass diese kuratierten Daten zur Verfügung stehen, wenn andere Teams nach ihnen suchen, und dass sie keine Zeit mit der Bereinigung oder Überprüfung der Daten verbringen müssen.
Sie fragen sich vielleicht: Ist das nicht einfach nur eine weitere Möglichkeit, analytische Daten in Silos zu speichern? Wie können andere Abteilungen im Einzelnen darauf zugreifen? Das führt uns zu unserer nächsten Säule.
Self-Service-Plattformen
Von den Abteilungen wird hier viel verlangt, und sie brauchen praktische Plattformen, die ihre Daten für andere zugänglich machen. Durchsuchbare Kataloge zum einfachen Auffinden von Daten, Abfragetools für Echtzeitanalysen und die Möglichkeit für Nutzer, Daten selbst zu bereinigen und zu integrieren sowie Einblicke über Dashboards und APIs zu teilen, sind alles Tools, die genutzt werden können.
Sie benötigen auch eine integrierte Governance, um Zugriffskontrollen durchzusetzen, was uns zu unserer letzten Säule führt.
Föderierte rechnergestützte Governance
Damit haben wir festgelegt, dass jede Abteilung die Kontrolle über ihre eigenen Daten hat. Das Daten-Mesh benötigt jedoch immer noch übergreifende Governance-Protokolle, um alles sicher zu halten und Risiken zu verhindern.
Diese Sicherheitskontrollen sollten in das System integriert werden, das die Daten abruft, anstatt von jeder Abteilung separat angewendet zu werden. Das System sollte im Rahmen der Suche die Nutzerberechtigungen prüfen und sicherstellen, dass den Nutzern von Anfang an nur die Daten angezeigt werden, auf die sie zugreifen dürfen.
Im öffentlichen Sektor kann das alles sein, von Datenschutzbestimmungen für Daten im Gesundheitswesen bis hin zu Verschlusssachen in Verteidigungssystemen.
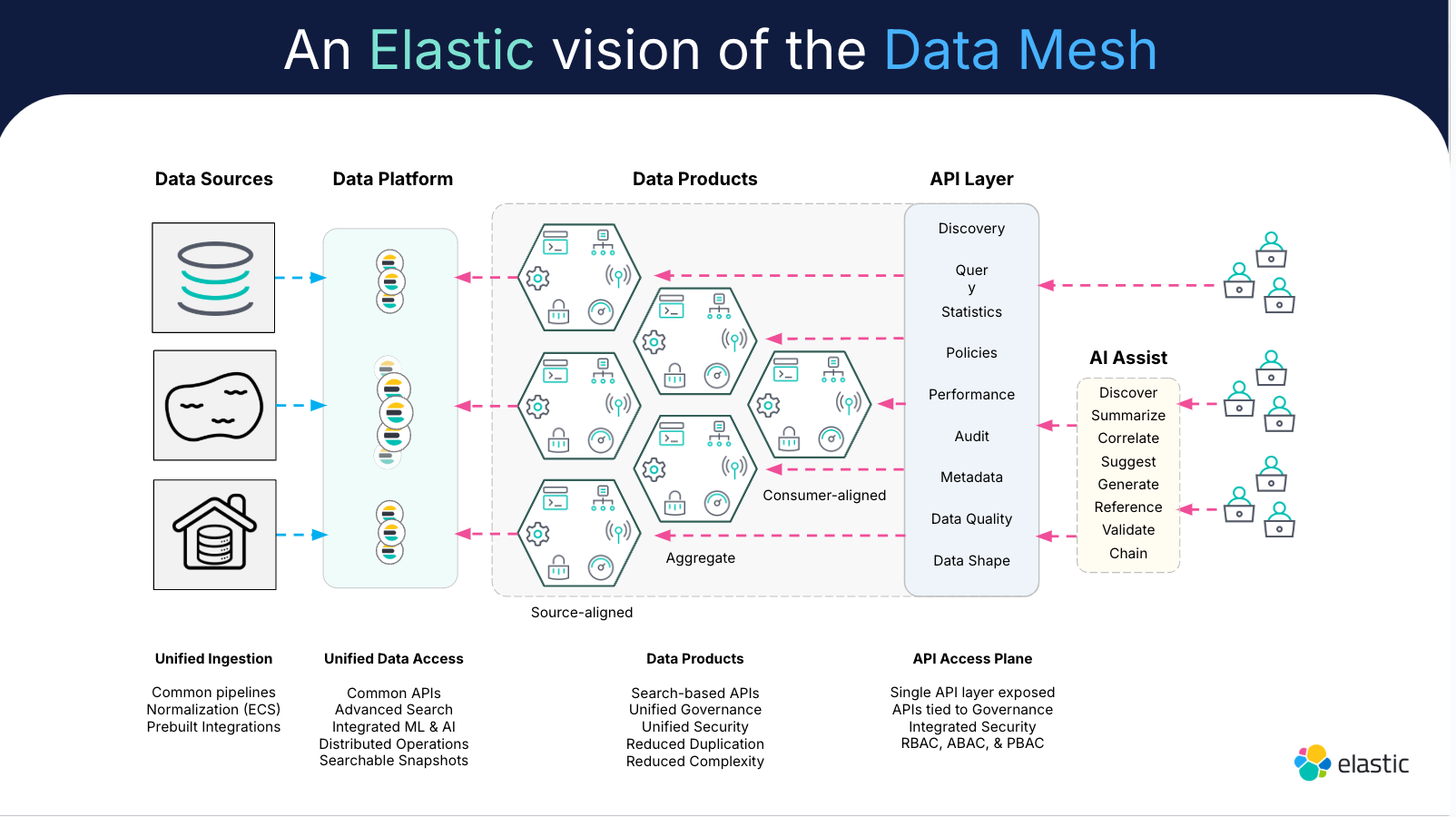
Daten-Mesh-Architektur
Eine Daten-Mesh-Architektur ist ein Framework, das die Säulen von Daten-Mesh in einem Prozess zur Verwaltung verteilter Daten vereint.
Die Implementierung einer Daten-Mesh-Architektur reduziert die Reibungsverluste im Kollaborationsprozess. Für Teams, die mit domänenspezifischen Daten für das Modelltraining und die Analyse arbeiten, ist es dank seines nutzerzentrierten Ansatzes ein Gamechanger.
Ein Daten-Mesh ermöglicht eine effizientere Datenverarbeitung und -verwaltung im großen Maßstab, trotz mehrerer Plattformen und Implementierungsteams. Die Daten-Mesh-Architektur schafft mehr Autonomie und eine stärkere Demokratisierung der Daten – wenn Sie über eine skalierbare, selbstbedienbare Daten-Beobachtbarkeit verfügen. Durch die Datenbeobachtung können Teams alle Daten über eine zentrale Ansicht verwalten.
Eine effektive Daten-Beobachtbarkeit ist in die Architektur eines Data-Mesh integriert. Dadurch erhalten die Teams Zugriff auf Einblicke, die sie aus allen von ihnen gesammelten Daten nutzen können. Stellen Sie sich das so vor: Bei der Daten-Beobachtbarkeit geht es darum, den Zustand und die Integrität der Daten im Auge zu behalten, während es bei Daten-Mesh-Architekturen um die dezentrale Verwaltung dieser Daten geht. Und um sie zu verwalten, müssen Sie in der Lage sein, sie im Detail zu durchschauen.
Daten-Mesh im Vergleich zu anderen Ansätzen
Wie schneidet Daten-Mesh im Vergleich zu alternativen Formen der analytischen Datenarchitektur und -datenspeicher ab? Sehen wir uns zwei weitere an, die häufig verglichen werden: Daten-Fabric und Daten-Lakes.
Daten-Mesh im Vergleich zu Daten-Fabric
Daten-Mesh und Daten-Fabric ähneln sich insofern, als sie beide einen dezentralen Ansatz verfolgen und Daten an entfernten Standorten sammeln. Ein Daten-Fabric kopiert jedoch die an einem Standort gesammelten Daten an einen anderen Standort. Diese Daten werden als einzelne Datensätze weitergegeben und können nicht mit anderen Datensätzen korreliert werden, es sei denn, sie werden von etwas konsumiert, das einen Sinn daraus macht. Dieser Ansatz kann oft zu Datensilos führen.
Ein Daten-Mesh-Ansatz hingegen basiert nicht auf dem Kopieren von Daten und indexiert Daten stattdessen lokal beim Ingestieren in eine verteilte Platform, auf der Nutzer lokal und standortübergreifend nach Daten suchen können. In diesem Modell werden Daten auf der Ebene der Such-Plattform vereinheitlicht. Daten werden einmal indiziert und stehen dann über diese einheitliche Ebene jedem autorisierten Nutzer oder Anwendungsfall zur Verfügung.
Daten-Mesh im Vergleich zu Daten-Lake
Ihnen ist vielleicht aufgefallen, dass es in Daten viele wasserbezogene Metaphern gibt: Datenströme, Daten-Pipelines usw. Daten können wie Wasser gesammelt, gespeichert, gefiltert und verteilt werden – manchmal effizient, manchmal chaotisch.
So wie ein See Wasser aus mehreren Quellen sammelt, sammelt ein Daten-Lake Daten und speichert sie für die zukünftige Verwendung. Mit anderen Worten, es ist eine Speicherumgebung für jede Kombination strukturierter, halbstrukturierter oder unstrukturierter Daten.
Daten-Lakes können den Eigentümern von Daten-Meshes bei der Verarbeitung und Kuratierung ihrer Datenprodukte manchmal hilfreich sein. Sie können einen Daten-Lake für die Langzeitspeicherung großer, unstrukturierter Datensätze (etwa Satellitenbilder oder öffentliche Aufzeichnungen) verwenden, die noch keinen bestimmten Zweck haben. Wenn ein Daten-Lake jedoch unorganisiert und schwer zu navigieren ist, verwandelt er sich in einen Datensumpf – undurchsichtig, unübersichtlich und schwer zu verwerten.
Daten-Mesh und AI
Daten-Mesh kann eine Möglichkeit sein, AI und Machine Learning für Behörden zu demokratisieren. Traditionell haben Data-Science-Teams als zentralisierte Knotenpunkte gearbeitet und Daten aus verschiedenen Quellen gezogen, um Modelle für Machine Learning zu entwickeln. Wie bereits erwähnt, kann dieser Prozess jedoch zu redundanter Arbeit und Inkonsistenzen führen, was wiederum Probleme bei der Reproduzierbarkeit der Modelle mit sich bringt.
Wenn Sie dieses Modell mit Daten-Mesh umdrehen und die AI-Entwicklung in die Fachteams einbetten, können Sie die Daten an der Quelle bereinigen und verfeinern und ein AI-gesteuertes Datenprodukt erstellen, das andere Abteilungen nutzen können.
Nehmen Sie als Beispiel die nationale Katastrophenhilfe. AI-Modelle, die in Notfallteams eingebettet sind, analysieren oft Daten wie Echtzeit-Satellitenbilder, Sensordaten und sogar Berichte aus den sozialen Medien, um die am stärksten betroffenen Gebiete zu identifizieren. Mit Daten-Mesh könnten verschiedene Behörden – von Regierungsstellen bis hin zu Ersthelfern – sofort auf diese Informationen zugreifen, ohne auf eine zentrale Verarbeitung zu warten, und so ihre Reaktionszeiten verbessern.
Ein Daten-Mesh verbessert auch die AI-Governance, da es sie von Anfang an einbezieht und Aufgaben wie Modellvalidierung, Erkennung von Verzerrungen, Erklärbarkeit und Monitoring der Modellabweichung standardisiert.
So implementieren Sie ein Daten-Mesh für den öffentlichen Sektor
Jede Organisation des öffentlichen Sektors hat ihre eigenen Datenbedürfnisse. Deshalb können Datensilos, die für alle gleich sind, für interne und externe Nutzer langsam und erdrückend sein. Zwei von drei Führungskräften im öffentlichen Sektor gaben an, dass sie mit den ihnen zur Verfügung stehenden Daten-Einblicken unzufrieden sind.
Ein Daten-Mesh kann an die individuellen Bedürfnisse jeder Behörde im öffentlichen Sektor angepasst werden, von der Verteidigung bis zur nationalen Sicherheit oder der Bundes-, Landes- und Kommunalverwaltung.
Um mit Daten-Mesh zu beginnen, müssen öffentliche Einrichtungen einige Schritte befolgen:
Weisen Sie bestimmten Abteilungen die Verantwortung für Daten zu.
Behandeln Sie Datensätze als gut dokumentierte, zugängliche Assets, die für die interne und externe Nutzung bestimmt sind, und stellen Sie sicher, dass sie den gesetzlichen Anforderungen entsprechen.
Implementieren Sie Tools, mit denen Behörden, Analysten und politische Entscheidungsträger problemlos auf Daten zugreifen und diese analysieren können, ohne auf zentralisierte IT-Teams angewiesen zu sein.
Setzen Sie die Governance agenturübergreifend durch und berücksichtigen Sie dabei Frameworks wie FedRAMP, CMMC und Zero Trust.
Und schließlich sollten Sie die gemeinsame Nutzung von Daten zwischen verschiedenen Organisationen fördern, um bessere Entscheidungen zu treffen und die öffentlichen Dienste zu verbessern, während gleichzeitig die Sicherheitskontrollen gepflegt werden.
Anwendungen für Regierung und Verteidigung
Ein Daten-Mesh eignet sich hervorragend für den Regierungs- und Verteidigungssektor, wo große, verteilte Daten sicher und in Echtzeit abgerufen und analysiert werden müssen.
Im Verteidigungsbereich hilft es bei der schnelleren Erfassung von Informationen und der Verwaltung von Ressourcen, sodass die Mitarbeitenden im Feld mit den neuesten Daten arbeiten können. Im Gesundheitswesen kann es helfen, epidemiologische Daten aus Krankenhäusern oder Forschungslabors schnell zu integrieren, um auf Ausbrüche zu reagieren. Verkehrsabteilungen können Verkehrs- und Wetterdaten stadtweit analysieren. Bildungsabteilungen können die Testergebnisse von Kindern in den letzten zehn Jahren einsehen und sie mit anderen Daten abgleichen, z. B. mit der Zeit, die für das Lernen aus der Ferne im Vergleich zur persönlichen Anwesenheit aufgewendet wurde.
Nehmen wir dieses Beispiel der US Navy: Ihr Streben nach digitaler Modernisierung hängt von der Fähigkeit ab, „alle Informationen sicher von überall nach überall zu verschieben“, um Informationsüberlegenheit zu erreichen. Der herkömmliche zentralisierte Datenspeicher ist jedoch zu riskant, insbesondere in Air-Gapped- und DDIL-Umgebungen (Denied, Degraded, Intermittent and Limited). Hier ist ein Fall, in dem ein globales Daten-Mesh helfen kann, das es ermöglicht, dass Daten an ihrer Quelle bleiben, während sie weiterhin durchsuchbar und in der riesigen Einsatzlandschaft der Navy zugänglich sind. Dieser dezentrale Ansatz hält den Betrieb auch dann widerstandsfähig, wenn ein Server oder ein Rechenzentrum ausfällt, und bietet eine einheitliche Sicht auf geschäftskritische Daten, ohne dass sie verschoben oder dupliziert werden müssen.
Daten-Mesh in Aktion mit Elastic
Als Search AI Company dient die Datenanalyseplattform von Elastic als leistungsstarkes globales Daten-Mesh, das maschinelles Lernen, Verarbeitung natürlicher Sprache, semantische Suche, Alarmierung und Visualisierung in einem einheitlichen System bietet. Mit anderen Worten: Elastic erfüllt eine vereinheitlichende Funktion, indem es Behörden einen vollständigen Einblick in ihre Daten sowie die Möglichkeit gibt, sie aufzunehmen, zu organisieren, darauf zuzugreifen und sie zu analysieren.
Drei Elastic-Features zeichnen Elastic aus:
Clusterübergreifende Suche (Cross-Cluster Search, CCS), mit der Sie eine einzelne Suchanforderung für einen oder mehrere Remotecluster ausführen können
Durchsuchbarer Snapshot, der Ihnen eine kostengünstige Möglichkeit bieten, auf selten genutzte, historische Daten zuzugreifen und diese abzufragen
Rollenbasierte Zugriffssteuerung, die integrierte Sicherheit bietet
Der Daten-Mesh-Ansatz von Elastic kann auch als Grundlage für moderne Sicherheits-Frameworks wie Zero Trust dienen und neue Möglichkeiten für datengesteuerte Vorgänge eröffnen.
Erfahren Sie mehr darüber, wie Elastic Teams in Behörden, im Gesundheitswesen und im Bildungswesen dabei hilft, den Wert ihrer Daten durch Geschwindigkeit, Umfang und Relevanz zu maximieren.
Entdecken Sie weitere Ressourcen zum Daten-Mesh im öffentlichen Sektor
Die Entscheidung über die Veröffentlichung der in diesem Blogeintrag beschriebenen Leistungsmerkmale und Features sowie deren Zeitpunkt liegt allein bei Elastic. Es ist möglich, dass noch nicht verfügbare Leistungsmerkmale oder Features nicht rechtzeitig oder überhaupt nicht veröffentlicht werden.
In diesem Blogpost haben wir möglicherweise generative KI-Tools von Drittanbietern verwendet oder darauf Bezug genommen, die sich im Besitz ihrer jeweiligen Eigentümer befinden und von diesen betrieben werden. Elastic hat keine Kontrolle über die Tools von Drittanbietern und wir übernehmen keine Verantwortung oder Haftung für deren Inhalt, Betrieb oder Verwendung, noch für Verluste oder Schäden, die aus Ihrer Verwendung solcher Tools entstehen können. Gehen Sie vorsichtig vor, wenn Sie KI-Tools mit persönlichen, sensiblen oder vertraulichen Daten verwenden. Alle Daten, die Sie eingeben, können für das Training von KI oder andere Zwecke verwendet werden. Es gibt keine Garantie dafür, dass Informationen, die Sie bereitstellen, sicher oder vertraulich behandelt werden. Setzen Sie sich vor Gebrauch mit den Datenschutzpraktiken und den Nutzungsbedingungen generativer KI-Tools auseinander.
Elastic, Elasticsearch, ESRE, Elasticsearch Relevance Engine und zugehörige Marken, Waren- und Dienstleistungszeichen sind Marken oder eingetragene Marken von Elastic N.V. in den USA und anderen Ländern. Alle weiteren Marken- oder Warenzeichen sind eingetragene Marken oder eingetragene Warenzeichen der jeweiligen Eigentümer.
Teilen
- Share on Twitter
Auf Twitter teilen
- Share on LinkedIn
Auf LinkedIn teilen
- Share on Facebook
Auf Facebook teilen
- Share by Email
Per E-Mail teilen
- Print this page
Drucken