
Kubernetes 监测可覆盖您现有的工作环境
仪表板、警报、SLO、ML 作业、用于 AI 主导的调查和补救的代理技能,以及 MCP 应用——连接后即可立即使用。智能体 AI 可识别异常情况、调查事件并自动进行修复,以便您能够更快地规划容量和解决问题。

以极低的成本实现高基数性能
Elastic Observability 解决了 SRE 寻求更佳基础设施监测解决方案的两大难题:Datadog 的自定义指标费用,以及 Grafana 碎片化堆栈在每次事件发生时强制执行的手动关联工作。由于我们优先采用 OpenTelemetry 并原生支持 Prometheus,因此您可以保留您喜爱的工作流,而无需牺牲性能或数据保留率。




Kubernetes 监测实践
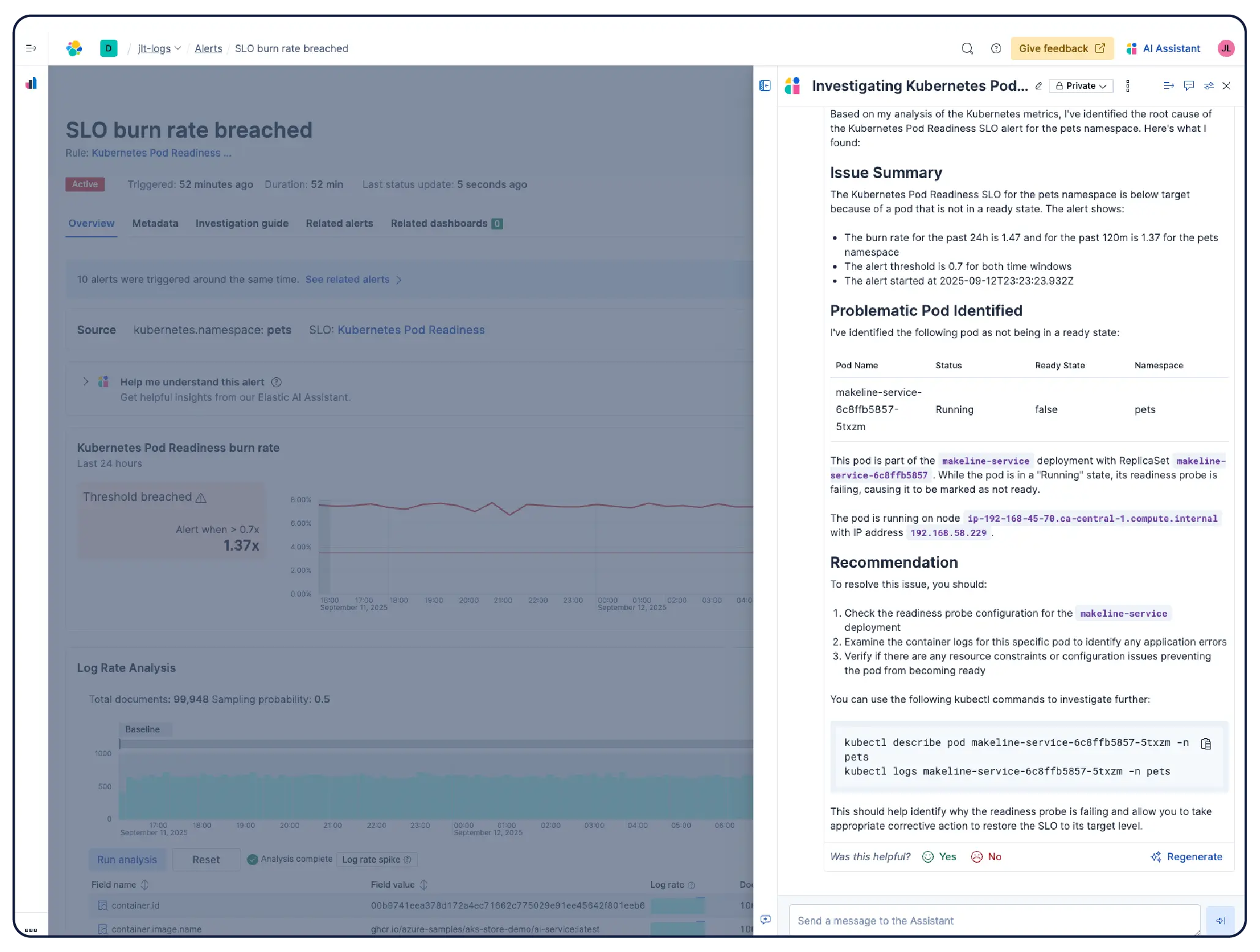
大规模监测基础设施。AI 主导的调查通过关联应用、Kubernetes 和云层之间的信号,自动发现根本原因并提出修复建议,无需人工排查。
Elastic 会自动构建并持续更新您的 Kubernetes 环境模型,包括节点、Pod、服务和依赖项。您可以跟踪 SLO 和错误预算,并利用智能体 AI 从症状直接定位到根本原因,而无需再翻阅复杂的仪表板。
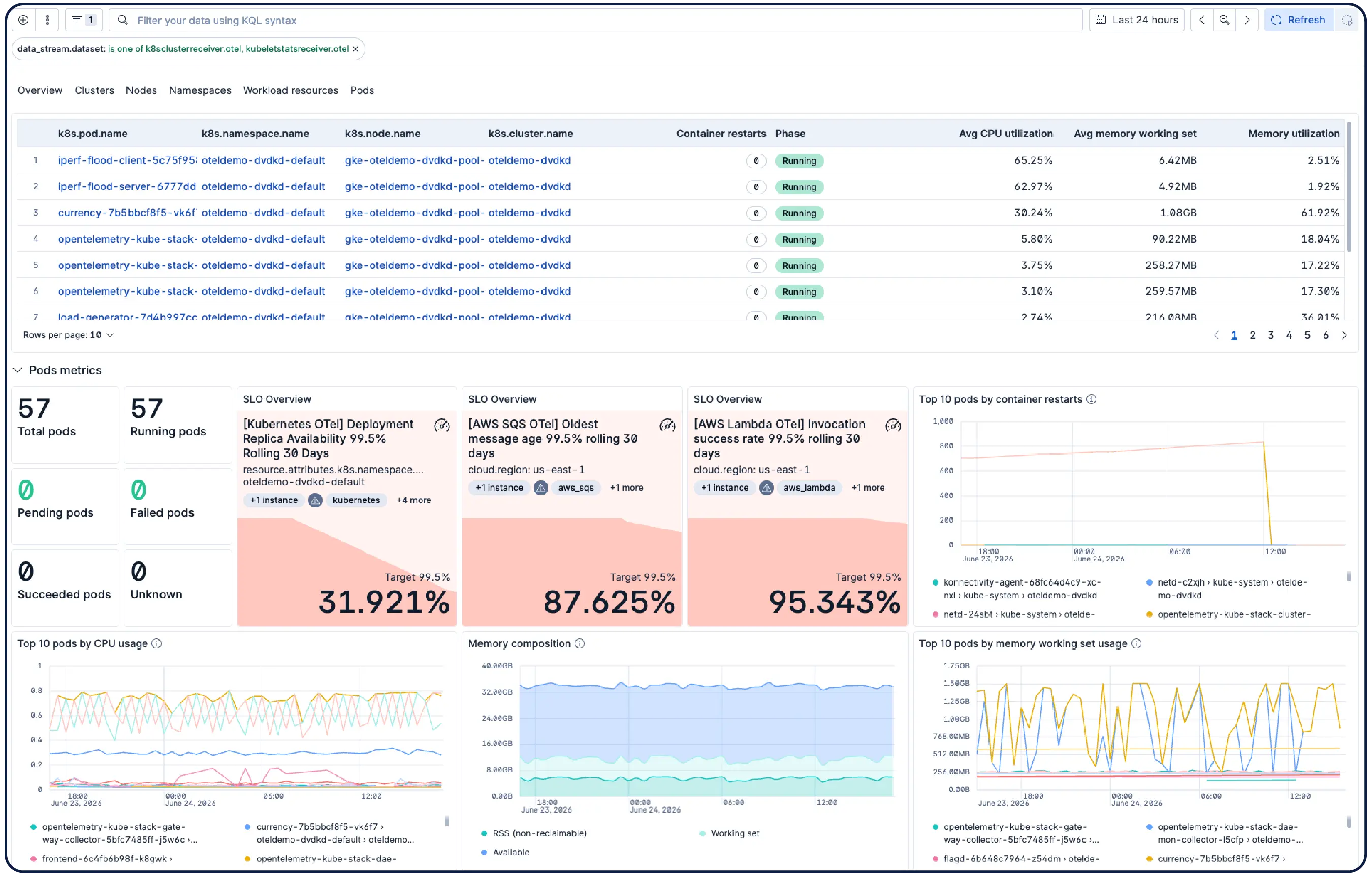
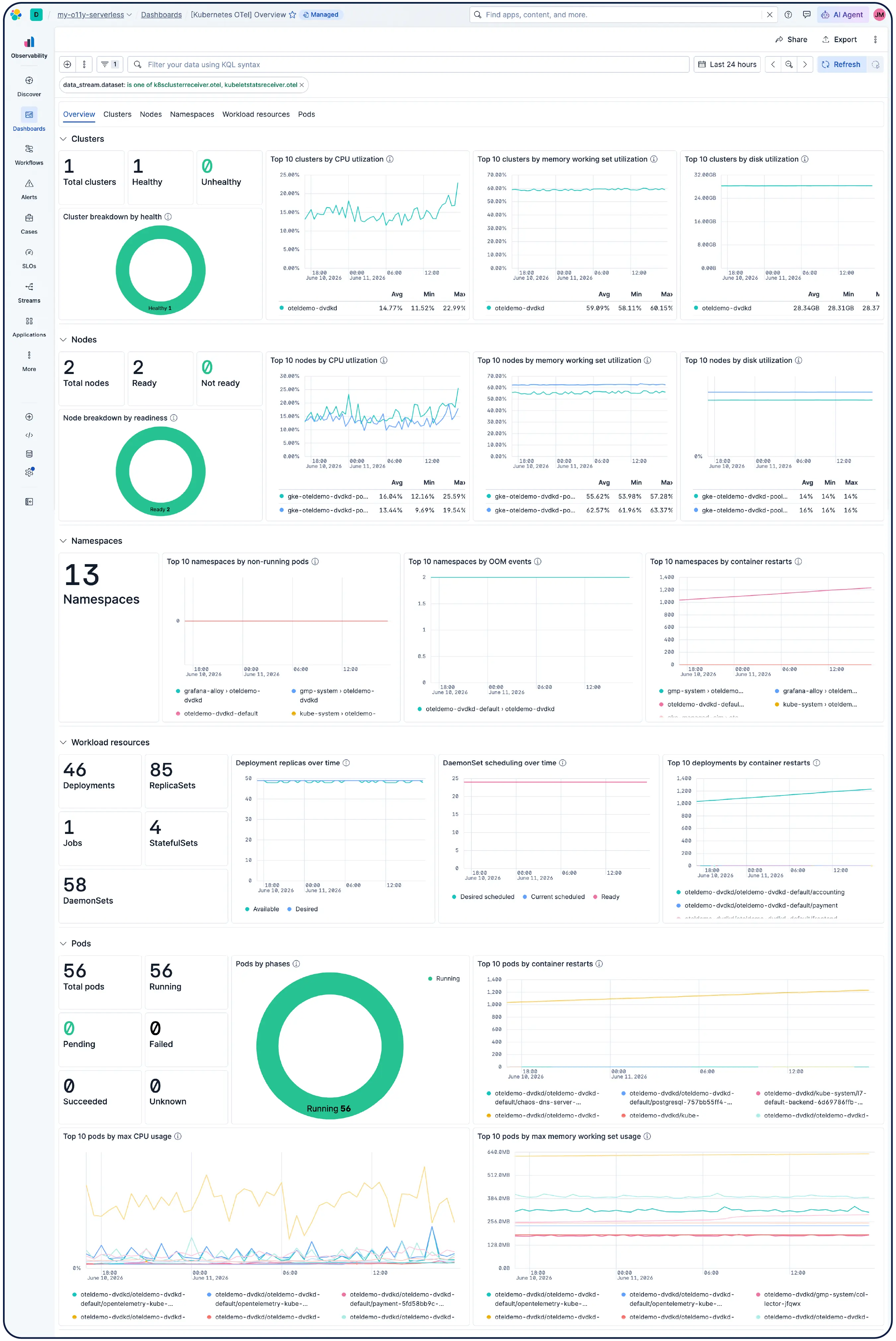
轻松扩展 Kubernetes
其他监控平台会让你在所需数据和可承受的成本之间做出选择。而 Elastic 则让你两者兼得。全面了解 Kubernetes 集群的每一层——节点、控制平面和工作负载——而无需承担运营开销或做出权衡。
Elastic
其他供应商
可预测的定价,长期以全分辨率保留——无基数惩罚,无强制汇总。
按主机计费是标准做法。每次自动扩展事件都按当月的节点峰值数量计费,而不是按平均使用量计费。
磁盘上的列式存储意味着不存在内存容量上限。可扩展到高基数的 Kubernetes 和云环境,而不会出现 OOM 瓶颈。
内存索引意味着基数峰值会在最不恰当的时候达到计费或性能限制。
对所有 Pod 和节点日志进行全文本搜索。在任何日志中查找任何字符串,无需预定义标签。
大多数供应商只对日志标签进行索引。如果在事件发生前没有定义标签,则在事件发生期间无法搜索该标签。
ES|QL 可在一个语句中查询日志、指标和追踪信息。在不切换工具或语言的情况下,将 Pod CPU 的峰值与导致该峰值的日志行关联起来。
针对每种信号类型使用不同的查询语言——一种用于日志,一种用于指标,一种用于跟踪——这意味着在你最不需要的时候进行上下文切换。
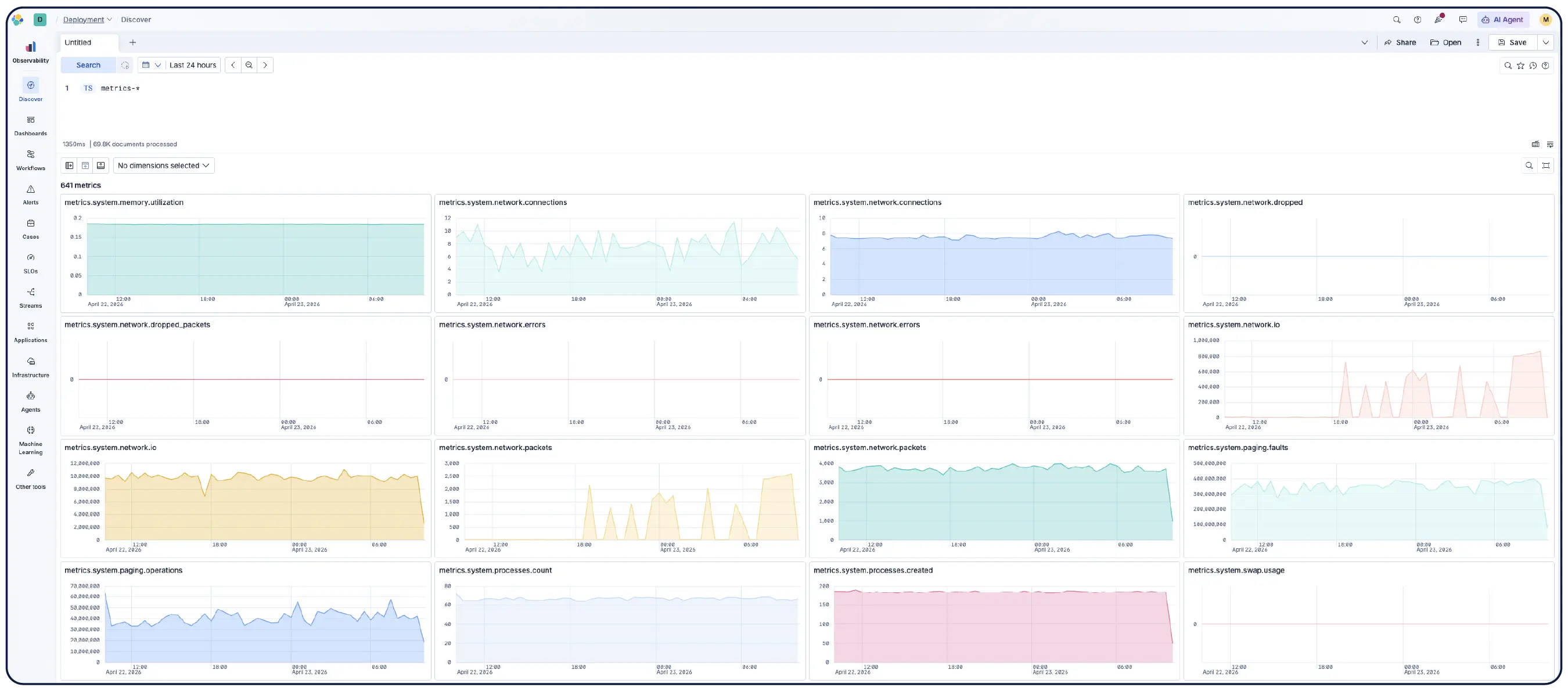
日志、指标和跟踪数据以 OpenTelemetry 格式原生摄取。您可以保留现有的工具,也可以使用 Elastic 完全上游化的发行版以获得生产级支持。
OTel 的检测工作通过专有后端进行路由,或在基础配额之上按自定义指标计费——这对您的团队已经采用的开放标准是不利的。
100 多个 ML 作业在 Kubernetes 指标和日志上自动运行。简单易用,适合初学者;可高度定制,满足专家需求。
异常检测需要手动配置监测或仅限于预定义模式。
Elastic Cloud、自我管理或混合云——EKS、GKE、AKS、本地部署、气隙环境。无论集群在何处运行,都使用同一个平台。
许多供应商仅提供 SaaS 服务。如果您的集群在本地部署或受监管环境中运行,那么在评估开始之前您就已无计可施。
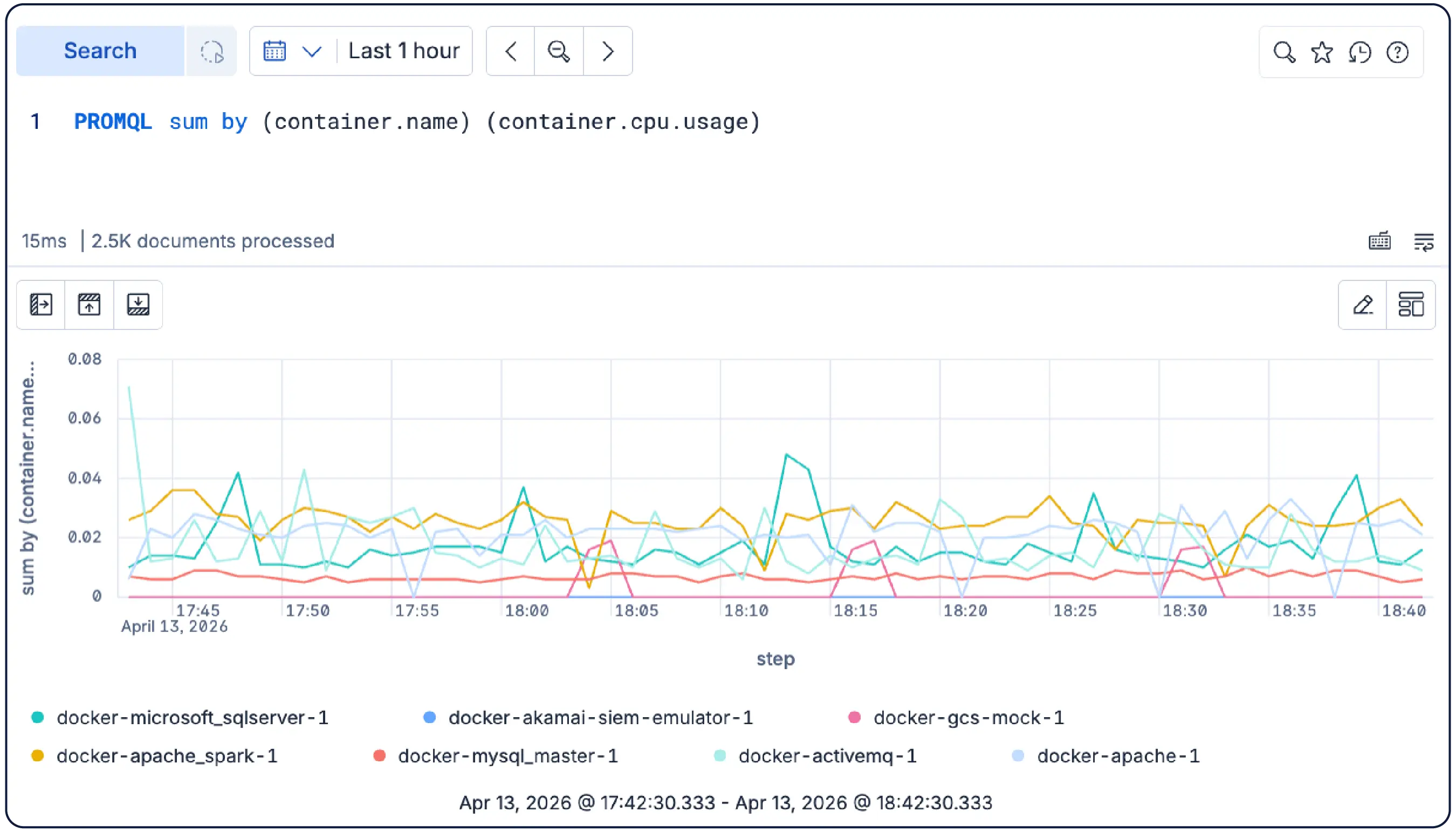
模式中立、开源,并基于开放标准构建——优先支持 OTel,原生兼容 Prometheus,支持 PromQL。以您偏好的格式存储数据,并直接进行查询。无需翻译,无需锁定。
专有智能体和后端是常态。更换供应商意味着需要重新配置整个技术栈。
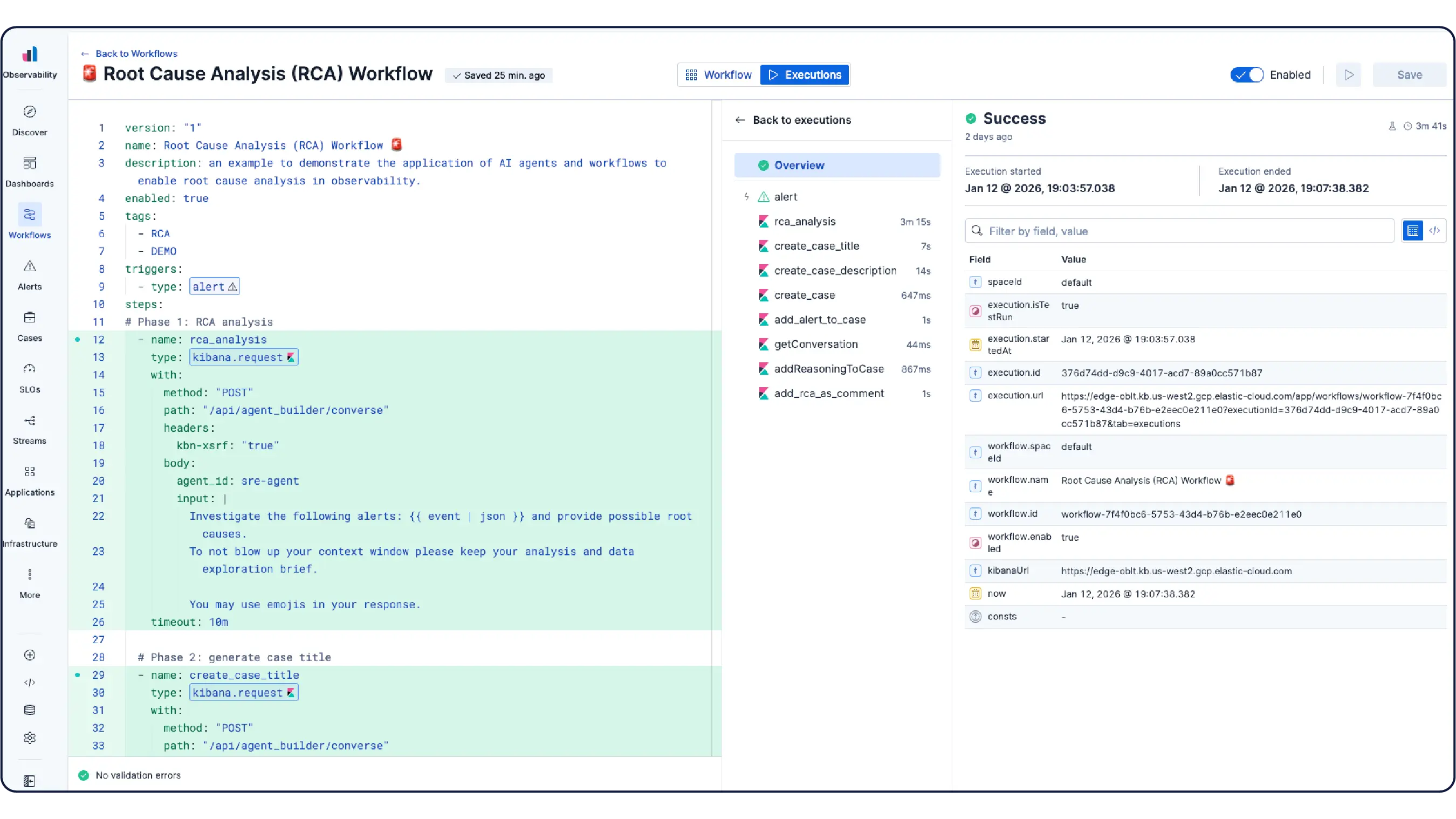
AI 分析您的指标、日志和跟踪,以快速找出根本原因并指导修复——无需手动深入仪表板。
AI 通常在分散的后端运行,而不是在统一的高性能数据存储中运行,这限制了它可以关联的内容和行动的速度。
了解像您这样的公司选择 Elastic Observability 的原因
客户聚焦

Comcast 每天通过 Elastic 摄取 400 TB 的数据,以监测服务并加速根本原因分析,确保一流的客户体验。
客户聚焦

Zooplus 使用 Elastic 监测 2,500 个微服务、20,000 个容器、600 个 AWS 账户(包含 70 个 AWS 服务)和 40 个 Kubernetes 集群。
客户聚焦

Informatica 将其整个日志工作负载迁移到 Elastic,涵盖 100 多个应用程序和 300 多个 Kubernetes 集群,从而降低了成本并减少了 MTTR。
加入聊天
加入 Elastic 的全球社区,参与开放对话与协作。


.jpg)

常见问题
什么是 Kubernetes 监测?
什么是 Kubernetes 监测?
Kubernetes 监控利用指标、日志和追踪信息来跟踪集群(包括节点、Pod、命名空间以及运行在其上的工作负载)的健康状况和性能。当出现问题时,你需要在服务不断动态变化、短暂存在的环境中快速定位根本原因。
Elastic 支持哪些 Kubernetes 发行版?
Elastic 支持哪些 Kubernetes 发行版?
Elastic 支持 KS、AKS、GKE 和自管理集群,并可在所有这些集群中实现动态自动发现。
为什么 Elastic Kubernetes 监控集成包含了这么多功能?
为什么 Elastic Kubernetes 监控集成包含了这么多功能?
因为 Kubernetes 监测中最困难的部分并非连接集群,而是构建仪表板、编写告警规则、配置 ML 作业以及随着集群变化持续维护所有内容所花费的时间。Elastic 集成了所有这些功能,让您从第一天起就能进行监测,而不是等到第三十天才开始。
智能体 AI 如何帮助处理 Kubernetes 事件?
智能体 AI 如何帮助处理 Kubernetes 事件?
Elastic 的 AI 智能体无需手动关联跨 Pod、服务和云层的仪表板,即可自动分析遥测数据,调查问题、找出根本原因并执行补救措施——同时利用 ML 模型以及来自运行手册和知识库的上下文。
Elastic 如何处理高基数 Kubernetes 指标?
Elastic 如何处理高基数 Kubernetes 指标?
Elastic 通过其时序数据流 (TSDS) 架构处理高基数 Kubernetes 指标,该架构使用列式磁盘存储,而非内存中的倒排索引。与基于 Prometheus 的后端在 Pod 和命名空间标签基数激增时容易发生内存溢出 (OOM) 不同,Elastic 不设内存基数上限。指标可通过 Prometheus 远程写入或 OpenTelemetry 原生摄取,无需进行模式转换,并且自动降采样可在不牺牲查询精度的前提下控制长期存储成本。
Elastic 是否支持 kube-state-metrics?
Elastic 是否支持 kube-state-metrics?
Elastic 的 OpenTelemetry 原生收集器可开箱即用地处理 Kubernetes 状态指标,因此不需要 kube-state-metrics。
Elastic 的 Kubernetes 监控定价与竞争对手相比如何?
Elastic 的 Kubernetes 监控定价与竞争对手相比如何?
Elastic Observability 采用基于使用量的计费模式,不收取主机费用,也不按峰值流量计费。Datadog 的按主机计费模式则根据当月节点峰值数量对自动扩展事件进行计费,而非按平均使用量计费。自定义指标需要额外付费,最高可达平均账单的 52%。Elastic 的计费模式意味着临时性工作负载和高基数 Prometheus 环境不会在月底产生意外费用。
从 Datadog 或 Grafana 迁移的过程是怎样的?
从 Datadog 或 Grafana 迁移的过程是怎样的?
借助我们的迁移工具(目前处于技术预览阶段),迁移变得轻松便捷,该工具可自动转换您的仪表板和告警规则。原生支持 PromQL 和 OTel 意味着您现有的数据采集架构无需更改即可继续使用。大多数团队在第二天即可恢复正常运行。
Elastic Kubernetes 监控是否包含安全功能?
Elastic Kubernetes 监控是否包含安全功能?
是的。Elastic 的 Kubernetes 安全态势管理 (KSPM) 集成会根据 CIS 基准指南评估您的集群配置,并生成包含分步修复说明的评估结果。它支持 EKS 和自管理集群,每四小时自动评估一次,并且所有 Elastic Cloud 用户均可使用,因此监测性能的同一平台也会检查您的安全态势。此外,Elastic Defend for Containers (D4C) 集成使用 eBPF 监测运行容器内的进程和文件活动,为 Kubernetes 环境提供云原生运行时保护。