Stretching the Cloud: Flexibility in Elastic Cloud Deployments
Want to learn more about the differences between the Amazon Elasticsearch Service and our official Elasticsearch Service? Visit our AWS Elasticsearch comparison page.
On August 1, Elastic launched some exciting new features in Elasticsearch Service on Elastic Cloud that help users better match their workloads to their cloud infrastructure. In this post we’ll take a look at how some of these new features work in Elasticsearch Service and also how they can be set up and further customized in Elastic Cloud Enterprise.
Where We Came From
Elasticsearch Service is known for its ease of use when it comes to performing everyday tasks such as creating, upgrading, configuring, and scaling Elasticsearch deployments. Creating a highly available cluster from scratch takes minutes, and growing a cluster is just a few clicks. But while Elasticsearch provides a lot of flexibility in how it can be used, the Elasticsearch Service previously provided a homogeneous experience in terms of which types of machines were used under the covers, and which Elasticsearch roles could be assigned to those machines.
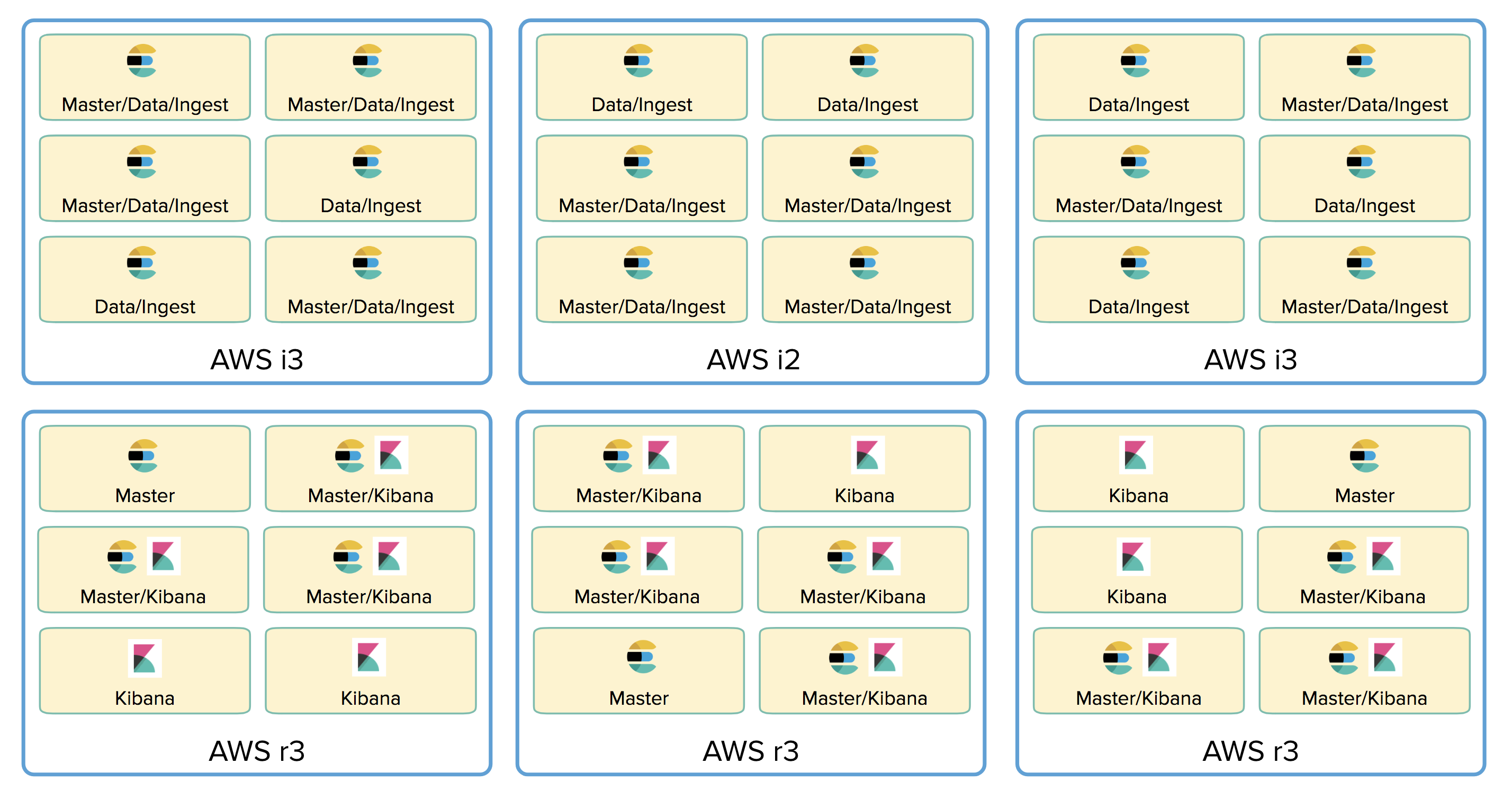
Additionally, Elasticsearch Service deployments have traditionally been all about Elasticsearch and Kibana, but we wanted to allow for additional products and solutions to be included in Elastic Cloud deployments, including machine learning and APM, and these called for different hardware than we typically used.
Where We Are At
Elasticsearch Service on Elastic Cloud now allows you to choose use case specific hardware profiles that match the way you want to use Elasticsearch. We currently offer four deployment profile options: I/O, compute, memory, and hot-warm.
The I/O optimized profile provides a balance of compute, memory, and SSD-based storage that is suitable for general purpose workloads, or workloads with frequent write operations. The compute optimized profile is suitable for CPU-intensive workloads where more computing power is needed relative to storage. The memory optimized profile is ideal for memory-intensive operations, such as frequent aggregations, where more memory is needed relative to storage. And the hot-warm profile is a cost-effective solution for storing time-based logs, where indices are migrated from I/O optimized to lower cost storage optimized hardware as they age.

When choosing a profile, the underlying AWS, GCP, or Azure machine types and hardware specs are described, so you always know what you’re getting and what performance to expect.
Customize Your Deployment
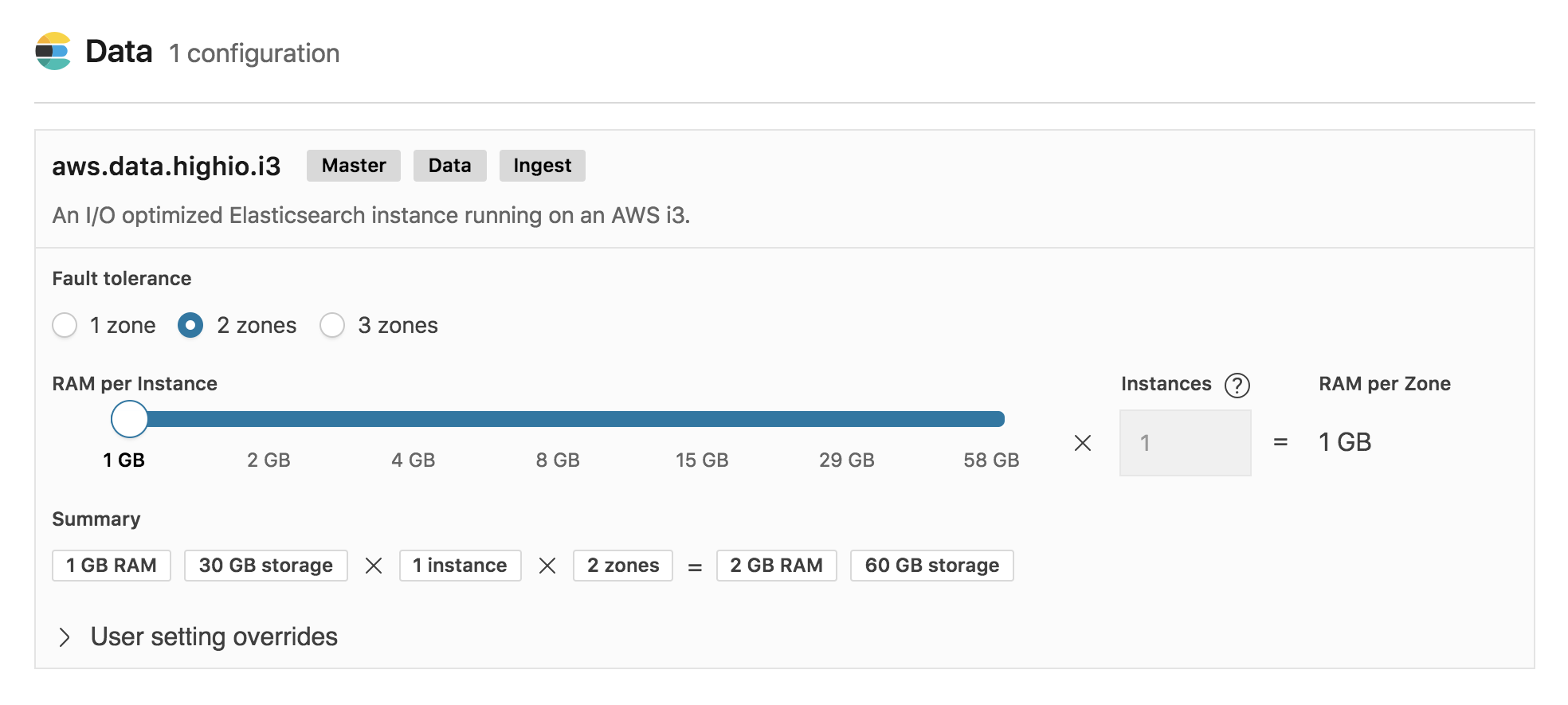
Choosing a hardware profile is only the first step in creating a deployment. You can also choose to customize your deployment by independently sizing and configuring the hardware on which different nodes and instances within your deployment will run. For example, for a larger deployment you may choose to configure dedicated master nodes. You can also choose to enable and run a dedicated machine learning node. And of course, you can independently specify the size and level of fault tolerance for your Elasticsearch nodes and Kibana instances.
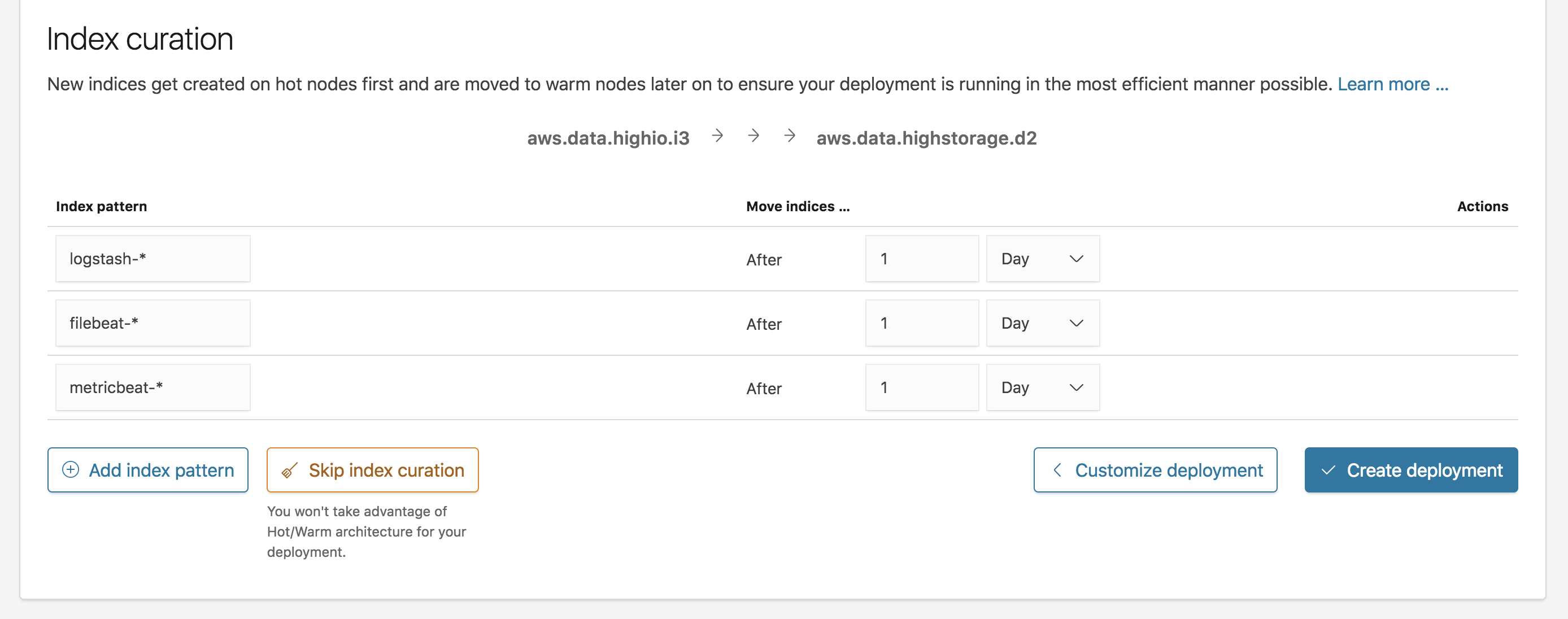
For hot-warm deployments you can also choose to configure index curation to automatically migrate indices from I/O optimized data nodes to storage optimized data nodes after they’ve reached a specified age. This architecture is well suited for storing time-based logs, as it allows you to take advantage of lower cost hardware for storing older indices that do not need to be frequently updated, while reserving your more performant hardware for newer indices that are under heavier I/O load. The index curation configuration allows you to specify a pattern to match the names of any indices you wish to be curated, along with the time period after which curation should take place for a new index.
Optimized Performance
However you customize your deployment, the machines that are used under the covers are matched to the hardware profile you choose. Overall, Elasticsearch Service now leverages a wider variety of hardware for deployments, and for the different roles within a deployment, providing a more optimized and cost-effective experience across the board.
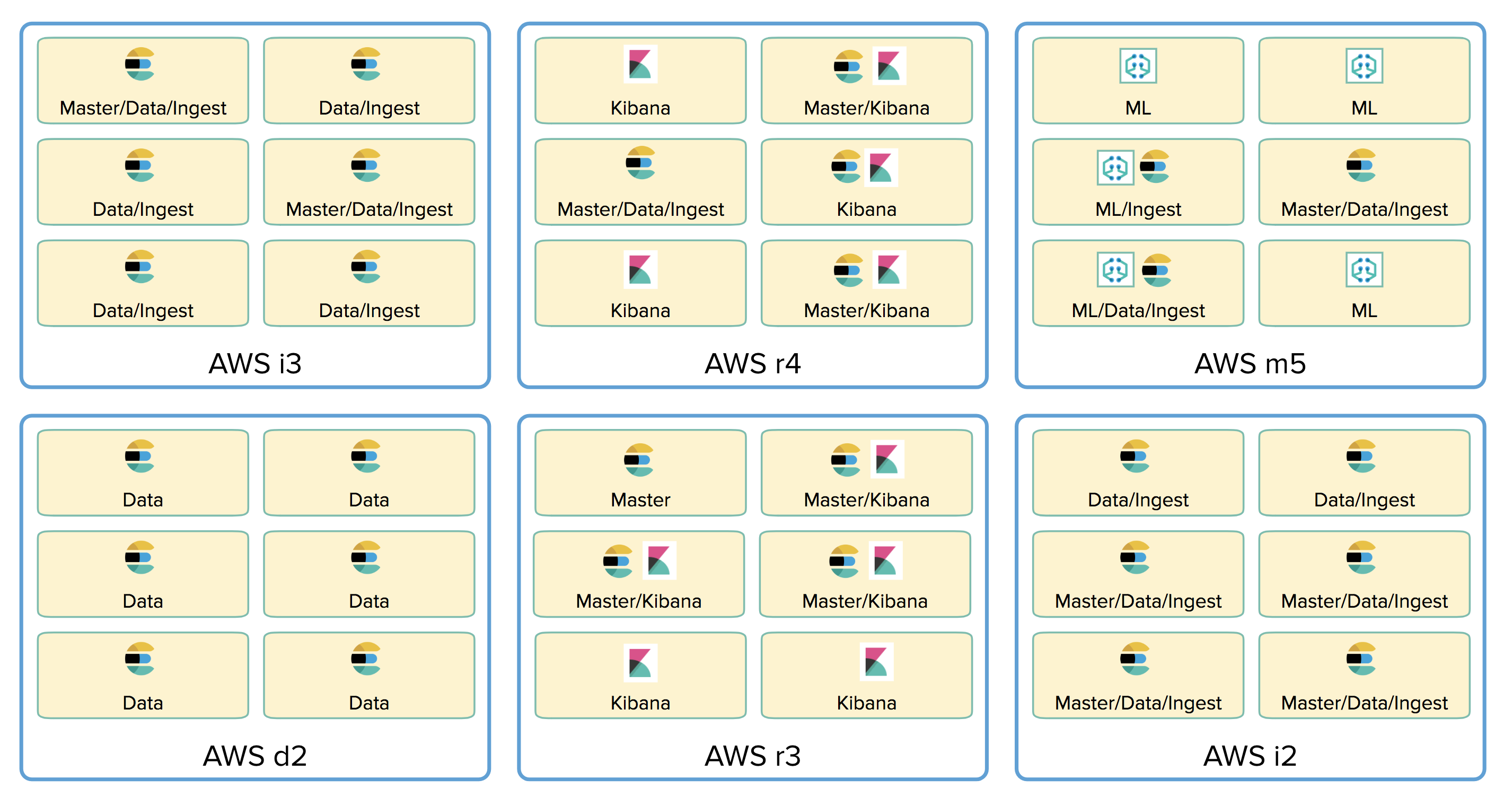
One of the optimizations that this separation of responsibilities onto different hardware allows for, is the ability for Elastic Cloud to route an Elasticsearch request that enters our public endpoint directly to the node that is most likely to process it. For example, read requests such as searches can be routed directly to data nodes. Write requests can be routed directly to ingest nodes. And cluster configuration requests can be routed directly to the master node.
A Peek Behind the Curtain
The features we’ve discussed here represent a new experience for users of the Elasticsearch Service on Elastic Cloud, but there’s another side of this functionality that a cloud administrator will experience, and in particular, an Elastic Cloud Enterprise administrator. The customization features introduced to Elasticsearch Service are set to be included in the next Elastic Cloud Enterprise release, so let’s take a peek at how things will work from the cloud administrator’s perspective.
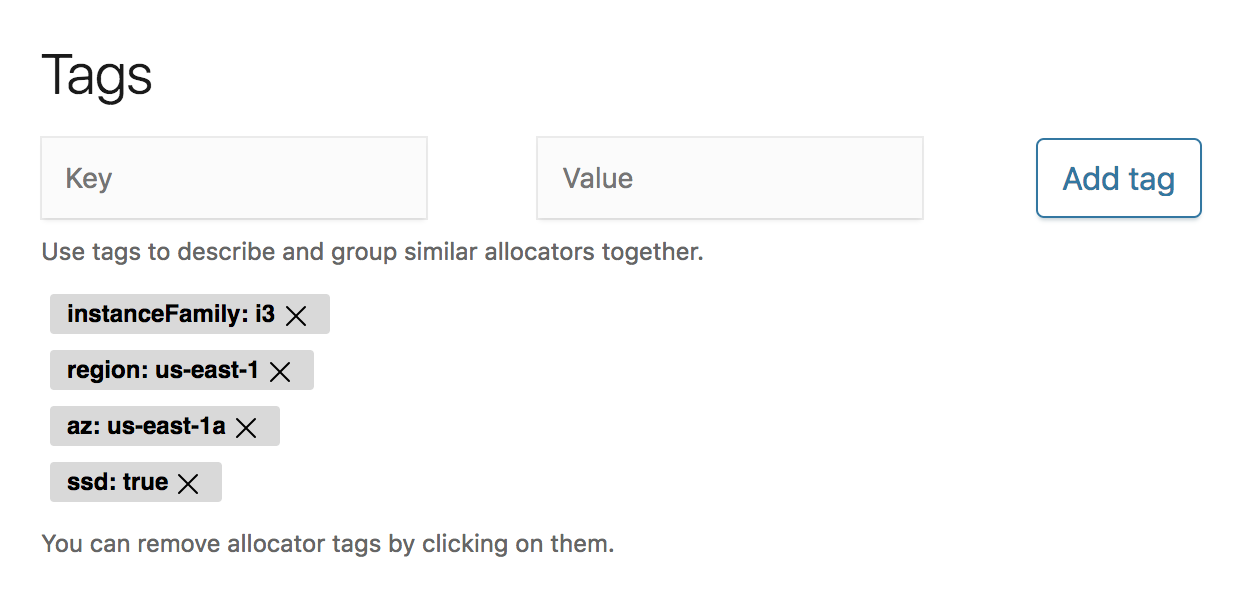
One of the first things an Elastic Cloud Enterprise administrator will notice in the next release is the ability to characterize available hardware for Elastic Stack deployments by tagging it. Tags are simple ways of describing the hardware, and are used later on to help determine which nodes and instances should be placed on what hardware.
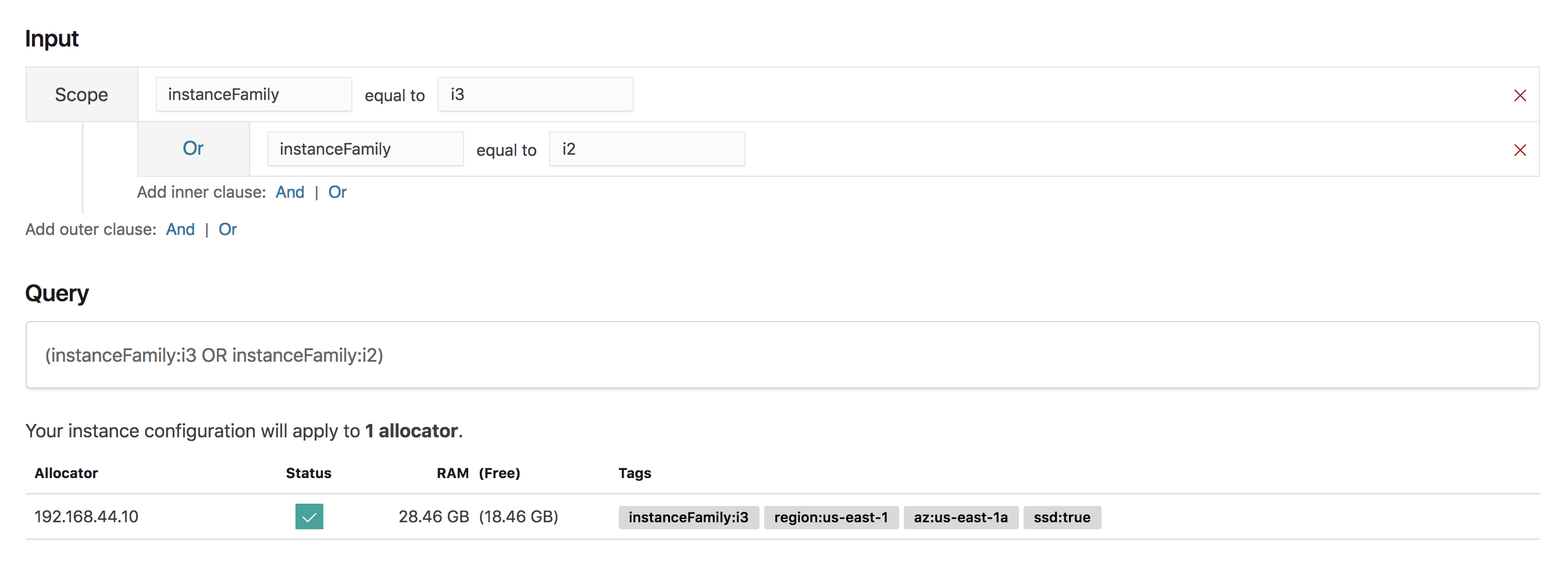
Next, an administrator can create instance configurations that represent the use of hardware for particular nodes or instances, or for a particular use case. The first part of this configuration involves expressing which machines you’d like the configuration to match. This is done by building an expression that matches the tags on machines.
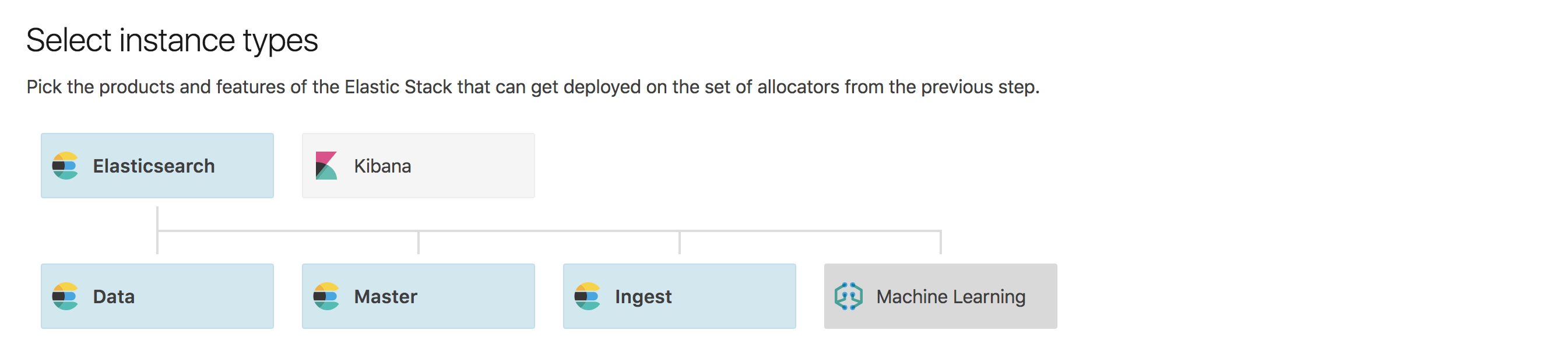
You can then specify the instance and node types that the configuration should support, as well as the supported memory and disk sizing for nodes or instances that use this configuration.

Finally, give your instance configuration a name that represents what it should be used for.
Tying it all Together
Having constructed some configurations to represent different use cases for different instance and node types, Elastic Cloud Enterprise administrators will have the ability to assemble them together into a template that can be used for creating entire deployments.
Creating a template is similar to creating a deployment but with a bit more power. To start, you can choose which types of nodes or instances, along with which instances configurations, are eligible to be included in deployments created from the template. The instance configurations you choose will drive the compatible sizes for each node or instance, and also will affect the hardware that they’re matched to. You can specify default sizing and fault tolerance for each of the nodes and instances in the deployment, and you can also configure default settings or plugins for deployments.
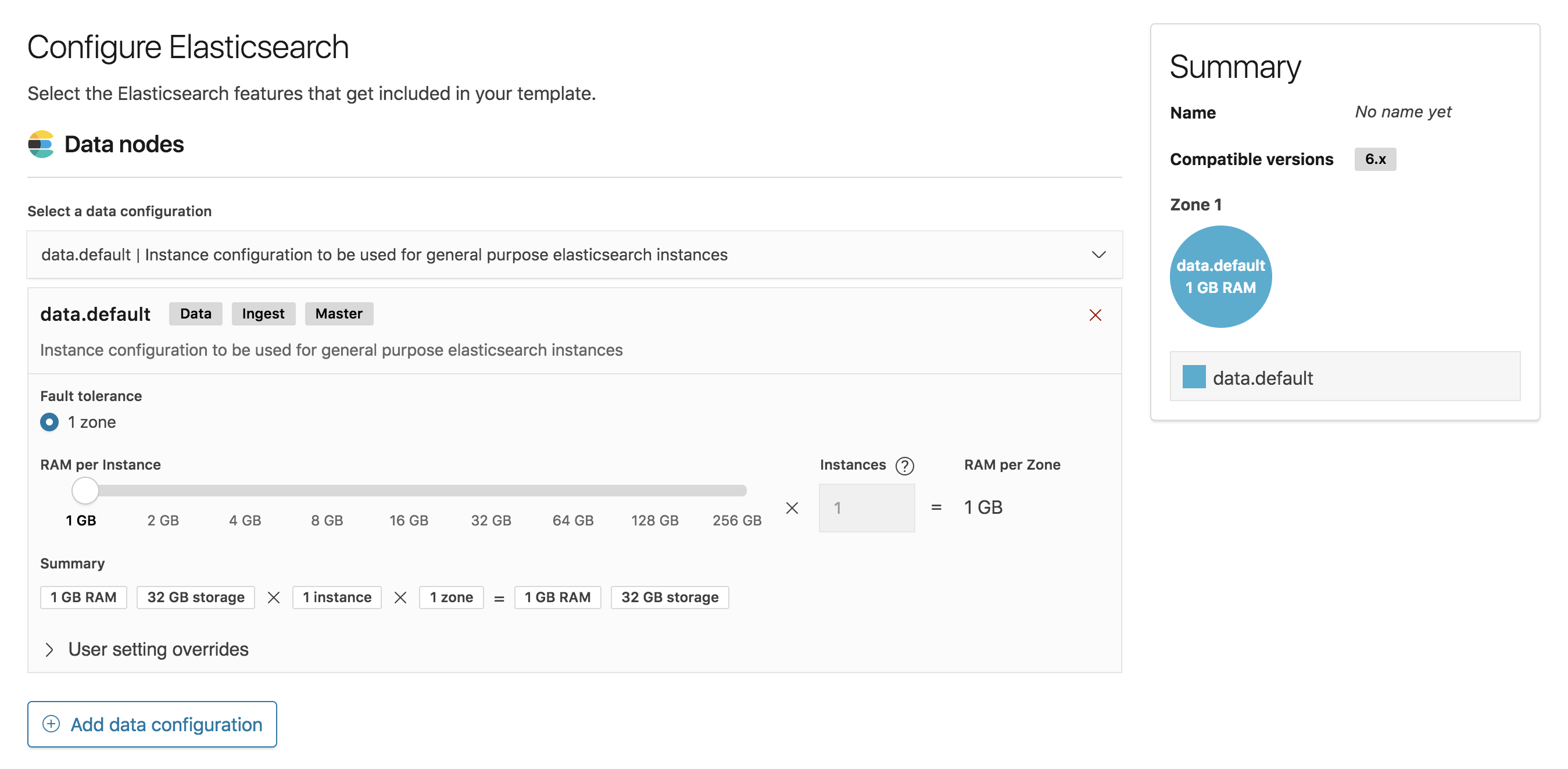
Hot-warm style deployment templates can be created by adding multiple data configurations to a template, and when multiple data configurations are present you can also specify index curation settings.
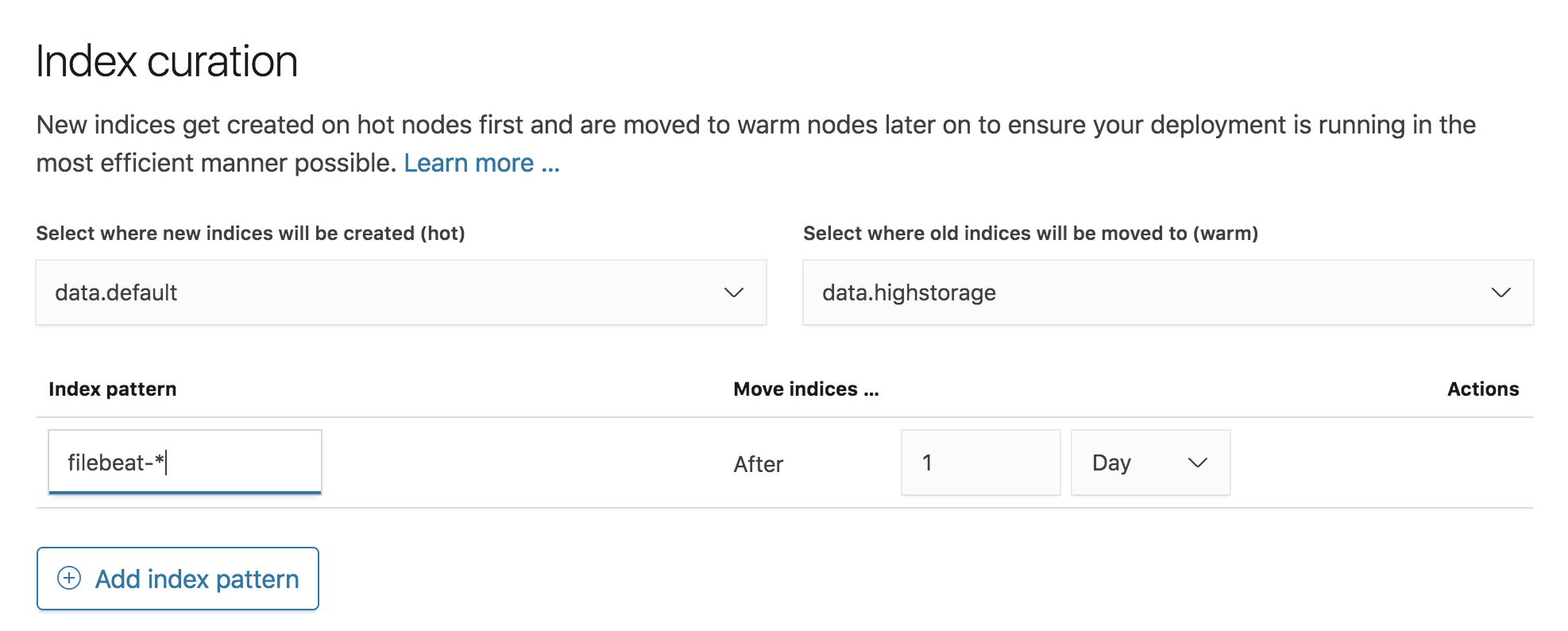
Give your template a name and now it’s ready to be used for creating deployments.
Summary
The new features in Elasticsearch Service on Elastic Cloud allow you to customize your deployments to match your use cases, including placing nodes and instances on different hardware as desired, and allowing users to create more efficient, cost-effective deployments than ever before. This same experience will be coming to soon to Elastic Cloud Enterprise, and will allow cloud administrators to more effectively manage their infrastructure than previously possible. We hope you try out these new features and tell us what you think.
Editor’s Note (September 3, 2019): This blog has been updated to include Microsoft Azure as a cloud provider for Elasticsearch Service on Elastic Cloud. For more information, please read the announcement blog.