Machine learning in cybersecurity: Detecting DGA activity in network data
In Part 1 of this blog series, we took a look at how we could use Elastic Stack machine learning to train a supervised classification model to detect malicious domains. In this second part, we will see how we can use the model we trained to enrich network data with classifications at ingest time. This will be useful for anyone who wants to detect potential DGA activity in their packetbeat data.
DGA detection with the Elastic Stack
A malicious program that infects a machine will often need a way to communicate back with a server controlled by the attacker — a so-called command & control (C&C or C2) server. To thwart defensive measures that block any hardcoded IP addresses or URLs, attackers use domain generation algorithms (DGAs). When malware needs to contact a C&C server, it will use the DGA to generate hundreds or thousands of candidate domains, and try to resolve an IP address for each. The attacker then has to register just one or a few of the domains generated by the DGA to be able to communicate with the infected machine. DGAs are seeded and randomized in different ways to make it even harder for defenders to block and detect them.
Because DGA activity usually involves DNS queries, it will often manifest itself in the DNS requests made from an infected machine. Packetbeat can collect DNS traffic and send it to Elasticsearch for analysis. In this blog post, we will look at how you can enrich the DNS query information in Packetbeat data with a score to indicate how malicious the domain is.

Inference processors and the ingest pipeline
In order to enrich Packetbeat data with predictions from a model trained to distinguish benign domains from malicious, we will need to configure an ingest pipeline with suitable inference processors. Inference processors offer users a way to use a model trained in the Elastic Stack (or a model trained in one of our supported external libraries) to make predictions on new documents as they are being ingested into Elasticsearch. In order to understand how all of these moving pieces fit together and what configurations are necessary, let’s briefly return to the first part of this blog.
In Part 1, we discussed the process for training a classification model to predict whether or not a given domain is malicious. One of the steps in this process is performing feature engineering on the training data — a set of known malicious and benign domains that our model will use to learn how to score new, previously unseen domains. The raw domains must be manipulated to extract features — unigrams, bigrams, and trigrams — that are useful for the model. The same feature engineering procedure must then be also applied to the domains in our Packetbeat data that we wish to score for maliciousness.
This is why, in addition to an inference processor, our ingest pipeline will also include Painless script processors to extract unigrams, bigrams, and trigrams from packetbeat DNS data at ingest time. A diagram featuring the full pipeline is illustrated in Figure 2.
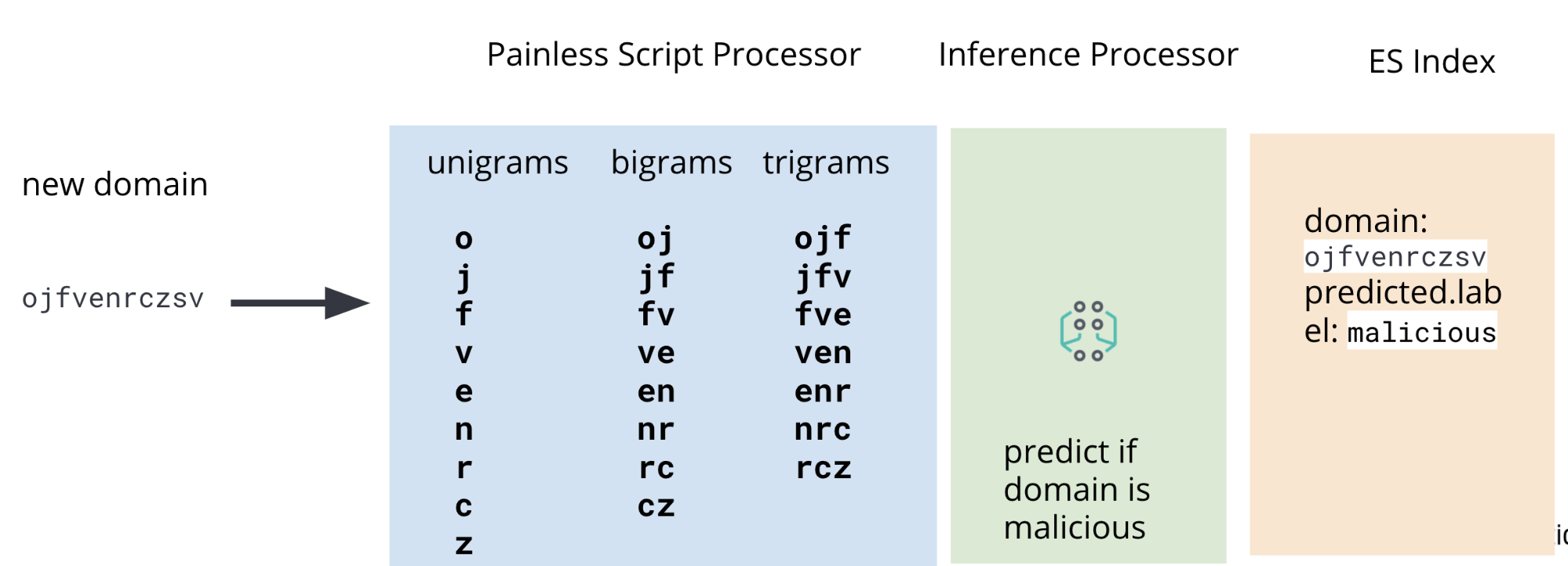
Within the Packetbeat data, the field we are interested in operating on is the DNS registered domain. Although there are some edge cases where this field will not contain the domain of interest, it will be good enough to illustrate the use case for the purposes of this blog. The image in Figure 3 illustrates the fields of interest in an example Packetbeat document.

dns.question.registered_domainIn order to extract unigrams, bigrams, and trigrams from dns.question.registered_domain, we will need to use a Painless script like the one in Figure 4.
POST _scripts/ngram-extractor-packetbeat
{
"script": {
"lang": "painless",
"source": """
String nGramAtPosition(String fulldomain, int fieldcount, int n){
String domain = fulldomain.splitOnToken('.')[0];
if (fieldcount+n>=domain.length()){
return ''
}
else
{
return domain.substring(fieldcount, fieldcount+n)
}
}
for (int i=0;i<ctx['dns']['question']['registered_domain'].length();i++){
ctx['field_'+Integer.toString(params.ngram_count)+'_gram_'+Integer.toString(i)] = nGramAtPosition(ctx['dns']['question']['registered_domain'], i, params.ngram_count)
}
"""
}
}
After the necessary features are extracted, the document — still passing through the ingest pipeline — will go through the inference processor where the classification model we trained in the previous installment will use the extracted features to make a prediction. Finally, because we do not want to clutter our index with all of the extra features needed by the model, we will add a series of Painless script processors to remove the fields containing the unigrams, bigrams, and trigrams.
Thus, at the end of the ingest pipeline, what we will ingest is a Packetbeat document with the new extra fields that contain the result of the ML predictions. A sample ingest pipeline configuration is shown in Figure 5. For full details, please refer to the examples repository.
PUT _ingest/pipeline/dga_ngram_expansion_inference
{
"description": "Expands a domain into unigrams, bigrams and trigrams and make a prediction of maliciousness",
"processors": [
{
"script": {
"id": "ngram-extractor-packetbeat",
"params":{
"ngram_count":1
}
}
},
{
"script": {
"id": "ngram-extractor-packetbeat",
"params":{
"ngram_count":2
}
}
},
{
"script": {
"id": "ngram-extractor-packetbeat",
"params": {
"ngram_count":3
}
}
},
{
"inference": {
"model_id": "dga-ngram-job-1587729368929",
"target_field": "predicted_label",
"field_mappings":{},
"inference_config": { "classification": {"num_top_classes": 2} }
}
},
{
"script": {
"id": "ngram-remover-packetbeat",
"params":{
"ngram_count":1
}
}
},
{
"script": {
"id": "ngram-remover-packetbeat",
"params":{
"ngram_count":2
}
}
},
{
"script": {
"id": "ngram-remover-packetbeat",
"params": {
"ngram_count":3
}
}
}
]
}
Because not every Packetbeat document will record a DNS request, we need to make the ingest pipeline execute conditionally only if the required DNS fields are present and non-empty in the ingested document. We can do this by using a Pipeline processor (see configuration in Figure 6) to check if the desired fields are present and populated and then redirect the processing of the document to the dga_ngram_expansion_inference pipeline we defined in Figure 5. While the configuration below is suitable for a prototype, for a production use case you will need to consider error handling in the ingest pipeline. For full configurations and instructions, please see the examples repository.
PUT _ingest/pipeline/dns_classification_pipeline
{
"description": "A pipeline of pipelines for performing DGA detection",
"version": 1,
"processors": [
{
"pipeline": {
"if": "ctx.containsKey('dns') && ctx['dns'].containsKey('question') && ctx['dns']['question'].containsKey('registered_domain') && !ctx['dns']['question']['registered_domain'].empty",
"name": "dga_ngram_expansion_inference"
}
}
]
}
Deploying the DGA Model without Packetbeat
In many environments, it might not be possible to use Packetbeat to collect network data. In this case, it is possible to use the inference processor and the ingest pipeline that we created in the first part of this blog post in various ways to enrich your existing data with results from your supervised machine learning model. In the section below, we will show you how to modify your index settings to make sure that any network data ingested into your index passes through the ingest pipeline that contains our DGA detecting machine learning model.
Setting an ingest pipeline in index settings
Suppose you have an index for your network data that is being populated through various ingest methods and you want each of the documents being ingested into the index to pass through the DGA ingest pipeline that we created in the first part of the document. In this case, when you are creating your index, you can modify the index settings and the field index.final_pipeline. Set the value of the index.final_pipeline index to the name of your ingest pipeline that contains the script processors and the inference processors. In the example ingest pipeline shown in the previous section, this setting would look like this index.final_pipeline = dns_classification_pipeline.
Using anomaly detection as second order analytics on the inference results
The model we trained in the first part of the series had a 2% false positive rate. While this sounds quite low, one has to keep in mind that DNS traffic usually has a high volume. Therefore, even with a 2% false positive rate, a large number of queries may be scored as malicious. One way to reduce the number of false positives would be to work on further feature engineering schemes. Another would be to use anomaly detection on the results of our classification. Let’s explore how to do the latter in the Elastic Stack.
The first thing to observe is that if we take the enriched Packetbeat documents and plot the count of Packetbeat documents labeled as malicious against time, what we get is a time series (Figure 7).
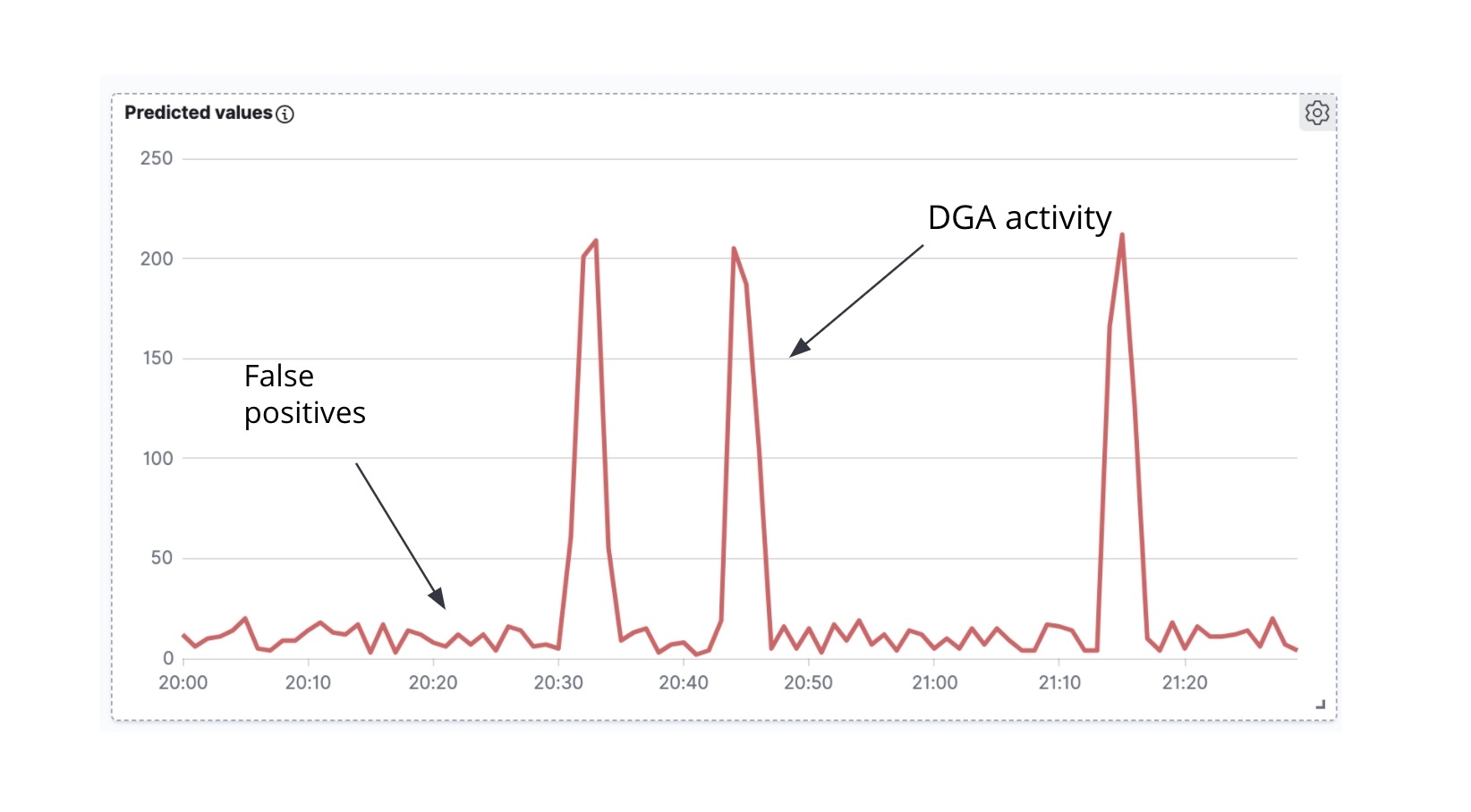
The second thing to note is that often (though there are exceptions) when a DGA malware is actively trying to communicate with the C&C server, it tends to generate a wave of DNS requests at once (i.e. the malware cycles through many of the domains generated by the algorithm, trying to resolve the IP address of each of the domains). In the time series analysis of predicted malicious domains over time (Figure 6), we can see peaks of activity and small noise in between the peaks. The peaks indicate that our classification model has classified many domains as malicious in a short span of time and we are thus likely dealing with a true DGA. In contrast, the background noise in between the peaks is most likely the result of false positives. It is precisely this intuition that we will seek to encode in a high_count anomaly detection job for this time series.
If we overlay the anomaly detection swimlane with the time series in Figure 7, we will see that we get anomaly alerts corresponding to the peaks in the time series (the true DGA activity) and no alerts in the intervals between the peaks (the background noise of false positives).
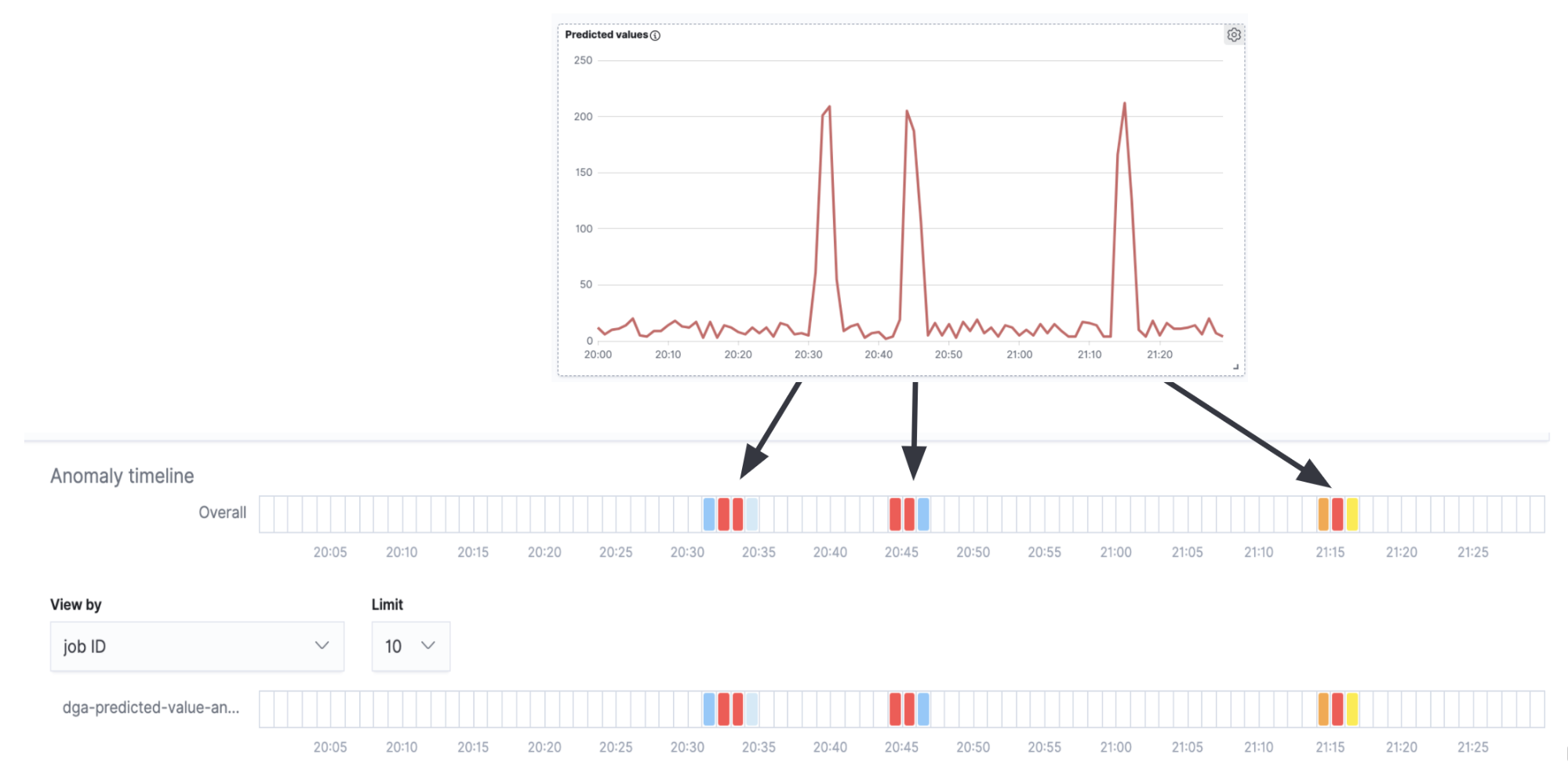
Although this is a very simple example and for a production use case would likely require more fine-tuning and configuration, it nevertheless shows that anomaly detection jobs can be effectively used as a second order analysis on inference results.
Conclusion
In this post, we’ve used a trained classification model to enrich network data (Packetbeat documents) at ingest time. The enrichment process, which is facilitated by the inference processor and ingest pipelines, adds a predicted label to each domain queried during a DNS request. This shows how likely the domain is to be malicious. Moreover, to reduce false positive alerts, we also examined how to use an anomaly detection job on the results of inference. We are also planning to provide a curated configuration and models for DGA detection in Elastic SIEM.
If you’d like to give this a try for yourself with your own network data, you can spin up a 14-day free trial of Elasticsearch Service to start ingesting and analyzing. You can also try machine learning free for 30 days by downloading the Elastic Stack locally and starting a trial license. Or, get started with the free and open Elastic SIEM to begin protecting your data today.