Vous débutez avec Elasticsearch ? Participez à notre webinaire Premiers pas avec Elasticsearch. Vous pouvez aussi démarrer un essai gratuit sur le cloud ou tester Elastic dès maintenant sur votre machine.
La taille du tas est la quantité de RAM allouée à la machine virtuelle Java d'un nœud Elasticsearch.
Depuis la version 7.11, Elasticsearch définit par défaut automatiquement la taille du tas de la JVM en fonction des rôles et de la mémoire totale d'un nœud. L'utilisation du dimensionnement par défaut est recommandée pour la plupart des environnements de production. Toutefois, si vous souhaitez définir manuellement la taille du tas de votre JVM, vous devez en règle générale définir -Xms et -Xmx sur la MÊME valeur, soit 50% de votre RAM totale disponible, avec un maximum (approximatif) de 31 Go.
Une taille de tas plus importante permet à votre nœud de disposer de plus de mémoire pour les opérations d'indexation et de recherche. Cependant, votre nœud a également besoin de mémoire pour la mise en cache, de sorte que l'utilisation de 50% maintient un équilibre sain entre les deux. Pour cette même raison, en production, vous devez éviter d'utiliser d'autres processus gourmands en mémoire sur le même nœud qu'Elasticsearch.
En règle générale, l'utilisation du tas suit un schéma en dents de scie, oscillant entre 30 et 70% du tas maximum utilisé. En effet, la JVM augmente régulièrement le pourcentage d'utilisation du tas jusqu'à ce que le processus de ramassage des ordures libère à nouveau de la mémoire. Une forte utilisation du tas se produit lorsque le processus de ramassage des ordures n'arrive pas à suivre. Un indicateur d'une utilisation élevée du tas est lorsque le ramasse-miettes est incapable de réduire l'utilisation du tas à environ 30%.

Dans l'image ci-dessus, vous pouvez voir une dent de scie normale du tas de la JVM.
Vous verrez également qu'il existe deux types de ramassage d'ordures, le jeune et l'ancien GC.
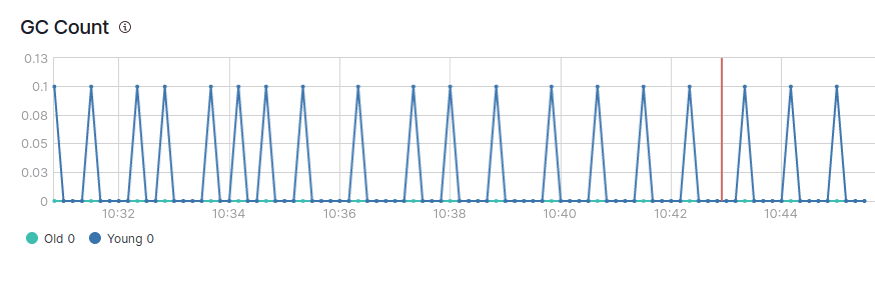
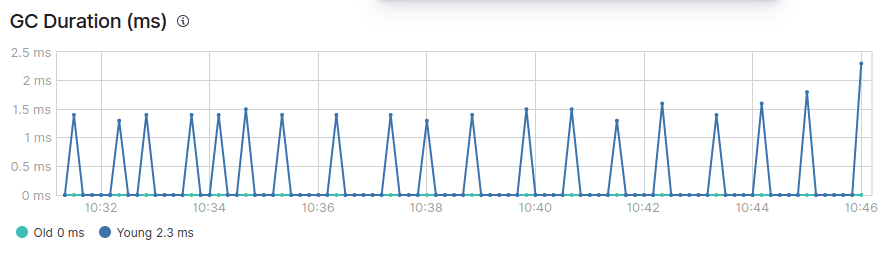
Dans une JVM en bonne santé, le ramassage des ordures devrait idéalement répondre aux conditions suivantes :
- Le jeune GC est traité rapidement (dans les 50 ms).
- Le jeune GC n'est pas exécuté fréquemment (environ 10 secondes).
- L'ancienne CG est traitée rapidement (en moins d'une seconde).
- L'ancienne CG n'est pas exécutée fréquemment (une fois toutes les 10 minutes ou plus).
Comment résoudre le problème d'une utilisation trop importante de la mémoire du tas ou d'une performance non optimale de la JVM ?
Plusieurs raisons peuvent expliquer l'augmentation de l'utilisation de la mémoire du tas :
La surexploitation
Veuillez consulter le document sur le surdimensionnement ici.
Grandes tailles d'agrégation
Afin d'éviter des agrégations trop importantes, limitez au maximum le nombre d'agrégats (taille) dans vos requêtes.
Vous pouvez utiliser la journalisation lente des requêtes (slow logs) et la mettre en œuvre sur un index spécifique en procédant comme suit.
Les requêtes qui prennent beaucoup de temps pour donner des résultats sont probablement celles qui consomment beaucoup de ressources.
Taille excessive de l'index en vrac
Si vous envoyez des requêtes volumineuses, cela peut être la cause d'une consommation élevée de la mémoire vive. Essayez de réduire la taille des demandes d'index en vrac.
Questions de cartographie
En particulier, si vous utilisez "fielddata : true", cela peut être un utilisateur majeur de la mémoire vive de votre JVM.
La taille du tas n'est pas correctement définie
La taille du tas peut être définie manuellement par :
Définition de la variable d'environnement :
Édition du fichier jvm.options dans le répertoire de configuration d'Elasticsearch :
Le paramètre de la variable d'environnement est prioritaire sur le paramètre du fichier.
Il est nécessaire de redémarrer le nœud pour que le réglage soit pris en compte.
Le nouveau ratio de la JVM n'est pas correctement défini
Il n'est généralement PAS nécessaire de définir cette valeur, car Elasticsearch le fait par défaut. Ce paramètre définit le ratio de l'espace disponible pour les objets de "nouvelle génération" et d'"ancienne génération" dans la JVM.
Si vous constatez que les anciens GC deviennent très fréquents, vous pouvez essayer de définir spécifiquement cette valeur dans le fichier jvm.options de votre répertoire de configuration Elasticsearch.
Quelles sont les meilleures pratiques pour gérer l'utilisation de la taille du tas et la collecte des déchets de la JVM dans un grand cluster Elasticsearch ?
Les meilleures pratiques pour gérer l'utilisation de la taille du tas et le ramassage des ordures de la JVM dans un grand cluster Elasticsearch consistent à s'assurer que la taille du tas est fixée à un maximum de 50% de la RAM disponible et que les paramètres du ramassage des ordures de la JVM sont optimisés pour le cas d'utilisation spécifique. Il est important de surveiller la taille du tas et les mesures du ramassage des ordures pour s'assurer que le cluster fonctionne de manière optimale. Plus précisément, il est important de surveiller la taille du tas de la JVM, le temps de ramassage des ordures et les pauses de ramassage des ordures. En outre, il est important de surveiller le nombre de cycles de ramassage des ordures et le temps passé à les effectuer. En surveillant ces mesures, il est possible d'identifier tout problème potentiel lié à la taille du tas ou aux paramètres du ramassage des ordures et de prendre des mesures correctives si nécessaire.
Pour aller plus loin

14 novembre 2025
Comment déployer Elasticsearch sur Azure AKS Automatic
Découvrez comment déployer Elasticsearch avec Kibana sur Azure en utilisant AKS Automatic et ECK pour une configuration Elasticsearch partiellement gérée.

11 novembre 2025
Configurer le découpage récursif pour les documents structurés dans Elasticsearch
Apprenez à configurer le découpage récursif dans Elasticsearch avec la taille des morceaux, les groupes de séparateurs et les listes de séparateurs personnalisées pour une indexation optimale des documents structurés.

7 novembre 2025
Présentation de l'interface utilisateur des règles de requête Elasticsearch dans Kibana
Découvrez comment utiliser l'interface utilisateur Elasticsearch Query Rules pour ajouter ou exclure des documents des requêtes de recherche à l'aide d'ensembles de règles personnalisables dans Kibana, sans affecter le classement organique.

3 octobre 2025
Comment déployer Elasticsearch sur AWS Marketplace
Découvrez comment configurer et exécuter Elasticsearch à l'aide d'Elastic Cloud Service sur AWS Marketplace grâce à ce guide étape par étape.

14 août 2025
Shards et répliques Elasticsearch : Un guide pratique
Maîtriser les concepts de shards et de réplicas Elasticsearch et apprendre à les optimiser.