Esta entrada de blog profundiza en los flujos de trabajo de RAG agentes, explicando sus características clave y patrones de diseño habituales. Además, demuestra cómo implementar estos flujos de trabajo mediante un ejemplo práctico que emplea Elasticsearch como almacén vectorial y LangChain para construir el marco agente RAG. Finalmente, el artículo analiza brevemente las mejores prácticas y los desafíos asociados al diseño e implementación de dichas arquitecturas. Puedes seguir el proceso para crear una pipeline agente RAG sencilla con este cuaderno Jupyter.
Introducción al RAG agente
La Generación Aumentada por Recuperación (RAG) se convirtió en una piedra angular en aplicaciones basadas en LLM, permitiendo a los modelos proporcionar respuestas óptimas al recuperar el contexto relevante basado en las consultas de los usuarios. Los sistemas RAG mejoran la precisión y el contexto de las respuestas de los LLM al aprovechar información externa de APIs o almacenes de datos, en lugar de limitar al conocimiento preentrenado de los LLM. Por otro lado, los agentes de IA operan de forma autónoma, tomando decisiones y tomando medidas para alcanzar sus objetivos designados.
El RAG agente es un marco que unifica las fortalezas tanto de la generación aumentada por recuperación como del razonamiento agentivo. Integra RAG en el proceso de toma de decisiones del agente, permitiendo al sistema elegir dinámicamente fuentes de datos, refinar consultas para una mejor recuperación de contexto, generar respuestas más precisas y aplicar un bucle de retroalimentación para mejorar continuamente la calidad de la salida.
Características clave del RAG agente
El marco RAG agente supone un avance importante respecto a los sistemas RAG tradicionales. En lugar de seguir un proceso de recuperación fijo, aprovecha agentes dinámicos capaces de planear, ejecutar y optimizar resultados en tiempo real.
Veamos algunas de las características clave que distinguen a las pipelines RAG agenticas:
- Toma de decisiones dinámica: El RAG agente emplea un mecanismo de razonamiento para entender la intención del usuario y enrutar cada consulta a la fuente de datos más relevante, produciendo respuestas precisas y conscientes del contexto.
- Análisis exhaustivo de consultas: Agentic RAG analiza en profundidad las consultas de los usuarios, incluyendo subpreguntas y su intención general. Evalúa la complejidad de las consultas y selecciona dinámicamente las fuentes de datos más relevantes para obtener información, cerciorando respuestas precisas y completas.
- Colaboración en varias etapas: Este marco permite la colaboración en varias etapas a través de una red de agentes especializados. Cada agente gestiona una parte específica de un objetivo mayor, trabajando de forma secuencial o simultánea para lograr un resultado coherente.
- Mecanismos de autoevaluación: La cadena agente RAG emplea la autorreflexión para evaluar documentos recuperados y respuestas generadas. Puede comprobar si la información recuperada responde completamente a la consulta y luego revisar la salida para comprobar su exactitud, completitud y consistencia fáctica.
- Integración con herramientas externas: Este flujo de trabajo puede interactuar con APIs externas, bases de datos y fuentes de información en tiempo real, incorporando información actualizada y adaptar dinámicamente a los datos en evolución.
Patrones de flujo de trabajo del RAG agente
Los patrones de flujo de trabajo definen cómo la IA agente estructura, gestiona y orquesta aplicaciones basadas en LLM de manera fiable y eficiente. Varios frameworks y plataformas, como LangChain, LangGraph, CrewAI y LlamaIndex, pueden emplear para implementar estos flujos de trabajo agentes.
- Cadena de recuperación secuencial: Los flujos de trabajo secuenciales dividen tareas complejas en pasos simples y ordenados. Cada paso mejora la entrada para el siguiente, lo que conduce a mejores resultados. Por ejemplo, al crear un perfil de cliente, un agente puede extraer datos básicos de un CRM, otro obtener el historial de compras de una base de datos de transacciones y un agente final combinar esta información para generar un perfil completo de recomendaciones o reportes.
- Cadena de recuperación de enrutamiento: En este patrón de flujo de trabajo, un agente router analiza la entrada y la dirige al proceso o fuente de datos más adecuada. Este enfoque es especialmente eficaz cuando existen múltiples fuentes de datos distintas con una superposición mínima. Por ejemplo, en un sistema de atención al cliente, el agente del router categoriza las solicitudes entrantes, como problemas técnicos, reembolsos o reclamaciones, y las encamina al departamento correspondiente para su gestión eficiente.
- Cadena de recuperación paralela: En este patrón de flujo de trabajo, se ejecutan simultáneamente múltiples subtareas independientes y sus salidas se agregan posteriormente para generar una respuesta final. Este enfoque reduce significativamente el tiempo de procesamiento y aumenta la eficiencia del flujo de trabajo. Por ejemplo, en un flujo de trabajo paralelo de atención al cliente, un agente recupera solicitudes pasadas similares y otro consulta artículos relevantes de la base de conocimiento. Un agregador combina entonces estas salidas para generar una resolución completa.
- Cadena de trabajadores Orchestrator: Este flujo de trabajo comparte similitudes con la paralelización debido a su utilización de subtareas independientes. Sin embargo, una distinción clave radica en la integración de un agente orquestador. Este agente es responsable de analizar las consultas de los usuarios, segmentarlas dinámicamente en subtareas durante la ejecución e identificar los procesos o herramientas adecuadas necesarias para formular una respuesta precisa.

Construyendo una pipeline RAG agentica desde cero
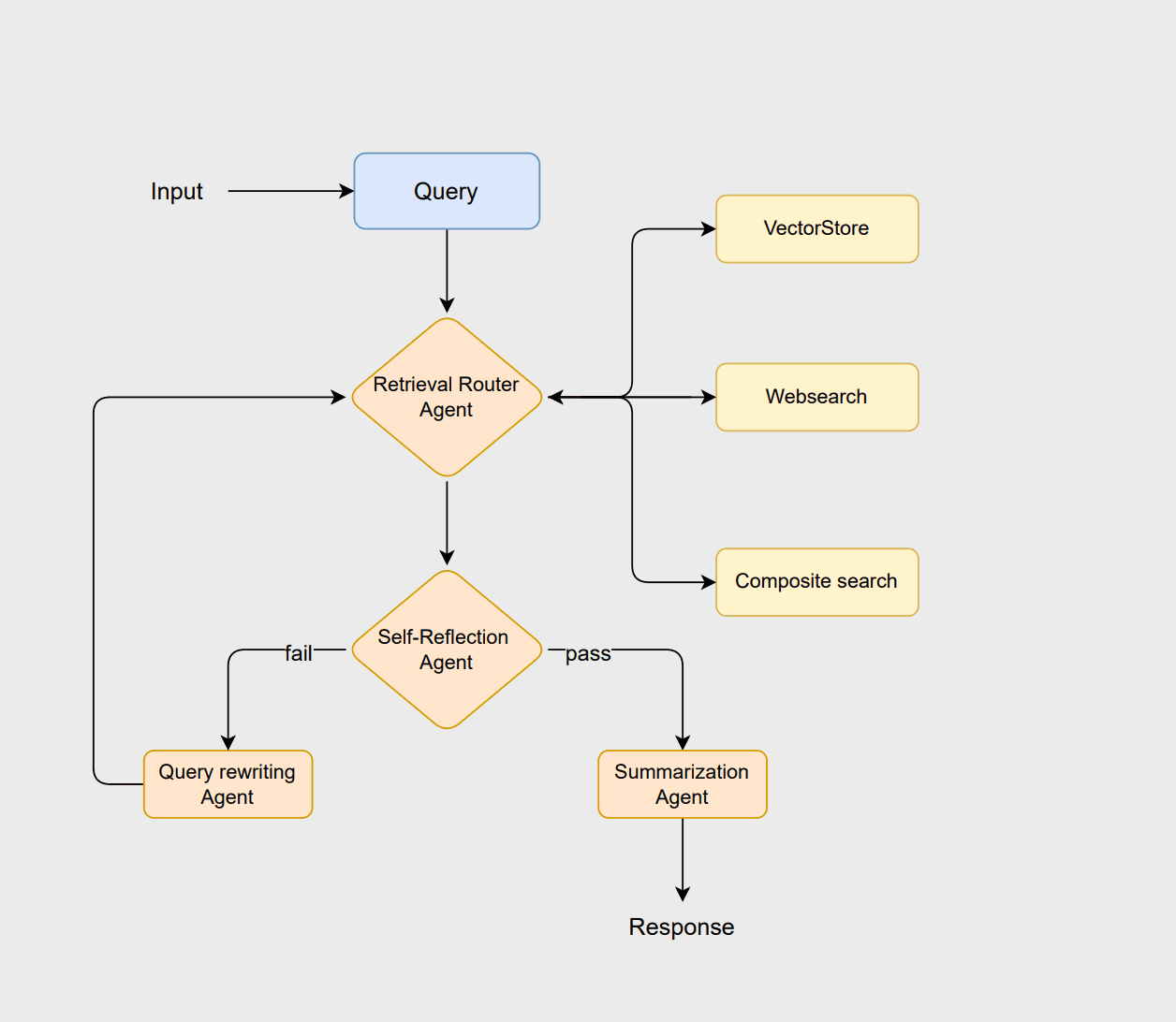
Para ilustrar los principios del RAG agente, diseñemos un flujo de trabajo usando LangChain y Elasticsearch. Este flujo de trabajo adopta una arquitectura basada en enrutamiento, donde varios agentes colaboran para analizar consultas, recuperar información relevante, evaluar resultados y generar respuestas coherentes. Podrías consultar este cuaderno Jupyter para seguir este ejemplo.
El flujo de trabajo comienza con el agente router, que analiza la consulta del usuario para seleccionar el método óptimo de recuperación, es decir, un enfoque vectorstore, websearcho composite . La vectorstore se encarga de la recuperación tradicional de documentos basada en RAG, la búsqueda sitio web obtiene la información más reciente que no está almacenada en la vectorstore, y el enfoque compuesto combina ambas cuando se necesita información de múltiples fuentes.
Si los documentos se consideran adecuados, el agente de resumen genera una respuesta clara y contextualmente adecuada. Sin embargo, si los documentos son insuficientes o irrelevantes, el agente de reescritura de la consulta reformula la consulta para mejorar la búsqueda. Esta consulta revisada resetear entonces el proceso de enrutamiento, permitiendo al sistema refinar su búsqueda y mejorar la salida final.
Prerrequisitos
Este flujo de trabajo se basa en los siguientes componentes clave para ejecutar el ejemplo de forma eficaz:
- Python 3.10
- Cuaderno Jupyter
- Azure OpenAI
- Elasticsearch
- LangChain
Antes de continuar, se te pedirá que configures el siguiente conjunto de variables de entorno requeridas para este ejemplo.
Fuentes de datos
Este flujo de trabajo se ilustra empleando un subconjunto del conjunto de datos de AG News. El conjunto de datos comprende artículos de noticias en diversas categorías, como Internacional, Deportes, Negocios y Ciencia/Tecnología.
El módulo ElasticsearchStore se emplea desde el langchain_elasticsearch como nuestro almacén vectorial. Para la recuperación, implementamos SparseVectorStrategy, empleando ELSER, el modelo propietario de incrustación de Elastic. Es esencial confirmar que el modelo ELSER está correctamente instalado y desplegado en tu entorno Elasticsearch antes de iniciar el almacén vectorial.
La funcionalidad de búsqueda sitio web se implementa usando DuckDuckGoSearchRun de las herramientas comunitarias LangChain, lo que permite al sistema recuperar información en tiempo real de la web de forma eficiente. También puedes considerar usar otras APIs de búsqueda que puedan ofrecer resultados más relevantes. Esta herramienta fue elegida porque permite búsquedas sin necesidad de clave API.
El retriever compuesto está diseñado para consultas que requieren una combinación de fuentes. Se emplea para proporcionar una respuesta completa y contextualmente precisa al recuperar datos en tiempo real de la web y consultar noticias históricas del almacén vectorial.
Preparando a los agentes
En el siguiente paso, los agentes LLM se definen para proporcionar capacidades de razonamiento y toma de decisiones dentro de este flujo de trabajo. Las cadenas de LLM que crearemos incluyen: router_chain, grade_docs_chain, rewrite_query_chainy summary_chain.
El agente router emplea un asistente LLM para determinar la fuente de datos más adecuada para una consulta determinada en tiempo de ejecución. El agente evaluador evalúa la relevancia de los documentos recuperados. Si los documentos se consideran relevantes, se entregan al agente de resumen para que genere un resumen. De lo contrario, el agente de consulta de reescritura reformula la consulta y la envía de vuelta al proceso de enrutamiento para otro intento de recuperación. Puedes encontrar las instrucciones de todos los agentes en la sección de cadenas de LLM del cuaderno.
La llm.with_structured_output limita la salida del modelo para seguir un esquema predefinido definido por el BaseModel bajo la clase RouteQuery , cerciorando la consistencia de los resultados. La segunda línea compone una RunnableSequence conectando router_prompt con router_structured, formando una tubería en la que el modelo de lenguaje procesa el prompt de entrada para producir resultados estructurados y compatibles con el esquema.
Definir nodos de grafo
Esta parte implica definir los estados del grafo, que representan los datos que fluyen entre los diferentes componentes del sistema. Una especificación clara de estos estados cerciora que cada nodo del flujo de trabajo sepa qué información puede acceder y actualizar.
Una vez definidos los estados, el siguiente paso es definir los nodos del grafo. Los nodos son como las unidades funcionales del grafo que realizan operaciones específicas sobre los datos. Hay 7 nodos diferentes en nuestra pipeline.
El nodo query_rewriter cumple dos funciones en el flujo de trabajo. Primero, reescribe la consulta del usuario usando el rewrite_query_chain para mejorar la recuperación cuando los documentos evaluados por el agente autorreflexivo se consideran insuficientes o irrelevantes. Segundo, actúa como un contador que registra cuántas veces se reescribió la consulta.
Cada vez que se invoca el nodo, incrementa la retry_count almacenada en el estado del flujo de trabajo. Este mecanismo impide que el flujo de trabajo entre en un bucle infinito. Si el retry_count supera un umbral predefinido, el sistema puede recurrir a un estado de error, una respuesta por defecto o cualquier otra condición predefinida que elijas.
Compilación del grafo
El último paso es definir las aristas del grafo y agregar las condiciones necesarias antes de compilarlo. Cada grafo debe comenzar desde un nodo inicial designado, que sirve como punto de entrada para el flujo de trabajo. Las aristas en el gráfico representan el flujo de datos entre nodos y pueden ser de dos tipos:
- Aristas rectas: Estas definen un flujo directo e incondicional de un nodo a otro. Cada vez que el primer nodo completa su tarea, el flujo de trabajo avanza automáticamente al siguiente nodo a lo largo de la arista recta.
- Aristas condicionales: Estas permiten que el flujo de trabajo se ramifice según el estado actual o los resultados del cálculo de un nodo. El siguiente nodo se selecciona dinámicamente en función de condiciones como resultados de evaluación, decisiones de enrutamiento o recuentos de intentos.
Con eso, tu primera pipeline de RAG agente está lista y puede probar usando el agente compilado.
Prueba de la tubería agente RAG
Ahora probaremos esta canalización usando tres tipos distintos de consultas como se indica a continuación. Ten en cuenta que los resultados pueden variar, y los ejemplos que se muestran a continuación ilustran solo un posible resultado.
Para la primera consulta, el router selecciona websearch como fuente de datos. La consulta no supera la evaluación de autorreflexión y posteriormente se redirige a la etapa de reescritura de la consulta, como se muestra en el resultado.
A continuación, examinamos un ejemplo en el que se emplea vectorstore recuperación, demostrado con la segunda consulta.
La consulta final se dirige a la recuperación compuesta, que emplea tanto la vectorstore como la búsqueda sitio web.
En el flujo de trabajo anterior, el RAG agente determina de forma inteligente qué fuente de datos emplear al recuperar información para una consulta de usuario, mejorando así la precisión y relevancia de la respuesta. Puedes crear ejemplos adicionales para probar al agente y revisar los resultados para ver si dan resultados interesantes.
Mejores prácticas para construir flujos de trabajo agenticos RAG
Ahora que entendemos cómo funciona el RAG agente, veamos algunas buenas prácticas para construir estos flujos de trabajo. Seguir estas directrices ayudará a mantener el sistema eficiente y fácil de mantener.
- Prepárate para los recursos de respaldo: Planea estrategias de respaldo con antelación para escenarios en los que algún paso del flujo de trabajo falle. Estos pueden incluir devolver respuestas por defecto, activar estados de error o emplear herramientas alternativas. Esto garantiza que el sistema gestione los fallos con elegancia sin romper el flujo de trabajo global.
- Implementa registros completos: Prueba a implementar registros en cada etapa del flujo de trabajo, como intentos, salidas generadas, elecciones de enrutamiento y reescrituras de consultas. Estos registros ayudan a mejorar la transparencia, facilitan la depuración y ayudan a refinar los prompts, el comportamiento de los agentes y las estrategias de recuperación con el tiempo.
- Selecciona el patrón de flujo de trabajo adecuado: Examina tu caso de uso y selecciona el patrón que mejor se adapte a tus necesidades. Emplea flujos de trabajo secuenciales para razonamiento paso a paso, flujos de trabajo paralelos para fuentes de datos independientes y patrones orquestador-trabajador para consultas multiherramienta o complejas.
- Incorpora estrategias de evaluación: Integra mecanismos de evaluación en diferentes etapas del flujo de trabajo. Estos pueden incluir agentes de autorreflexión, calificación de documentos recuperados o controles automáticos de calidad. La evaluación ayuda a verificar que los documentos recuperados son relevantes, que las respuestas son precisas y que todas las partes de una consulta compleja están abordadas.
Desafíos
Aunque los sistemas RAG agenticos ofrecen beneficios significativos en términos de adaptabilidad, precisión y razonamiento dinámico, también presentan ciertos desafíos que deben abordar durante sus etapas de diseño e implementación. Algunos de los principales retos incluyen:
- Flujos de trabajo complejos: A medida que se agregan más agentes y puntos de decisión, el flujo de trabajo global se vuelve cada vez más complejo. Esto puede llevar a mayores probabilidades de errores o fallos en tiempo de ejecución. Siempre que sea posible, prioriza flujos de trabajo optimizados eliminando agentes redundantes y puntos de decisión innecesarios.
- Escalabilidad: Puede ser complicado escalar sistemas RAG agentes para manejar grandes conjuntos de datos y grandes volúmenes de consultas. Incorpora estrategias eficientes de indexación, caché y procesamiento distribuido para mantener el rendimiento a gran escala.
- Orquestación y sobrecarga computacional: La ejecución de flujos de trabajo con múltiples agentes requiere orquestación avanzada. Esto incluye una planeación cuidadosa, gestión de dependencias y coordinación de agentes para evitar cuellos de botella y conflictos, todo lo cual contribuye a la complejidad general del sistema.
- Complejidad de la evaluación: La evaluación de estos flujos de trabajo presenta desafíos inherentes, ya que cada etapa requiere una estrategia de evaluación distinta. Por ejemplo, la etapa RAG debe evaluar para verificar la relevancia y completitud de los documentos recuperados, mientras que los resúmenes generados deben verificar para garantizar su calidad y precisión. Del mismo modo, la efectividad de la reformulación de consultas requiere una lógica de evaluación separada para determinar si la consulta reescrita mejora los resultados de recuperación.
Conclusión
En esta entrada de blog, presentamos el concepto de RAG agente y destacamos cómo mejora el marco tradicional de RAG al incorporar capacidades autónomas de la IA agente. Exploramos las características principales de RAG agente y demostramos estas características mediante un ejemplo práctico, construyendo un asistente de noticias usando Elasticsearch como almacén vectorial y LangChain para crear el marco agente.
Además, discutimos las mejores prácticas y los principales retos a considerar al diseñar e implementar una pipeline agentica RAG. Estos conocimientos están destinados a guiar a los desarrolladores en la creación de sistemas agentivos robustos, escalables y eficientes que combinen eficazmente la recuperación, el razonamiento y la toma de decisiones.
¿Qué sigue ahora?
El flujo de trabajo que creamos es sencillo, dejando amplio margen para mejoras y experimentación. Podemos mejorar esto experimentando con varios modelos de incrustación y refinando estrategias de recuperación. Además, integrar a un agente de reclasificación para priorizar los documentos recuperados podría ser beneficioso. Otra área de exploración implica desarrollar estrategias de evaluación para marcos agentivos, identificando específicamente enfoques comunes y reutilizables aplicables a diferentes tipos de marcos. Por último, experimentar con estos marcos en conjuntos de datos grandes y más complejos.
Mientras tanto, si tienes experimentos similares que compartir, ¡nos encantaría saberlos! No dudes en dar tus opiniones o conectar con nosotros a través de nuestro canal comunitario de Slack o foros de discusión.
Recursos
Contenido relacionado

8 de abril de 2026
Cómo construir aplicaciones de IA con agentes con Mastra y Elasticsearch
Aprende a construir aplicaciones de IA agéntica usando Mastra y Elasticsearch a través de un ejemplo práctico.

25 de marzo de 2026
La herramienta de shell no es una solución mágica para la ingeniería de contexto
Aprenda qué herramientas de recuperación de contexto existen para la ingeniería de contexto, cómo funcionan y sus compensaciones.

23 de marzo de 2026
Uso de la API de inferencia de Elasticsearch junto con modelos de Hugging Face
Aprende a conectar Elasticsearch a modelos de Hugging Face usando endpoints de inferencia y crea un sistema multilingüe de recomendación de blogs con búsqueda semántica y finalización de chat.

27 de marzo de 2026
Cómo crear un servidor MCP de Elasticsearch con TypeScript
Aprende a crear un servidor MCP de Elasticsearch con TypeScript y Claude Desktop.
17 de marzo de 2026
Extensión CLI de Gemini para Elasticsearch con herramientas y habilidades
Te presentamos la extensión de Elastic para la CLI de Gemini de Google, que te permite hacer búsquedas, recuperar y analizar datos de Elasticsearch en flujos de trabajo de desarrollo y de agentes.