Get hands-on with Elasticsearch: Dive into our sample notebooks in the Elasticsearch Labs repo, start a free cloud trial, or try Elastic on your local machine now.
ES|QL overview
ES|QL is a new query language introduced by Elasticsearch that combines a simplified syntax with the pipe operator to enable users to intuitively extrapolate and manipulate data. The new version 8.13.0 of the official Java client introduced support for ES|QL queries, with a new API that allows for easy query execution and automatic translation of the results to java objects.
How to perform ES|QL queries with the Java client
Prerequisites
- Elasticsearch version >= 8.11.0
- Java version >= 17
Ingesting data
Before we start querying we need to have some data available: we're going to store this csv file into Elasticsearch by using the BulkIngester utility class available in the Java client. The csv lists books from the Amazon Books Reviews dataset, categorizing them using the following header row:
First of all, we have to create the index to map the fields correctly:
Then the Java class for the books:
We're going to use Jackson's CSV mapper to read the file, so let's configure it:
Then we'll read the csv file line by line and optimize the ingestion using the BulkIngester:
The indexing will take around 15 seconds, but when it's done we'll have the books index filled with ~80K documents, ready to be queried.
ES|QL
Now it's time to extract some information from the books data. Let's say we want to find the latest reprints of Asimov's works:
Thanks to the ObjectsEsqlAdapter using Book.class as the target, we can ignore what the json result of the ES|QL query would be, and just focus on the more familiar list of books that is automatically returned by the client.
For those who are used to SQL queries and the JDBC interface, the client also provides the ResultSetEsqlAdapter, which can be used in the same way and instead returns a java.sql.ResultSet
Another example, we now want to find out the top-rated books from Penguin Books:
The Java code to retrieve the data stays the same since the result is again a list of books. There are exceptions of course, for example if a query uses the eval command to add a new column, the Java class should be modified to represent the new result.
The full code for this article can be found in the official client repository. Feel free to reach out on Discuss for any questions or issues.
Frequently Asked Questions
What is ES|QL?
ES|QL is a new query language introduced by Elasticsearch that combines a simplified syntax with the pipe operator to enable users to intuitively extrapolate and manipulate data.
Related Content
How to instrument your search API with OpenTelemetry and query it with ES|QL
Add custom attributes to OpenTelemetry spans and run six ES|QL queries that reveal your top searches, zero-result rate and slowest queries.

How to build search analytics on Elastic using OpenTelemetry, no extra pipeline required
How to instrument your search application to use modern Open Telemetry standard to drive insights in to your search and users.
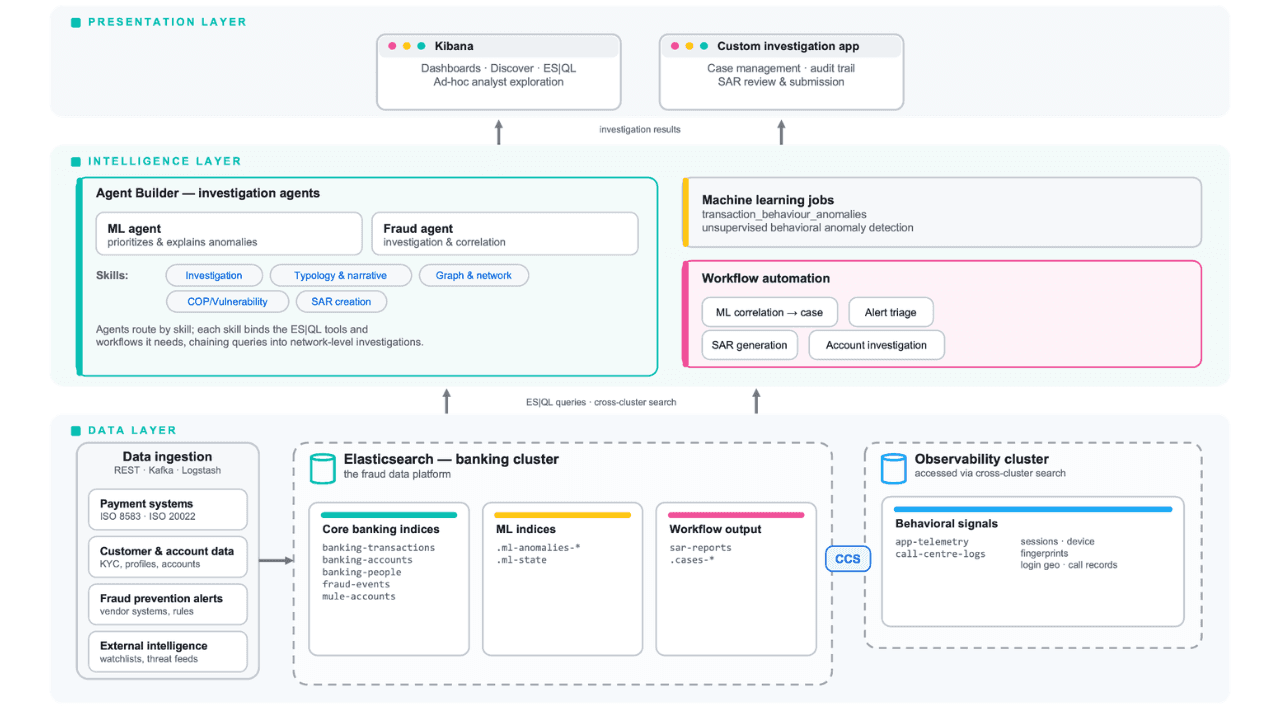
Follow the money: tracing laundering networks with ES|QL and cross-cluster search
The data model, cross-cluster architecture and five ES|QL queries that power mule detection and laundering network tracing, built from infrastructure most financial institutions already run.

July 1, 2026
One command. Natural language. Your Elasticsearch data, straight to the terminal.
Query your Elasticsearch data from the terminal in plain English. The official Elastic GitHub Copilot CLI plugin generates and runs ES|QL queries against your cluster. No Kibana, no manual syntax.

June 30, 2026
Building a multilingual voice agent with Elastic Agent Builder & Sarvam AI
A working demo combining Sarvam AI speech with Elastic Agent Builder: identity verification, per-customer ES|QL queries, and mid-call language switching across 22 Indian languages without multilingual indices.