Como adicionar suporte para mais idiomas em seus mecanismos do Elastic Enterprise Search


 Share on Twitter
Share on TwitterCompartilhar no Twitter

 Share on LinkedIn
Share on LinkedInCompartilhar no LinkedIn

 Share on Facebook
Share on FacebookCompartilhar no Facebook

 Share by Email
Share by EmailCompartilhar por e-mail

 Print this page
Print this pageImprimir
Os mecanismos no Elastic App Search permitem que você indexe documentos e forneça funcionalidades ajustáveis de busca prontas para uso. Por padrão, os mecanismos oferecem suporte para uma lista de idiomas predefinida. Se seu idioma não está nessa lista, este post explica como você pode adicionar suporte para idiomas adicionais. Faremos isso criando um mecanismo do App Search que tem analisadores configurados para esse idioma.
Antes de entrarmos a fundo nos detalhes, vamos definir o que é um analisador do Elasticsearch:
Um analisador do Elasticsearch é um pacote que contém três componentes de nível inferior: filtros de caracteres, tokenizadores e filtros de token. Os analisadores podem ser integrados ou customizados. Os analisadores integrados pré-empacotam os componentes em analisadores adequados para diferentes idiomas e tipos de texto.
Os analisadores de cada campo são usados para:
- Indexar. Cada campo do documento será processado com seu analisador correspondente e dividido em tokens para facilitar a busca.
- Buscar. A consulta de busca será analisada para garantir uma correspondência adequada com os campos indexados que já foram analisados.
Os mecanismos baseados em índice do Elasticsearch possibilitam a criação de mecanismos do App Search a partir de índices existentes do Elasticsearch. Criaremos um índice do Elasticsearch com nossos próprios analisadores e mapeamentos, e usaremos esse índice no App Search.
Existem quatro etapas nesse processo:
1. Criar um índice do Elasticsearch e indexar documentos
Para começar, vamos pegar um índice que não foi otimizado para nenhum idioma. Vamos supor que esse seja um novo índice que não tenha mapeamentos predefinidos e seja criado quando os documentos forem indexados pela primeira vez.
No Elasticsearch, mapeamento é o processo que define como um documento e o os campos que ele contém são armazenados e indexados. Cada documento é uma coleção de campos, cada um com seu próprio tipo de dados. Ao mapear seus dados, você cria uma definição de mapeamento, que contém uma lista de campos pertinentes ao documento.
Voltemos ao nosso exemplo. O índice é chamado de books, onde o title está no idioma romeno. Escolhemos o romeno porque é meu idioma e não está incluído na lista de idiomas compatíveis com o App Search por padrão.
POST books/_doc/1
{
"title": "Un veac de singurătate",
"author": "Gabriel García Márquez"
}
POST books/_doc/2
{
"title": "Dragoste în vremea holerei",
"author": "Gabriel García Márquez"
}
POST books/_doc/3
{
"title": "Obosit de viaţă, obosit de moarte",
"author": "Mo Yan"
}
POST books/_doc/4
{
"title": "Maestrul și Margareta",
"author": "Mihail Bulgakov"
}2. Adicionar analisadores de idioma ao índice books
Quando inspecionamos o mapeamento do índice books, vemos que ele não está otimizado para romeno. Como sabemos isso? Não há um campo analysis no bloco settings, e os campos de texto não usam um analisador customizado.
GET books
{
"books": {
"aliases": {},
"mappings": {
"properties": {
"author": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"title": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
}
}
},
"settings": {
"index": {
"routing": {
"allocation": {
"include": {
"_tier_preference": "data_content"
}
}
},
"number_of_shards": "1",
"provided_name": "books",
"creation_date": "1679310576178",
"number_of_replicas": "1",
"uuid": "0KuiDk8iSZ-YHVQGg3B0iw",
"version": {
"created": "8080099"
}
}
}
}
}Se tentarmos criar um mecanismo do App Search com o índice books, teremos dois problemas. Primeiro, os resultados da busca não serão otimizados para romeno e segundo, recursos como o ajuste de precisão estarão desabilitados.
Uma observação rápida sobre diferentes tipos de mecanismos do Elastic App Search:
- A opção padrão é um mecanismo gerenciado do App Search, que criará e gerenciará automaticamente um índice oculto do Elasticsearch. Com essa opção, você precisa usar a API de documentos do App Search para fazer a ingestão de dados no seu mecanismo.
- Com a outra opção, o App Search cria um mecanismo com um índice existente do Elasticsearch — nesse caso, o App Search usará o índice como está. Aqui, você pode ingerir dados diretamente no índice subjacente usando a API de documentos do índice do Elasticsearch.
[Artigo relacionado: API de busca do Elasticsearch: uma nova maneira de localizar documentos com o App Search] (em inglês)
Quando você criar um mecanismo a partir de um índice existente do Elasticsearch, se os mapeamentos não seguirem as convenções do App Search, nem todos os recursos serão habilitados para esse mecanismo. Vamos dar uma olhada mais de perto nas convenções de mapeamento do App Search observando um mecanismo que é totalmente gerenciado pelo App Search. Esse mecanismo tem dois campos, title e author, e usa o idioma inglês.
GET .ent-search-engine-documents-app-search-books/_mapping/field/title
{
".ent-search-engine-documents-app-search-books": {
"mappings": {
"title": {
"full_name": "title",
"mapping": {
"title": {
"type": "text",
"fields": {
"date": {
"type": "date",
"format": "strict_date_time||strict_date",
"ignore_malformed": true
},
"delimiter": {
"type": "text",
"index_options": "freqs",
"analyzer": "iq_text_delimiter"
},
"enum": {
"type": "keyword",
"ignore_above": 2048
},
"float": {
"type": "double",
"ignore_malformed": true
},
"joined": {
"type": "text",
"index_options": "freqs",
"analyzer": "i_text_bigram",
"search_analyzer": "q_text_bigram"
},
"location": {
"type": "geo_point",
"ignore_malformed": true,
"ignore_z_value": false
},
"prefix": {
"type": "text",
"index_options": "docs",
"analyzer": "i_prefix",
"search_analyzer": "q_prefix"
},
"stem": {
"type": "text",
"analyzer": "iq_text_stem"
}
},
"index_options": "freqs",
"analyzer": "iq_text_base"
}
}
}
}
}
}Você verá que o campo title tem vários subcampos. Os subcampos date, float e location não são campos de texto.
Aqui, nosso interesse é saber como definir os campos de texto exigidos pelo App Search. São vários os campos! Esta página de documentação explica os campos de texto usados no App Search. Vejamos os analisadores que o App Search define para um índice oculto pertencente a um mecanismo gerenciado do App Search:
GET .ent-search-engine-documents-app-search-books/_settings/index.analysis*
{
".ent-search-engine-documents-app-search-books": {
"settings": {
"index": {
"analysis": {
"filter": {
"front_ngram": {
"type": "edge_ngram",
"min_gram": "1",
"max_gram": "12"
},
"bigram_joiner": {
"max_shingle_size": "2",
"token_separator": "",
"output_unigrams": "false",
"type": "shingle"
},
"bigram_max_size": {
"type": "length",
"max": "16",
"min": "0"
},
"en-stem-filter": {
"name": "light_english",
"type": "stemmer"
},
"bigram_joiner_unigrams": {
"max_shingle_size": "2",
"token_separator": "",
"output_unigrams": "true",
"type": "shingle"
},
"delimiter": {
"split_on_numerics": "true",
"generate_word_parts": "true",
"preserve_original": "false",
"catenate_words": "true",
"generate_number_parts": "true",
"catenate_all": "true",
"split_on_case_change": "true",
"type": "word_delimiter_graph",
"catenate_numbers": "true",
"stem_english_possessive": "true"
},
"en-stop-words-filter": {
"type": "stop",
"stopwords": "_english_"
}
},
"analyzer": {
"i_prefix": {
"filter": [
"cjk_width",
"lowercase",
"asciifolding",
"front_ngram"
],
"tokenizer": "standard"
},
"iq_text_delimiter": {
"filter": [
"delimiter",
"cjk_width",
"lowercase",
"asciifolding",
"en-stop-words-filter",
"en-stem-filter"
],
"tokenizer": "whitespace"
},
"q_prefix": {
"filter": [
"cjk_width",
"lowercase",
"asciifolding"
],
"tokenizer": "standard"
},
"iq_text_base": {
"filter": [
"cjk_width",
"lowercase",
"asciifolding",
"en-stop-words-filter"
],
"tokenizer": "standard"
},
"iq_text_stem": {
"filter": [
"cjk_width",
"lowercase",
"asciifolding",
"en-stop-words-filter",
"en-stem-filter"
],
"tokenizer": "standard"
},
"i_text_bigram": {
"filter": [
"cjk_width",
"lowercase",
"asciifolding",
"en-stem-filter",
"bigram_joiner",
"bigram_max_size"
],
"tokenizer": "standard"
},
"q_text_bigram": {
"filter": [
"cjk_width",
"lowercase",
"asciifolding",
"en-stem-filter",
"bigram_joiner_unigrams",
"bigram_max_size"
],
"tokenizer": "standard"
}
}
}
}
}
}
}Se quisermos criar um índice que possamos usar no App Search, para um idioma diferente como norueguês, finlandês ou árabe, precisaremos de analisadores semelhantes. Para nosso exemplo, precisamos garantir que os filtros de stem e stop words usem a versão romena.
Voltando ao nosso índice books inicial, vamos adicionar os analisadores certos.
Um rápido aviso de cautela aqui. Para índices existentes, os analisadores são um tipo de configuração do Elasticsearch que só pode ser alterado quando um índice é fechado. Nesta abordagem, começamos com um índice existente e, portanto, precisamos fechar o índice, adicionar analisadores e depois reabrir o índice.
Observação: como alternativa, você também pode recriar o índice do zero com os mapeamentos corretos e depois indexar todos os documentos. Se for melhor para o seu caso de uso, fique à vontade para pular as partes deste guia que tratam da abertura e do fechamento do índice, bem como da reindexação.
Você pode fechar o índice executando POST books/_close. E depois disso, adicionaremos os analisadores:
PUT books/_settings
{
"analysis": {
"filter": {
"front_ngram": {
"type": "edge_ngram",
"min_gram": "1",
"max_gram": "12"
},
"bigram_joiner": {
"max_shingle_size": "2",
"token_separator": "",
"output_unigrams": "false",
"type": "shingle"
},
"bigram_max_size": {
"type": "length",
"max": "16",
"min": "0"
},
"ro-stem-filter": {
"name": "romanian",
"type": "stemmer"
},
"bigram_joiner_unigrams": {
"max_shingle_size": "2",
"token_separator": "",
"output_unigrams": "true",
"type": "shingle"
},
"delimiter": {
"split_on_numerics": "true",
"generate_word_parts": "true",
"preserve_original": "false",
"catenate_words": "true",
"generate_number_parts": "true",
"catenate_all": "true",
"split_on_case_change": "true",
"type": "word_delimiter_graph",
"catenate_numbers": "true"
},
"ro-stop-words-filter": {
"type": "stop",
"stopwords": "_romanian_"
}
},
"analyzer": {
"i_prefix": {
"filter": [
"cjk_width",
"lowercase",
"asciifolding",
"front_ngram"
],
"tokenizer": "standard"
},
"iq_text_delimiter": {
"filter": [
"delimiter",
"cjk_width",
"lowercase",
"asciifolding",
"ro-stop-words-filter",
"ro-stem-filter"
],
"tokenizer": "whitespace"
},
"q_prefix": {
"filter": [
"cjk_width",
"lowercase",
"asciifolding"
],
"tokenizer": "standard"
},
"iq_text_base": {
"filter": [
"cjk_width",
"lowercase",
"asciifolding",
"ro-stop-words-filter"
],
"tokenizer": "standard"
},
"iq_text_stem": {
"filter": [
"cjk_width",
"lowercase",
"asciifolding",
"ro-stop-words-filter",
"ro-stem-filter"
],
"tokenizer": "standard"
},
"i_text_bigram": {
"filter": [
"cjk_width",
"lowercase",
"asciifolding",
"ro-stem-filter",
"bigram_joiner",
"bigram_max_size"
],
"tokenizer": "standard"
},
"q_text_bigram": {
"filter": [
"cjk_width",
"lowercase",
"asciifolding",
"ro-stem-filter",
"bigram_joiner_unigrams",
"bigram_max_size"
],
"tokenizer": "standard"
}
}
}
}Você pode ver que estamos adicionando o ro-stem-filter para stemização em romeno, o que melhorará a relevância da busca para variações de palavras que são específicas do romeno. Estamos incluindo o filtro de stop words (palavras vazias) romenas (ro-stop-words-filter) para garantir que as stop words romenas não sejam consideradas para fins de busca.
E agora reabriremos o índice executando POST books/_open.
3. Atualizar o mapeamento do índice para usar analisadores
Depois de definirmos as configurações de análise, podemos modificar o mapeamento do índice. O App Search usa modelos dinâmicos para garantir que os novos campos tenham os subcampos e analisadores corretos. Para nosso exemplo, adicionaremos apenas os subcampos aos campos title e author existentes:
PUT books/_mapping
{
"properties": {
"author": {
"type": "text",
"fields": {
"delimiter": {
"type": "text",
"index_options": "freqs",
"analyzer": "iq_text_delimiter"
},
"enum": {
"type": "keyword",
"ignore_above": 2048
},
"joined": {
"type": "text",
"index_options": "freqs",
"analyzer": "i_text_bigram",
"search_analyzer": "q_text_bigram"
},
"prefix": {
"type": "text",
"index_options": "docs",
"analyzer": "i_prefix",
"search_analyzer": "q_prefix"
},
"stem": {
"type": "text",
"analyzer": "iq_text_stem"
}
}
},
"title": {
"type": "text",
"fields": {
"delimiter": {
"type": "text",
"index_options": "freqs",
"analyzer": "iq_text_delimiter"
},
"enum": {
"type": "keyword",
"ignore_above": 2048
},
"joined": {
"type": "text",
"index_options": "freqs",
"analyzer": "i_text_bigram",
"search_analyzer": "q_text_bigram"
},
"prefix": {
"type": "text",
"index_options": "docs",
"analyzer": "i_prefix",
"search_analyzer": "q_prefix"
},
"stem": {
"type": "text",
"analyzer": "iq_text_stem"
}
}
}
}
}4. Reindexar os documentos
O índice books agora está quase pronto para ser usado no App Search!
Só precisamos garantir que os documentos que indexamos antes de modificarmos o mapeamento tenham todos os subcampos corretos. Para fazer isso, podemos executar uma reindexação usando update_by_query:
POST books/_update_by_query?refresh
{
"query": {
"match_all": {
}
}
}Como estamos usando uma consulta match_all, todos os documentos existentes serão atualizados.
Com uma solicitação de atualização por consulta, também podemos incluir um parâmetro de script para definir como atualizar os documentos.
Observe que não estamos alterando os documentos, mas queremos reindexar os documentos existentes da forma como estão para garantir que os campos de texto author e title tenham os subcampos corretos. Portanto, não precisamos incluir um script na nossa solicitação de atualização por consulta.
Agora temos um índice otimizado para o idioma que podemos usar no App Search com mecanismos do Elasticsearch! Você verá os benefícios em ação nas capturas de tela a seguir.
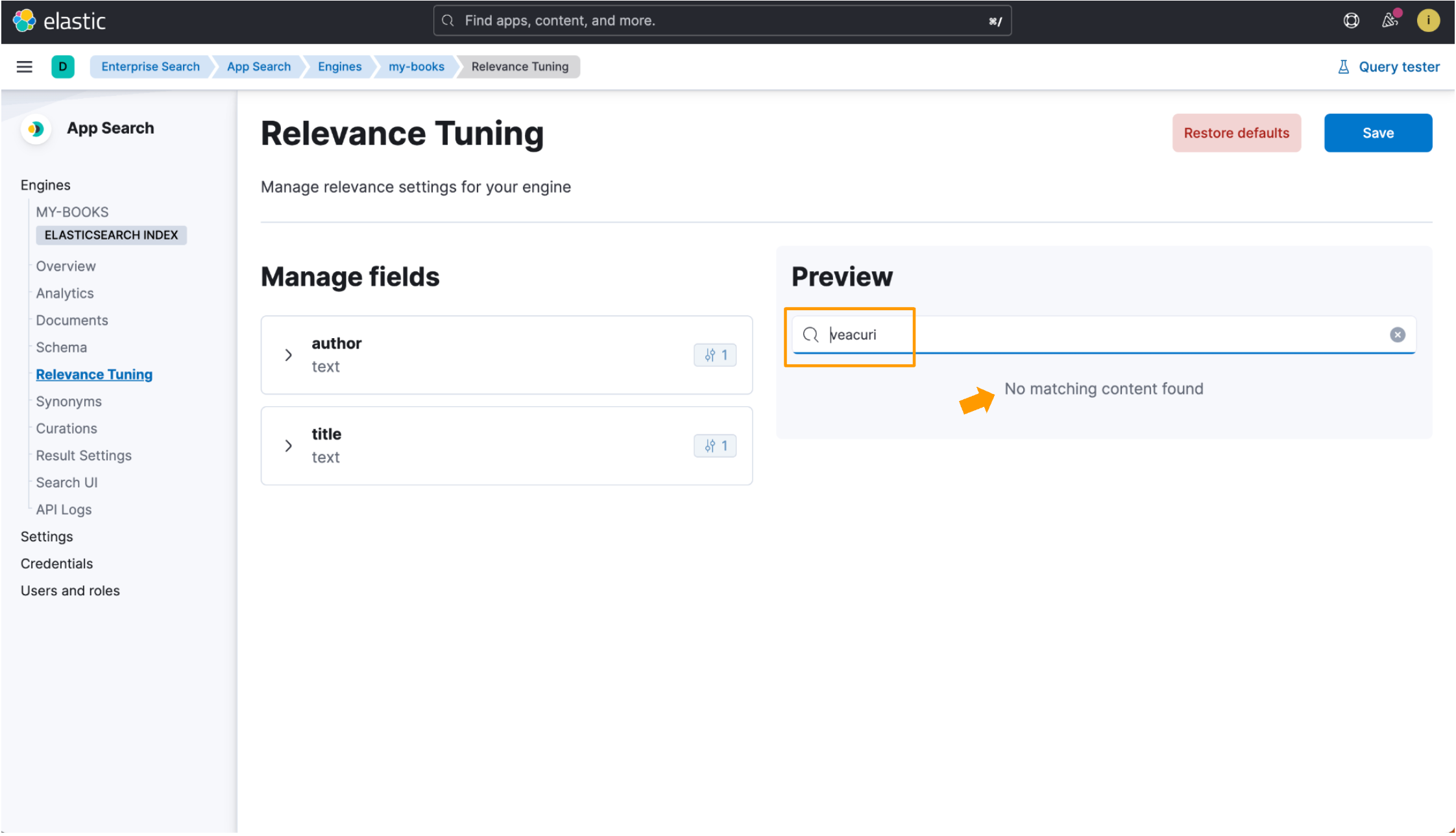
Usaremos o título do livro Cem Anos de Solidão como referência. O título traduzido em romeno é Un veac de singurătate. Preste atenção na palavra veac, que é a palavra romena para “século”. Faremos uma busca com a forma plural de veac, que é veacuri. Ingerimos esse registro de dados em ambos os exemplos que veremos:
{
"title": "Un veac de singurătate",
"author": "Gabriel García Márquez"
}Quando um índice não é otimizado para um idioma, o título do livro romeno Un veac de singurătate é indexado com o analisador padrão, que funciona bem para a maioria dos idiomas, mas nem sempre corresponde a documentos relevantes. A busca por veacuri não mostra nenhum resultado, pois essa entrada de busca não corresponde a nenhum texto simples no registro de dados.
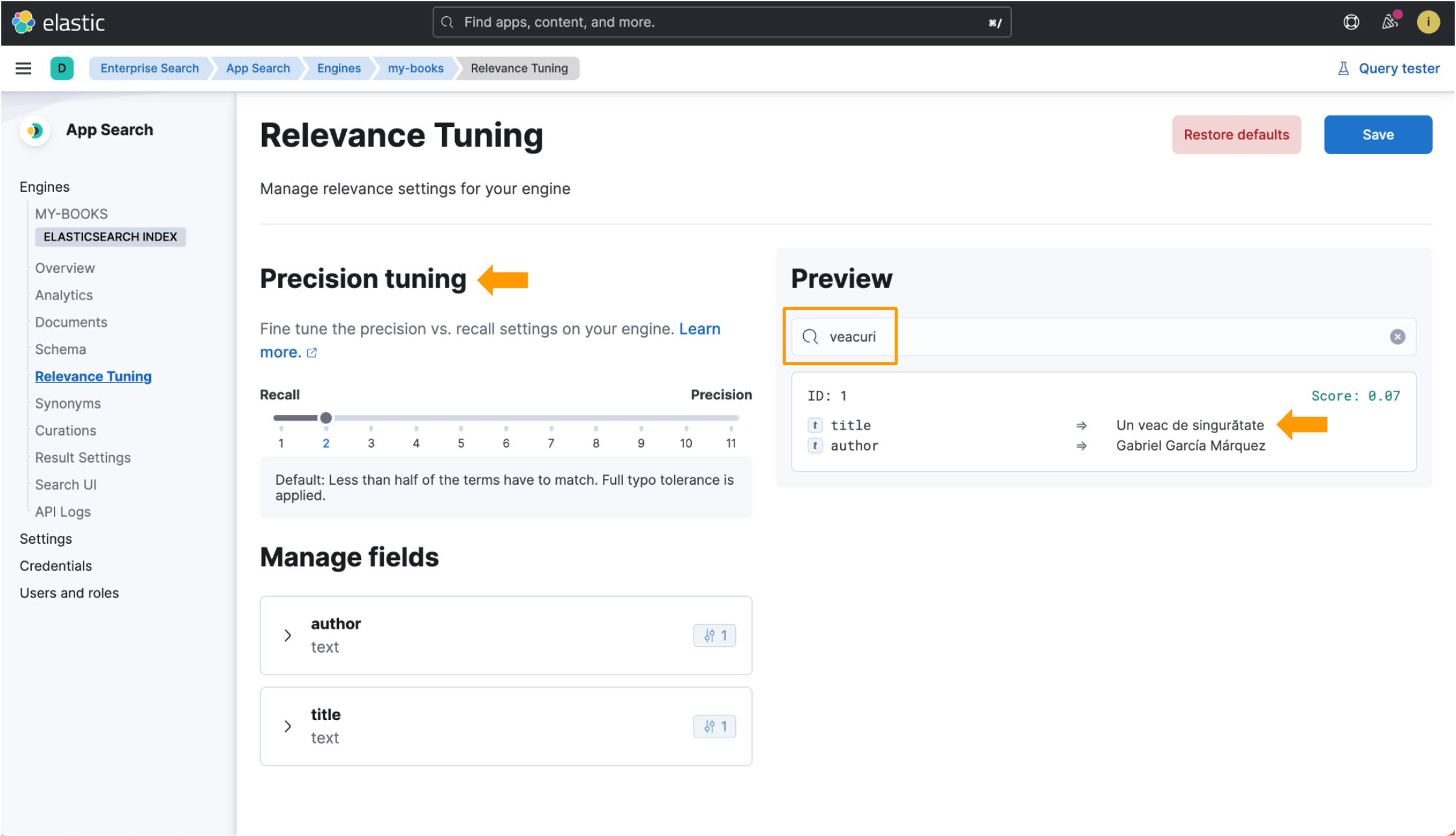
Porém, com o uso do índice otimizado para o idioma, quando buscamos por veacuri, o Elastic App Search corresponde isso à palavra do idioma romeno veac e retorna os dados que estamos procurando. Os campos de ajuste de precisão também estão disponíveis na visualização Relevance Tuning (Ajuste de relevância)! Observe todas as partes destacadas nesta imagem:
Então, com isso, adicionamos suporte no Elastic Enterprise Search para romeno, que é o meu idioma! O processo usado neste guia pode ser replicado para criar índices otimizados para qualquer outro idioma aceito pelo Elasticsearch. Para obter a lista completa de analisadores de idioma compatíveis no Elasticsearch, consulte esta página de documentação.
Os analisadores no Elasticsearch são um tópico fascinante. Se tiver interesse em saber mais, aqui estão alguns outros recursos:
- Página de documentação de visão geral da análise de texto (em inglês) do Elasticsearch
- Página de documentação de referência de analisadores integrados (em inglês) do Elasticsearch (consulte esta subpágina para obter uma lista dos analisadores de idioma compatíveis)
- Saiba mais sobre o Elastic Enterprise Search e a avaliação do Elastic Cloud
Compartilhar
- Share on Twitter
Compartilhar no Twitter
- Share on LinkedIn
Compartilhar no LinkedIn
- Share on Facebook
Compartilhar no Facebook
- Share by Email
Compartilhar por e-mail
- Print this page
Imprimir