Faça a ingestão de dados diretamente do Google BigQuery no Elastic usando o Google Dataflow


 Share on Twitter
Share on TwitterCompartilhar no Twitter

 Share on LinkedIn
Share on LinkedInCompartilhar no LinkedIn

 Share on Facebook
Share on FacebookCompartilhar no Facebook

 Share by Email
Share by EmailCompartilhar por e-mail

 Print this page
Print this pageImprimir
Hoje temos o prazer de anunciar o suporte para a ingestão direta de dados do BigQuery no Elastic Stack. Agora analistas de dados e desenvolvedores podem ingerir dados do Google BigQuery no Elastic Stack com apenas alguns cliques no Google Cloud Console. Aproveitando os modelos do Dataflow, as integrações nativas permitem que os clientes simplifiquem sua arquitetura de pipeline de dados e eliminem a sobrecarga operacional relacionada à instalação e gerenciamento do agente.
Muitos analistas de dados e desenvolvedores usam o Google BigQuery como solução de data warehouse e o Elastic Stack como solução de busca e visualização de dashboard. Para aprimorar a experiência de ambas as soluções, o Google e a Elastic trabalharam juntos para fornecer uma maneira simplificada de ingerir dados de tabelas e visualizações do BigQuery no Elastic Stack. E tudo isso é possível com apenas alguns cliques no Google Cloud Console, sem precisar instalar agentes de dados ou ferramentas de ETL (extrair, transformar, carregar).
Neste post do blog, mostraremos como começar com a ingestão de dados do Google BigQuery no Elastic Stack sem agente.
Simplifique os casos de uso do BigQuery + Elastic
O BigQuery é uma solução popular de data warehouse sem servidor que possibilita centralizar dados de diferentes fontes, como aplicações customizadas, bancos de dados, Marketo, NetSuite, Salesforce, fluxos de cliques da Web ou até mesmo o Elasticsearch. Os usuários podem fazer junções de conjuntos de dados de diferentes fontes e depois executar consultas SQL para analisar os dados. É comum utilizar a saída de trabalhos SQL do BigQuery para criar mais visualizações e tabelas no BigQuery ou criar dashboards para compartilhar com outras partes interessadas e equipes em sua organização, o que pode ser feito com o Kibana, a ferramenta de visualização de dados nativa da Elastic.
Outro caso de uso importante do BigQuery e do Elastic Stack é uma busca de texto completo. Os usuários do BigQuery podem ingerir dados no Elasticsearch e, em seguida, consultar e analisar os resultados da busca usando APIs do Elasticsearch ou o Kibana.
Simplifique a ingestão de dados
O Google Dataflow é um serviço de mensagens assíncrono e sem servidor baseado no Apache Beam. O Dataflow pode ser usado em vez do Logstash para ingerir dados diretamente do Google Cloud Console. As equipes do Google e da Elastic trabalharam juntas para desenvolver um modelo do Dataflow pronto para uso para enviar dados do BigQuery para o Elastic Stack. Esse modelo substitui o processamento de dados, como a transformação do formato de dados anteriormente concluída pelo Logstash de uma maneira sem servidor — sem outras alterações para quem usava anteriormente o pipeline de ingestão do Elasticsearch.
Se você está usando o BigQuery e o Elastic Stack hoje, precisa instalar um processador de dados separado como o Logstash ou uma solução customizada em uma máquina virtual (VM) do Google Compute Engine e, em seguida, usar um desses processadores de dados para enviar dados do BigQuery para o Elastic Stack. O provisionamento de uma VM e a instalação de um processador de dados exigem um trabalho adicional de processo e gerenciamento. Agora você pode pular essa etapa e ingerir dados diretamente do BigQuery no Elastic usando um menu suspenso no Dataflow. Tirar trabalho da frente é uma iniciativa valiosa para muitos usuários, especialmente quando isso pode ser feito com alguns cliques no Google Cloud Console.
Aqui está um resumo do fluxo de ingestão de dados. A integração funciona para todos os usuários, independentemente de você estar usando o Elastic Stack no Elastic Cloud, o Elastic Cloud no Google Cloud Marketplace ou um ambiente autogerenciado.
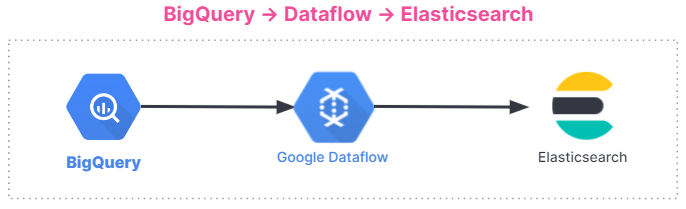
Começar
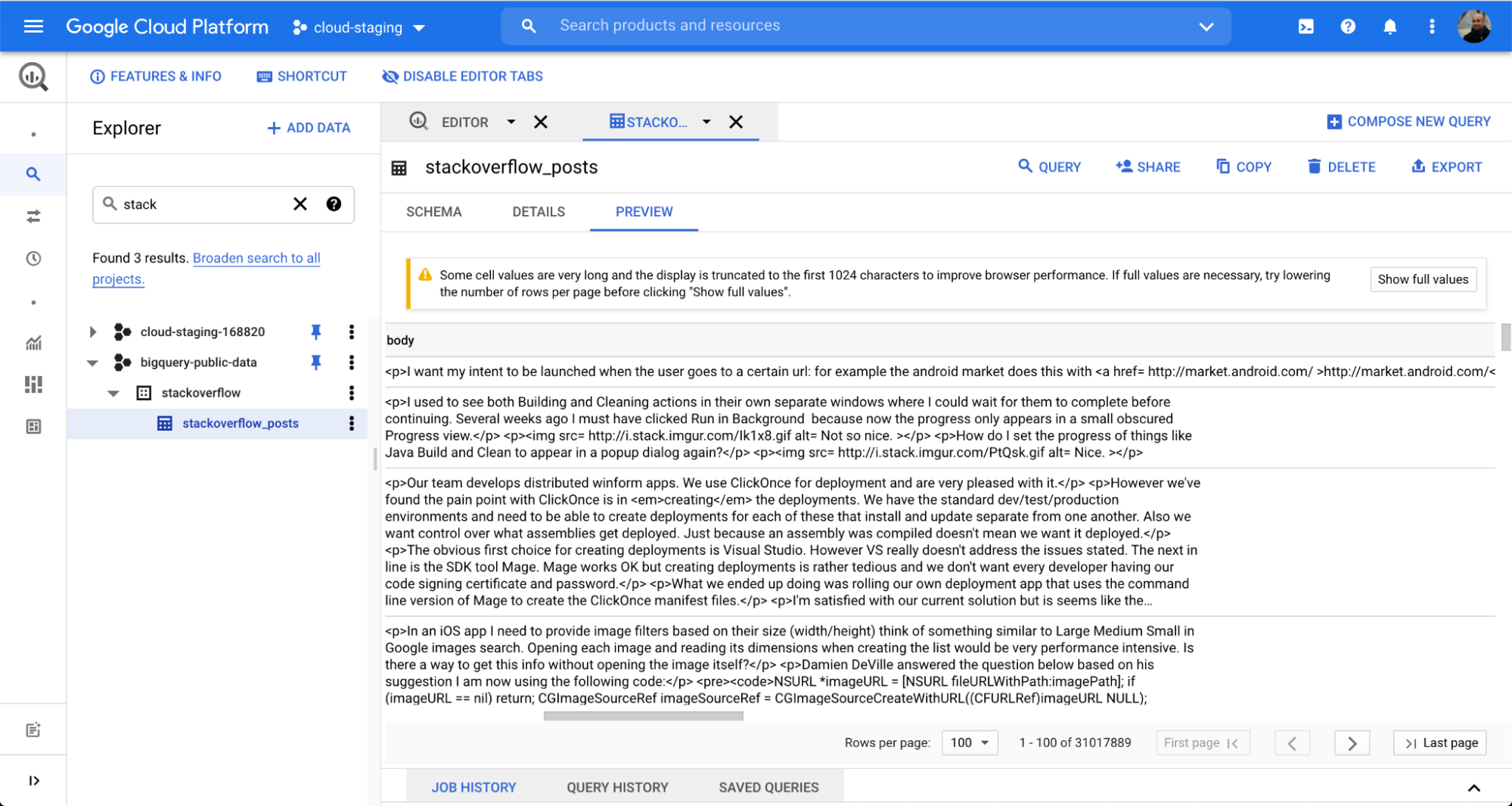
Para ilustrar como é fácil integrar dados do BigQuery no Elasticsearch, usaremos um conjunto de dados público do popular fórum de perguntas e respostas Stack Overflow. Com apenas alguns cliques, você pode ingerir os dados por meio da tarefa em lote do Dataflow e começar a fazer buscas e análises no Kibana.
Usamos uma tabela chamada stackoverflow_posts no conjunto de dados stackoverflow do BigQuery. Ela tem vários campos estruturados como colunas como post body, title, comment_count etc., que vamos trazer para o Elasticsearch para realizar busca e agregação de texto livre.
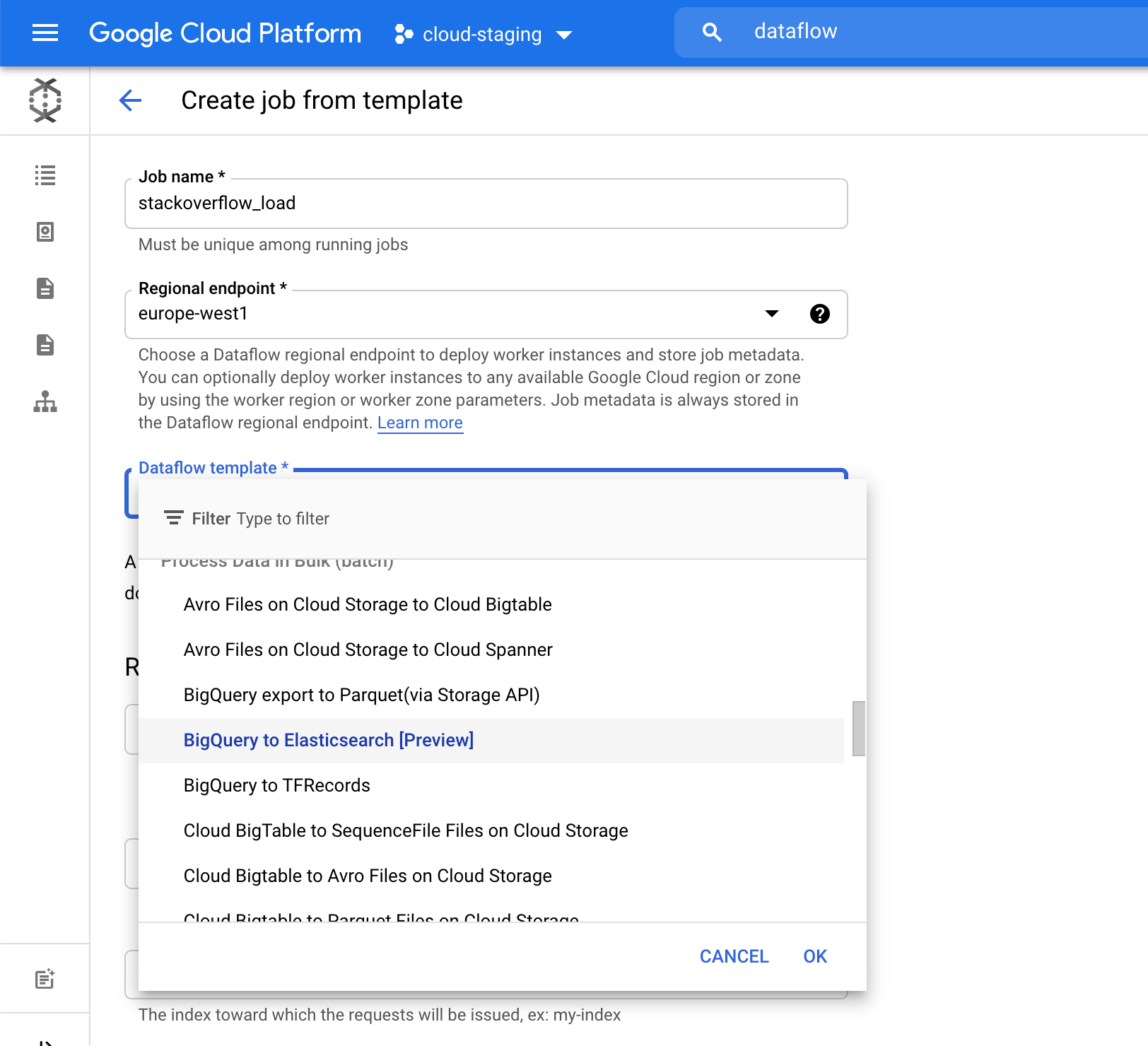
Para o campo Elasticsearch index (Índice do Elasticsearch), escolha o nome de um índice onde seus dados serão carregados. Por exemplo, usamos o índice stack-posts. Tabela no BigQuery para leitura na forma de: my-project:my-dataset.my-table. No nosso exemplo, é bigquery-public-data:stackoverflow.stackoverflow_posts.
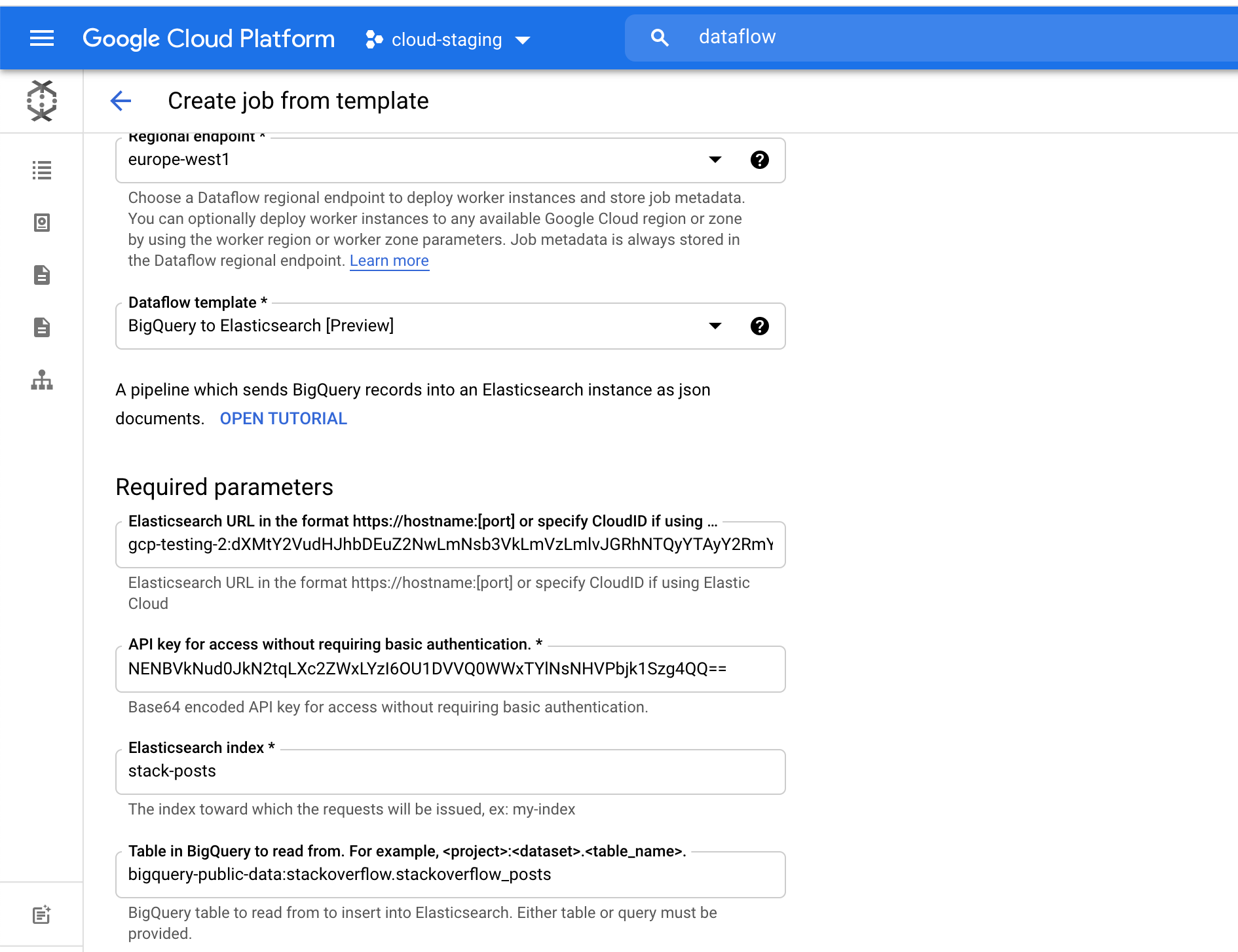
Clique em Run Job (Executar trabalho) para iniciar o processamento em lote.
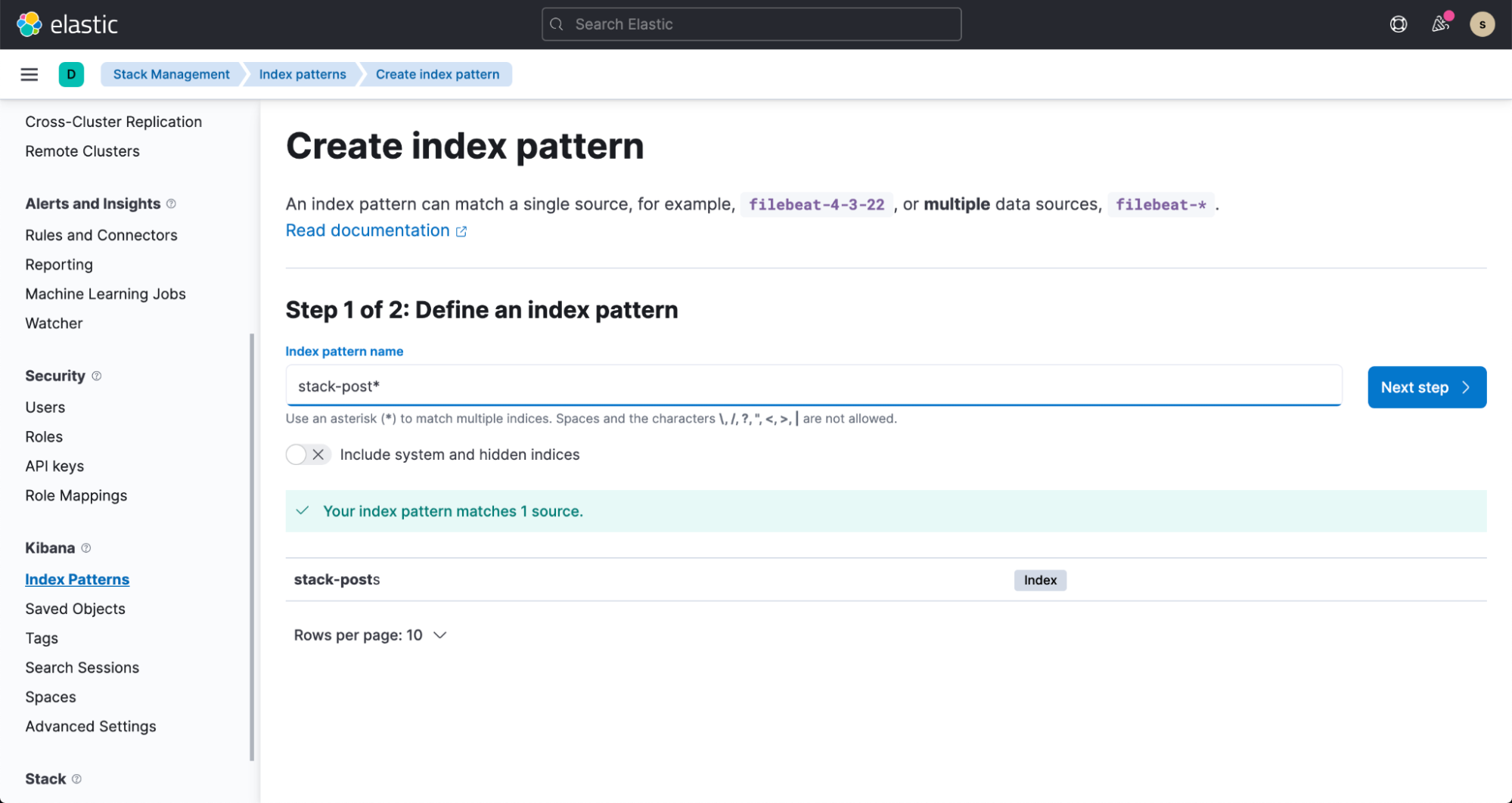
Em alguns minutos, você poderá ver os dados fluindo para o índice do Elasticsearch. Para visualizar esses dados, crie um padrão de indexação seguindo a documentação.
E agora, vá para o Discover no Kibana e comece a fazer buscas nos seus dados!
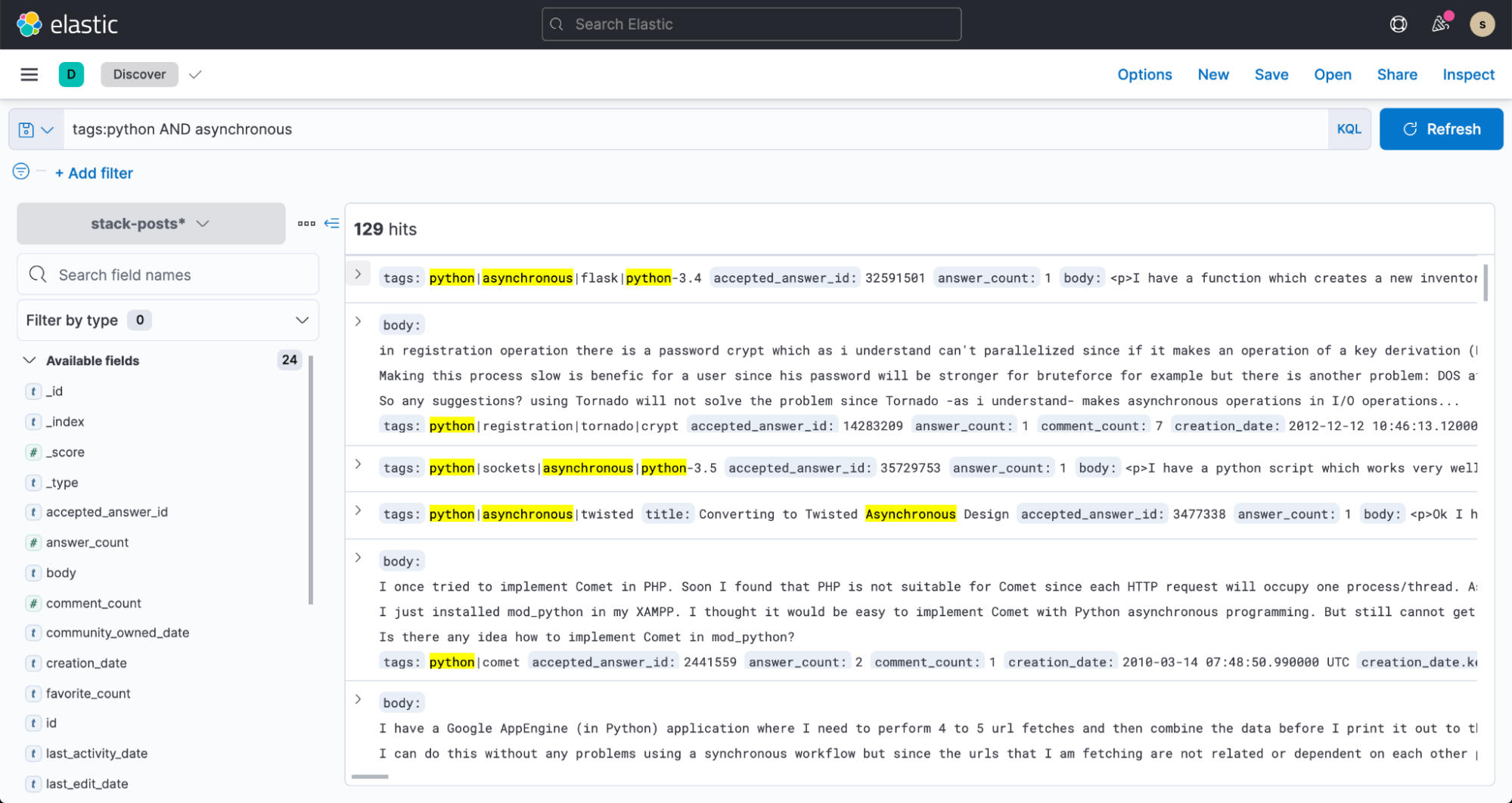
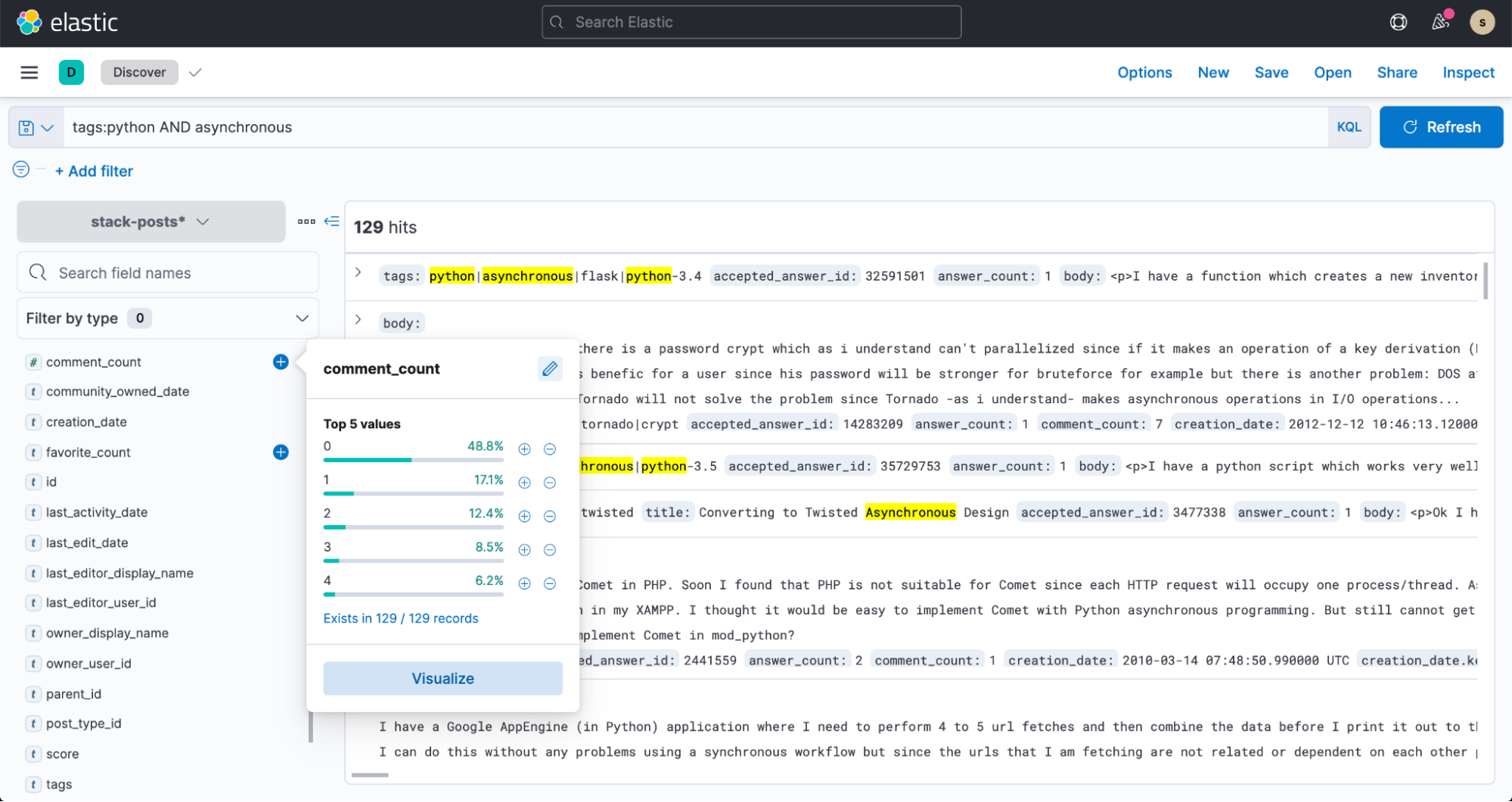
Resumo
A Elastic está sempre buscando facilitar e simplificar para os clientes executarem onde quiserem e usarem o que quiserem — e essa integração com o Google Cloud é o exemplo mais recente disso. O Elastic Cloud estende o valor do Elastic Stack, permitindo que os clientes façam mais e mais rápido, o que o torna a melhor maneira de experimentar a nossa plataforma. Para começar a usar o Elastic no Google Cloud, acesse o Google Cloud Marketplace ou o website elastic.co.Compartilhar
- Share on Twitter
Compartilhar no Twitter
- Share on LinkedIn
Compartilhar no LinkedIn
- Share on Facebook
Compartilhar no Facebook
- Share by Email
Compartilhar por e-mail
- Print this page
Imprimir