Compreendendo a malha de dados no setor público: pilares, arquitetura e exemplos


 Share on Twitter
Share on TwitterCompartilhar no Twitter

 Share on LinkedIn
Share on LinkedInCompartilhar no LinkedIn

 Share on Facebook
Share on FacebookCompartilhar no Facebook

 Share by Email
Share by EmailCompartilhar por e-mail

 Print this page
Print this pageImprimir
Pense em todos os dados por trás de projetos, como inteligência de defesa, registros de saúde pública, modelos de planejamento urbano e muito mais. As agências governamentais geram enormes quantidades de dados o tempo todo. As coisas ficam ainda mais complicadas quando os dados estão espalhados por plataformas de nuvem, sistemas locais ou ambientes especializados, como satélites e centros de resposta a emergências. É difícil encontrar informações, muito menos usá-las de forma eficiente. E com diferentes equipes trabalhando com muitos aplicativos e formatos de dados diferentes, surge uma real falta de interoperabilidade.
Apesar de seus melhores esforços para construir organizações orientadas por dados, a realidade é que 65% dos líderes do setor público ainda têm dificuldades para usar dados continuamente em tempo real e em escala, de acordo com um estudo recente da Elastic.
“Estamos demorando mais para fazer nosso trabalho, o que não é bom, já que a maior parte do nosso trabalho é feito em caso de emergência”, disse um líder do setor público à Elastic. “Precisamos obter informações o mais rápido possível.”
A montanha de dados está crescendo. O acesso a ela é um gargalo. Então, como os órgãos do setor público podem se livrar da complexidade desses silos centralizados? A malha de dados oferece uma maneira alternativa de organizar dados que pode ser a resposta.
O que é malha de dados?
Em termos simples, uma malha de dados supera os silos. Os dados coletados em toda a rede ficam disponíveis para serem recuperados e analisados em qualquer ponto do ecossistema — desde que o usuário tenha permissão para acessá-los. Ela fornece uma camada unificada, porém distribuída, que simplifica e padroniza as operações de dados.

4 pilares da malha de dados
O Data Mesh é baseado em quatro princípios de dados:
Propriedade de domínio: como agências e departamentos gerenciam seus próprios dados
Dados como produto: onde esses proprietários de domínio garantem que seus conjuntos de dados sejam de alta qualidade e facilmente acessíveis
Plataformas de autoatendimento: permita que equipes internas e externas encontrem e usem dados de alta qualidade sem interrupções de TI
Governança federada: garante que tudo esteja funcionando de forma tranquila e segura em todos os sistemas
Vamos examinar cada um deles um pouco mais de perto.
Propriedade do domínio
Em vez de depender de uma equipe central de TI para gerenciar todos os dados, a propriedade dos dados é distribuída entre agências e departamentos governamentais. Basicamente, você está construindo equipes técnicas que refletem a composição da própria agência. Você quer que as pessoas mais intimamente familiarizadas com esses dados sejam as donas deles. Isso pode ser aplicado à saúde pública, defesa, planejamento urbano e muito mais — praticamente qualquer caso de uso do setor público.
Por exemplo, a Agência de Segurança Cibernética e de Infraestrutura dos EUA (CISA) usa uma abordagem de malha de dados para obter visibilidade dos dados de segurança de centenas de agências federais, permitindo que cada agência mantenha o controle de seus dados.
Saiba mais sobre como acelerar o CISA Zero Trust com a Elastic como uma camada de dados unificada.
Isso nos leva ao segundo (e provavelmente o mais importante) pilar — aquele que os outros três pilares foram projetados para sustentar:
Dados como um produto
Cada conjunto de dados é tratado como um produto com documentação e padrões de qualidade claros. O departamento que possui os dados precisa garantir que eles sejam facilmente acessíveis e organizados para quando outros departamentos precisarem. Em outras palavras, eles são responsáveis por compartilhar esses dados como um produto utilizável.
Da perspectiva do governo, isso poderia ser informação de censo, dados de resposta a emergências ou relatórios de inteligência, por exemplo. Tudo depende da estrutura do projeto ou da agência governamental. O importante é que esses dados selecionados estejam prontos para uso quando outras equipes os procurarem, e elas não precisarão gastar tempo limpando ou verificando-os.
Então, você pode perguntar: esta não é apenas outra maneira de isolar dados analíticos? Quais são os detalhes de como outros departamentos podem acessá-lo? Isso nos leva ao nosso próximo pilar.
Plataformas de autoatendimento
Os departamentos estão sendo solicitados a fazer muito aqui e precisarão de plataformas convenientes que tornem seus dados acessíveis a outras pessoas. Catálogos pesquisáveis para fácil descoberta de dados, ferramentas de consulta para análise em tempo real e a capacidade dos usuários de limpar e integrar dados, bem como compartilhar insights por meio de painéis e APIs, são todas ferramentas que podem ser usadas.
Eles também precisarão de governança integrada para impor controles de acesso, o que nos leva ao nosso pilar final.
Governança computacional federada
Então, estabelecemos que cada departamento está no controle de seus próprios dados. No entanto, a malha de dados ainda precisa de protocolos de governança abrangentes para mantê-la segura e evitar riscos.
Esses controles de segurança devem ser incorporados ao sistema que recupera os dados, em vez de serem aplicados separadamente por cada departamento. O sistema deve verificar as permissões do usuário como parte da pesquisa e garantir que as pessoas vejam apenas os dados aos quais têm permissão de acesso desde o início.
No setor público, isso pode ser qualquer coisa, desde regulamentações de privacidade em dados de saúde até informações confidenciais em sistemas de defesa.
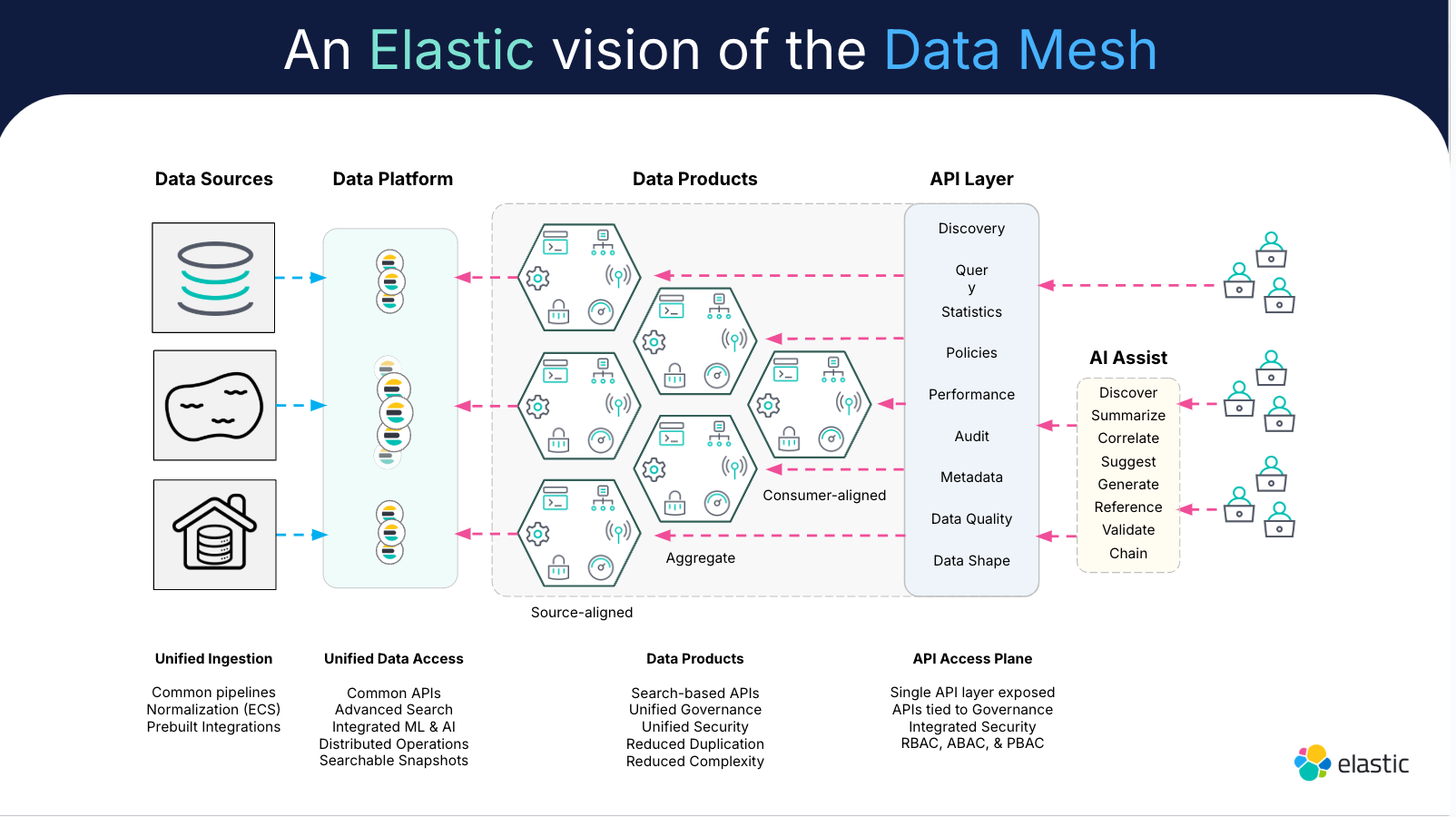
Arquitetura de malha de dados
Uma arquitetura de malha de dados é um framework que une os pilares da malha de dados em um processo para gerenciar dados distribuídos.
Implementar uma arquitetura de malha de dados reduz o atrito no processo de colaboração. É um divisor de águas para as equipes que trabalham com dados específicos de domínio para treinamento e análise de modelos, graças à sua abordagem mais centrada no usuário.
A malha de dados ajuda a permitir um tratamento e governança de dados mais eficientes em escala, apesar das múltiplas plataformas e equipes de implementação. A arquitetura de malha de dados cria mais autonomia e mais democratização de dados — se você tiver observabilidade de dados escalável e autossuficiente. A observabilidade de dados é o que permite que as equipes gerenciem todos esses dados em um único painel.
A observabilidade efetiva dos dados é incorporada à arquitetura de uma malha de dados. É o que dá às equipes acesso a insights que podem usar de todos os dados que coletam. Pense desta forma: a observabilidade de dados significa ter os olhos postos na saúde e integridade dos dados, enquanto as arquiteturas de malha de dados tratam do gerenciamento descentralizado desses dados. E para gerenciá-lo, você precisa ser capaz de vê-lo em detalhes.
Malha de dados vs. outras abordagens
Como a malha de dados se compara a formas alternativas de arquitetura e armazenamento de dados analíticos? Vejamos outros dois que frequentemente geram comparações: data fabric e data lakes.
Malha de dados vs. tecido de dados
A malha de dados e o tecido de dados são abordagens semelhantes, pois ambos adotam uma abordagem descentralizada, coletando dados em locais remotos. No entanto, um tecido de dados pega os dados coletados em um site e os copia para outro site. Esses dados são compartilhados como registros individuais e não podem ser correlacionados com outros registros, a menos que sejam consumidos por algo que faça sentido. Essa abordagem muitas vezes pode levar a silos de dados.
Uma abordagem de malha de dados, por outro lado, não depende da cópia de dados e, em vez disso, indexa os dados localmente ao ingeri-los em uma plataforma distribuída, onde os usuários podem pesquisar dados localmente e em sites remotos. Neste modelo, os dados são unificados na camada da plataforma de pesquisa. Os dados são indexados uma vez e depois ficam disponíveis para qualquer usuário autorizado ou caso de uso por meio dessa camada unificada.
Malha de dados vs. data lake
Você deve ter notado que há muitas metáforas relacionadas à água nos dados: fluxos de dados, pipelines de dados, etc. Dados, assim como a água, podem ser coletados, armazenados, filtrados e distribuídos — às vezes de forma eficiente, às vezes de forma caótica.
Da mesma forma que um lago coleta água de várias fontes, um data lake coleta dados e os armazena para uso futuro. Em outras palavras, é um ambiente de armazenamento para qualquer combinação de dados estruturados, semiestruturados ou não estruturados.
Às vezes, os data lakes podem ser úteis para proprietários de domínios de malha de dados enquanto eles processam e selecionam seus produtos de dados. Eles podem usar um data lake para armazenamento de longo prazo de grandes conjuntos de dados não estruturados (digamos, imagens de satélite ou registros públicos) que ainda não têm uma finalidade específica. Mas se um data lake se torna desorganizado e difícil de navegar, ele se transforma em um pântano de dados — obscuro, desorganizado e difícil de extrair valor.
Malha de dados e IA
A malha de dados pode oferecer uma maneira de democratizar a IA e o aprendizado de máquina para agências do setor público. Tradicionalmente, as equipes de ciência de dados operam como hubs centralizados, extraindo dados de várias fontes para desenvolver modelos de aprendizado de máquina. No entanto, como observado anteriormente, esse processo pode causar trabalho redundante e inconsistências, levando a desafios com a reprodutibilidade do modelo.
Ao inverter esse modelo com a malha de dados e incorporar o desenvolvimento de IA nas equipes de domínio, você pode limpar e refinar os dados em sua fonte e criar um produto de dados orientado por IA que outros departamentos podem utilizar.
Tome como exemplo a resposta a desastres nacionais. Modelos de IA incorporados em equipes de resposta a emergências frequentemente analisam dados como imagens de satélite em tempo real, dados de sensores e até mesmo relatórios de mídia social para identificar as áreas mais afetadas. Com a malha de dados, diferentes agências, desde agências governamentais até socorristas, podem acessar essas informações imediatamente, sem esperar pelo processamento centralizado, e, como resultado, melhorar seus tempos de resposta.
A malha de dados também melhora a governança da IA porque a incorpora desde o início, padronizando tarefas como validação de modelo, detecção de viés, explicabilidade e monitoramento de desvio de modelo.
Como implementar malha de dados para o setor público
Cada organização do setor público tem um conjunto exclusivo de necessidades de dados, e é por isso que os silos de dados de tamanho único podem ser lentos e sufocantes para usuários internos e externos. Dois em cada três líderes do setor público disseram que estão insatisfeitos com os insights de dados disponíveis para eles.
A malha de dados pode ser personalizada de acordo com as necessidades específicas de cada agência do setor público, desde defesa até segurança nacional ou governos federal, estadual e local.
Para começar a usar a malha de dados, as agências do setor público precisarão seguir algumas etapas:
Atribua responsabilidade pelos dados a departamentos específicos.
Trate os conjuntos de dados como ativos bem documentados e acessíveis, projetados para uso interno e externo, e certifique-se de que eles estejam em conformidade com os requisitos regulatórios.
Implemente ferramentas que permitam que agências, analistas e formuladores de políticas acessem e analisem dados facilmente, sem depender de equipes de TI centralizadas.
Aplique a governança em todas as agências, tendo em mente frameworks como FedRAMP, CMMCe Zero Trust.
E, finalmente, incentive o compartilhamento de dados entre as organizações para tomar melhores decisões e melhorar os serviços públicos, mantendo os controles de segurança.
Aplicações governamentais e de defesa
A malha de dados é uma opção natural para os setores governamentais e de defesa, onde grandes conjuntos de dados distribuídos precisam ser acessados com segurança e analisados em tempo real.
Na defesa, auxilia na coleta mais rápida de informações e na gestão de ativos, permitindo que operadores em campo atuem com os dados mais recentes. Na saúde pública, pode ajudar a integrar rapidamente dados epidemiológicos de hospitais ou laboratórios de pesquisa para responder a surtos. Departamentos de transporte podem analisar dados de trânsito e meteorológicos em todas as cidades. Departamentos de educação podem visualizar as notas de testes das crianças na última década e cruzá-las com outros dados, como o tempo gasto em aprendizagem remota versus presencial.
Vejamos o exemplo da Marinha dos EUA: seu impulso para a modernização digital depende da capacidade de "mover com segurança qualquer informação de qualquer lugar para qualquer lugar" para alcançar a superioridade informacional. Mas o armazenamento centralizado de dados tradicional é muito arriscado, especialmente em ambientes com isolamento térmico e Negado, Degradado, Intermitente e Limitado (DDIL). Aqui está um caso em que uma malha global de dados pode ajudar, permitindo que os dados permaneçam em sua origem, enquanto ainda podem ser pesquisados e acessados em todo o vasto cenário operacional da Marinha. Essa abordagem descentralizada mantém as operações resilientes mesmo em caso de falha de um servidor ou data center e fornece uma visão unificada dos dados de missão crítica sem a necessidade de movê-los ou duplicá-los.
Malha de dados em ação com a Elastic
Como a Search AI Company, a plataforma de análise de dados Elastic serve como uma poderosa malha de dados global, oferecendo machine learning, processamento de linguagem natural, pesquisa semântica, alertas e visualização em um sistema unificado. Em outras palavras, a Elastic tem uma função unificadora ao oferecer às agências visibilidade total de seus dados, bem como a capacidade de ingeri-los, organizá-los, acessá-los e analisá-los.
Três recursos principais diferenciam a Elastic:
Cross-cluster search (CCS), que permite executar uma única solicitação de search em um ou mais clusters remotos
snapshots pesquisáveis, que fornecem uma maneira econômica para acessar e consultar dados históricos usados com pouca frequência
Controle de acesso por função, que fornece segurança integrada
A abordagem de malha de dados da Elastic também pode servir como base para frameworks de segurança modernos, como Zero Trust, e abre novas possibilidades para operações orientadas por dados.
Saiba mais sobre como a Elastic ajuda as equipes governamentais, de saúde e de educação a maximizar o valor dos dados com velocidade, escala e relevância.
Explore mais malhas de dados nos recursos do setor público
O lançamento e o tempo de amadurecimento de todos os recursos ou funcionalidades descritos neste artigo permanecem a exclusivo critério da Elastic. Os recursos ou funcionalidades não disponíveis no momento poderão não ser entregues ou não chegarem no prazo previsto.
Nesta postagem do blog, podemos ter usado ou feito referência a ferramentas de IA generativa de terceiros, que são de propriedade e operadas por seus respectivos proprietários. A Elastic não tem nenhum controle sobre as ferramentas de terceiros e não temos nenhuma responsabilidade ou obrigação por seu conteúdo, operação ou uso, nem por qualquer perda ou dano que possa surgir do uso de tais ferramentas. Tenha cuidado ao usar ferramentas de IA com informações pessoais, sensíveis ou confidenciais. Os dados que você enviar poderão ser usados para treinamento de IA ou outros fins. Não há garantia de que as informações fornecidas serão mantidas em segurança ou em confidencialidade. Você deve se familiarizar com as práticas de privacidade e os termos de uso de qualquer ferramenta de IA generativa antes de usá-la.
Elastic, Elasticsearch, ESRE, Elasticsearch Relevance Engine e marcas associadas são marcas comerciais, logotipos ou marcas registradas da Elasticsearch N.V. nos Estados Unidos e em outros países. Todos os outros nomes de empresas e produtos são marcas comerciais, logotipos ou marcas registradas de seus respectivos proprietários.
Compartilhar
- Share on Twitter
Compartilhar no Twitter
- Share on LinkedIn
Compartilhar no LinkedIn
- Share on Facebook
Compartilhar no Facebook
- Share by Email
Compartilhar por e-mail
- Print this page
Imprimir