NLP를 배포하는 방법: 정서 분석 예제


 Share on Twitter
Share on Twitter트위터에서 공유하기

 Share on LinkedIn
Share on LinkedIn링크드인에서 공유하기

 Share on Facebook
Share on Facebook페이스북에서 공유하기

 Share by Email
Share by Email이메일로 공유하기

 Print this page
Print this page인쇄하기
여기에서는 자연어 처리(NLP)에 대한 여러 블로그 시리즈의 한 파트로서, 정서 분석 NLP 모델을 사용하여 댓글(텍스트) 필드에 긍정적 또는 부정적 정서가 포함되어 있는지 평가하는 예제를 살펴보겠습니다. 공개 모델을 사용하여 해당 모델을 Elasticsearch에 배포하고 이를 수집 파이프라인에서 사용하여 고객 리뷰를 긍정적 또는 부정적으로 분류하는 방법을 보여드리겠습니다.
정서 분석은 필드가 둘 중 하나의 값으로 예측되는 이진 분류의 하나입니다. 일반적으로 해당 예측에는 0과 1 사이의 확률 점수가 있으며, 1에 가까울수록 예측이 정확함을 나타냅니다. 이러한 유형의 NLP 분석은 제품 리뷰 또는 고객 피드백과 같은 많은 데이터 세트에 유용하게 적용될 수 있습니다.
우리가 분류하고자 하는 고객 리뷰는 2015 Yelp Dataset Challenge의 공개 데이터 세트입니다. Yelp Review 사이트에서 분류한 이 데이터 세트는 정서 분석을 테스트하기에 안성맞춤인 리소스입니다. 이 예제에서는 공통 정서 분석 NLP 모델로 Yelp 리뷰 데이터 세트의 샘플을 평가하고, 이 모델을 사용하여 댓글을 긍정적 또는 부정적으로 레이블을 지정하겠습니다. 이를 통해 긍정적 리뷰와 부정적 리뷰의 비율을 알아내고자 합니다.
Elasticsearch에 정서 분석 모델 배포
docker run -it --rm elastic/eland \
eland_import_hub_model \
--url $ELASTICSEARCH_URL \
--hub-model-id distilbert-base-uncased-finetuned-sst-2-english \
--task-type text_classification \
--start
이번에는 --task-type이 text_classification으로 설정되고 --start 옵션이 Eland 스크립트로 전달되므로, 모델 관리 UI에서 시작할 필요 없이 모델이 자동으로 배포됩니다.
배포되면, Kibana 콘솔에서 다음 예제를 따라 해 보세요.
POST _ml/trained_models/distilbert-base-uncased-finetuned-sst-2-english/deployment/_infer
{
"docs": [
{
"text_field": "The movie was awesome!"
}
]
}
결과는 다음과 같은 형태입니다.
{
"predicted_value" : "POSITIVE",
"prediction_probability" : 0.9998643924765398
}
다음 예제도 수행해 볼 수 있습니다.
POST _ml/trained_models/distilbert-base-uncased-finetuned-sst-2-english/deployment/_infer
{
"docs": [
{
"text_field": "The cat was sick on the bed"
}
]
}
고양이와 시트를 청소하는 사람 모두에게 매우 부정적인 반응을 일으킵니다.
{
"predicted_value" : "NEGATIVE",
"prediction_probability" : 0.9992468477843378
}
Yelp 리뷰 분석
서론에서 언급했듯이 Hugging Face에 제공된 Yelp 리뷰 중 수동으로 정서가 표시된 하위 집합을 사용할 것입니다. 이를 통해 결과를 마크업 인덱스와 비교할 수 있습니다. 추론 프로세서로 처리하기 위해 Kibana의 파일 업로드 기능을 사용하여 이 데이터 세트의 샘플을 업로드합니다.
이전 블로그 게시물에서처럼 Kibana 콘솔에서 수집 파이프라인을 생성할 수 있는데, 이번에는 정서 분석을 위한 수집 파이프라인을 만들고 이를 sentiment라고 부릅니다. 리뷰는 review라는 이름의 필드에 있습니다. 이전과 마찬가지로, field_map을 정의하여 모델이 예상하는 필드에 review를 매핑하겠습니다. NER 파이프라인의 동일한 on_failure 핸들러가 다음과 같이 설정됩니다.
PUT _ingest/pipeline/sentiment
{
"processors": [
{
"inference": {
"model_id": "distilbert-base-uncased-finetuned-sst-2-english",
"field_map": {
"review": "text_field"
}
}
}
],
"on_failure": [
{
"set": {
"description": "Index document to 'failed-<index>'",
"field": "_index",
"value": "failed-{{{_index}}}"
}
},
{
"set": {
"description": "Set error message",
"field": "ingest.failure",
"value": "{{_ingest.on_failure_message}}"
}
}
]
}
리뷰 문서는 Elasticsearch 인덱스 yelp-reviews에 저장됩니다. reindex API를 사용하여 정서 분석 파이프라인을 통해 리뷰 데이터를 푸시합니다. 재색인이 모든 문서를 처리하고 추론하는 데 다소 시간이 걸릴 것을 감안하여, wait_for_completion=false 플래그로 API를 호출하여 백그라운드에서 재색인을 수행합니다. Task management API로 진행 상황을 확인하세요.
POST _reindex?wait_for_completion=false
{
"source": {
"index": "yelp-reviews"
},
"dest": {
"index": "yelp-reviews-with-sentiment",
"pipeline": "sentiment"
}
}
위와 같이 하면 작업 ID가 반환됩니다. 다음 명령을 통해 작업 진행 상황을 모니터링할 수 있습니다.
The above returns a task id. We can monitor progress of the task with:
또는 모델 통계 UI에서 추론 횟수가 증가하는 것을 관찰하여 진행 상황을 추적할 수도 있습니다.

재색인된 문서에는 이제 추론 결과가 포함됩니다. 예를 들어, 분석된 문서 중 하나는 다음과 같습니다.
{
"review": "The food is good. Unfortunately the service is very hit or miss. The main issue seems to be with the kitchen, the waiters and waitresses are often very apologetic for the long waits and it's pretty obvious that some of them avoid the tables after taking the initial order to avoid hearing complaints.",
"ml": {
"inference": {
"predicted_value": "NEGATIVE",
"prediction_probability": 0.9985209630712552,
"model_id": "distilbert-base-uncased-finetuned-sst-2-english"
}
},
"timestamp": "2022-02-02T15:10:38.195345345Z"
}
예측 값은 NEGATIVE이며, 이는 열악한 서비스를 감안할 때 타당합니다.
얼마나 많은 리뷰가 부정적인지 시각화
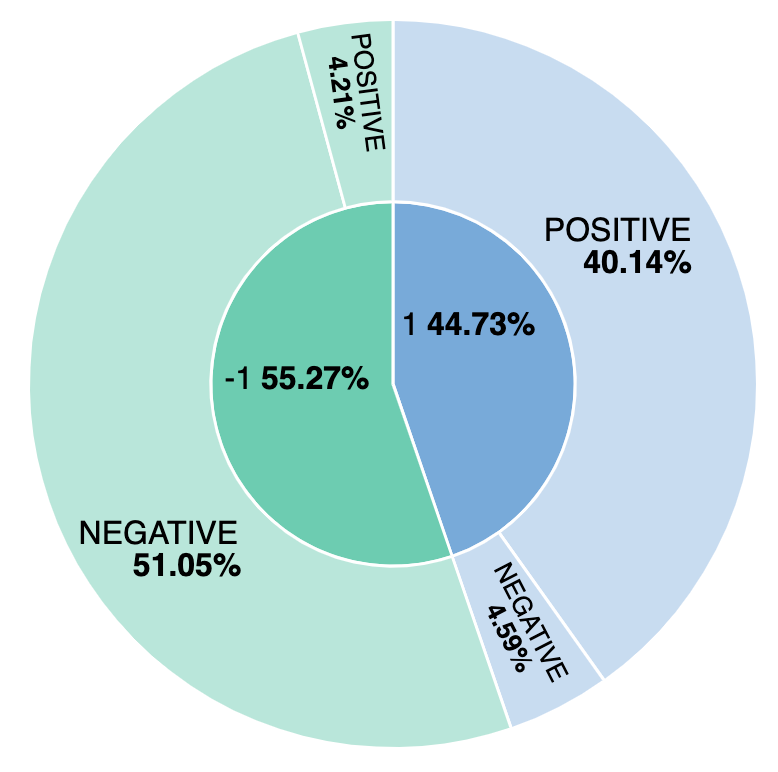
리뷰의 몇 퍼센트가 부정적입니까? 그리고 우리 모델은 수동으로 레이블이 지정된 정서와 비교하면 어떻습니까? 모델의 긍정적 또는 부정적 리뷰와 수동으로 표시된 긍정적 또는 부정적 리뷰를 추적하는 간단한 시각화를 구축하여 확인해 보겠습니다. ml.inference.predicted_value field를 기반으로 시각화를 생성하여 비교한 것을 보면 리뷰의 약 44%가 긍정적인 것으로 간주되고 그중 4.59%가 정서 분석 모델에서 레이블이 잘못 지정되었음을 확인할 수 있습니다.
직접 사용해 보기
다른 NLP 관련 글을 읽고 싶으시면 다음을 참조하세요.
공유하기
- Share on Twitter
트위터에서 공유하기
- Share on LinkedIn
링크드인에서 공유하기
- Share on Facebook
페이스북에서 공유하기
- Share by Email
이메일로 공유하기
- Print this page
인쇄하기