Elastic Stack 7.0.0 출시
7.0을 소개합니다! 이번 릴리즈는 861명의 커미터가 제출한 10,000여 개의 끌어오기 요청으로 이루어졌습니다. 따라서 무엇보다도 우리 직원 여러분과 커뮤니티에게 큰 감사를 드리고 싶습니다.
코드에 기여하신 분들에게서 릴리즈에 대한 이야기를 듣고 싶으시면, 2019년 4월 25일 오전 8시(태평양 연안 표준시, PDT)에 라이브 가상 출시 이벤트를 개최할 예정이오니, 7.0 데모와 전 세계의 Elastic 엔지니어가 함께 하는 AMA(무엇이든 물어보세요) 부스 등 여러 가지 행사에 참여해 주시기 바랍니다.
Elastic Stack 7.0은 다운로드하여 즉시 사용할 수 있으며 또는 Elastic Cloud의 Elasticsearch Service에서 완전한 관리형 배포를 스핀업할 수 있습니다. Elastic Cloud의 [Elasticsearch Service]는 새로운 Elastic Stack 버전을 출시 당일에 바로 제공하는 유일한 호스트형 솔루션입니다.
7.0에 수많은 기능을 담았기 때문에, 어디서부터 말씀드려야 할지 모르겠지만, 바로 시작해 보겠습니다.
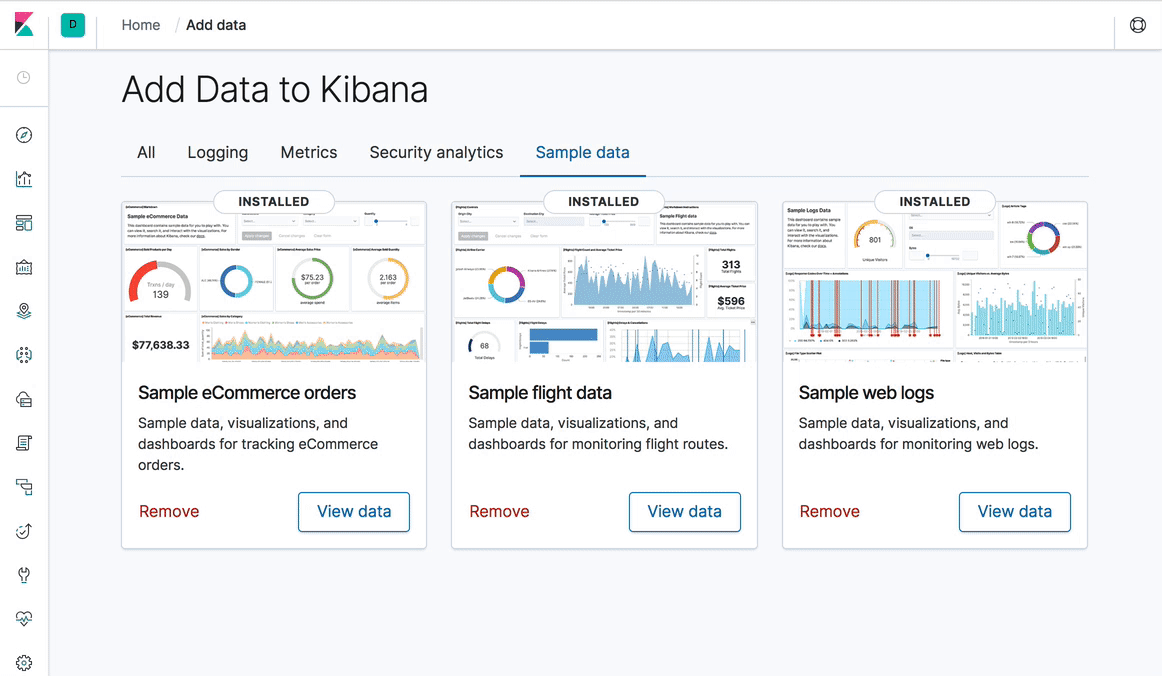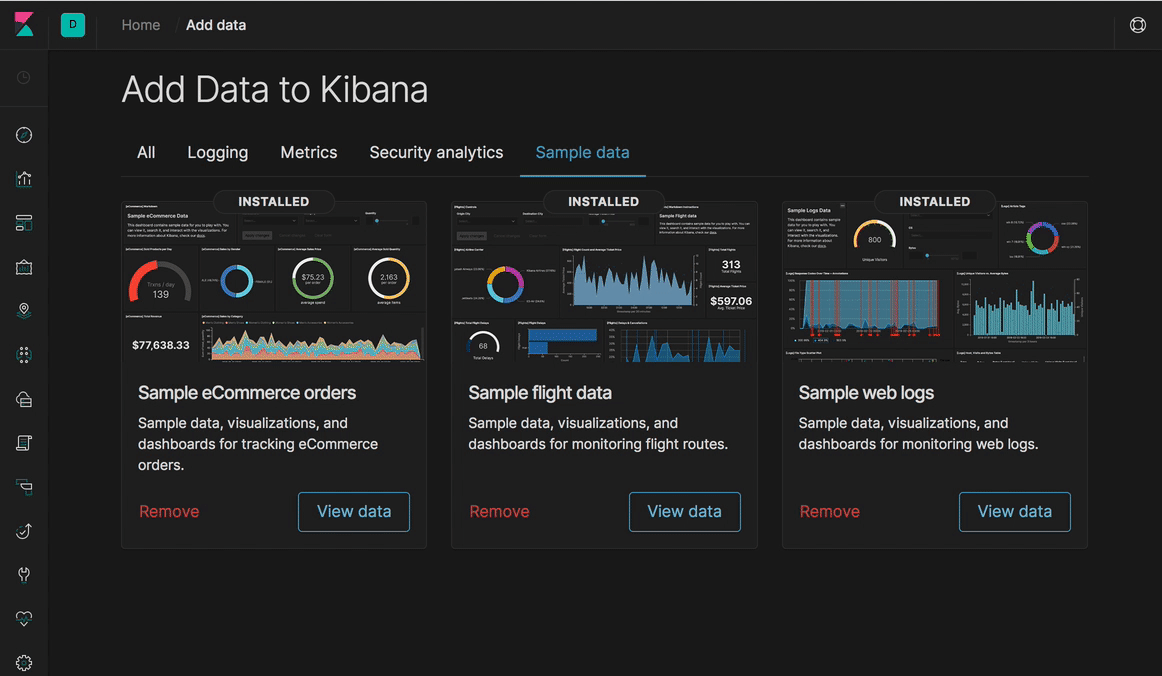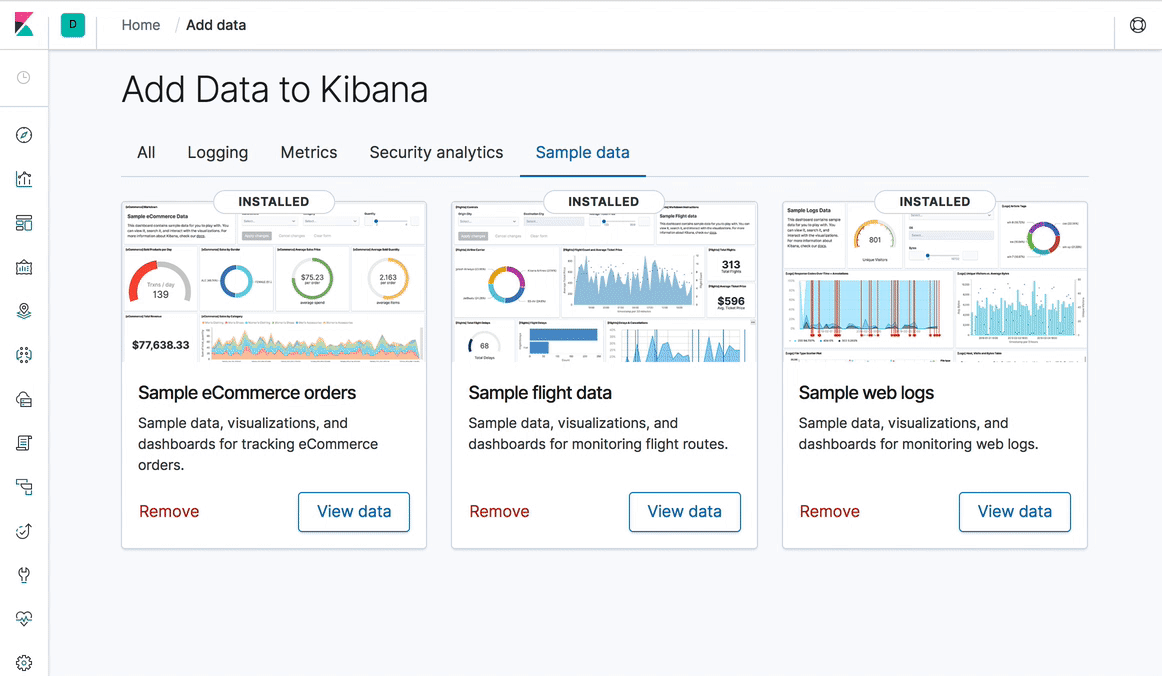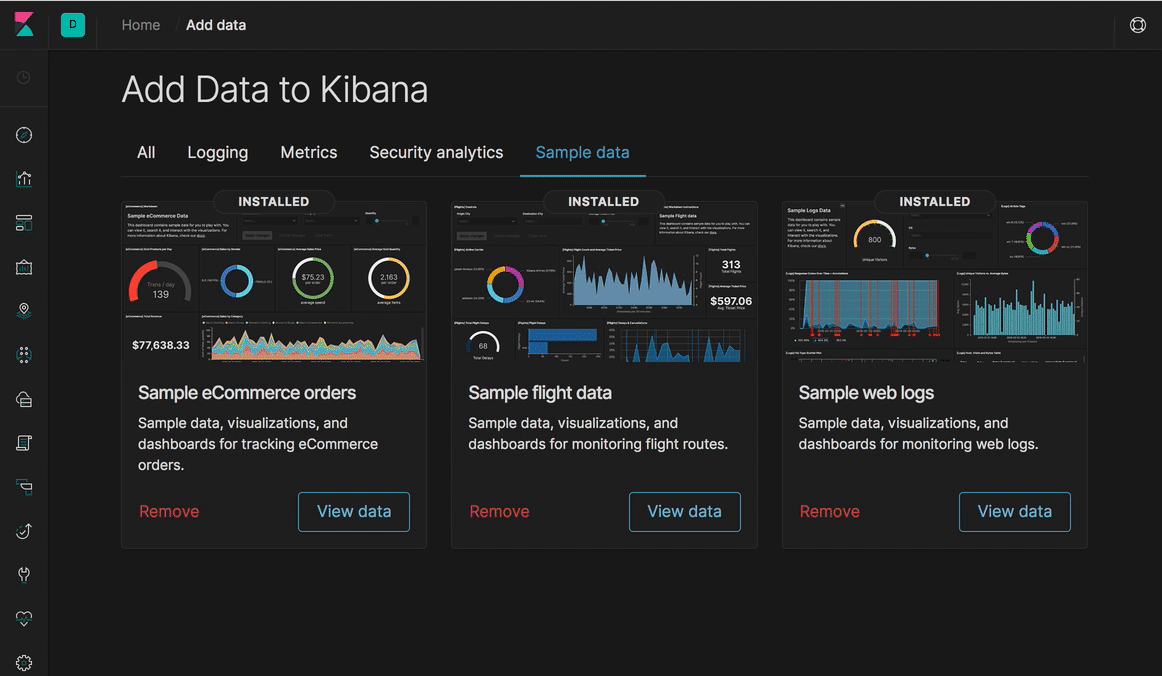
Kibana 7.0: 새로운 디자인과 탐색...그리고 다크 모드!
Kibana 7.0 디자인의 경우, 우리는 콘텐츠에 중점을 두기로 결정했습니다. 따라서 전반적으로 UI가 한결 가볍고 보다 미니멀한 느낌이라고 생각하실 것입니다. 가장 눈에 띄는 변경 사항은 새로운 글로벌 탐색으로의 전환입니다. 이를 위해 상수 헤더를 도입하여 Kibana 공간을 전환하고, 이동 경로를 표시하며, 비밀번호 변경이나 로그아웃 같은 사용자 작업을 시작합니다. 이 변경 작업을 완료하고 일관성을 향상시키기 위해, Elastic UI 프레임워크를 만들었습니다. 지난 해에는 이러한 구성 요소를 사용해 Kibana가 거의 완전히 변모되었습니다. 이러한 구성 요소와 디자인 팀, 엔지니어링 팀의 엄청나게 힘든 노력을 통해, 우리는 스타일과 스타일 시트가 적용되는 방법에서도 극적인 간소화를 이루어냈습니다.
이렇게 향상된 일관성과 스타일 시트를 통해 Kibana 역사상 가장 큰 기능 요청 중 하나처럼 느껴졌던 작업을, 바로 Kibana 전체적으로 적용된 다크 모드를 끝마칠 수 있었습니다. 이런 변경으로 얻게 되는 또 다른 장점은 이제 Kibana 대시보드가 반응이 빠른 디자인을 갖게 되었다는 것입니다. 이것은 모바일 장치에서 사용성을 극적으로 개선하는 첫 단계입니다.
Elasticsearch 클러스터 조정의 신기원
처음부터 우리는 Elasticsearch를 쉽게 확장할 수 있고, 치명적인 오류가 발생하더라도 잘 복원될 수 있도록 하는 데 중점을 두었습니다. 이 요구 사항을 지원하기 위해, 우리는 개별 노드를 좀더 확장 가능하고 안정적으로 만드는 것에서부터 Zen Discovery라고도 하는 클러스터 조정 레이어에 대한 지속적인 개선에 이르기까지 여러 가지 접근 방식을 취해 왔습니다. 7.0에서는 이 두 영역에서 다시 한 번 큰 개선 사항을 도입하게 됩니다.
Elasticsearch를 위한 완전히 새로운 클러스터 조정 레이어가 있으며 훨씬 빠르고 안전하고 사용하기 쉽습니다. 이를 위해, 먼저 디자인을 검증하기 위해 정형 모델을 사용하여 새로운 분산 합의 알고리즘의 이론적인 정확성에 중점을 두었습니다. Paxos, Raft, Zab, Viewstamped Replication(VR) 등과 같이 잘 알려진 합의 알고리즘이 있긴 하지만, Elasticsearch 클러스터의 요구 사항에는 클러스터 변경을 위한 더 높은 처리량, 간편한 클러스터 확장 또는 축소 지원, 6.7 클러스터를 7.0으로 롤링 업그레이드할 수 있도록 하기 위한 원활한 롤링 업그레이드 전략이 포함됩니다. 이러한 기능은 위에서 언급한 알고리즘에서는 제공할 수 없는 것들입니다. 새 클러스터 조정 레이어는 또한 인적 오류가 발생할 가능성을 줄이고, 치명적인 오류에서 복구할 때 더 분명한 선택을 제공하는 여러 변경 사항을 포함합니다. 안정성, 성능, 사용자 환경을 모두 동시에 개선하는 것은 쉽지 않습니다. 특히 그러한 중앙 구성 요소에서는 더 그렇습니다. 우리는 새 조정 레이어와 지금까지의 개발 프로세스에 대해 자부심을 느낍니다. 더 자세한 정보는 블로그를 읽어보세요.
Elasticsearch의 개별 노드는 복원력을 염두에 두고 구축됩니다. 노드에 요청을 너무 많이 보내거나 요청이 너무 크면, 노드는 푸시백을 하게 됩니다. Elasticsearch에서는 이를 위해 회로 차단기를 사용합니다. 이것은 노드가 해당 요청을 처리할 수 없을 것이라는 결정을 내리고 즉시 클라이언트에게 가능하면 다른 노드에서 다시 시도하도록 요청함으로써 응답합니다. 사용자들이 방대한 멀티테넌트 클러스터보다는 테넌트당 클러스터 모델로 옮겨가고 있기 때문에 좀더 일반적이 되고 있는 JVM 힙 크기가 더 작은 노드의 경우, 이것이 훨씬 더 중요합니다. 7.0에서는 실제 메모리 회로 차단기를 도입하고 있습니다. 이것은 사용할 수 없는 요청을 훨씬 더 정확하게 감지하고, 개별 노드가 불안정해지지 않도록 방지합니다. 이러한 변경 사항으로 전체 노드 및 클러스터 안정성이 어떻게 개선되는지에 대한 자세한 정보는 블로그를 읽어보시기 바랍니다.
사용 사례에서 정확도 및 속도 개선
정확도와 속도는 좋은 검색 환경의 초석입니다. Elasticsearch 7.0은 몇 가지 기본 기능을 도입하여 이 두 가지를 모두 개선합니다.
- 더욱 빠른 상위 k개 쿼리: 많은 검색 사용 사례에서, 상위 k개(예: 20위권) 쿼리 결과를 신속하게 보는 것은 정확한 적중 횟수(즉, 쿼리에 일치되는 총 결과 수)보다 사용자에게 훨씬 더 중요합니다. 예를 들어, 누군가가 전자상거래 웹 사이트에서 어느 상품을 찾고 있다면, 그 사람은 자신의 검색 쿼리에 일치되는 120,897개의 다른 결과보다 가장 정확도가 높은 결과 10개에 더 관심이 많을 것입니다. Elasticsearch 7.0(과 Lucene 8.0)은 상위 적중 결과를 검색할 때 속도를 엄청나게 향상시키는 [새로운 알고리즘(Block-Max WAND)](Block-Max WAND)](https://www.elastic.co/kr/blog/faster-retrieval-of-top-hits-in-elasticsearch-with-block-max-wand)을 구현합니다.
- 간격 쿼리: 법률 검색 및 특허 검색 등 일부 검색 사용 사례의 경우, 단어나 구절이 서로 특정 거리 내에 있는 레코드를 찾아야 할 필요가 생깁니다. Elasticsearch 7.0에서 간격 검색은 그러한 쿼리를 구조화하는 완전히 새로운 방식을 도입하며, 이전 방법(범위 쿼리)에 비해 사용과 정의가 상당히 간단해졌습니다. 간격 쿼리는 또한 범위 쿼리에 비해 경계 사례에 대한 복원성이 훨씬 더 큽니다.
- Function score 2.0: 사용자가 정확도와 결과 순위에 대해 훨씬 더 정밀하게 컨트롤하려고 하는 고급 검색 사용 사례의 경우, 사용자 정의 점수는 수익과 직결됩니다. Elasticsearch는 초창기부터 그렇게 할 수 있는 기능을 제공해 왔습니다. 7.0은 차세대 함수 점수 기능을 도입하여 레코드당 순위 점수를 생성할 수 있는 훨씬 간단하고 유연한 모듈식 방법을 제공합니다. 새로운 모듈식 구조를 통해 사용자는 한 세트의 산술 및 거리 함수를 조합하여 임의의 함수 점수 계산을 생성함으로써 결과에 대한 점수와 순위가 매겨지는 방식에 대해 좀더 컨트롤할 수 있습니다.
Elastic Maps에서 geotile 그리드를 이용한 부드러운 확대/축소
Elasticsearch에 위치 정보 지원이 처음 추가된 초창기 시절부터, Lucene에 Bkd 트리 기반의 데이터 구조를 도입하여 이를 사용해 위치 정보 도형 쿼리 성능을 25배 이상 개선하고, Kibana에서 글로벌 기본 지도를 지원하는 Elastic Maps 서비스를 출시하기까지, 위치 정보 데이터에 대한 지원은 여러 해 동안 계속해서 개선되어 왔습니다.
7.0에서도 이 투자를 계속하여 Elasticsearch에서 새로운 집계를 도입함으로써, 사용자가 결과 데이터 도형을 변경하지 않고도 지도 상에서 확대/축소할 수 있는 방식으로 (위치 정보) 지도 타일을 처리합니다. 새로운 geotilegrid 집계는 그리드에서 셀을 나타내는 버킷으로 geopoints를 그룹화하며, 각 셀은 지도의 타일 하나와 서로 연결됩니다. 이번 변경 작업 전에는, 확대/축소 수준이 달라지면 도형의 주변부가 살짝 변할 수 있었습니다. 다른 확대/축소 수준에서 직사각형 타일이 방향을 바꾸게 되기 때문입니다. 7.0에서 Elastic Maps는 이미 이 새로운 집계를 사용하여 확대/축소 시에도 사용자가 계속 안정적으로 볼 수 있도록 하고 있습니다. 이러한 수준의 정확성은 공격자들로부터 네트워크를 보호하든, 특정 위치에서 느린 애플리케이션 응답 시간을 조사하든, 또는 퍼시픽 크레스트 트레일에서 하이킹을 하고 있는 남동생을 추적하든 중요합니다.
나노초 정밀도 지원으로 시계열 사용 사례 강화
인프라 메트릭, 시스템 감사 로그, 네트워크 트래픽이든, 아니면 화성 탐사선이든, 시계열 데이터는 많은 사람들이 Elastic Stack을 사용하는 방법에 있어 중요합니다. 여러 시스템과 서비스에서 이벤트를 정확하게 순서대로 정렬하고 상호 연관시키는 기능은 핵심적입니다.
지금까지 Elasticsearch는 밀리초의 정밀도로만 타임스탬프를 저장했습니다. 7.0에서는 0을 몇 개 추가하여 나노초의 정밀도를 구현함으로써, 정밀도가 요구되는 사용 빈도가 높은 데이터 컬렉션이 있는 사용자가 이 데이터를 정확하게 저장하고 순서대로 배열할 수 있게 해줍니다. 이러한 변경은 역사적인 JODA 라이브러리에서 JDK 8의 공식 Java time API로 마이그레이션함으로써 가능했습니다.