Entender la malla de datos en el sector público: pilares, arquitectura y ejemplos


 Share on Twitter
Share on TwitterComparte en Twitter

 Share on LinkedIn
Share on LinkedInComparte en LinkedIn

 Share on Facebook
Share on FacebookComparte en Facebook

 Share by Email
Share by EmailComparte por correo electrónico

 Print this page
Print this pageImprime
Piensa en todos los datos que hay detrás de proyectos como la inteligencia de defensa, los registros de salud pública, los modelos de planificación urbana y mucho más. Las agencias gubernamentales generan enormes cantidades de datos todo el tiempo. Las cosas se ponen aún más complicadas cuando los datos se distribuyen a través de plataformas en el cloud, sistemas locales o entornos especializados como satélites y centros de respuesta a emergencias. Es difícil encontrar información, mucho menos usarla eficientemente. Y con diferentes equipos que trabajan con muchas apps y formatos de datos diferentes, surge una verdadera falta de interoperabilidad.
A pesar de sus mejores esfuerzos por construir organizaciones impulsadas por los datos, la realidad es que el 65 % de los líderes del sector público sigue teniendo dificultades para usar los datos de forma continua, en tiempo real y a escala, según un reciente estudio de Elastic.
“Nos está tomando más tiempo hacer nuestro trabajo, lo cual no es bueno, ya que la mayor parte de nuestro trabajo se hace en una emergencia”, dijo un líder del sector público a Elastic. “Necesitamos poder obtener información lo más pronto posible”.
La montaña de datos está creciendo. El acceso a ella supone un cuello de botella. Entonces, ¿cómo pueden las agencias del sector público deshacerse de la complejidad de esos silos centralizados? La malla de datos ofrece una forma alternativa para organizar los datos que podría ser la respuesta.
¿Qué es una malla de datos?
En pocas palabras, una malla de datos supera los silos. Los datos recopilados de toda la red están disponibles para ser recuperados y analizados en cualquier punto del ecosistema o en todos, siempre que el usuario tenga permiso para acceder a ellos. Proporciona una capa unificada, pero distribuida que simplifica y estandariza las operaciones de datos.

Cuatro pilares de la malla de datos
La malla de datos se basa en cuatro principios clave:
Propiedad del dominio: cómo las agencias y los departamentos gestionan sus propios datos
Datos como producto: donde esos propietarios de dominio se aseguran de que sus conjuntos de datos sean de alta calidad y de fácil acceso
Plataformas de autoservicio: permite que los equipos internos y externos encuentren y usen datos de alta calidad sin demoras de parte de IT
Gobernanza federada: garantiza que todo funcione sin problemas y de forma segura en todos los sistemas
Veamos cada uno de ellos en más detalle.
Propiedad del dominio
En lugar de depender de un equipo central de IT para administrar todos los datos, la propiedad de los datos se distribuye entre las agencias y departamentos gubernamentales. Básicamente, se trata de crear equipos técnicos que reflejan la composición de la propia agencia. Quieres que los posean las personas que están más familiarizadas con esos datos. Esto se puede aplicar a la salud pública, la defensa, la planificación urbana y más, prácticamente cualquier caso de uso del sector público.
Por ejemplo, la Agencia de Ciberseguridad y Seguridad de la Infraestructura (CISA) de EE. UU. usa un enfoque de malla de datos para obtener visibilidad de los datos de seguridad de cientos de agencias federales, mientras permite que cada agencia mantenga el control de sus datos.
Esto nos lleva al segundo (y posiblemente más importante) pilar, aquel que los otros tres están diseñados para respaldar:
Los datos como producto
Cada set de datos se trata como un producto con una documentación clara y estándares de calidad. El departamento que posee los datos necesita asegurarse de que estén fácilmente accesibles y organizados para cuando otros departamentos los necesiten. En otras palabras, son responsables de compartir esos datos como un producto utilizable.
Desde el punto de vista del gobierno, podría tratarse de información del censo, datos de respuesta a emergencias o informes de inteligencia, por ejemplo. Todo depende de la estructura del proyecto o agencia gubernamental. Lo importante es que estos datos seleccionados estarán listos para usar cuando otros equipos vengan a buscarlos, y no tendrán que perder tiempo limpiándolos o verificándolos.
Entonces, te preguntarás, ¿no es esta otra forma de aislar los datos analíticos? ¿Cuáles son los aspectos prácticos de cómo otros departamentos pueden acceder a ellos? Eso nos lleva a nuestro siguiente pilar.
Plataformas de autoservicio
A los departamentos se les pide mucho aquí, y necesitarán plataformas convenientes que hagan que sus datos estén accesibles para otros. Los catálogos de búsqueda para facilitar el descubrimiento de datos, las herramientas de consulta para el análisis en tiempo real y la capacidad de los usuarios para limpiar e integrar datos por sí mismos, así como para compartir información a través de dashboards y API, son herramientas que se pueden emplear.
También necesitarán una gobernanza integrada para hacer cumplir los controles de acceso, lo que nos lleva a nuestro último pilar.
Gobernanza computacional federada
Por lo tanto, hemos establecido que cada departamento tiene el control de sus propios datos. Sin embargo, la malla de datos aún necesita protocolos de gobernanza generales para que se mantenga segura y prevenir riesgos.
Estos controles de seguridad deberían estar integrados en el sistema que recupera los datos, en lugar de que cada departamento los aplique por separado. El sistema debería verificar los permisos de usuario como parte de la búsqueda y asegurarse de que las personas solo vean los datos a los que tienen permiso de acceso desde el principio.
En el sector público, esto podría ser cualquier cosa, desde regulaciones de privacidad en datos de salud hasta información clasificada en sistemas de defensa.
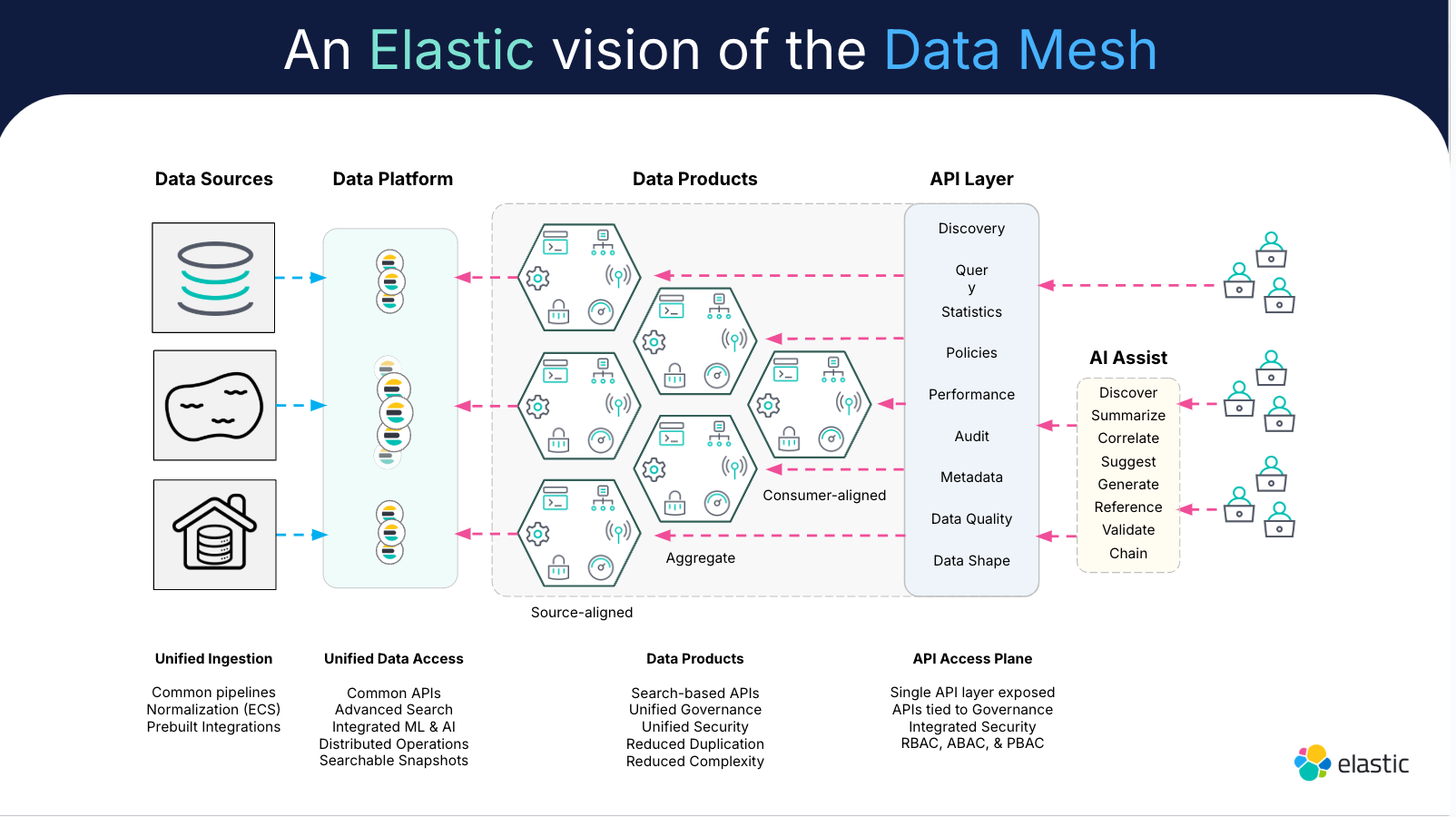
Arquitectura de la malla de datos
Una arquitectura de malla de datos es un marco de trabajo que une los pilares de la malla de datos en un proceso para gestionar datos distribuidos.
La implementación de una arquitectura de malla de datos reduce la fricción en el proceso de colaboración. Es un cambio radical para los equipos que trabajan con datos específicos de un dominio para el entrenamiento de modelos y las analíticas, gracias a su enfoque más centrado en el usuario.
La malla de datos ayuda a permitir un manejo y una gobernanza de datos más eficientes a escala, a pesar de las múltiples plataformas y equipos de implementación. La arquitectura de la malla de datos crea más autonomía y más democratización de los datos, si tienes una observabilidad de datos escalable y de autoservicio. La observabilidad de los datos es lo que permite a los equipos gestionar todos esos datos en un solo panel.
La observabilidad efectiva de los datos está integrada en la arquitectura de una malla de datos. Es lo que les da a los equipos acceso a la información que pueden emplear a partir de todos los datos que recopilan. Imagínalo así: la observabilidad de datos es como tener ojos que vigilan la condición e integridad de la información, mientras que las arquitecturas de las mallas de datos tratan de que cada parte de la organización gestione sus propios datos. Y para poder gestionar, debes tener la capacidad de verlos en detalle.
Malla de datos vs. otros enfoques
¿Cómo se compara la malla de datos con formas alternativas de arquitectura y almacenamiento de datos analíticos? Veamos otros dos casos que a menudo se comparan: la estructura de datos y los lagos de datos.
Malla de datos vs. estructura de datos
La malla de datos y la estructura de datos son enfoques similares en el sentido de que ambos adoptan un enfoque descentralizado, y recopilan datos en sitios remotos. Sin embargo, una estructura de datos toma los datos recopilados en un sitio y los copia a otro. Estos datos se comparten como registros individuales y no se pueden correlacionar con otros registros a menos que sean consumidos por algo que les dé sentido. A menudo, este enfoque puede conducir a silos de datos.
En contraste, un modelo de malla de datos no depende de la replicación de datos, sino que crea índices de los datos de forma local al ser ingestados en una plataforma distribuida. Esto permite a los usuarios buscar información tanto en su ubicación como en sitios remotos. En este modelo, los datos se unifican en la capa de la plataforma de búsqueda. Los datos se indexan una vez y, luego, están disponibles para cualquier usuario autorizado o caso de uso a través de esta capa unificada.
Malla de datos vs. lago de datos
Es posible que hayas notado que hay muchas metáforas relacionadas con el agua en los datos: flujos de datos, pipelines de datos, etc. Los datos, al igual que el agua, se pueden recopilar, almacenar, filtrar y distribuir, a veces de manera eficiente, a veces de manera caótica.
De la misma manera que un lago recolecta agua de múltiples fuentes, un lago de datos recopila datos y los conserva para su uso futuro. En otras palabras, es un entorno de almacenamiento para cualquier combinación de datos estructurados, semiestructurados o datos no estructurados.
Los lagos de datos a veces pueden ser útiles para los propietarios de dominios de malla de datos cuando procesan y conservan sus productos de datos. Pueden usar un lago de datos para el almacenamiento a largo plazo de grandes conjuntos de datos no estructurados (por ejemplo, imágenes satelitales o registros públicos) que aún no tienen un propósito específico. Pero, si un lago de datos se desorganiza y se vuelve difícil de navegar, se convierte en un pantano de datos: turbio, desordenado y del que es difícil extraer valor.
Malla de datos y AI
La malla de datos puede ofrecer una forma de democratizar la AI y el machine learning para las agencias del sector público. Tradicionalmente, los equipos de ciencia de datos han operado como centros centralizados, al extraer datos de múltiples fuentes para desarrollar modelos de machine learning. Sin embargo, como se mencionó con anterioridad, este proceso puede causar trabajo redundante e inconsistencias, lo que genera desafíos con la reproducibilidad del modelo.
Al invertir ese modelo con la malla de datos e integrar el desarrollo de AI dentro de los equipos de dominio, puedes limpiar y perfeccionar los datos en su origen y crear un producto de datos impulsado por AI que otros departamentos puedan usar.
Tomemos como ejemplo la respuesta a desastres nacionales. Los modelos de AI integrados en los equipos de respuesta a emergencias, a menudo, analizan datos como imágenes satelitales en tiempo real, datos de sensores e incluso reportes de redes sociales para identificar las áreas más afectadas. Con la malla de datos, diferentes agencias, desde las agencias gubernamentales hasta los encargados de la respuesta inicial, podrían acceder a esta información de inmediato sin esperar el procesamiento centralizado y, como resultado, mejorar sus tiempos de respuesta.
La malla de datos también mejora la gobernanza de la AI porque la incorpora desde el principio, estandarizando tareas como la validación del modelo, la detección de sesgos, la capacidad de explicación y el monitoreo de la desviación del modelo.
Cómo implementar la malla de datos para el sector público
Cada organización del sector público tiene un conjunto único de necesidades de datos, por lo que los silos de datos estandarizados pueden ser lentos y sofocantes para los usuarios internos y externos. Dos de cada tres líderes del sector público dijeron que no están satisfechos con la información sobre los datos disponible.
La malla de datos se puede personalizar según las necesidades únicas de cada agencia del sector público, desde la defensa hasta la seguridad nacional o el gobierno federal, estatal y local.
Para comenzar con la malla de datos, las agencias del sector público tendrán que seguir algunos pasos:
Asignar la responsabilidad de los datos a departamentos específicos.
Trata los sets de datos como activos accesibles y bien documentados, diseñados para uso interno y externo, y asegúrate de que cumplen con los requisitos normativos.
Implementa herramientas que permitan a las agencias, los analistas y los responsables políticos acceder y analizar fácilmente los datos sin depender de equipos de IT centralizados.
Implementa la gobernanza en todas las agencias, teniendo en cuenta marcos de trabajo como FedRAMP, CMMC y Zero Trust.
Y finalmente, fomenta el intercambio de datos entre las organizaciones para tomar mejores decisiones y mejorar los servicios públicos mientras se mantienen los controles de seguridad.
Aplicaciones gubernamentales y de defensa
La malla de datos es una opción natural para el gobierno y los sectores de defensa, donde se debe acceder y analizar de forma segura y en tiempo real a grandes conjuntos de datos distribuidos.
En defensa, ayuda a recopilar inteligencia y gestionar activos más rápido para que los operadores en el campo puedan actuar con los datos más recientes. En salud pública, puede ayudar a integrar con rapidez los datos epidemiológicos de hospitales o laboratorios de investigación para responder a los brotes. Los departamentos de transporte pueden analizar el tráfico y los datos meteorológicos de las ciudades. Los departamentos de educación pueden ver los resultados de los exámenes de los niños en la última década y relacionarlos con otros datos, como el tiempo dedicado al aprendizaje remoto frente al presencial.
Tomemos este ejemplo de la Marina de los EE. UU.: su impulso hacia la modernización digital depende fundamentalmente de la capacidad de “trasladar de forma segura cualquier información desde cualquier lugar hacia cualquier lugar” para alcanzar la superioridad de la información. Pero el almacenamiento de datos centralizado tradicional es demasiado arriesgado, en especial, en entornos aislados u denegados, degradados, intermitentes y limitados (DDIL). Este es un caso en el que una malla de datos global puede ayudar, lo que permite que los datos permanezcan en su fuente, se puedan buscar y estar accesibles en todo el vasto panorama operativo de la Armada. Este enfoque descentralizado mantiene la resiliencia de las operaciones incluso si falla un servidor o centro de datos y proporciona una vista unificada de los datos esenciales sin necesidad de trasladarlos o duplicarlos.
Malla de datos en acción con Elastic
Como The Search AI Company, la plataforma de analíticas de datos de Elastic sirve como una poderosa malla global de datos, que ofrece machine learning, procesamiento de lenguaje natural, búsqueda semántica, alertas y visualización en un sistema unificado. En otras palabras, Elastic cumple una función unificadora al proporcionarles a las agencias una visibilidad total de sus datos, así como la capacidad de ingestarlos, organizarlos, acceder a ellos y analizarlos.
Tres características clave distinguen a Elastic:
Búsqueda entre clusters (CCS), que te permite ejecutar una única solicitud de búsqueda en uno o varios clusters remotos
Snapshots buscables, que proporcionan una forma rentable de acceder y consultar tus datos históricos de uso poco frecuente
Control de acceso basado en roles, que proporciona seguridad integrada
El enfoque de malla de datos de Elastic también puede servir como base para marcos de trabajo de seguridad modernos como Zero Trust y abre nuevas posibilidades para las operaciones basadas en datos.
Obtén más información sobre cómo Elastic ayuda a los equipos de gobierno, salud y educación a maximizar el valor de los datos con velocidad, escala y relevancia.
Explora más recursos sobre la malla de datos en el sector público
El lanzamiento y el momento de cualquier característica o funcionalidad descrita en esta publicación quedan a exclusivo criterio de Elastic. Es posible que cualquier característica o funcionalidad que no esté disponible en este momento no se lance a tiempo o no se lance en absoluto.
En esta publicación de blog, es posible que hayamos usado o nos hayamos referido a herramientas de AI generativa de terceros, que son propiedad de sus respectivos propietarios y están gestionadas por ellos. Elastic no tiene ningún control sobre las herramientas de terceros y no tenemos ninguna responsabilidad por su contenido, operación o uso, ni por ninguna pérdida o daño que pueda surgir de tu uso de dichas herramientas. Ten cuidado al usar herramientas de AI con información personal, sensible o confidencial. Cualquier dato que envíes puede usarse para el entrenamiento de AI u otros fines. No se garantiza que la información que proporciones se mantenga segura o confidencial. Debes familiarizarte con las prácticas de privacidad y los términos de uso de cualquier herramienta de AI generativa antes de usarla.
Elastic, Elasticsearch, ESRE, Elasticsearch Relevance Engine y las marcas asociadas son marcas comerciales, logotipos o marcas comerciales registradas de Elasticsearch N.V. en Estados Unidos y otros países. Todos los demás nombres de empresas y productos son marcas comerciales, logotipos o marcas comerciales registradas de sus respectivos dueños.
Comparte
- Share on Twitter
Comparte en Twitter
- Share on LinkedIn
Comparte en LinkedIn
- Share on Facebook
Comparte en Facebook
- Share by Email
Comparte por correo electrónico
- Print this page
Imprime