Anomalie-Scoring in Machine Learning und Elasticsearch – so funktioniert’s
Anmerkung des Autors (3. August 2021): Dieser Beitrag verwendet veraltete Features. In der Dokumentation zum Thema Map custom regions with reverse geocoding (benutzerdefinierte Regionen mit umgekehrter Geocodierung zuordnen) finden Sie eine aktuelle Anleitung.
Wir werden häufig gefragt, was es mit dem „Anomalie-Score“ von Elastic Machine Learning auf sich hat und wie sich die verschiedenen Scores in den Dashboards zur „Unüblichkeit“ einzelner Auftretensereignisse innerhalb der Datasets verhalten. Es kann sehr nützlich sein, über die verschiedenen Arten von Anomalie-Scores, die zugehörigen Abhängigkeiten und die Einsatzmöglichkeiten des Scores als Indikator für das proaktive Alerting Bescheid zu wissen. Dieser Blogbeitrag erhebt nicht den Anspruch, allumfassend zu sein und die definitive Referenz zum Thema darzustellen, aber wir versuchen, möglichst umfangreiche praktische Informationen darüber zu vermitteln, wie Machine Learning (ML) beim Scoring vorgeht.
Zunächst einmal sollte beachtet werden, dass es drei verschiedene Möglichkeiten gibt, die „Unüblichkeit“ zu betrachten (und letztendlich mit einem Score zu bewerten): das Scoring für eine einzelne Anomalie („Record-Scoring“), das Scoring für eine Entität, wie einen Benutzer oder eine IP-Adresse, („Influencer-Scoring“) und das Scoring für ein Zeitfenster („Bucket-Scoring“). Wir werden uns außerdem ansehen, welche hierarchischen Beziehungen es zwischen diesen unterschiedlichen Scores gibt.
Record-Scoring
Der erste Scoring-Typ, ganz unten in der Hierarchie, ist die absolute Unüblichkeit des Auftretens einer bestimmten Instanz von etwas, wie zum Beispiel:
- Für user=admin wurden innerhalb der letzten Minute 300 fehlgeschlagene Logins beobachtet
- Der Reaktionszeitwert für einen bestimmten Middleware-Aufruf ist soeben plötzlich auf 300 % des Normalwertes angestiegen
- Die Zahl der heute Nachmittag verarbeiteten Aufträge ist deutlich geringer als das, was für einen Donnerstagnachmittag zu erwarten ist
- Es gibt eine Remote-IP-Adresse, an die deutlich mehr Daten übertragen werden als an andere IP-Adressen
Für jedes der oben aufgeführten Auftretensereignisse existiert eine berechnete Wahrscheinlichkeit. Dieser Wert wird mit sehr hoher Genauigkeit ermittelt (bis hinunter auf 1e-308) und er basiert auf Verhaltensbeobachtungen aus der Vergangenheit, anhand derer ein Baseline-Wahrscheinlichkeitsmodell für das jeweilige Element aufgestellt wurde. Dieser rohe Wahrscheinlichkeitswert ist zweifelsohne sehr nützlich, lässt aber bestimmte Kontextinformationen vermissen, wie zum Beispiel:
- Wie verhält sich das aktuelle abweichende Verhalten zu Anomalien in der Vergangenheit? Ist die Unüblichkeit im Vergleich zu früheren Anomalien weniger oder stärker ausgeprägt?
- Wie verhält sich die Anomalie bei diesem Element zu potenziellen Abweichungen vom normalen Verhalten bei anderen Elementen (anderen Benutzern, anderen IP-Adressen usw.)?
Um dem Benutzer das Verständnis und die Einordnung zu erleichtern, normalisiert ML die Wahrscheinlichkeit so, dass der Grad der Abweichung vom normalen Verhalten auf einer Skala von 0 bis 100 eingestuft wird. Dieser Wert wird in der UI als „anomaly score“ (Anomalie-Score) angegeben.
Damit der Benutzer den Wert besser einordnen kann, stuft die UI den Score in einen von vier „Severity“-Bereichen ein: Scores von 75 bis 100 werden als „critical“ angesehen, Scores von 50 bis 75 gelten als „major“, Scores von 25 bis 50 sind „minor“ und Scores von 0 bis 25 werden als „warning“ gekennzeichnet. Jedem Bereich ist eine andere Farbe zugewiesen.
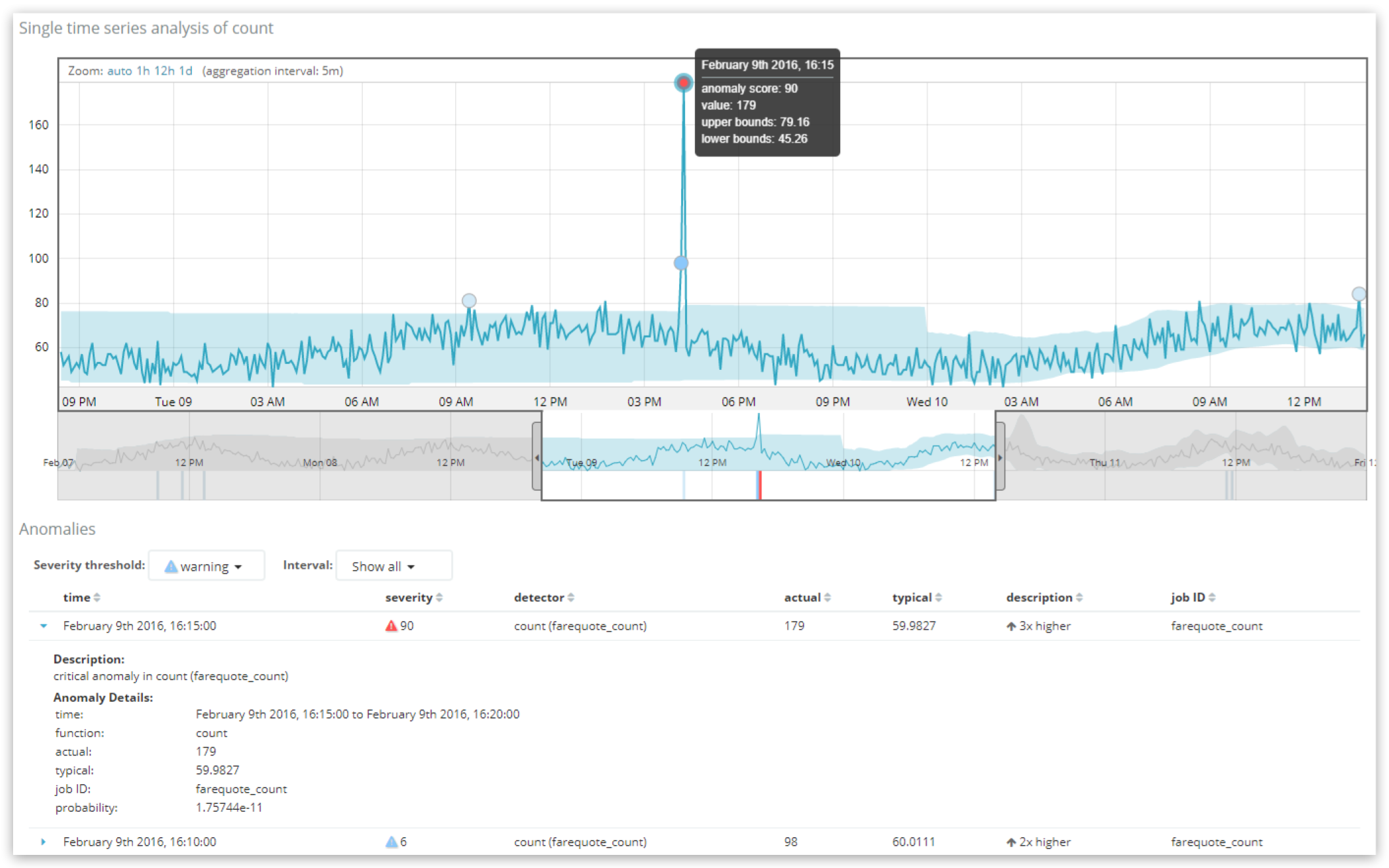
In diesem Screenshot der Ansicht „Single Metric Viewer“ sehen Sie zwei Anomalie-Records, von denen einer mit einem Score von 90 im Bereich der „kritischen“ Anomalien liegt. Mithilfe der Funktion „Severity threshold“ über der Tabelle lässt sich die Tabelle nach Anomalien mit einem bestimmten Schweregrad filtern, und mit der Funktion „Interval“ können die Records so gruppiert werden, dass derjenige mit dem höchsten Score in der letzten Stunde oder an diesem Tag angezeigt wird.
Wenn wir in der ML-API Record-Ergebnisse abfragen möchten, um an Informationen zu Anomalien in einem bestimmten 5-minütigen Zeitfenster („Bucket“) zu gelangen, müssten wir Folgendes angeben (wobei farequote_count der Name des Jobs ist):
GET /_xpack/ml/anomaly_detectors/farequote_count/results/records?human
{
"sort": "record_score",
"desc": true,
"start": "2016-02-09T16:15:00.000Z",
"end" :"2016-02-09T16:20:00.000Z"
}
Daraufhin würden wir Folgendes angezeigt bekommen:
{
"count": 1,
"records": [
{
"job_id": "farequote_count",
"result_type": "record",
"probability": 1.75744e-11,
"record_score": 90.6954,
"initial_record_score": 85.0643,
"bucket_span": 300,
"detector_index": 0,
"is_interim": false,
"timestamp_string": "2016-02-09T16:15:00.000Z",
"timestamp": 1455034500000,
"function": "count",
"function_description": "count",
"typical": [
59.9827
],
"actual": [
179
]
}
]
}
Das zeigt uns, dass während dieses 5-minütigen Intervalls (bucket_span) der Record-Score bei 90,6954 (von 100) und die Roh-„Wahrscheinlichkeit“ (probability) bei 1,75744e-11 lag. Daraus lässt sich entnehmen, dass es sehr unwahrscheinlich ist, dass das Datenvolumen in diesem 5-Minuten-Intervall tatsächlich 179 Dokumente erreicht, weil der „typische“ Wert wesentlich geringer ist und näher an 60 liegt.
Wie Sie sehen, stimmen die Werte hier mit dem überein, was der Benutzer in der UI sieht. Der Wahrscheinlichkeitswert von 1,75744e-11 ist eine sehr kleine Zahl, es ist also sehr unwahrscheinlich, dass ein solches Verhalten auftritt. Da aber das Format, in dem der Wert präsentiert wird, nicht ohne Weiteres verständlich ist, ist es sinnvoll, ihn in eine Skala von 0 bis 100 zu übertragen. Der dabei zum Einsatz kommende Normalisierungsprozess ist proprietär, basiert aber, grob gesagt, auf einer Quantilanalyse, bei der Wahrscheinlichkeitswerte für Anomalien in diesem Job aus der Vergangenheit miteinander verglichen werden. Vereinfacht gesagt erhalten die niedrigsten Wahrscheinlichkeiten für den Job die höchsten Anomalie-Scores.
Häufig wird fälschlicherweise angenommen, dass der Anomalie-Score direkt mit der in der Spalte „description“ der UI angegebenen Abweichung in Zusammenhang steht (hier: „3x higher“). Aber der Anomalie-Score ist einzig und allein das Ergebnis der Berechnung des Wahrscheinlichkeitswertes. Die Angaben unter „description“ und auch unter typical sind vereinfachte Kontextinformationen, die dabei helfen sollen, die Anomalie besser zu verstehen.
Influencer-Scoring
Nachdem wir uns mit dem Anomalie-Scoring für einzelne Records beschäftigt haben, soll es jetzt um die zweite Möglichkeit zur Betrachtung der Unüblichkeit gehen: die Einstufung von Entitäten, die an einer Anomalie mitgewirkt haben könnten. In ML bezeichnen wir diese „mitwirkenden“ Entitäten als „Influencer“. Im Beispiel oben war die Analyse für die Mitwirkung von Influencern zu einfach, handelte es sich doch lediglich um eine einzelne Zeitreihe. In komplexeren Analysen kann es zusätzliche Felder geben, die Auswirkungen auf das Vorhandensein einer Anomalie haben können.
Stellen Sie sich zum Beispiel vor, ML soll die Internetaktivitäten einer Benutzerpopulation analysieren, bei der der ML-Job nach unüblichen Byteübertragungen und Domainbesuchen sucht. In einem solchen Fall könnte als möglicher Influencer „user“ angegeben werden, da dies die Entität ist, die das Auftreten der Anomalie „verursacht“ (irgendetwas oder -wer muss ja diese Bytes an eine Zieldomain senden). Damit wird jedem Benutzer für jedes Zeitintervall ein Influencer-Score zugeordnet, dessen Wert davon abhängt, wie stark die ihm zugeschriebene Anomalie in einem oder beiden dieser Bereiche (Byteübertragungen und Domainbesuche) ausgeprägt ist.
Je höher der Influencer-Score des Benutzers ist, desto größer war sein Anteil – oder seine Schuld – an den Anomalien. Dies bietet aufschlussreiche Einblicke in die ML-Ergebnisse, speziell bei Jobs, bei denen mehrere Detectors zum Einsatz kommen.
Bei allen ML-Jobs wird zusätzlich zu den bei der Erstellung des Jobs hinzugefügten Influencern auch ein integrierter Influencer namens bucket_time erstellt. Dabei wird eine Aggregation aller Records im Bucket genutzt.
Zur Demonstration eines Beispiels für Influencer zeigen wir im Folgenden das Ergebnis eines ML-Jobs mit zwei Detectors, der einen Dataset von API-Reaktionszeit-Aufrufen für eine Flugpreisangebots-Engine analysiert:
- Zahl der API-Aufrufe (
count), aufgeteilt nach Fluglinie (airline) - mittlere Reaktionszeit der API-Aufrufe (
mean(responsetime)), aufgeteilt nach Fluglinie (airline)
wobei als Influencer airline festgelegt wird.
Im „Anomaly Explorer“ wird das dann wie folgt dargestellt:
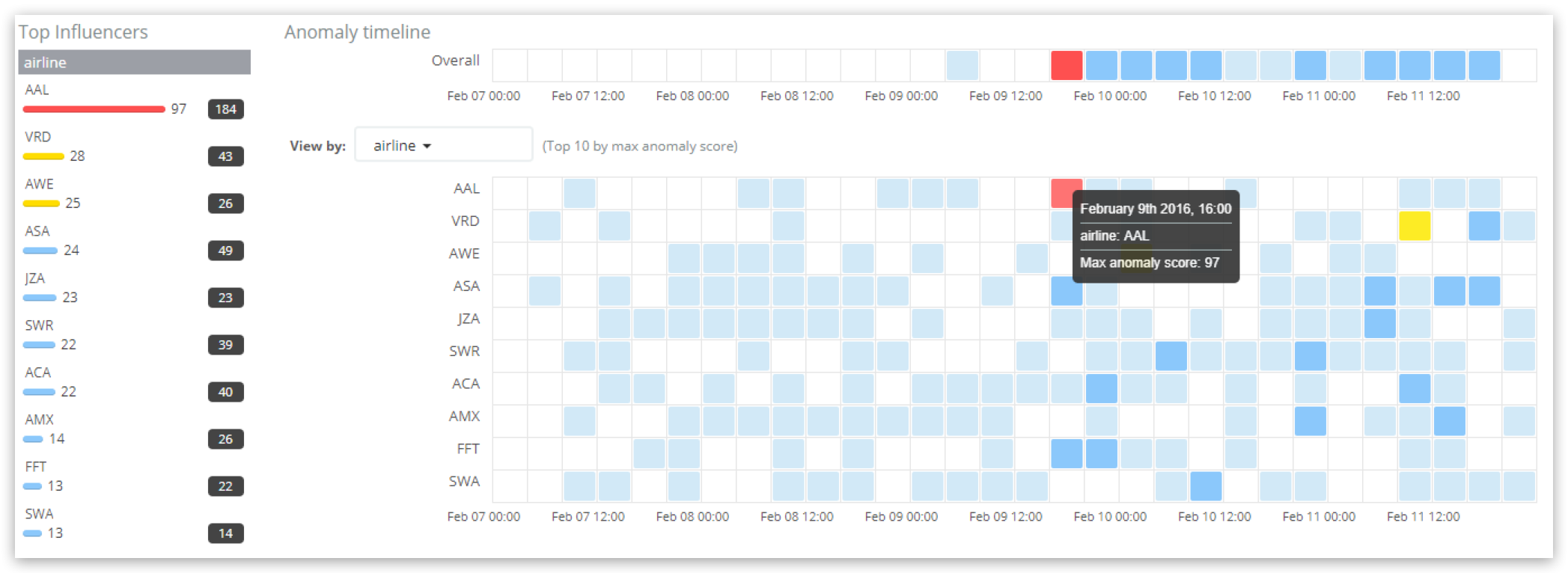
Im Abschnitt „Top influencers“ auf der linken Seite sind die Influencer mit den höchsten Scores im ausgewählten Zeitraum aufgeführt. Für jeden Influencer werden der maximale Influencer-Score (in allen Buckets) sowie der Gesamt-Influencer-Score über den Dashboard-Zeitraum hinweg (Summe aus allen Buckets) angezeigt. Die Fluggesellschaft AAL hat mit 97 den höchsten Influencer-Score und die Gesamtsumme aus allen Influencer-Scores über den gesamten Zeitraum hinweg liegt bei AAL bei 184. In der Hauptzeitleiste werden die Ergebnisse nach Influencer dargestellt, wobei die Influencer-Airline mit dem höchsten Score (97) farblich hervorgehoben wird. Zu beachten ist, dass die Scores, die in den Diagrammen und der Tabelle unter „Anomalies“ für AAL angegeben werden, nicht dieselben wie der Influencer-Score sind, denn bei ihnen handelt es sich um die „Record-Scores“ der einzelnen Anomalien.
Eine Abfrage der API auf Influencer-Ebene, wie:
GET _xpack/ml/anomaly_detectors/farequote_count_and_responsetime_by_airline/results/influencers?human
{
"start": "2016-02-09T16:15:00.000Z",
"end" :"2016-02-09T16:20:00.000Z"
}
gibt die folgenden Informationen zurück:
{
"count": 2,
"influencers": [
{
"job_id": "farequote_count_and_responsetime_by_airline",
"result_type": "influencer",
"influencer_field_name": "airline",
"influencer_field_value": "AAL",
"airline": "AAL",
"influencer_score": 97.1547,
"initial_influencer_score": 98.5096,
"probability": 6.56622e-40,
"bucket_span": 300,
"is_interim": false,
"timestamp_string": "2016-02-09T16:15:00.000Z",
"timestamp": 1455034500000
},
{
"job_id": "farequote_count_and_responsetime_by_airline",
"result_type": "influencer",
"influencer_field_name": "airline",
"influencer_field_value": "AWE",
"airline": "AWE",
"influencer_score": 0,
"initial_influencer_score": 0,
"probability": 0.0499957,
"bucket_span": 300,
"is_interim": false,
"timestamp_string": "2016-02-09T16:15:00.000Z",
"timestamp": 1455034500000
}
]
}
Die Ausgabe enthält ein Ergebnis für die als Influencer angegebene Airline AAL, wobei der influencer_score-Wert von 97,1547 den Wert widerspiegelt, der in der Ansicht „Anomaly Explorer“ (auf 97 gerundet) angegeben wird. Der unter probability angegebene Wahrscheinlichkeitswert von 6,56622e-40 bildet auch hier die Grundlage für den influencer_score-Wert (vor der Normalisierung) – er berücksichtigt die Wahrscheinlichkeiten der einzelnen Anomalien, auf die diese Fluggesellschaft Einfluss hat, sowie den Grad ihrer Einflussnahme.
Außerdem wird ein Wert mit der Bezeichnung initial_influencer_score (hier: 98,5096) ausgegeben. Dies war der ursprüngliche Score bei Verarbeitung des Ergebnisses vor der leichten Anpassung durch nachfolgende Normalisierungen auf 97,1547. Die Unterschiede treten auf, weil der ML-Job die Daten in chronologischer Reihenfolge verarbeitet und ältere Rohdaten bei den Analysen nicht mehr berücksichtigt werden. Wie Sie sehen, wurde auch ein zweiter Influencer, die Airline AWE, identifiziert, aber deren Influencer-Score ist so niedrig (gerundeter Wert 0), dass sie in der Praxis vernachlässigt werden kann.
Da sich der influencer_score-Wert aus den aggregierten Werten mehrerer Detectors zusammensetzt, werden Sie feststellen, dass die API nicht den eigentlichen Wert oder typische Werte für die Zahl oder den Mittelwert der Reaktionszeiten zurückgibt. Wenn Sie diese Angaben benötigen, stehen sie für denselben Zeitraum als Record-Score zur Verfügung (siehe oben).
Bucket-Scoring
Die dritte, letzte und hierarchisch am weitesten oben angesiedelte Möglichkeit, die Unüblichkeit als Score zu erfassen, ist die Berücksichtigung der Zeit, insbesondere des bucket_span des ML-Jobs. Unübliche Verhaltensweisen treten zu bestimmten Zeiten auf und es ist möglich, dass einzelne, mehrere oder viele Dinge sich gleichzeitig (im selben Bucket) und zusammen unüblich verhalten.
Die Unüblichkeit eines Zeit-Buckets hängt daher von verschiedenen Faktoren ab:
- Größenordnung der einzelnen Anomalien (Records), die innerhalb dieses Buckets auftreten
- Zahl der einzelnen Anomalien (Records), die innerhalb dieses Buckets auftreten. Diese kann recht hoch sein, wenn der Job durch Einsatz von „byfields“ und/oder „partitionfields“ aufgeteilt ist oder im Job mehrere Detectors definiert wurden.
Die Berechnung des Bucket-Scores erschöpft sich nicht in einer einfachen Durchschnittsermittlung aller einzelnen Anomalie-Record-Scores, sondern berücksichtigt auch die Influencer-Scores im jeweiligen Bucket.
Zurück zum ML-Job aus unserem letzten Beispiel mit den beiden Detectors
count, aufgeteilt nachairline, undmean(responsetime), aufgeteilt nachairline.
Im „Anomaly Explorer“ ergibt sich folgendes Bild:
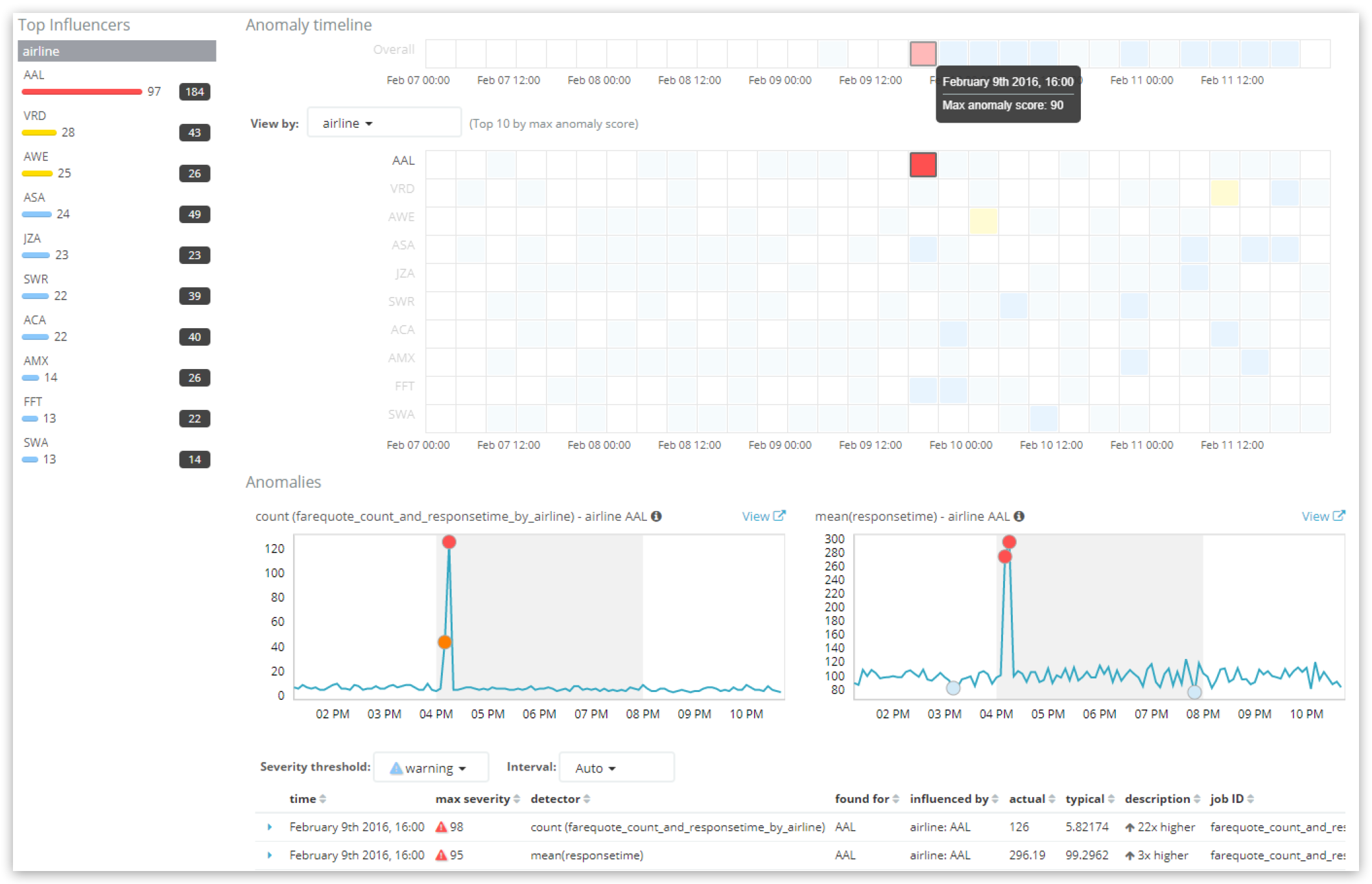
In der zusammenfassenden Zeile der Anomalie-Zeitleiste ganz oben wird der Score für das Bucket angezeigt. Aber Achtung! Wenn der in der UI ausgewählte Zeitbereich sehr weit gefasst ist, während der bucket_span des ML-Jobs relativ kurz ist, kann es sein, dass eine „Kachel“ in der UI bei näherer Betrachtung mehrere Buckets enthält, deren Werte aggregiert wurden.
Die oben dargestellte Kachel weist einen Wert von 90 auf und in diesem Bucket gibt es zwei kritische Record-Anomalien: bei jedem Detector eine, mit Record-Scores von 98 und 95.
Eine Abfrage der API auf Bucket-Ebene, wie:
GET _xpack/ml/anomaly_detectors/farequote_count_and_responsetime_by_airline/results/buckets?human
{
"start": "2016-02-09T16:15:00.000Z",
"end" :"2016-02-09T16:20:00.000Z"
}
gibt die folgenden Informationen zurück:
{
"count": 1,
"buckets": [
{
"job_id": "farequote_count_and_responsetime_by_airline",
"timestamp_string": "2016-02-09T16:15:00.000Z",
"timestamp": 1455034500000,
"anomaly_score": 90.7,
"bucket_span": 300,
"initial_anomaly_score": 85.08,
"event_count": 179,
"is_interim": false,
"bucket_influencers": [
{
"job_id": "farequote_count_and_responsetime_by_airline",
"result_type": "bucket_influencer",
"influencer_field_name": "airline",
"initial_anomaly_score": 85.08,
"anomaly_score": 90.7,
"raw_anomaly_score": 37.3875,
"probability": 6.92338e-39,
"timestamp_string": "2016-02-09T16:15:00.000Z",
"timestamp": 1455034500000,
"bucket_span": 300,
"is_interim": false
},
{
"job_id": "farequote_count_and_responsetime_by_airline",
"result_type": "bucket_influencer",
"influencer_field_name": "bucket_time",
"initial_anomaly_score": 85.08,
"anomaly_score": 90.7,
"raw_anomaly_score": 37.3875,
"probability": 6.92338e-39,
"timestamp_string": "2016-02-09T16:15:00.000Z",
"timestamp": 1455034500000,
"bucket_span": 300,
"is_interim": false
}
],
"processing_time_ms": 17,
"result_type": "bucket"
}
]
}
Beachten Sie vor allem die folgenden Aspekte:
anomaly_score: aggregierter, normalisierter Gesamt-Score (hier: 90,7)initial_anomaly_score: Der Anomalie-Score zum Zeitpunkt der Bucket-Verarbeitung (falls sich der originaleanomaly_score-Wert durch spätere Normalisierungen geändert hat). Derinitial_anomaly_score-Wert erscheint in der UI nirgends.bucket_influencers: Array von Influencer-Typen in diesem Bucket. Wie zu erwarten (siehe unsere Influencer-Besprechung oben), enthält dieses Array sowohl den Eintraginfluencer_field_name:airlineals auch den Eintraginfluencer_field_name:bucket_time(der als integrierter Influencer immer hinzugefügt wird). Konkrete Details zu Influencern (z. B. der Name der Airline) können, wie oben besprochen, durch API-Abfragen auf Influencer- oder Record-Wert-Ebene abgerufen werden.
Anomalie-Scores für Alerting-Funktionen
Wenn wir nun drei grundlegende Scores (einen für einzelne Records, einen für Influencer und einen für das Time-Bucket) haben, welcher eignet sich dann fürs Alerting? Die Antwort lautet, wie so häufig: kommt drauf an – und zwar darauf, was Sie erreichen und wie detailliert und wie häufig Sie benachrichtigt werden möchten.
Wenn es Ihnen darum geht, bei signifikanten Abweichungen im gesamten Dataset als Funktion der Zeit alarmiert zu werden, bietet sich wahrscheinlich das Bucket-basierte Anomalie-Scoring als geeignete Lösung für Sie an. Haben Sie dagegen die Absicht, über besonders unübliche Veränderungen im Zeitverlauf bei den Entitäten informiert zu werden, ist das Influencer-Scoring sicher das Richtige für Sie. Und wenn Sie Benachrichtigungen über die unüblichsten Anomalien innerhalb eines Zeitfensters erhalten möchten, empfiehlt es sich, Ihr Reporting oder Alerting auf einzelnen Record-Scores aufzubauen.
Die Gefahr, von Alarmen überflutet zu werden, ist beim Bucket-basierten Anomalie-Scoring am geringsten, da Sie bei diesem Ansatz pro Bucket-Zeitraum nie mehr als eine Alarmbenachrichtigung erhalten. Bei einem auf record_score basierenden Alerting ist dagegen die Zahl der Anomalie-Records pro Zeiteinheit in keiner Weise begrenzt, sodass sehr viele Alarme bei Ihnen eingehen könnten. Dies ist ein wichtiger Aspekt, den Sie beachten sollten, wenn Sie bei der Alerting-Einrichtung auf das Record-Scoring setzen möchten.
Weitere Informationen: