Überwachen von NVIDIA-GPU-Metriken mit Elastic Observability
Grafikprozessoren (Graphical Processing Units, GPUs) sind nicht nur etwas fürs Gaming. Sie werden heute auch zum Anlernen neuraler Netzwerke, für numerische Strömungsberechnungen, zum Schürfen von Bitcoins und zur Verarbeitung von Arbeitslasten in Rechenzentren genutzt. Außerdem stellen sie einen essenziellen Bestandteil der meisten Hochleistungs-Computersysteme dar, sodass die Überwachung der GPU-Performance in modernen Rechenzentren mittlerweile genauso wichtig ist wie die Überwachung der CPU-Performance.
Das alles ist Grund genug, einen Blick darauf zu werfen, wie die Kombination aus Elastic Observability und den GPU-Monitoring-Tools von NVIDIA dazu genutzt werden kann, die GPU-Performance zu überwachen und zu optimieren.
Abhängigkeiten
Um die NVIDIA-GPU-Metriken zum Laufen zu bringen, müssen wir auf Basis des Quellcodes NVIDIA-GPU-Monitoring-Tools erstellen (Go). Und natürlich brauchen wir auch eine NVIDIA-GPU. Da AMD- und andere GPU-Typen andere Linux-Treiber und Monitoring-Tools verwenden, widmen wir ihnen einen eigenen Blogpost.
NVIDIA-GPUs gehören zum Standardangebot von Google Cloud, Amazon Web Services (AWS) und anderen Cloud-Anbietern. Dieser Blogpost basiert auf einer auf Genesis Cloud laufenden Instanz.
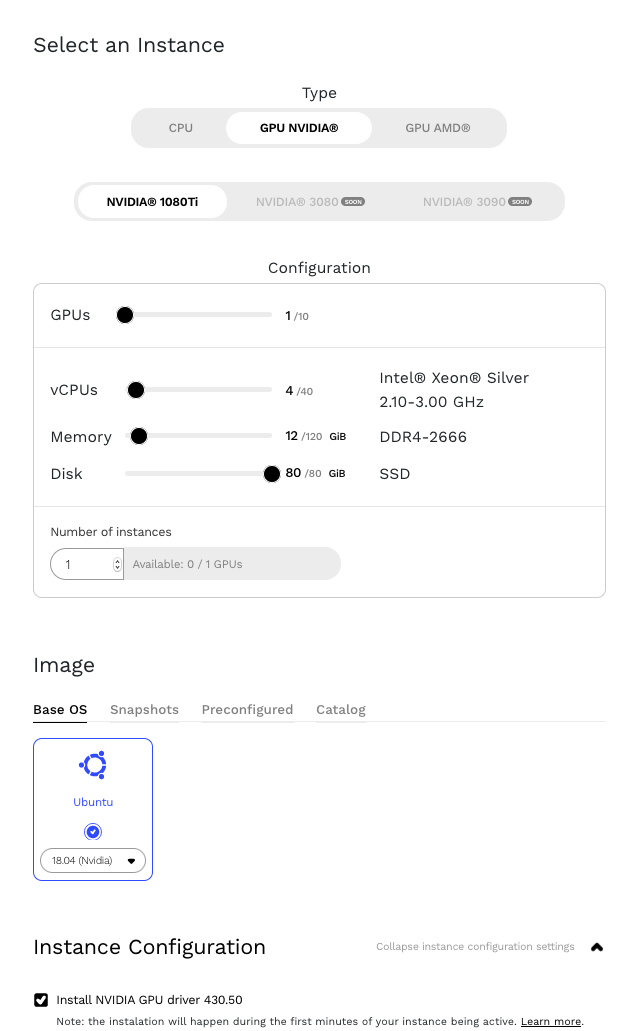
Der erste Schritt besteht darin, den NVIDIA Datacenter Manager zu installieren. Dazu folgen wir der Installationsanleitung für Ubuntu 18.04 im Abschnitt „Getting Started“ des „Data Center GPU Manager User Guide“. Hinweis: Achten Sie darauf, den Parameter <architecture> durch einen eigenen Wert zu ersetzen. Welcher das ist, können Sie über den Befehl uname ermitteln:
uname -a
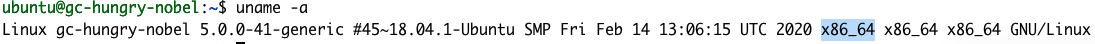
Der Befehlsausgabe können wir entnehmen, dass unsere Architektur als X86_64 anzugeben ist. Schritt 1 im Abschnitt „Getting Started“ sieht also wie folgt aus:
echo "deb http://developer.download.nvidia.com/compute/cuda/repos/$distribution/x86_64 /" | sudo tee /etc/apt/sources.list.d/cuda.list
In Schritt 2 gibt es einen Schreibfehler. Das > nach $distribution ist falsch und darf nicht mit geschrieben werden.
sudo apt-key adv --fetch-keys https://developer.download.nvidia.com/compute/cuda/repos/$distribution/x86_64/7fa2af80.pub
Nach der Installation können wir mit dem Befehl nvidia-smi unsere GPU-Details aufrufen.
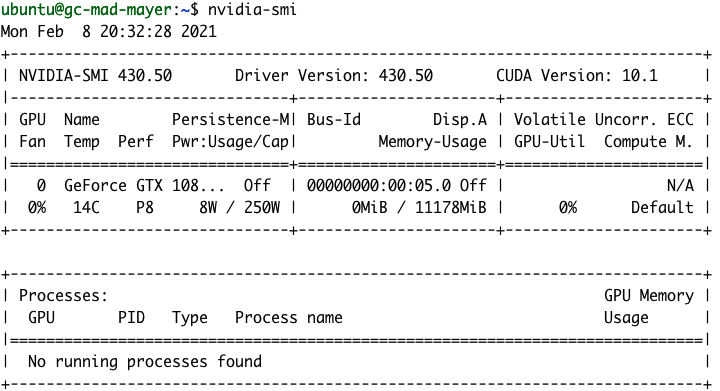
NVIDIA-GPU-Monitoring-Tools
Zum Erstellen der NVIDIA-GPU-Monitoring-Tools müssen wir Golang installieren. Das geht so:
cd /tmp wget https://golang.org/dl/go1.15.7.linux-amd64.tar.gz sudo mv go1.15.7.linux-amd64.tar.gz /usr/local/ cd /usr/local/ sudo tar -zxf go1.15.7.linux-amd64.tar.gz sudo rm go1.15.7.linux-amd64.tar.gz
Zum Abschluss der NVIDIA-Einrichtung installieren wir die GPU-Monitoring-Tools von NVIDIA (gpu-monitoring-tools), die wir bei GitHub finden.
cd /tmp git clone https://github.com/NVIDIA/gpu-monitoring-tools.git cd gpu-monitoring-tools/ sudo env "PATH=$PATH:/usr/local/go/bin" make install
Metricbeat
Jetzt können wir uns an die Installation von Metricbeat machen. Schauen Sie kurz bei elastic.co nach, wie die aktuelle Versionsnummer von Metricbeat lautet, und passen Sie in den Befehlen unten die Versionsnummer entsprechend an.
cd /tmp wget https://artifacts.elastic.co/downloads/beats/metricbeat/metricbeat-7.10.2-amd64.deb sudo dpkg -i metricbeat-7.10.2-amd64.deb # 7.10.2 ist die Versionsnummer
Elastic Cloud
Lassen Sie uns nun den Elastic Stack einrichten. Wir brauchen einen Ort für die Unterbringung unserer neuen GPU-Monitoring-Daten. Zu diesem Zweck erstellen wir ein neues Deployment auf Elastic Cloud. Wenn Sie noch kein Elastic Cloud-Konto haben, können Sie das Angebot 14 Tage kostenlos ausprobieren. Stattdessen können Sie auch lokal ein eigenes Deployment einrichten.
Als Nächstes erstellen wir ein neues Elastic Observability-Deployment auf Elastic Cloud.
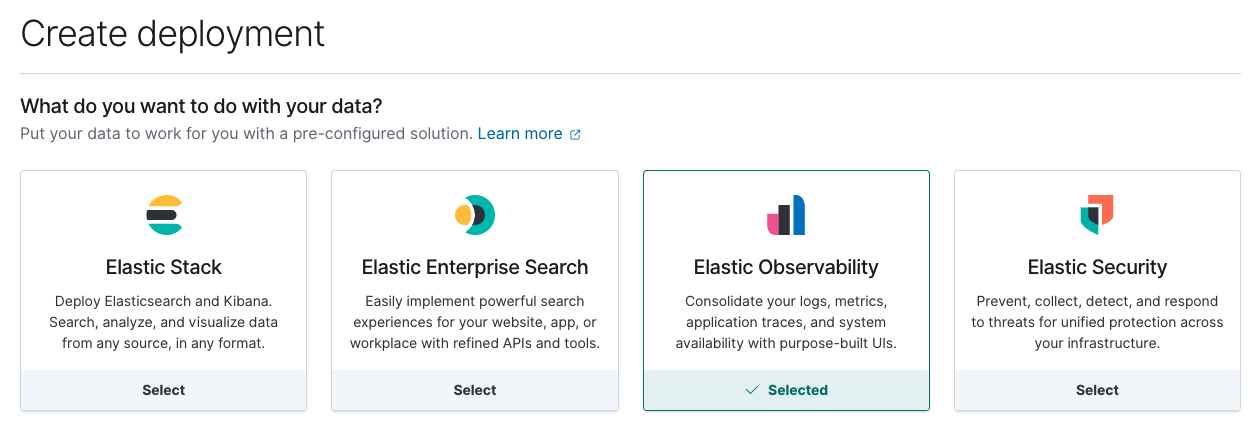
Wenn Sie Ihr Cloud-Deployment zum Laufen gebracht haben, notieren Sie sich die Cloud-ID und die Anmeldedaten für die Authentifizierung. Diese Angaben brauchen wir für die Metricbeat-Konfiguration.
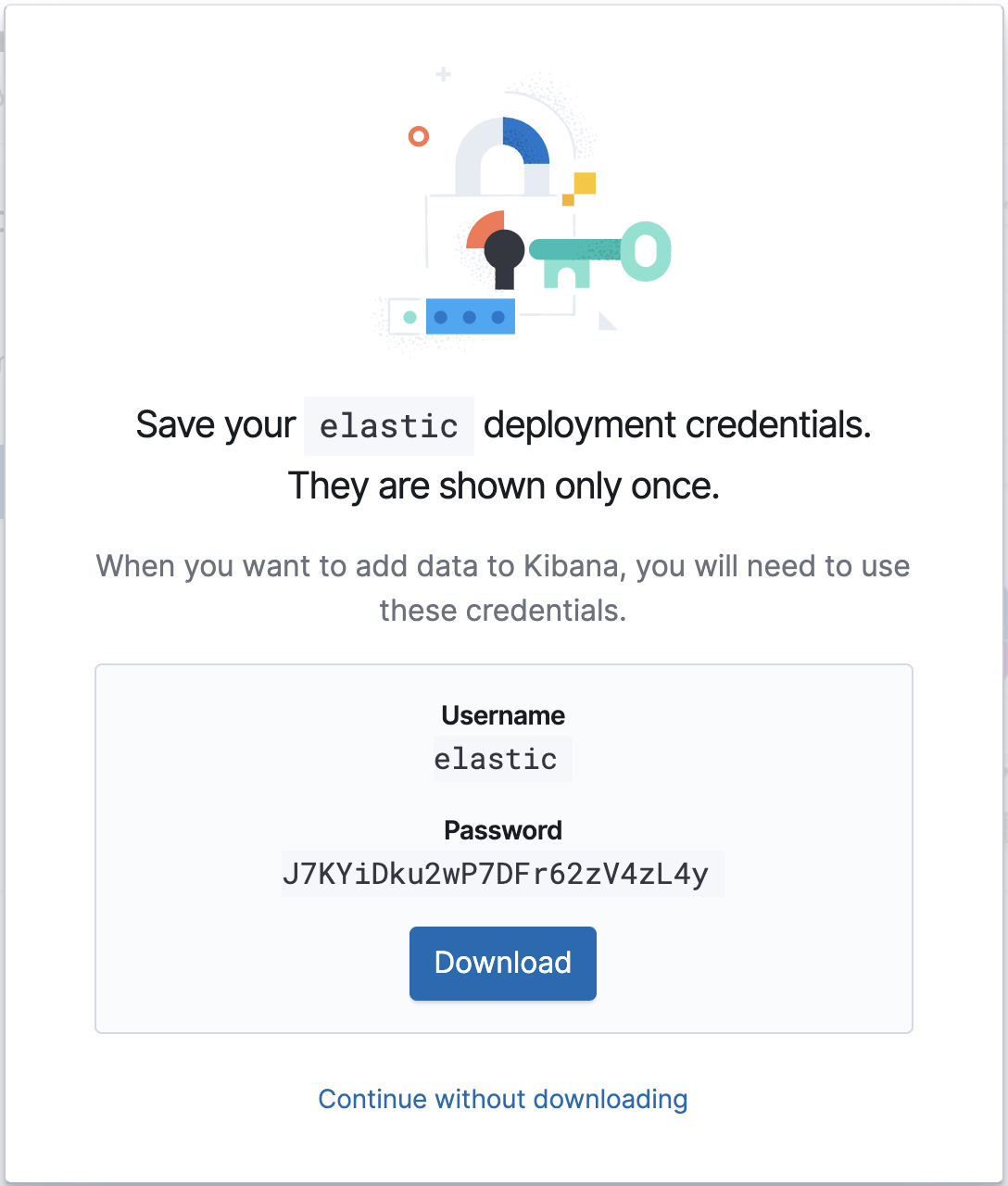
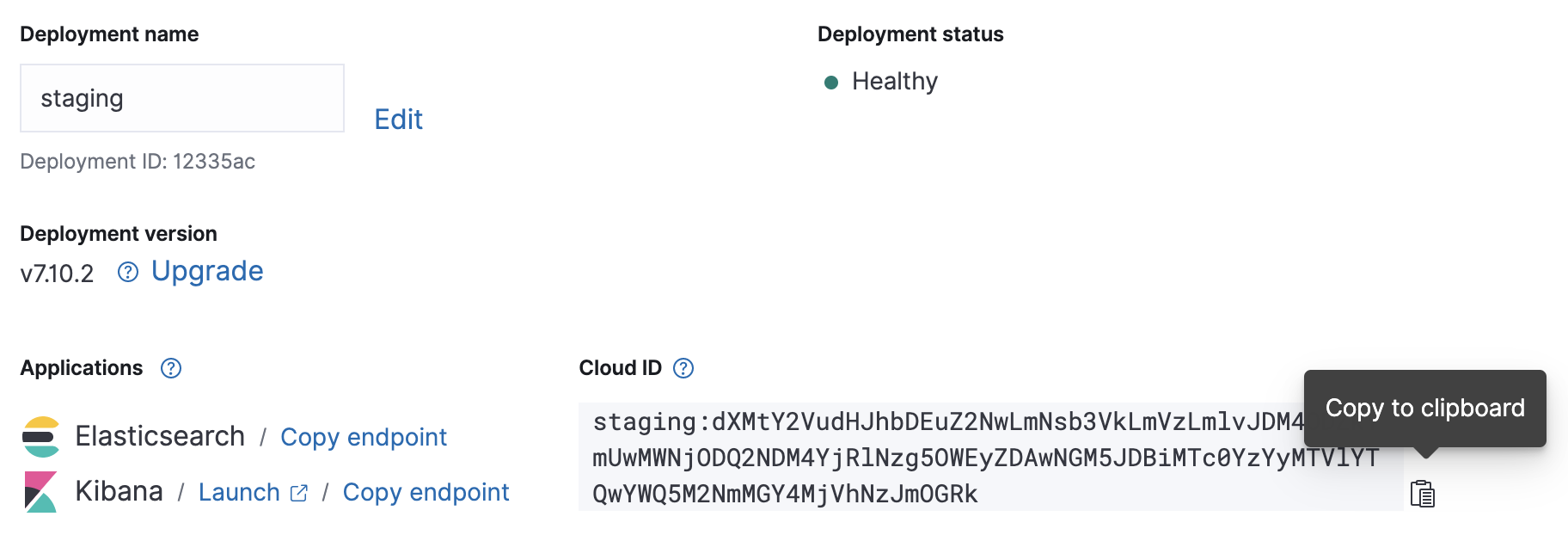
Konfiguration
Die Metricbeat-Konfigurationsdatei finden Sie in /etc/metricbeat/metricbeat.yml. Öffnen Sie sie im Editor Ihrer Wahl und versehen Sie die Parameter cloud.id und cloud.auth mit den Werten für Ihr Deployment.
Beispiel für die Änderung der Metricbeat-Konfiguration anhand der Screenshots weiter oben:
cloud.id: "staging:dXMtY2VudHJhbDEuZ2NwLmNsb3VkLmVzLmlvJDM4ODZkYmUwMWNjODQ2NDM4YjRlNzg5OWEyZDAwNGM5JDBiMTc0YzYyMTVlYTQwYWQ5M2NmMGY4MjVhNzJmOGRk" cloud.auth: "elastic:J7KYiDku2wP7DFr62zV4zL4y"
Die Input-Konfiguration von Metricbeat ist modular. Da die GPU-Monitoring-Tools von NVIDIA die GPU-Metriken über Prometheus veröffentlichen, besteht die nächste Aufgabe darin, das Prometheus-Modul von Metricbeat zu aktivieren.
sudo metricbeat modules enable prometheus
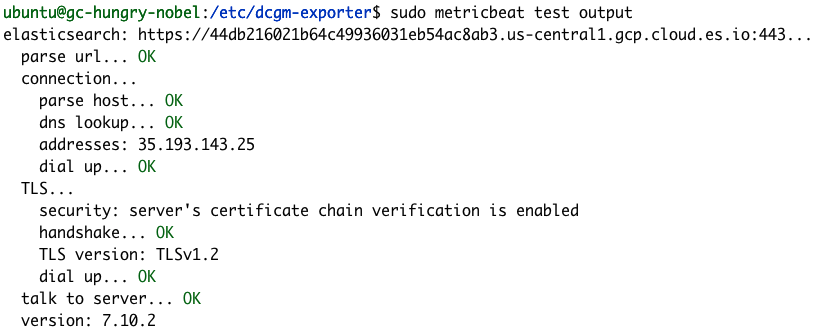
Mithilfe der Metricbeat-Befehle „test“ und „modules“ können wir uns bestätigen lassen, dass unsere Metricbeat-Konfiguration erfolgreich war.
sudo metricbeat test config

sudo metricbeat test output
sudo metricbeat modules list
Wenn die Konfigurationstests bei Ihnen nicht so erfolgreich verlaufen sind wie in den Beispielen oben, sehen Sie sich unsere Hinweise für die Fehlersuche und ‑behebung in Metricbeat an.
Zum Abschluss der Metricbeat-Konfiguration führen wir den zugehörigen Befehl „setup“ aus, mit dem wir ein paar Standard-Dashboards laden und Index-Mappings einrichten. Die Ausführung von „setup“ dauert in der Regel einige Minuten.
sudo metricbeat setup

Exportieren der Metriken
Jetzt geht’s ans Exportieren der Metriken. Dazu starten wir den DCGM-Exporter von NVIDIA:
dcgm-exporter --address localhost:9090 # Ausgabe INFO[0000] Starting dcgm-exporter INFO[0000] DCGM successfully initialized! INFO[0000] Not collecting DCP metrics: Error getting supported metrics: This request is serviced by a module of DCGM that is not currently loaded INFO[0000] Pipeline starting INFO[0000] Starting webserver
Hinweis: Die DCP-Warnung kann ignoriert werden.
Die Konfiguration der DCGM-Exporter-Metriken ist in der Datei /etc/dcgm-exporter/default-counters.csv definiert, in der standardmäßig 38 verschiedene Metriken mit ihren Definitionen aufgeführt sind. Eine vollständige Liste der möglichen Werte finden Sie im DCGM Library API Reference Guide.
Wir starten jetzt in einer anderen Konsole Metricbeat.
sudo metricbeat -e
Jetzt können Sie zur Kibana-Instanz wechseln und das Indexmuster „metricbeat-*“ aktualisieren. Dazu navigieren wir zu Stack Management > Kibana > Index Patterns und wählen aus der angezeigten Liste metricbeat-* aus. Dann klicken wir auf Refresh field list.
Jetzt sind unsere neuen GPU-Metriken in Kibana verfügbar. Die neuen Feldnamen sind mit dem Präfix „prometheus.metrics.DCGM_“ versehen. Das folgende Snippet zeigt die neuen Felder aus Discover:
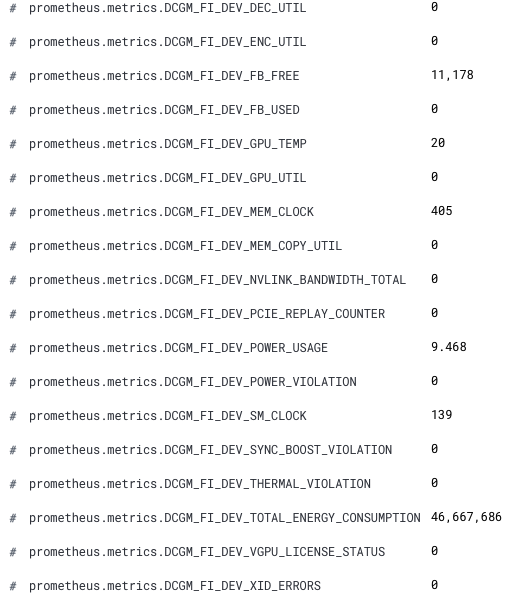
Voilà! Jetzt können wir unsere GPU-Metriken in Elastic Observability analysieren.
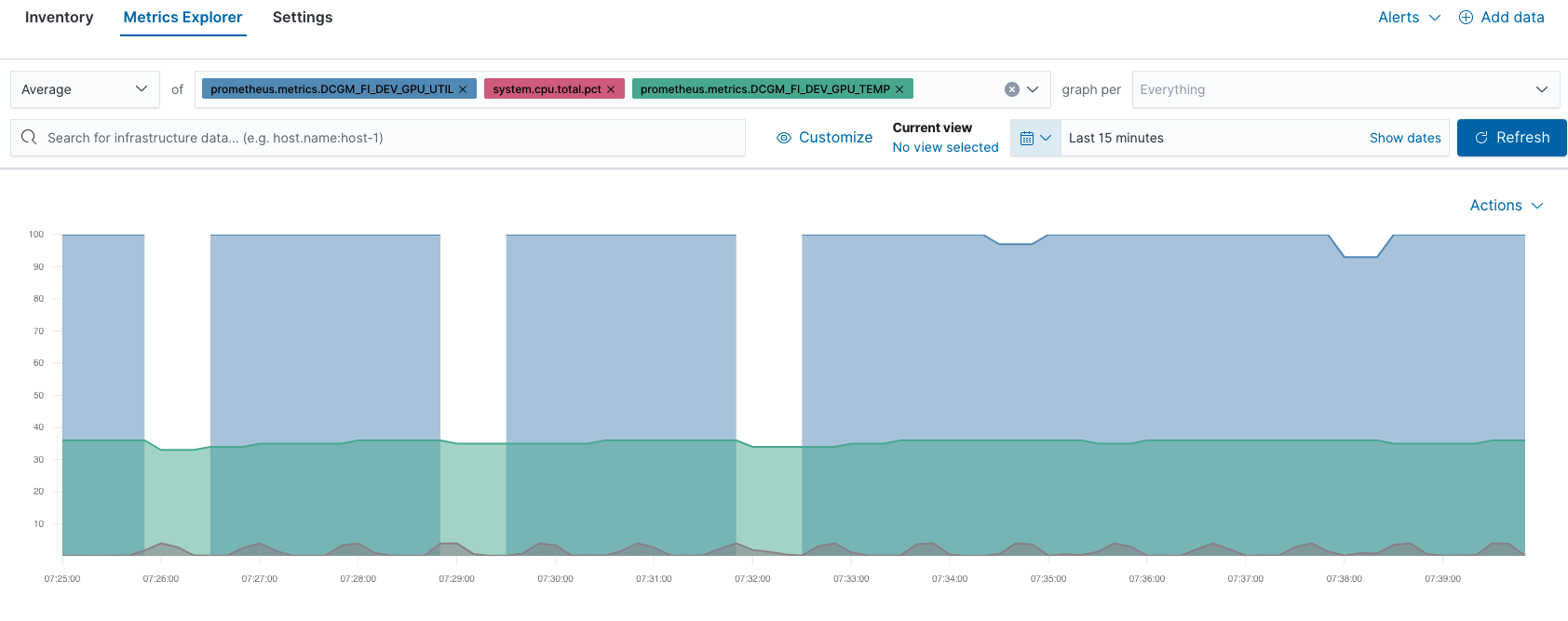
So können wir zum Beispiel in Metrics Explorer die GPU-Performance mit der CPU-Performance vergleichen:
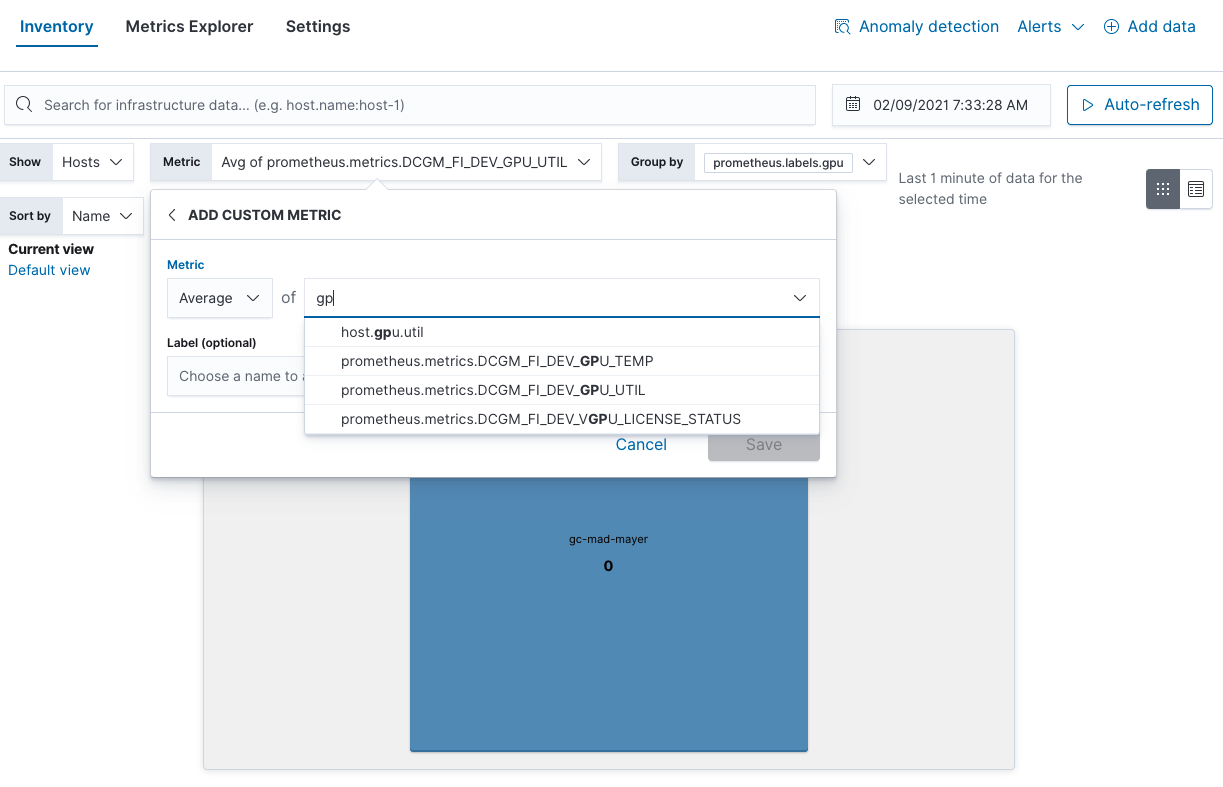
Außerdem können Sie in der Inventaransicht auch Hotspots der GPU-Nutzung finden:
Was muss beim GPU-Monitoring berücksichtigt werden?
Wir hoffen, dass Ihnen dieser Blogpost ein wenig weitergeholfen hat. Die beschriebenen Optionen sind nur einige von vielen Monitoring-Optionen von Elastic Observability, mit denen Sie Ihre Ziele erreichen können. Mit NVIDIA lassen sich unter anderem auch noch die folgenden GPU-Aspekte überwachen:
- GPU-Temperatur: Prüfung auf Hotspots
- Nutzung der GPU-Leistung: Unerwartet hohe Leistungsnutzung => mögliche HW-Probleme
- Aktuelle Taktrate: Unerwartet geringe Taktrate => Leistung gedrosselt oder HW-Probleme
Und wenn Sie einmal die GPU-Last simulieren müssen, können Sie den Befehl dcgmproftester10 verwenden.
dcgmproftester10 --no-dcgm-validation -t 1004 -d 30
Zur weiteren Verfeinerung des Monitorings lassen sich die Empfehlungen von NVIDIA mittels Elastic-Alerting automatisieren. Und wenn Sie es noch weiter treiben möchten, haben Sie die Möglichkeit, mithilfe von Machine Learning Anomalien in Ihrer GPU-Infrastruktur ausfindig zu machen. Wenn Sie noch kein Elastic Cloud-Konto haben und die in diesem Blogpost beschriebenen Schritte selbst nachvollziehen möchten, können Sie Elastic Cloud 14 Tage kostenlos ausprobieren.