Generieren und Visualisieren von Alpha mit Vectorspace AI-Datensätzen und Canvas
Abstract
Lesen Sie nach, wie Vectorspace-Datensätze den Elastic Stack und Canvas in Kibana einsetzen, um Informationen zu visualisieren und maximalen Nutzen aus vorhandenen Daten zu schöpfen.
Hintergrund
Im Jahr 2002 hat Vectorspace im Lawrence Berkeley National Laboratory die sogenannten Feature-Vektoren auf Basis von natürlichem Sprachverstehen (Natural Language Understanding, NLU) entwickelt, die inzwischen auch als Wort-Einbettungen bezeichnet werden. Feature-Vektoren wurden eingesetzt, um Korrelations-Matrixdatensätze zu generieren und verborgene Beziehungen zwischen Genen zu analysieren, die im Zusammenhang mit verlängerter Lebensdauer, Brustkrebs und der Reparatur von DNA-Schäden durch Weltraumstrahlung stehen.
Als Datenquellen dienten Ergebnisse aus Laborexperimenten, wissenschaftliche Literatur aus der National Library of Medicine, Ontologien, kontrollierte Vokabulare, Enzyklopädien, Wörterbücher und andere genomische Forschungsdatenbanken.
Damals wurde außerdem AutoClass entwickelt, ein Bayesscher Klassifikator, der normalerweise für Sterne verwendet wird. AutoClass wurde eingesetzt, um Gruppen von Genen auf Basis eine Datensatzes mit Genexpressionswerten zu klassifizieren. Um die Verluste zu minimieren und hilfreichere Ergebnisse zu erhalten, wurden die Datensätze mit Wort-Einbettungen und Themenmodellierung angereichert. Damals bestand das Ziel darin, die konzeptuellen Verbindungen, die Forscher in der Biomedizin direkt vor einer Entdeckung herstellen, digital zu imitieren. Ein Teil dieser Arbeit wurde als Paper veröffentlicht, das verborgene Beziehungen zwischen Genen beschreibt, die mit einer Verlängerung der Lebensdauer von Fadenwürmern zusammenhängen. Seit 2005 ist die SPAWAR-Abteilung der US-Marine an diesem Programm beteiligt. Seitdem haben verschiedene Ressourcen in anderen Bereichen geforscht, wie etwa den Finanzmärkten.
Tuning für Datensätze
Mit der Zeit hat Vectorspace gelernt, die Datensätze zu „tunen“, indem die durch Wort-Einbettungen abgebildeten Feature-Vektoren erweitert oder miteinander verknüpft werden. Auf diese Weise entstehen neue Visualisierungen, Interpretationen, Hypothesen oder Entdeckungen. Beim Anreichern von Zeitreihendatensätzen für die Finanzmärkte mit dieser Art von Feature-Vektoren können einzigartige Signale produziert oder ein Alpha generiert werden. Am Anfang stehen Datenquellen, die für einen bestimmten Kontext oder ein bestimmtes Thema optimiert wurden, wie unten gezeigt:
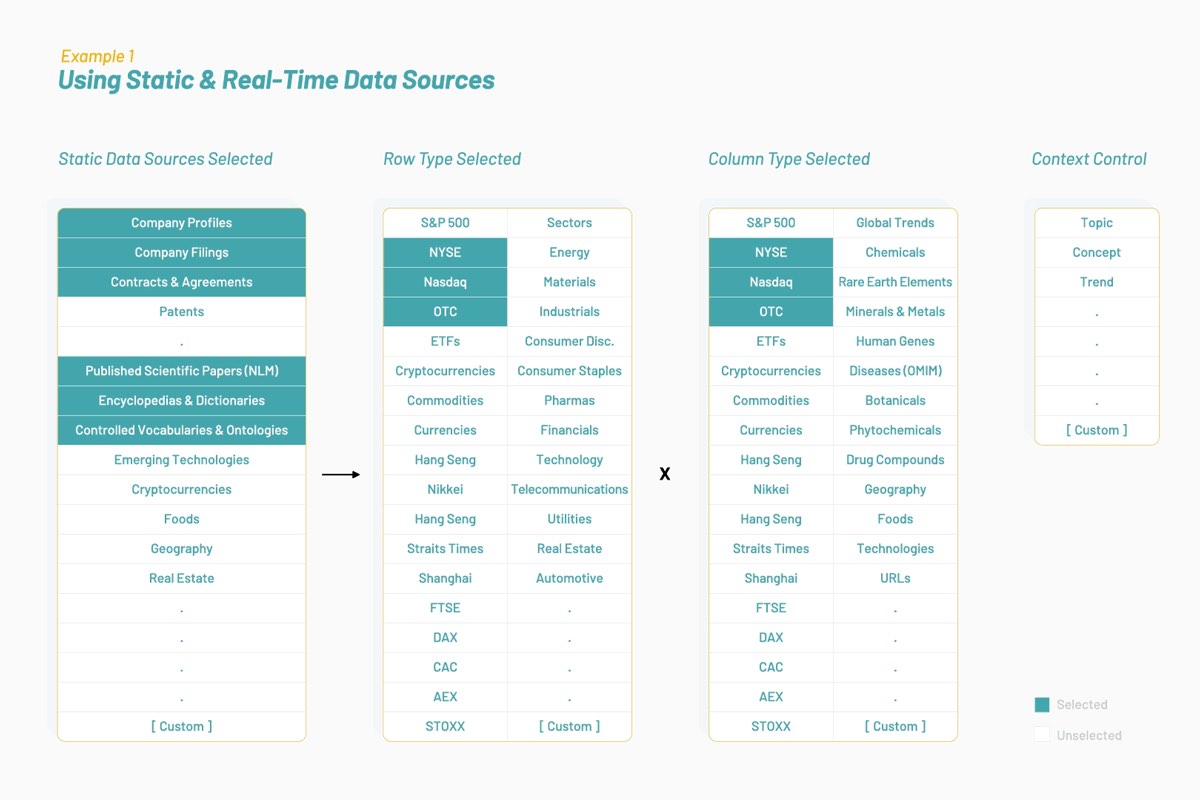
Die resultierenden Datensätze bestehen aus Feature-Vektoren, bei denen es sich um Wort-Einbettungen handelt, die wiederum auf biomedizinischer Literatur und natürlicher Sprache zu börsennotierten Unternehmen an der New Yorker Börse und dem NASDAQ basieren. Ein interdisziplinärer Forschungsansatz könnte sich damit befassen, ob Gene und Aktien gemeinsame Attribute und Verhaltensweisen haben, wenn sie in den gemeinsamen Pfaden miteinander interagieren.
Ein zweiteiliges Ziel
Erster Teil: Herausfinden, wie das Wissen zu beobachteten Interaktionen zwischen Genen, Proteinen, Medikamenten und Krankheiten auf Aktien angewendet werden kann.
Zweiter Teil: Mögliche Schaffung einer Finanzierungsquelle zur Verbesserung der Sicherheit lange Reisen im Weltall. Dazu wurden erweiterte Datensätze verwendet, um Alpha in den Finanzmärkten zu generieren.
Upside-Ereignisauslöser
Interagieren Gene auf ähnliche Weise miteinander wie Aktien? Am 20. September 2004 fand ein Ereignis statt, das diese Frage zumindest teilweise beantwortet hat. Die Merck-Aktie (MRK) fiel um 21 %, (höchstwahrscheinlich) weil die Arznei Vioxx im Verdacht stand, Herzanfälle zu verursachen. Dieses Ereignis hat weitere latente sympathische Schwankungen der Aktienkurse anderer börsennotierter Pharmaunternehmen verursacht, insbesondere für Pfizer (PFE). Mit der von Vectorspace produzierten Datensatzanreicherung konnte eine verzögerte Schwankung des Kurses von PFE vorhergesagt werden, basierend auf dem Zusammenhang mit dem von Merck produzierten Medikament Vioxx. Weitere Details dazu später.
Im weiteren Verlauf der Forschung entstand ein interessantes Paper, das im Februar 2001 mit dem Titel „Contagious Speculation and a Cure for Cancer: A Non-Event that Made Stock Prices Soar“ im Journal of Finance veröffentlicht wurde. Dieses Paper beschreibt ein Ereignis im Zusammenhang mit dem Unternehmen EntreMed (damaliges Börsenkürzel ENMD):
„Nach einem Sonntagsartikel in der New York Times über die potenzielle Entwicklung neuer Medikamente zur Krebsheilung stieg die EntreMed-Aktie von 12.063 zum Börsenschluss am Freitag auf 85 zur Öffnung und 52 zur Schließung am Montag. Die Aktie schloss in den drei folgenden Wochen jeweils über 30. Die Begeisterung schwappte auf andere Biotech-Aktien über. Der potenzielle Durchbruch in der Krebsforschung war jedoch schon mehr als fünf Monate zuvor in der Zeitschrift Nature und in verschiedenen beliebten Zeitungen inklusive der Times veröffentlicht wurden. In diesem Fall führte die begeisterte öffentliche Aufmerksamkeit zu einem dauerhaften Anstieg der Aktienpreise, obwohl keine wirklich neuen Informationen veröffentlicht wurden.“ Eine der vielen aufschlussreichen Beobachtungen der Forscher aus dem Fazit sticht besonders hervor: „[Preis-]Schwankungen können sich auf Aktien mit bestimmten Gemeinsamkeiten konzentrieren, dabei muss es sich jedoch nicht um wirtschaftliche Grundlagen handeln.“ — (Huberman und Regev 387)
Die Teams mit Hintergrundwissen in verschiedenen Bereichen wie etwa der Entwicklung quantitativer Algorithmen, Investmentbanking und der Leitung börsennotierter Unternehmen stellten Ähnlichkeiten zwischen Genen und Aktien fest. Analog zu Genen haben auch Aktien „Ausdruckswerte“, Attribute, verborgene Beziehungen untereinander und mit externen Ereignissen, Themen oder globalen Trends. Diese Beziehungen sind eine Art von Wissen, das tendenziell zum allergrößten Teil in der menschlichen Sprache eingebettet ist. Analog zu Genen können auch Cluster von Aktien miteinander interagieren und sympathisieren. Diese Daten können eingesetzt werden, um zukünftige Kurskorrelationen zwischen Unternehmen auf Basis der „latenten Verschränkung“ vorherzusagen. Aktien-Cluster können außerdem als „Baskets“ dienen, die bekannte und verborgene Beziehungen untereinander und mit externen Ereignissen gemeinsam haben. Cluster oder Baskets können mithilfe von Kontext kontrolliert werden.
Nicht alle Boote steigen mit der Flut
Vectorspace hat versucht, die Ursachen der beobachteten Korrelationen zu analysieren und sah eine Gelegenheit zur Schaffung eines Finanzierungsinstruments, das sich eine Ineffizienz der Finanzmärkte auf Basis von analysierbaren Informationsblasen zunutze macht. Das Unternehmen beobachtete verzögerte Reaktionen zwischen verschiedenen Aktien, ähnlich einer Flut, die die Boote in einer Bucht oder einem Hafen einige Minuten später anhebt als auf dem offenen Meer. Der Wasseranstieg in einem Hafen kann durch ein Ereignis ausgelöst werden, das anschließend die Boote im Hafen anhebt, die in diesem Beispiel für Cluster von börsennotierten Assets stehen, wie etwa Aktien. Auf den Finanzmärkten steigen jedoch nicht alle Boote. Die Vorhersage, welche Assets mit einem Ereignis verknüpft sind, zusammen mit der Stärke und dem Kontext für die Korrelation, kann ein wichtiges Signal liefern. Dabei handelt es sich um eine Art von asymmetrischen Informationen, die eingesetzt werden können, um den Markt vorherzusagen oder auch kurz- oder langfristige Risiken beim Kapitaleinsatz zu reduzieren. Dies wird auch als „Alpha-Generierung“ bezeichnet und kann visualisiert und interpretiert werden.
Um die wahrscheinlichkeitstheoretische Hypothese mit den steigenden Booten zu testen, wurden Daten aus 20 Jahren analysiert und nach Mustern für sympathische Schwankungen oder latente Verschränkungen zwischen den Aktienkursen von Unternehmen auf Basis von Marktereignissen durchsucht. Dabei wurden zahlreiche Beispiele gefunden, darunter auch die drei folgenden Ereignisse: EntreMed (ENMD) 1998, Merck (MRK) 2004 und Celgene (CELG) 2019.
Ereignis 1: EntreMed (ENMD) gewinnt 608 % (4. Mai 1998)
EntreMed gibt nach Börsenschluss am Freitag bekannt, dass das Unternehmen eine Heilung für eine bestimmte Art von Krebs entwickelt hat. Der Aktienkurs stieg von 12 $ am Freitag auf 85 $ zur Börsenöffnung am Montag. In Sympathie dazu stieg ein ganzer Basket von Aktien ebenfalls an, die in Verbindung zu ENMD standen, auf Basis von menschlicher Sprache rund um die Proteinforschung im Zusammenhang mit Krebstherapien.
Hier sind einige relevante Ausschnitte aus dem Paper zu diesem Ereignis:
Seite 392 Absatz 4: „Die Erlöse von drei dieser Unternehmen überschritten 100 Prozent, die Erlöse zweier Unternehmen lagen zwischen 50 und 100 Prozent, und die Erlöse zweier weiterer Unternehmen lagen zwischen 25 und 50 Prozent. Ein Vergleich dieser Erlöse mit der extremen Erlösverteilung aus Tabelle I zeigt, wie ungewöhnlich die Erlöse dieser sieben Biotech-Aktien waren, und insbesondere, wie ungewöhnlich ihr Clustering war.“
Seite 395 Absatz 1: „Es ist nicht ungewöhnlich, dass sich ein Durchbruch in der Krebsforschung nicht nur auf den Aktienkurs des Unternehmens auswirkt, das die Kommerzialisierungsrechte an der Entwicklung besitzt. Die Märkte erkennen mögliche Spillover-Effekte und vermuten, dass andere Unternehmen ebenfalls von der Innovation profitieren werden.“
Seite 396 Absatz 3: „[Preis-]Schwankungen können sich auf Aktien mit bestimmten Gemeinsamkeiten konzentrieren, dabei muss es sich jedoch nicht um wirtschaftliche Grundlagen handeln“
Ereignis 2: Merck (MRK) verliert 25,8 % (30. September 2004)
Merck hat Vioxx, ein Medikament im Wert von 2,5 Milliarden US-Dollar, vom Markt genommen, da es aufgrund von COX-2-Hemmern Herz- und Schlaganfälle verursacht. Diese Korrelation hatte eine Ursache. MRK schloss mit 45,07 $ am Vortag und öffnete mit 33,40 $ am 30. September. Bei Experimenten mit Wort-Einbettungen als Feature-Vektoren wurde festgestellt, dass Pfizer (PFE) aufgrund ähnlicher Feature-Vektoren am engsten mit Merck verknüpft war, da das Unternehmen zur gleichen Zeit an einem ähnlichen Arzneiwirkstoff arbeitete, der auf dem COX-2-Hemmer basierte. Wenige Wochen später sank der Kurs von PFE beträchtlich.
„Am 17. Dezember 2004 kündigten Pfizer und das US National Cancer Institute an, dass sie die Verabreichung von Celebrex (celecoxib), einem Cyclooxygenase-2-Hemmer (COX-2) in einer laufenden klinischen Untersuchung zur Vermeidung von Dickdarmpolypen aufgrund eines erhöhten Risikos von Herz- und Gefäßkomplikationen einstellen würden. Rofecoxib (Vioxx), ein weiterer COX-2-Hemmer von Merck, wurde im September 2004 weltweit vom Markt genommen, da ein erhöhtes Risiko für Herzinfarkte und Schlaganfälle festgestellt wurde.“ - CMAJ.
Der PFE-Kurs sank um 24 $, von 28,98 $ zur Schließung am Vortag auf einen Tiefstwert von 21,99 $ an diesem Tag.
Ereignis 3: Celgene (CELG) gewinnt 31,8 % (3. Januar 2019)
Am 3. Januar 2019 hat Bristol-Myers Squibb (BMY) das Unternehmen Celgene (CELG) für 74 Milliarden US-Dollar gekauft. CELG stieg über Nacht von 66,64 $ auf 87,86 $ pro Aktie, was einem Anstieg von 31,8 % entspricht. Im Verlauf von vier Tagen verzeichnete ein Basket von Aktien im Zusammenhang mit CELG einen Anstieg von 20 %, basierend auf Beziehungen in menschlicher Sprache rund um diese Unternehmen. Als Datenquellen für die Beziehungen zwischen diesen Unternehmen wurden unter anderem Profilsammlungen von börsennotierten Unternehmen und von Experten begutachtete wissenschaftliche Veröffentlichungen herangezogen.
Bei der Vectorspace-Analyse dieses Vorgangs wurde festgestellt, dass bestimmte NLU-Korrelationen latente kursbasierte Korrelationen zwischen Aktienkursen und zwischen Aktienkursen und Ereignissen verursachen können. Das Team hat herausgefunden, dass diese und ähnliche Beispiele verwendet werden können, um den Markt vorherzusagen oder um Arbitrage-Modelle zu entwickeln.
Visualisieren von Alpha
Heutzutage setzt Vectorspace AI Datensätze ein, um Netzwerke von verborgenen Beziehungen zwischen Interaktionen von Genen, Proteinen, Mikrobien, Arzneien und Krankheiten in den Biowissenschaften oder zwischen Aktienkursen an den Finanzmärkten aufzudecken. Unsere Kunden nutzen diese Datensätze hauptsächlich, um vorhandene interne Datensätze anzureichern. Die Datensätze werden mit Kombinationen von Feature-Vektoren generiert, die aus gewichteten Attributen auf Basis der Vektorisierung von Wörtern und Objekten bestehen. Die Datensätze werden praktisch in Echtzeit aktualisiert und mit Utility-Token-Gutschriften über eine API abgerufen.
Durch den Einsatz von Elastic Stack und Canvas kann Vectorspace seinen Kunden Datenvisualisierungen und Interpretationen in neutralen, vollständig konfigurierbaren Ansichten praktisch in Echtzeit bereitstellen. Dies ist wichtig für das Gesamtverfahren, da neue Interpretationen und Einblicke zu neuen Hypothesen, Signalen oder Entdeckungen führen können.
Es ist nicht unüblich, dass Anlageverwaltungsunternehmen und Institutionen aus Datenschutzgründen lokale Data-Engineering-Pipelinelösungen anfordern. Wir verpacken unsere Data-Engineering-Pipeline mit Elastic Cloud Enterprise, um unseren Kunden eine Komplettlösung für die Signalgenerierung anbieten zu können.
Die Vectorspace-Kunden im Finanzbereich nutzen die Daten, um den Signal-Rausch-Abstand zu optimieren, Alpha zu generieren, Verlustfunktionen zu minimeren oder Sharpe- oder Sorino-Verhältnisse zu maximieren. Dazu werden Ergebnisse aus Rückvergleichsstrategien auf Basis von Datensatzanreicherungen praktisch in Echtzeit visualisiert und interpretiert, und Überanpassungen in Rückvergleichen reduziert.
Die Aktualisierungshäufigkeit der Datensätze schwankt zwischen einer Minute und einem Monat, je nach Volatilität der zugrunde liegenden Datenquellen. Ein häufig angefragtes Paket besteht aus einem Datensatz mit einer Zeitreihenserie, in der die einzelnen Zeilen börsennotierte Unternehmen enthalten, die mit Feature-Vektoren in Form von Arzneiwirkstoffen angereichert wurden, die wiederum eine NLU-basierte Korrelationsgewichtung haben. Dabei ist es entscheidend, einen Kontext für die Analyse auszuwählen. Ebenso wie der Kontext eine Definition beeinflussen kann, können die richtigen kontextbezogenen Einschränkungen den Wert einer Korrelationsgewichtung im Lauf der Zeit ändern. Der Kontext wirkt sich auch auf die Stärke der Beziehungen zwischen Unternehmen und zwischen Unternehmen und Ereignissen aus.
Visualisierung mit Canvas
Lassen Sie uns nun einen dieser Datensätze verwenden, um den Basket von Aktien zu generieren und zu visualisieren, die mit Celgene (CELG) verknüpft sind, zusammen mit dem Ereignis, das einen verzögerten Kursanstieg für einen Teil dieser Aktien ausgelöst hat. Dabei besprechen wir die typischen Schritte der Vectorspace-Kunden mit diesen Datensätzen zur Interpretation der Ergebnisse praktisch in Echtzeit, sowie die Ergebnisse eines Rückvergleichs in Canvas. Zunächst sehen wir uns die Endergebnisse für eine ganze Gruppe von Baskets an, um zu bestätigen, dass der Celgene-Basket kein handverlesener Einzelfall ist.
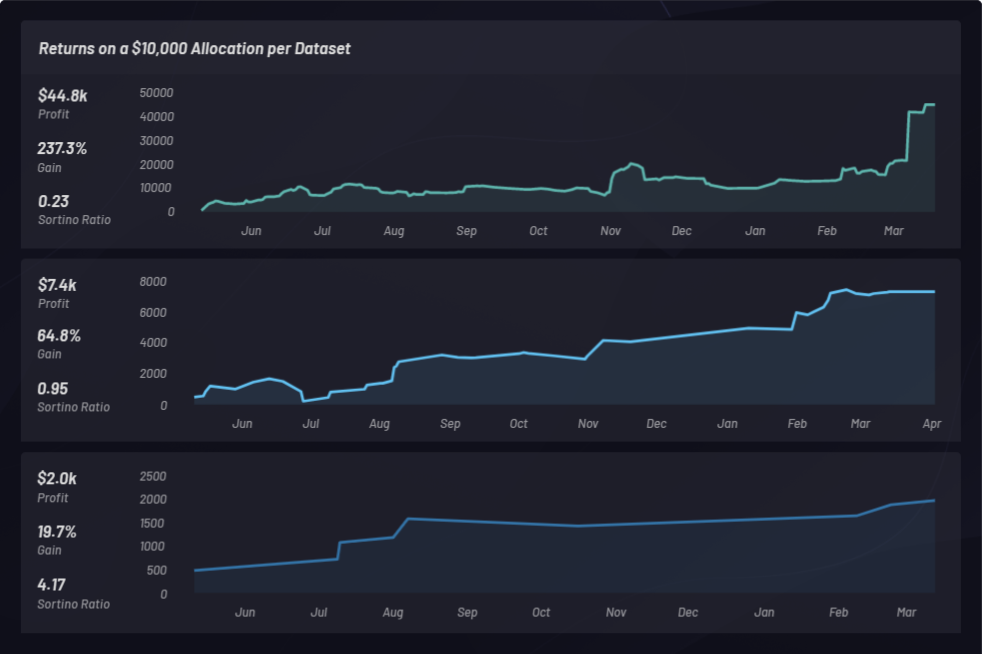
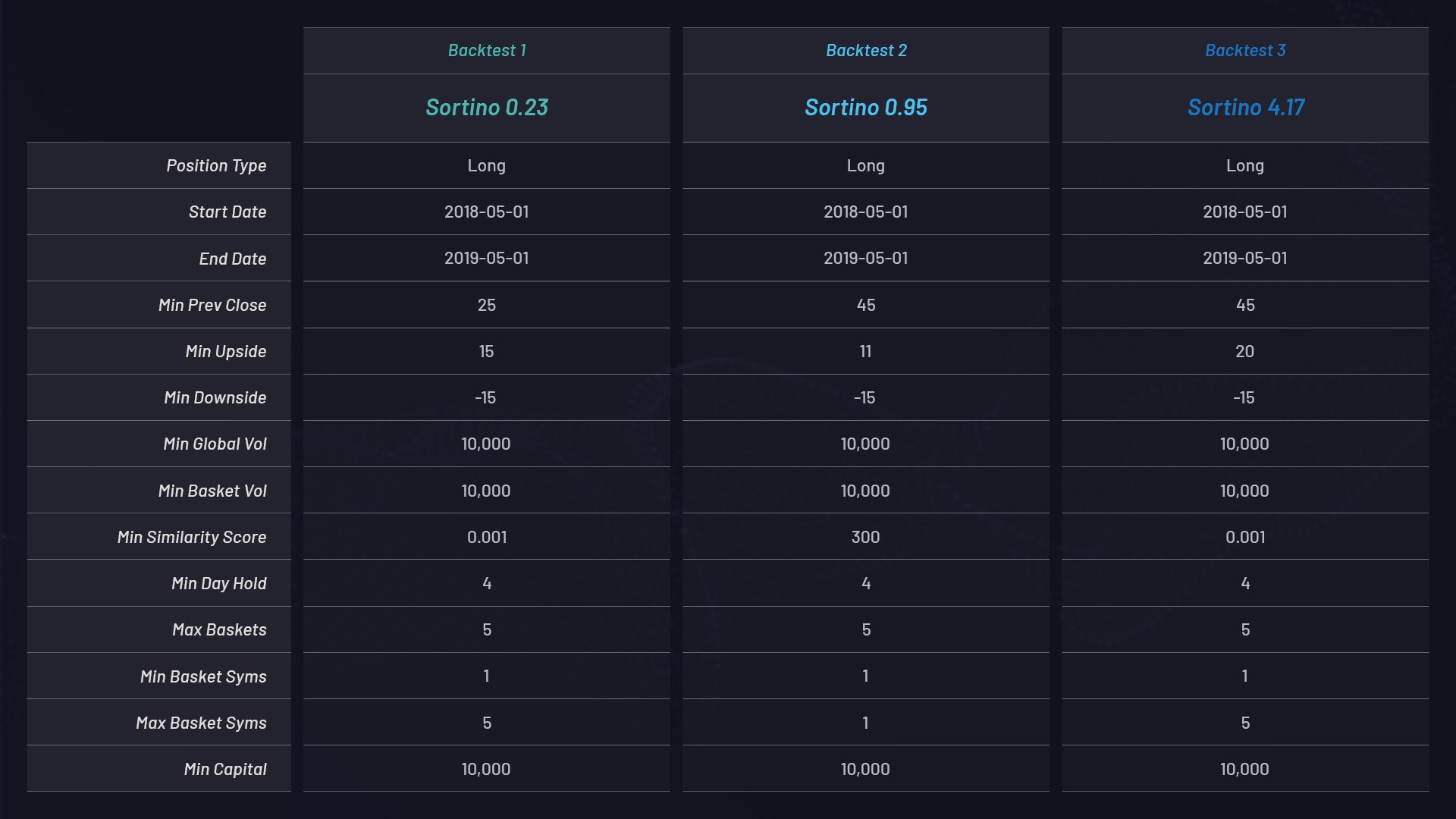
Die folgenden drei Rückvergleiche verwenden Long-Only-Baskets mit verschiedenen Parametereinstellungen. Die Modelle verwenden einen Kapitaleinsatz von 10.000 $ und sind nach ihrem Sortino-Verhältnis geordnet:
Parametereinstellungen für die einzelnen Baskets:
In den folgenden Abbildungen wurden die Rückvergleichsergebnisse in Kibana geladen und als Statistiken dargestellt:
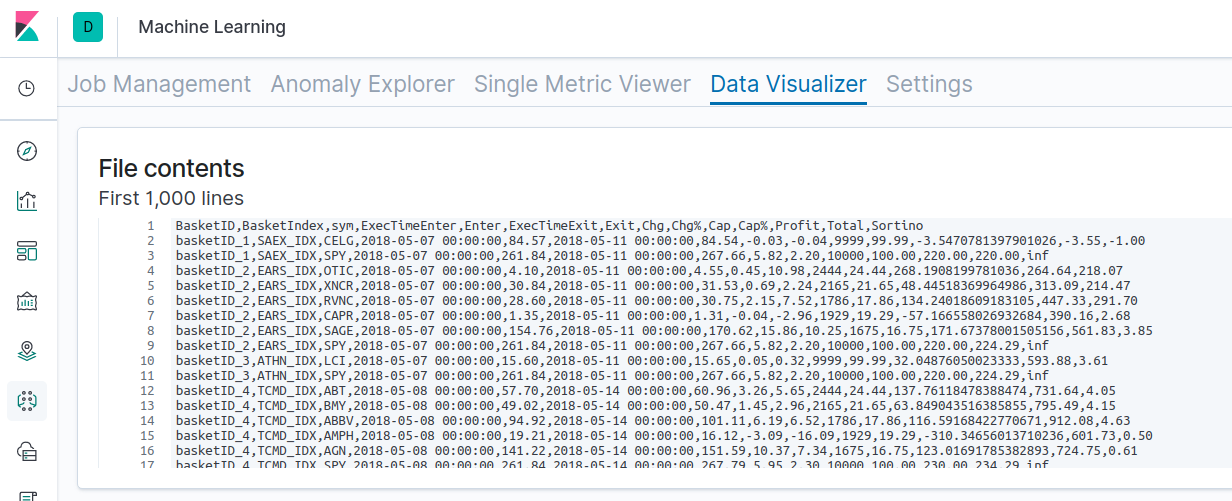
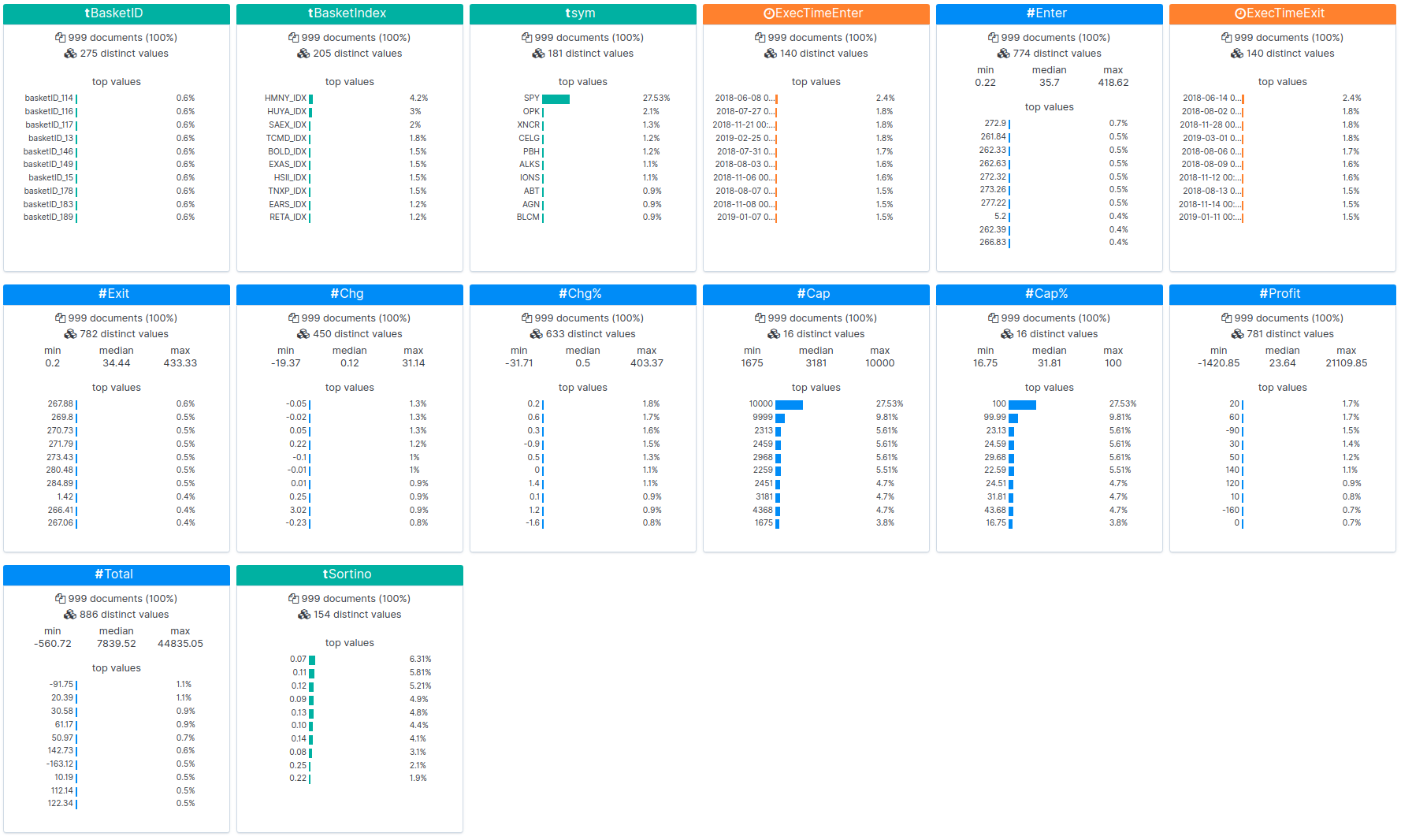
Sie finden die Rohergebnisse für einen der Rückvergleiche hier. Mit den folgenden Schritten können Sie Rückvergleiche für angereicherte NLU-Datensätze durchführen. Wir haben diese Schritte verwendet, um die oben gezeigten Ergebnisse zu generieren.
- Wort-Einbettungen in Form von Feature-Vektoren werden für alle NYSE- und Nasdaq-Aktien mit der Datensatz-API generiert.
- Wir verwenden die Kursdaten aller NYSE- und Nasdaq-Aktien für ein ganzes Jahr vom 1. Mai 2018 bis zum 1. Mai 2019, um nach Ereignisauslösern zu suchen, die durch einen plötzlichen Anstieg der Aktienkurse definiert sind.
- Für alle Aktien, deren prozentualer Anstieg einen bestimmten Schwellenwert überschreitet, z. B. + 15 %, wird aus dem Datensatz ein Cluster oder Basket von miteinander verknüpften Aktien generiert. Beachten Sie dazu den Parameter „MIN_UPSIDE“ in der oben gezeigten Tabelle.
- Anschließend werden Filterparameter wie Volumen, Marktwert, Floating usw. eingesetzt, um den Basket zu verfeinern.
- Ein- und Ausstiegszeiten sind mit einem Hold-Zeitraum von vier Tagen definiert.
- Die Erlöse werden für lang- und kurzfristige Baskets zusammen mit S&P 500 als Baseline-Vergleich sowie mit Sortino-Verhältnissen berechnet.
- Die Datensätze und Erlöse werden mit Canvas überwacht, visualisiert und interpretiert.
Rückvergleichsergebnisse
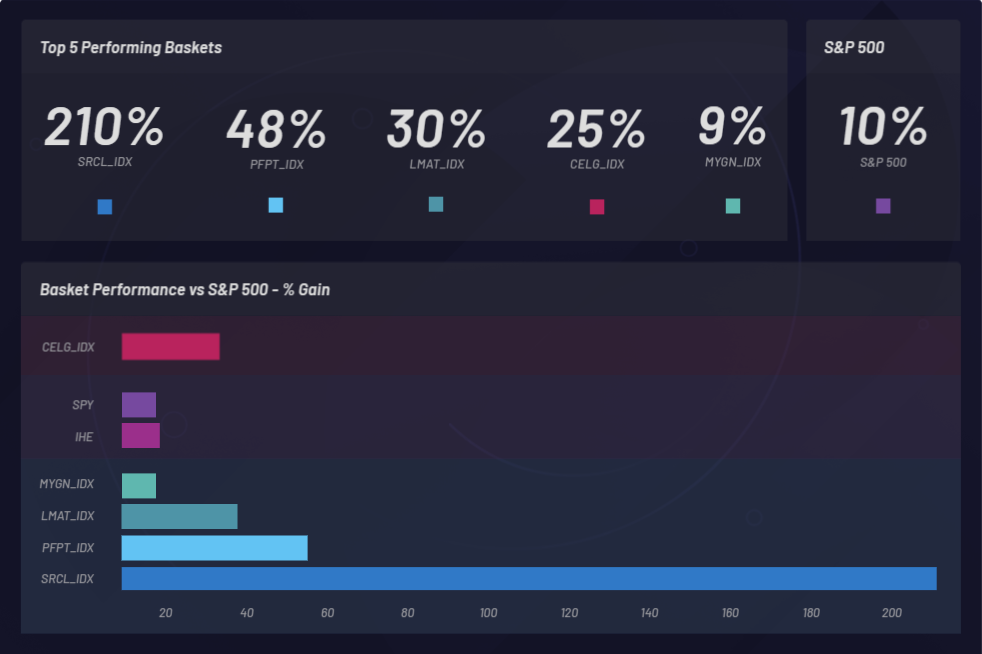
Sehen wir uns nun die Gesamtergebnisse der drei einjährigen Rückvergleiche vom 1. Mai 2018 bis zum 1. Mai 2019 mit Canvas an, jeweils auf Basis der Performance aller Baskets, die in diesem Zeitraum generiert wurden.
Bei den Rückvergleichen werden Unternehmen ermittelt, deren Aktienkurse nach dem Kauf von Celgene einen Anstieg verzeichneten. Wir laden einen erweiterten Datensatz, in dem wir Korrelationen beobachten können. Die aus dem Datensatz generierten Baskets (Cluster) können ebenfalls nach ihrer Performance angezeigt werden. Wir können einen Basket mit der Baseline-Performance von S&P 500 vergleichen, um sicherzustellen, dass wir zumindest das Marktmittel überschreiten. Einzelne Baskets werden überwacht, um festzustellen, ob sie besser performen als S&P 500 (SPY):
In der folgenden Grafik überwachen wir ein Ereignis und die daraus resultierenden sympathischen Schwankungen anderer Aktien. In diesem Fall war CELG (Celgene) das Ereignis, und EPZM (Epizyme) wurde als resultierende Basket-Komponente ausgewählt. NLU-basierte Korrelationen können preisbasierte Korrelationen vorhersagen. Wir können aktualisierte NLU-basierte Korrelationen zwischen Unternehmen und Ereignissen erfassen, um asymmetrische Arbitrage-Modelle zu entwickeln. Ein Vorsprung vor dem Markt ist nur dann möglich, wenn die Reaktion in Form einer Preisschwankung oder Preiskorrelation verzögert erfolgt, im Gegensatz zu NLU-basierten Korrelationen zwischen CELG und EPZM, die wir hier beobachten können:
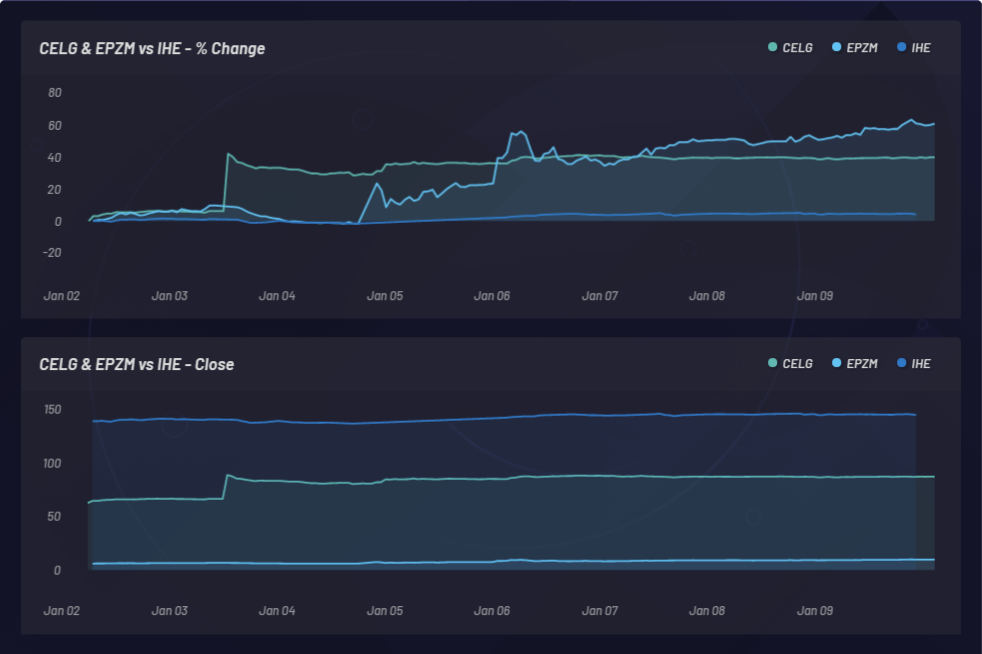
CELG (Celgene) und AGIO (Agios Pharmaceuticals):
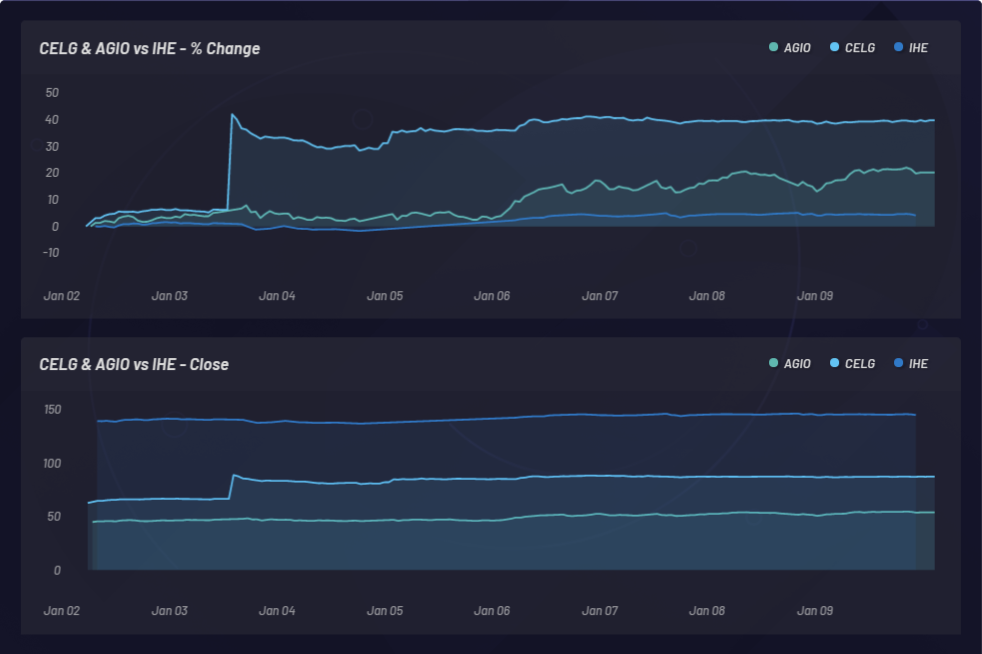
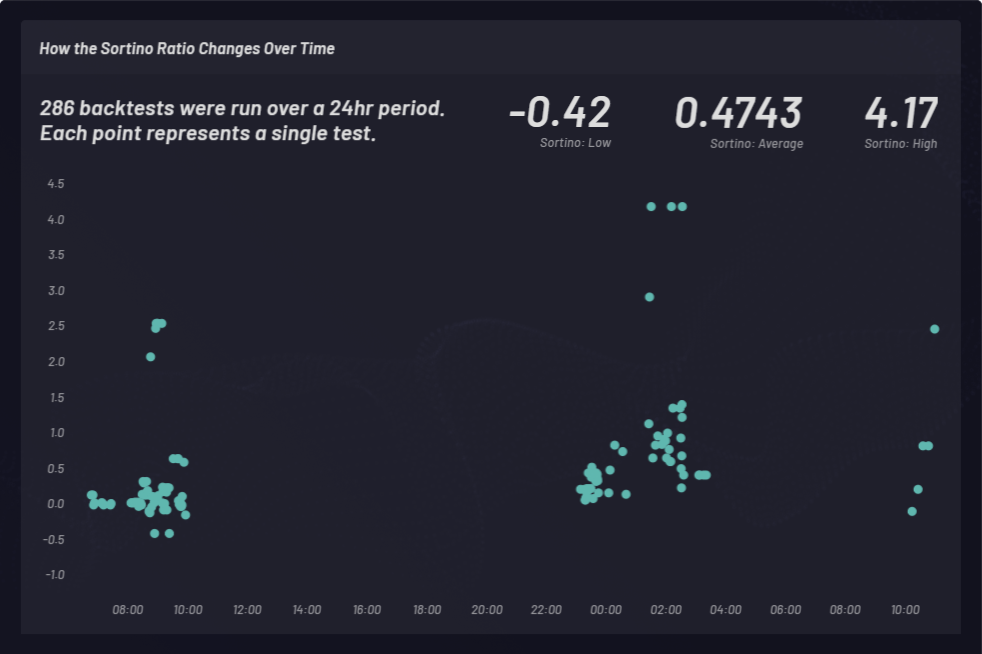
Ein Sortino-Verhältnis wird berechnet, um risikobereinigte Renditen zu messen. Im folgenden Beispiel verwenden wir ein Sortino-Verhältnis anstelle eines Sharpe-Verhältnisses, um die Aufwärts-Volatilität besser zu berücksichtigen. Das Sortino-Verhältnis verändert sich mit der Zeit. Rückvergleiche mit Long-Baskets wurden zu drei verschiedenen Zeitpunkten während eines 24-stündigen Zeitraums durchgeführt (siehe unten). Insgesamt wurden 286 Rückvergleichs-Durchläufe mit verschiedenen globalen Parametereinstellungen durchgeführt. Jeder Punkt im folgenden Cluster steht für einen einzelnen Rückvergleich mit dem jeweiligen Sortino-Verhältnis auf der Y-Achse:
Berücksichtigung von wechselnden Korrelationen
Die National Library of Medicine veröffentlicht alle 24 Stunden etwa 1.500 von Experten begutachtete wissenschaftliche Papers. Vectorspace nutzt die NLM als Datenquelle.

Die Korrelationen zwischen Genen, Arzneiwirkstoffen, pharmazeutischen Nachrichten und börsennotierten Unternehmen ändern sich im Lauf der Zeit, manchmal innerhalb von Sekunden. Diese Änderungen beeinflussen den Signal-Rausch-Abstand bei der Entdeckung von Wirkstoffen, die sich möglicherweise für alternative Nutzungen oder Neupositionierungen eignen.
Wenn sich die Korrelationswerte zwischen einem börsennotierten Unternehmen und Genen, Proteinen, Arzneiwirkstoffen, Mikroben oder Krankheiten ändern, werden diese neuen Beziehungen im Datensatz abgebildet und können mit Canvas praktisch in Echtzeit überwacht werden.

Durch die Kontextsteuerung bei der Erstellung von NLU-basierten Datensätzen können neue Arten von Korrelationsbewertungen ergeben. Es ist wichtig, den Kontext von NLU-Beziehungen zu kontrollieren, um neue Einblicke zu gewinnen.
Mit der zusätzlichen Kontextkontrolle können die Forscher NLU-basierte Datensätze verwenden, um Fragen zu beantworten, wie etwa: „Welche Pharma-Aktien stehen im Zusammenhang mit diesen Arzneiwirkstoffen im Kontext von DNA-Reparaturgenen auf Basis der neuesten Forschungsergebnisse?“. Außerdem können die Antworten oder Ergebnisse mit Canvas umfangreich visualisiert und interpretiert werden.
Alle 24 Stunden werden etwa 1.500 neue von Experten begutachtete wissenschaftliche Papers sowie Nachrichten und andere öffentliche Ankündigungen veröffentlicht. Daher ändern sich die Korrelationsgewichtungen, die wiederum Änderungen in den Beziehungen beispielsweise zwischen börsennotierten Pharmaunternehmen und Arzneiwirkstoffen definieren. In Kombination mit internen Datenquellen können NLU-basierte Datensätze einzigartige Signale liefern.
Fazit
Korrelationen auf Basis von natürlicher Sprachverarbeitung und NLU können den Weg für neue Einblicke, Hypothesen oder Entdeckungen ebnen.
NLU-Datensätze eröffnen völlig neue Möglichkeiten für Biowissenschaften und Aktienmärkte im Zusammenhang mit kontextbezogenen Korrelationen, alternativen Datenquellen, Feature-Vektoren, Visualisierung und Interpretation. Möglicherweise werden unsere Teams in Zukunft einige dieser Themen besprechen, beispielsweise die Anreicherung von Zeitreihendaten für eine Vielzahl von handelbaren Vermögenswerten. Anhand der einzelnen NLU-Feature-Vektoren können unsere Teams erklären, wie sich graphenbasierte Beziehungsnetzwerke oder ganze Netzwerke von Clustern mit Canvas und anderen Tools im Elastic Stack erstellen lassen. Außerdem können unsere Teams beschreiben, wie Feature-Vektoren computerbasiert miteinander verknüpft werden können, um ausgewählte Verlustfunktionen auf Basis einer Utility-Token-API mit einem Blotter für offene Märkte zu minimieren.
Vectorspace arbeitet weiterhin an der Entwicklung verwandter Anwendungen für Datensätze zur Analyse der Reparatur von Erbgutschäden durch LET-Strahlung (Weltraumstrahlung), Epigenetik und der Lebenswartung für Menschen im Weltraum. Der Elastic Stack, inklusive Canvas und anderer Tools, unterstützt diese Forschung in den Bereichen Kreativität und Nützlichkeit. Wenn Sie mehr darüber erfahren möchten, wie Sie Datensätze anreichern können oder woher Sie kostenlose Utility-Token-Gutschriften für die API bekommen, wenden Sie sich an Vectorspace, und wir stellen gerne die erforderlichen Daten für Ihre ersten Schritte bereit.
Und falls Sie den Elastic Stack ausprobieren möchten, sichern Sie sich eine kostenlose 14-tägige Testversion des Elasticsearch Service, oder laden Sie die Lösung als Teil der Standarddistribution herunter.
Vectorspace entwickelt Systeme und Datensätze in Anlehnung an die menschliche Wahrnehmung für Arbitrage-Modelle und wissenschaftliche Erkenntnisse (High-Level-KI/NLP/ML) für Genentech, das Lawrence Berkeley National Laboratory, das US-Energieministerium (DOE), das US-Verteidigungsministerium (DOD), die Biowissenschaftsabteilung der NASA, DARPA und SPAWAR (Abteilung für Weltraum- und Seekriegsführungssysteme der US-Marine) und weitere Kunden.
Shaun McGough ist Product Manager bei Elastic mit den Fachgebieten Datenvisualisierung und alternative Investitionen.