Elasticsearch:构建聊天机器人 RAG 应用
概述
简介
在本指南中,您将学习如何搭建并运行一个基于 RAG 的聊天机器人应用。RAG 代表检索增强生成。这种方法通过自定义数据源来锚定生成式人工智能 (GenAI) 和大型语言模型 (LLM) 的响应,从而避免 LLM 幻觉等问题。本教程将逐步演示如何配置和运行 Elastic 的示例聊天机器人 RAG 应用,让您能亲身体验其运行效果。
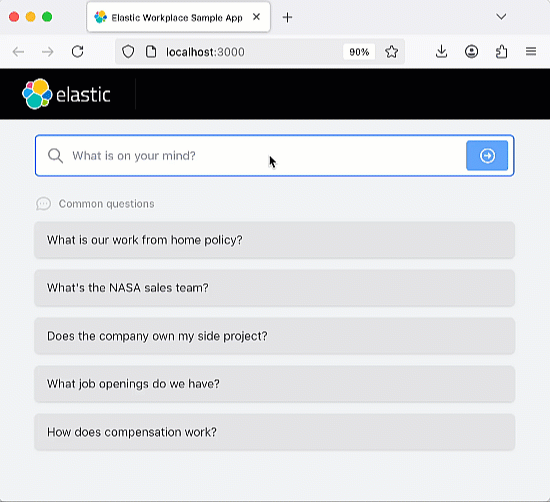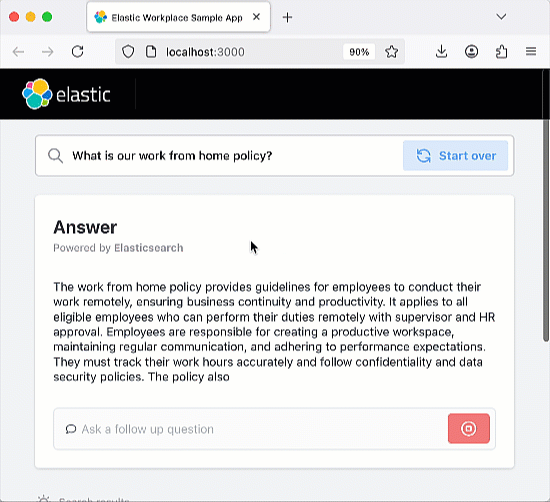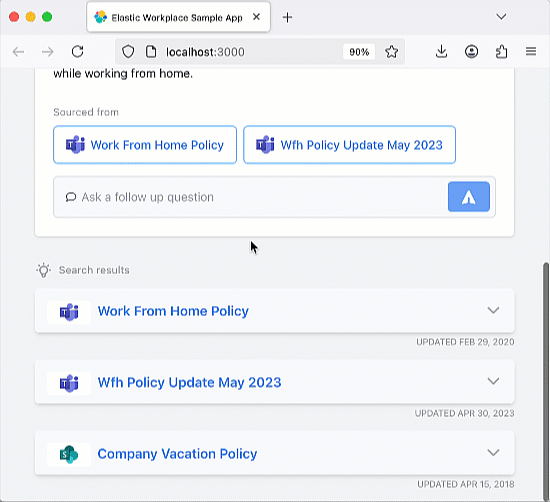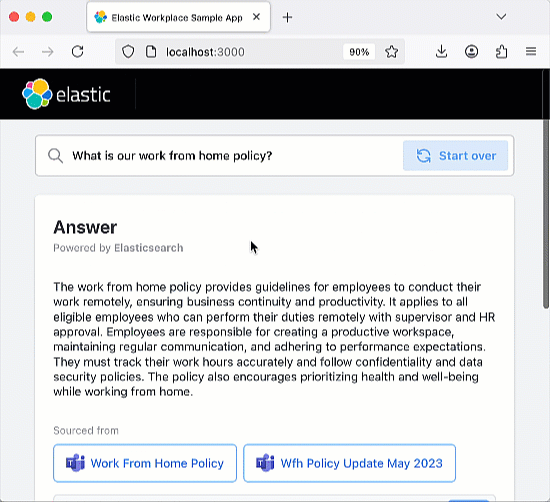
该聊天机器人 RAG 应用是开源的,已托管在 GitHub 上,您可以克隆、分叉并创建自己的版本。该应用使用 Elastic Cloud 托管 Elasticsearch 索引,作为 RAG 应用的检索增强“可信来源”。这确保生成的响应都基于索引中包含的文档信息。该聊天机器人应用经过编码,支持 OpenAI 等多种主流 LLM 服务。该应用架构基于 Python Flask 后端和 React 前端。完整的需求列表请参阅 Elasticsearch Labs 聊天机器人教程。
该聊天机器人 RAG 应用是学习和实验的绝佳工具,您可以在本地计算机上运行它,亲眼见证 Elastic Cloud 与 LLM 如何协同工作,为您的专属文档集打造定制化的生成式人工智能搜索体验。该应用支持与各种 LLM 集成,如 OpenAI、AWS Bedrock、Azure OpenAI、Google Vertex AI、Mistral AI 和 Cohere。有两种方法可以在本地计算机上部署示例聊天机器人 RAG 应用:使用 Docker 或 Python。
下面我们开始吧
运行聊天机器人 RAG 应用
请根据您偏好的部署方式,选择下方“使用 Docker 运行聊天机器人应用”或“使用 Python 运行聊天机器人应用”章节中的步骤进行操作。使用 Docker 所需步骤较少,而使用 Python 则能让您更深入地了解如何配置和运行应用的后端与前端组件。两种运行方式默认都使用 OpenAI 作为 LLM。当您成功使用 OpenAI 运行应用后,只需简单几步即可切换至其他支持的 LLM。
使用 Docker 运行聊天机器人应用
使用 Docker 运行聊天机器人 RAG 应用的过程包括:
- 克隆应用的代码
- 创建 Elastic Cloud 部署
- 创建 OpenAI API 密钥
- 填充应用设置
请按照本介绍视频操作,其中包含在本地计算机上运行应用所需的所有步骤:
介绍视频:使用 Docker 通过 OpenAI 运行聊天机器人 RAG 应用
使用 Python 运行聊天机器人应用程序
使用 Python 运行聊天机器人 RAG 应用程序的过程包括:
- 克隆应用的代码
- 创建 Elastic Cloud 部署
- 创建 OpenAI API 密钥
- 填充应用设置
应用及其依赖项配置完成后,应用的 Python 后端就会启动。然后,React 前端将开始提供应用的 UI,您可以在浏览器中与之交互。
请遵循此介绍视频,其中包含在本地计算机上运行应用所需的所有步骤:
使用 Elasticsearch
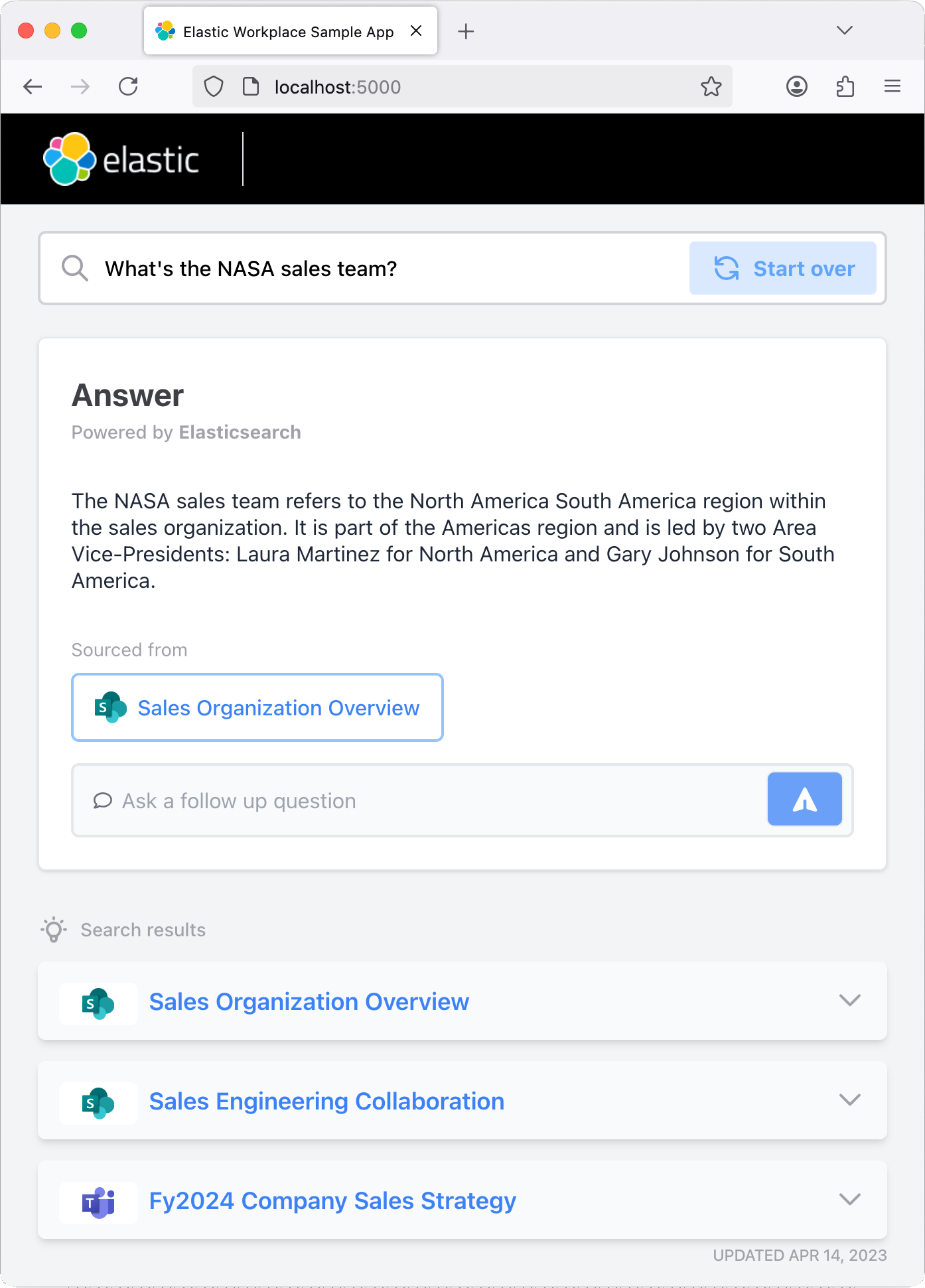
试试正在运行的应用
运行应用后,您可以尝试提问或使用预设问题。该应用的编码包含 Elastic 索引,可以摄取聊天记录,因此您应该尝试提出后续问题,以测试聊天机器人的“记忆”能力。
后续步骤
感谢您花时间了解如何运行 Elastic 聊天机器人 RAG 示例应用。当您开始使用 Elastic 时,您需要了解在整个环境中部署时作为用户应管理的一些操作、安全性和数据组件。
准备好开始了吗?那就在 Elastic Cloud 上开始 14 天的免费试用吧。