January 2, 2026
Automating log parsing in Streams with ML
Learn how a hybrid ML approach achieved 94% log parsing and 91% log partitioning accuracy through automation experiments with log format fingerprinting in Streams.


April 3, 2025
Generating filters and facets using ML
Exploring the pros and cons of automating the creation of filters and facets in a search experience using ML models vs the classical hard-coded approach.

February 5, 2025
Implementing clustering workflows in Elastic to enhance search relevance
We demonstrate how to integrate custom clustering models into the Elastic Stack by leveraging OpenAI text-ada-002 vectors, streamlining the workflow within Elastic’s ecosystem.

January 7, 2025
Early termination in HNSW for faster approximate KNN search
Learn how HNSW can be made faster for KNN search, using smart early termination strategies.

December 19, 2024
Understanding optimized scalar quantization
In this post, we explain a new form of scalar quantization we've developed at Elastic that achieves state-of-the-art accuracy for binary quantization.

December 10, 2024
cRank it up! - Introducing the Elastic Rerank model (in Technical Preview)
Get started in minutes with the Elastic Rerank model: powerful semantic search capabilities, with no required reindexing, provides flexibility and control over costs; high relevance, top performance, and efficiency for text search.

December 5, 2024
Exploring depth in a 'retrieve-and-rerank' pipeline
Select an optimal re-ranking depth for your model and dataset.

November 25, 2024
Introducing Elastic Rerank: Elastic's new semantic re-ranker model
Learn about how Elastic's new re-ranker model was trained and how it performs.
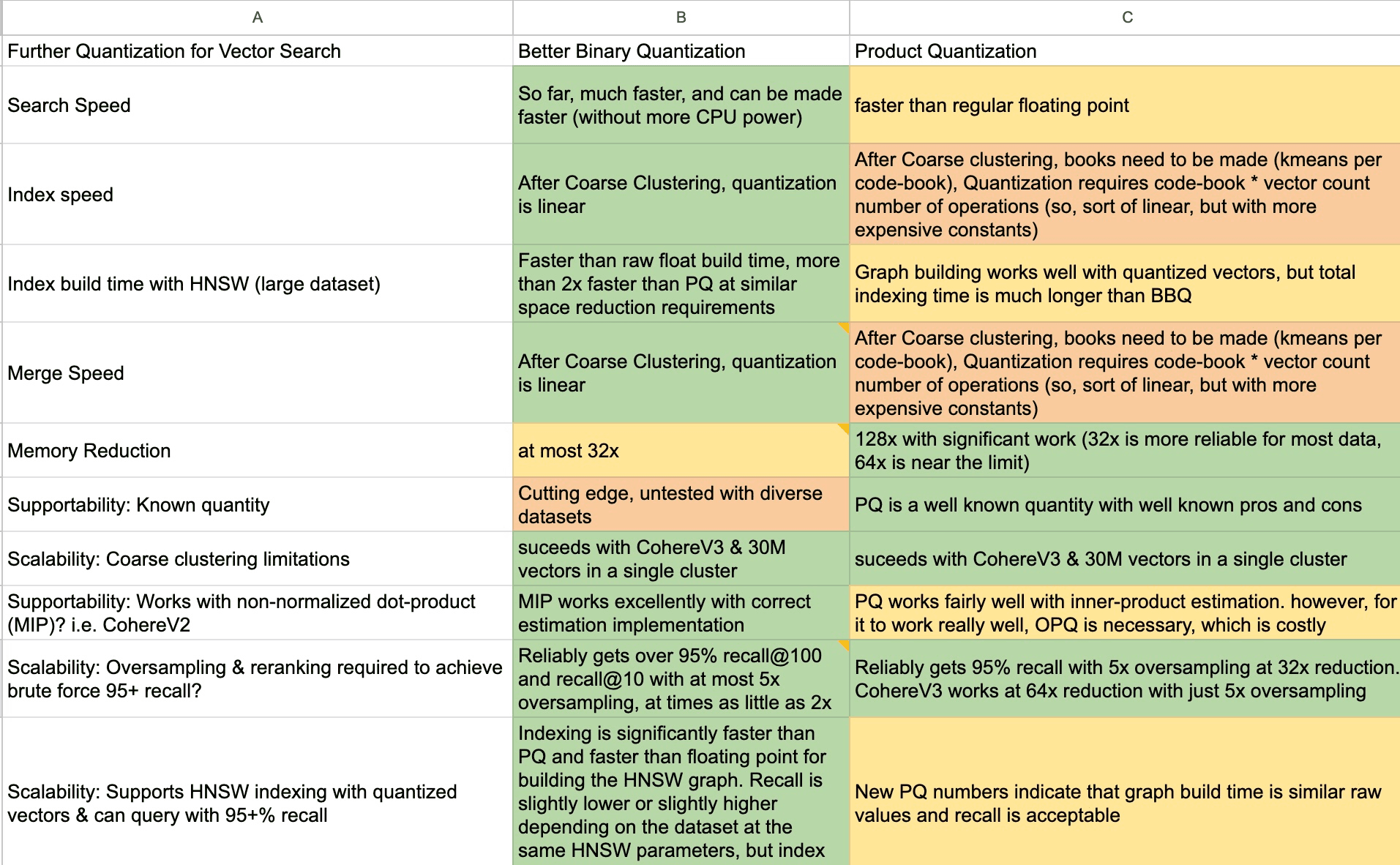
November 18, 2024
Better Binary Quantization (BBQ) vs. Product Quantization
Why we chose to spend time working on Better Binary Quantization (BBQ) instead of product quantization in Lucene and Elasticsearch.