Vers des expériences propulsées par l'IA générative
Une IA optimisée pour la recherche et des outils de développement qui favorisent la rapidité et la scalabilité


 Share on Twitter
Share on TwitterPartager sur Twitter

 Share on LinkedIn
Share on LinkedInPartager sur LinkedIn

 Share on Facebook
Share on FacebookPartager sur Facebook

 Share by Email
Share by EmailPartage par e-mail

 Print this page
Print this pageImprimer
Chaque jour s'accompagne d'un certain nombre d'avancées sur les grands modèles de langage (LLM) et l'IA générative. Les développeurs se retrouvent à la tête de ce mouvement, dont ils influencent la direction et les possibilités. Dans cet article, nous allons voir comment les clients d'Elastic se servent de la base de données vectorielle et de la plateforme ouverte d'Elastic dans le cadre de l'IA optimisée pour la recherche et des outils de développement. Leur but : accélérer et scaler les expériences d'IA générative afin de décupler les possibilités de croissance.
D'après une étude récente menée auprès des développeurs par Dimensional Research et sponsorisée par Elastic, 87 % des développeurs ont déjà réfléchi à un cas d'utilisation pour l'IA générative, qu'il s'agisse de l'analyse des données, du support technique, de la recherche sur l'espace de travail ou des chatbots. Mais seulement 11 % ont réussi à mettre en œuvre ces cas d'utilisation dans des environnements de production.
Plusieurs obstacles viennent se mettre en travers de leur route :
Déploiement et gestion des modèles : pour choisir le bon modèle, il faut faire des tests et itérer rapidement. Or, le déploiement de LLM pour les applications d'IA générative demande beaucoup de temps et est très complexe. La courbe d'apprentissage qui lui est associée est difficile pour la plupart des entreprises.
Préoccupations concernant la législation et la conformité : ces préoccupations sont particulièrement importantes lorsque des données confidentielles sont en jeu. Elles peuvent freiner l'adoption d'un modèle.
- Scaling : des données spécifiques au domaine sont essentielles pour les LLM. Ce sont elles qui leur permettent de comprendre le contexte et de générer des sorties précises. Pour pouvoir récupérer ce contexte au fur et à mesure que vos données scalent, vous devez prendre en charge les charges de travail qui génèrent des plongements vectoriels avec une scalabilité égale. Il vous faudra donc davantage de ressources de mémoire et de calcul. Lorsqu'on utilise de grands ensembles de données, les fenêtres contextuelles à fournir à un LLM sont vastes et coûteuses. Par ailleurs, ce n'est pas parce qu'il y a plus de contexte que la pertinence sera meilleure. Seule une plateforme robuste d'outils peut mettre le contexte en forme et trouver le bon équilibre entre pertinence et échelle, afin de mettre en place une architecture viable parée pour l'avenir en matière d'innovation.
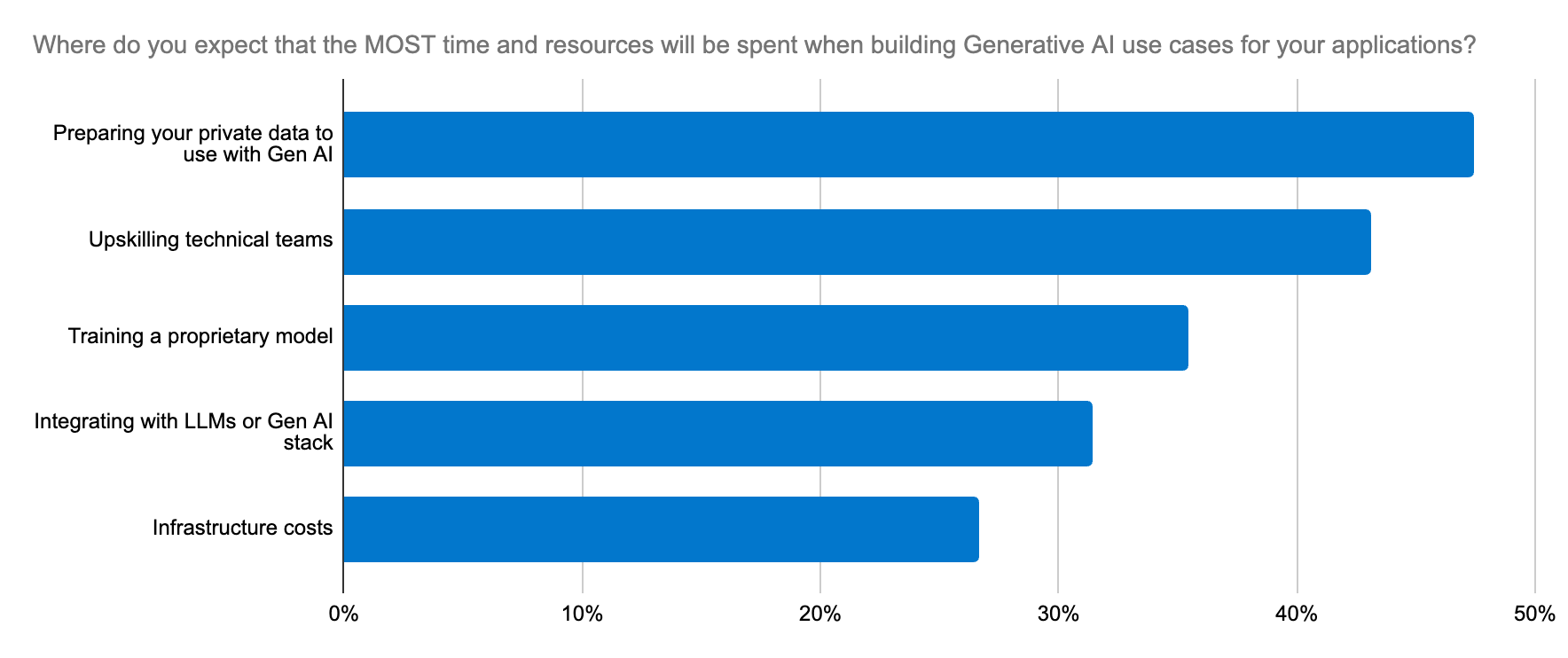
Les développeurs cherchent un moyen fiable, scalable et économique de créer des applications d'IA générative, ainsi qu'une plateforme qui simplifie la mise en place et le processus de sélection du LLM.
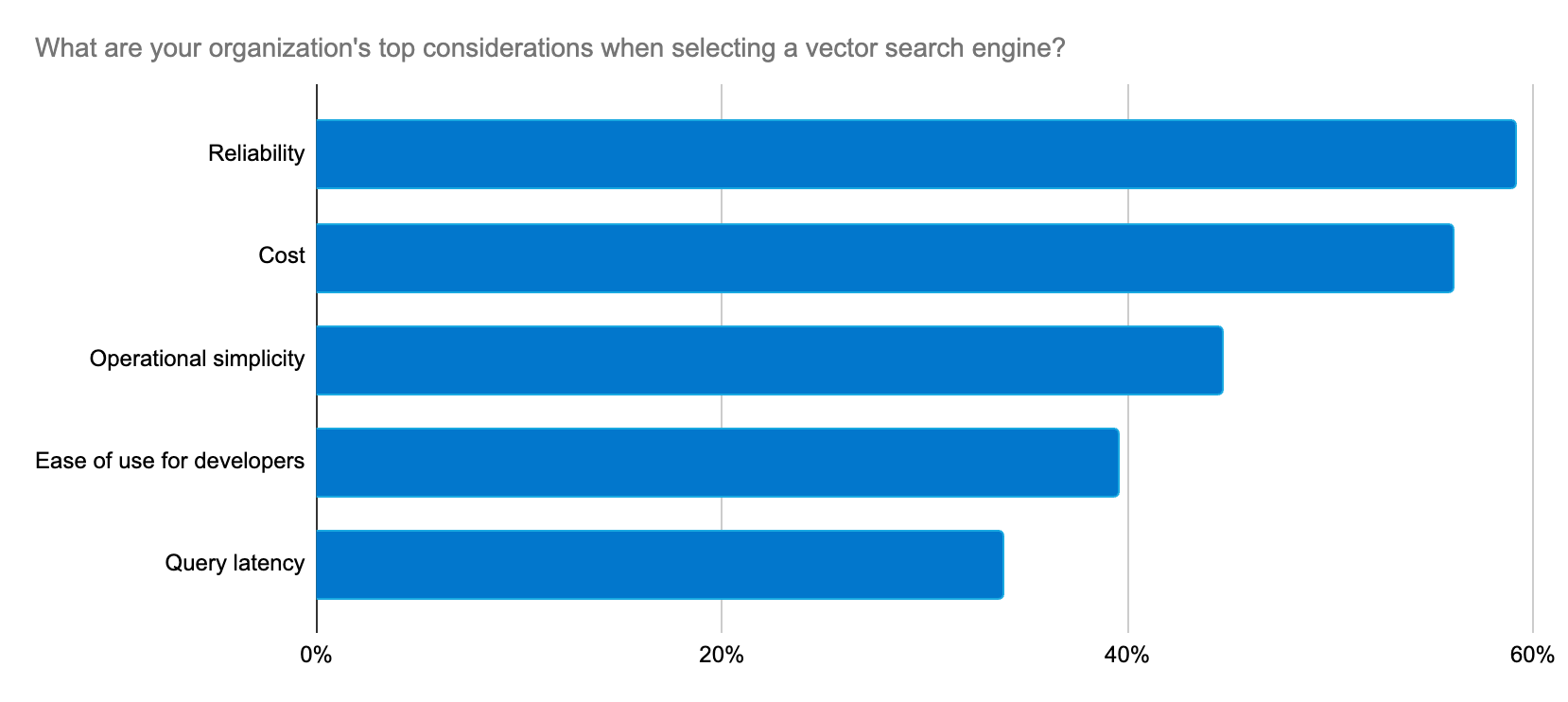
Elastic fournit constamment des solutions qui répondent aux préoccupations des développeurs à un rythme d'innovation soutenu afin de prendre en charge les cas d'utilisation de l'IA générative.
Déployez des expériences d'IA générative avec rapidité et à grande échelle
Elasticsearch est la base de données vectorielle la plus téléchargée du marché. L'association étroite entre Elastic et la communauté Lucene nous a permis de concevoir et de fournir rapidement des innovations en matière de recherche à nos clients. Elasticsearch est désormais adossé à Lucene 9.10, ce qui permet aux clients de bénéficier d'une vitesse optimale et d'une grande échelle avec l'IA générative. Avec la version 9.10, les utilisateurs constatent notamment une amélioration considérable en ce qui concerne la latence des requêtes sur les index à plusieurs segments. Et ce n'est que le début. La vitesse va aller en s'accélérant davantage.
Nous avons choisi Elastic comme base de données vectorielle en raison de sa flexibilité, de sa scalabilité et de sa fiabilité inhérentes. Elastic va plus loin en fournissant constamment de nouvelles fonctionnalités qui étayent le Machine Learning et l'IA générative.
Peter O'Connor, directeur de l'ingénierie de plateforme chez Stack Overflow
Pour mettre en œuvre les charges de travail RAG et les scaler rapidement, rien de tel qu'Elastic Learned Sparse EncodeR (ELSER), proposé en disponibilité générale. Ce modèle de Machine Learning optimisé, à interaction tardive, est facile à déployer pour la recherche sémantique. ELSER fournit des résultats de recherche pertinents d'un point de vue contextuel sans qu'il soit nécessaire de le régler. Grâce à cette solution intégrée et fiable, les développeurs n'ont plus besoin de se creuser les méninges pour sélectionner, déployer et gérer un modèle. Celui-ci est déjà tout trouvé !
ELSER rehausse la pertinence de la recherche sans sacrifier la rapidité. Par exemple, lorsque Consensus a mis à niveau sa plateforme académique de recherche propulsée par Elastic à l'aide d'ELSER, elle a réduit sa latence de recherche de 75 % tout en optimisant sa précision.
Lorsque vous associez ELSER avec le modèle d'intégration E5, vous pouvez facilement appliquer la recherche vectorielle multilingue. Notre artefact optimisé d'E5 est conçu spécifiquement pour les déploiements Elasticsearch. La recherche multilingue est également disponible lorsqu'on charge des modèles multilingues ou qu'on procède à une intégration avec l'API d'inférence d'Elastic (par exemple, les plongements de modèle multilingues de Cohere). Ces avancées donnent un coup d'accélérateur à la génération augmentée de récupération (RAG), ce qui fait d'Elastic une infrastructure stratégique pour scaler les expériences innovantes adossées à l'IA générative que vous concevez.
Le but d'Elastic est également de scaler ces expériences avec efficacité. La quantification scalaire, qui équipe notre version 8.12, vient changer la donne en ce qui concerne le stockage vectoriel. Lorsque les expansions vectorielles sont volumineuses, les recherches peuvent être lentes. Or, cette technique de compression permet de réduire considérablement le volume de mémoire exigé en le divisant par quatre, ainsi que de prendre en charge un plus grand nombre de vecteurs. À de plus grandes échelles, elle a un impact négligeable sur le rappel. Elle multiplie la vitesse de la recherche vectorielle par deux dans le cadre de la RAG sans sacrifier la précision. Résultat ? Un système plus simple et plus rapide qui réduit les coûts d'infrastructure à grande échelle.
Quand vous associez la précision et la vitesse d'Elastic à la puissance de Google Cloud, vous pouvez développer une plateforme de recherche très stable et rentable qui garantit une formidable expérience aux utilisateurs.
Sujith Joseph, architecte principal chargé du cloud et de la recherche d'entreprise chez Cisco Systems
Le moteur de recherche le plus pertinent pour la RAG
La pertinence est la clé d'une expérience d'IA générative optimale. Pour récupérer des documents pertinents aux fins de contexte pour les LLM, l'idéal est d'utiliser ELSER pour la recherche sémantique et BM25 pour la recherche textuelle. Les grandes fenêtres contextuelles peuvent être affinées davantage à l'aide de rerankers, des outils qui effectuent un nouveau tri et qui font désormais partie de la Suite Elastic. Les rerankers appliquent des modèles de Machine Learning puissants pour affiner vos résultats de recherche afin de vous présenter ceux qui sont les plus pertinents d'après les préférences utilisateur et les signaux. L'apprentissage du classement (LTR) est aujourd'hui une fonctionnalité native d'Elasticsearch Platform. Elle est particulièrement intéressante pour les cas d'utilisation de RAG, dont le but est de fournir les résultats les plus pertinents à un LLM aux fins de contexte.
La mise en œuvre est simplifiée grâce à l'API d'inférence et des fournisseurs tiers comme Cohere. Passez à notre dernière version pour tester l'impact des rerankers sur la pertinence.
Ces approches contribuent non seulement à améliorer la pertinence de la recherche (de 30 %, dans le cas de Consensus), mais aussi à vous aider à atteindre de bons résultats rapidement en affinant la pertinence de la RAG et en gérant efficacement les flux de ML.
Vers une simplification de choix et de l'échange de modèle
Lorsqu'on choisit un modèle, on peut avoir l'impression de chercher une aiguille dans une botte de foin. D'après l'étude que nous avons réalisée auprès des développeurs, l'un des cinq principaux efforts en matière d'IA générative concerne l'intégration aux LLM. Il ne s'agit pas simplement de déterminer s'il est préférable d'utiliser un LLM en source ouverte ou en source fermée. Les enjeux vont au-delà de ça, car il est ici question de précision, de sécurité des données, de spécificité à un domaine et de la possibilité de s'adapter rapidement à l'évolution de l'écosystème du LLM. Les développeurs ont besoin d'un workflow qui soit simple pour pouvoir tester de nouveaux modèles et les changer.
Elastic prend en charge les modèles de transformateur et les modèles de base grâce à sa plateforme, sa base de données vectorielle et son moteur de recherche ouverts. Elastic Learned Sparse EncodeR (ELSER) est un excellent point de départ pour accélérer la mise en œuvre de la RAG.
En parallèle, l'API d'inférence d'Elastic rationalise le code et la gestion des inférences multicloud pour les développeurs. Que vous utilisiez ELSER ou des plongements d'OpenAI (le modèle le plus évalué et le plus utilisé par les développeurs), de Hugging Face, de Cohere ou autre pour les charges de travail de RAG, un seul appel d'API suffit pour avoir un code propre et pouvoir gérer le déploiement des inférences hybrides. Avec l'API d'inférence, vous avez accès à un vaste panel de modèles. Vous n'avez plus qu'à faire votre choix en fonction de vos besoins. L'intégration se fait facilement avec le traitement du langage naturel (NLP) spécifique au domaine et avec les modèles d'IA générative, ce qui vous permet de rationaliser la gestion des modèles et, de là, vous libérer du temps pour le consacrer à l'innovation en matière d'IA.
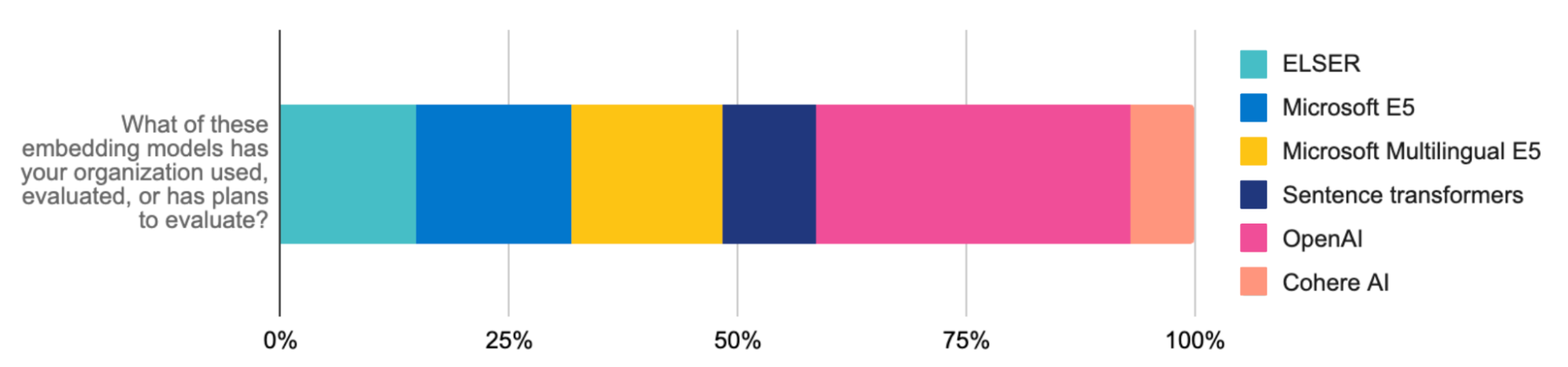
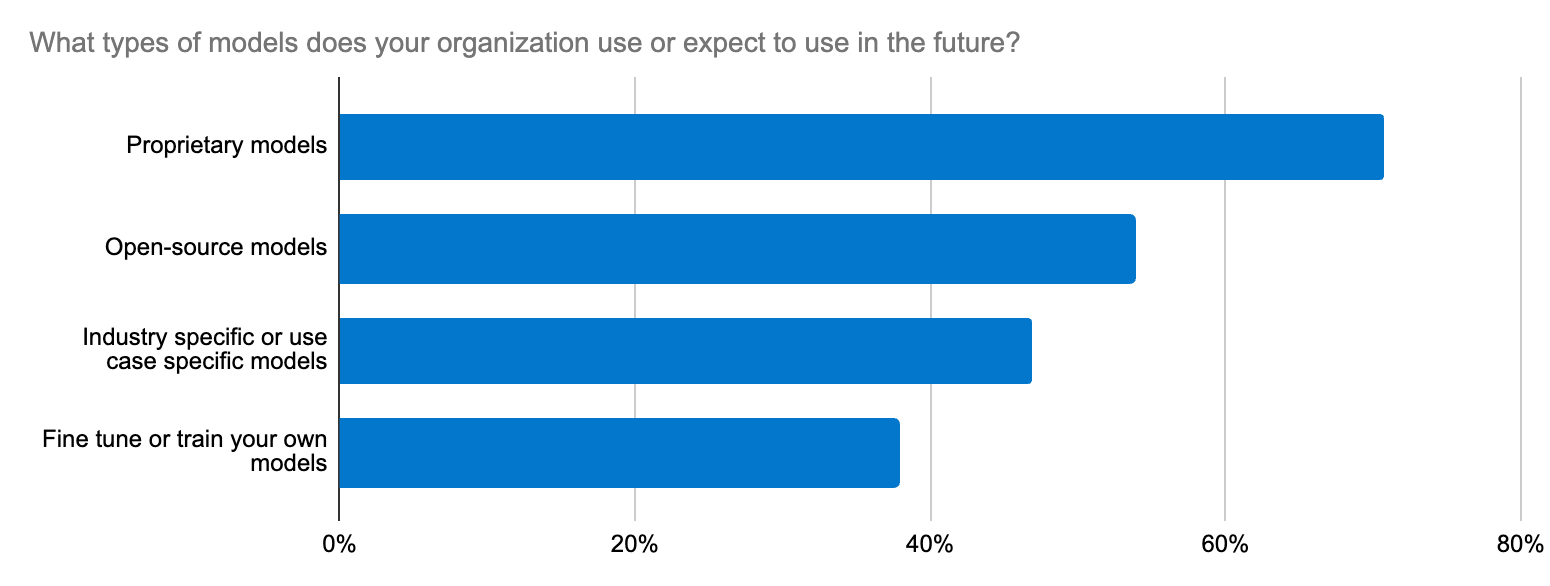
L'union fait la force, grâce aux intégrations
Les développeurs peuvent aussi héberger différents modèles de transformateur, y compris les modèles publics et privés de Hugging Face. Même si Elasticsearch sert de base de données vectorielle polyvalente pour l'intégralité de l'écosystème, les développeurs qui préfèrent utiliser des outils tels que LangChain et LlamaIndex peuvent tirer parti de nos intégrations tout en utilisant les modèles LangChain pour mettre rapidement en place des applications d'IA générative prêtes à être lancées en production. La plateforme ouverte d'Elastic vous permet de vous adapter rapidement, de faire des tests et d'accélérer les projets d'IA générative. Elastic a récemment été ajoutée en tant que base de données vectorielle tierce pour On Your Data, un nouveau service permettant de créer des copilotes conversationnels. Un autre bon exemple est la collaboration d'Elastic avec l'équipe Cohere. Le but de cette collaboration est de travailler en coulisses pour faire d'Elastic une base de données vectorielle optimale pour les plongements de Cohere.
L'IA générative est en train de bouleverser le fonctionnement des entreprises, et Elastic est là pour accompagner cette transformation. Pour les développeurs, une mise en œuvre réussie de l'IA générative passe par un apprentissage continu et une capacité à s'adapter rapidement à l'évolution du paysage de l'IA. D'ailleurs, on vous recommande de jeter un œil à Elastic Search Labs pour plus d'informations.
À vous de jouer !
- Envie d'en savoir plus ? Découvrez ces fonctionnalités et bien d'autres dans les notes de publication d'Elastic Search.
- Les clients qui utilisent déjà Elastic Cloud peuvent accéder à la majorité de ces fonctionnalités directement depuis la console Elastic Cloud. Vous n'utilisez pas encore Elastic Cloud ? Démarrez un essai gratuit.
- Testez Elasticsearch Relevance Engine, notre suite d'outils destinée aux développeurs pour la création d'applications de recherche adossées à l'IA.
La publication et la date de publication de toute fonctionnalité ou fonction décrite dans le présent article restent à la seule discrétion d'Elastic. Toute fonctionnalité ou fonction qui n'est actuellement pas disponible peut ne pas être livrée à temps ou ne pas être livrée du tout.
Dans cet article, nous sommes susceptibles d'avoir utilisé ou mentionné des outils d'intelligence artificielle générative tiers appartenant à leurs propriétaires respectifs qui en assurent aussi le fonctionnement. Elastic n'a aucun contrôle sur les outils tiers et n'est en aucun cas responsable de leur contenu, de leur fonctionnement, de leur utilisation, ni de toute perte ou de tout dommage susceptible de survenir à cause de l'utilisation de tels outils. Lorsque vous utilisez des outils d'IA avec des informations personnelles, sensibles ou confidentielles, veuillez faire preuve de prudence. Toute donnée que vous saisissez dans ces solutions peut être utilisée pour l'entraînement de l'IA ou à d'autres fins. Vous n'avez aucune garantie que la sécurisation ou la confidentialité des informations renseignées sera assurée. Vous devriez vous familiariser avec les pratiques en matière de protection des données personnelles et les conditions d'utilisation de tout outil d'intelligence artificielle générative avant de l'utiliser.
Elastic, Elasticsearch, ESRE, Elasticsearch Relevance Engine et les marques associées sont des marques commerciales, des logos ou des marques déposées d'Elasticsearch N.V. aux États-Unis et dans d'autres pays. Tous les autres noms de produits et d'entreprises sont des marques commerciales, des logos ou des marques déposées appartenant à leurs propriétaires respectifs.
Partager
- Share on Twitter
Partager sur Twitter
- Share on LinkedIn
Partager sur LinkedIn
- Share on Facebook
Partager sur Facebook
- Share by Email
Partage par e-mail
- Print this page
Imprimer